(论文翻译)THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS《彩票假说:寻找稀疏、可训练的神经网络》
公式不清楚的地方请对照英文原文进行查看:原论文链接
神经网络修剪技术可以将训练网络的参数计数减少90%以上,降低存储需求并提高推理的计算性能,而不影响准确性。然而,当代的经验是,通过修剪产生的稀疏架构从一开始就难以训练,这将类似地提高训练性能。我们发现,一个标准的修剪技术自然地发现子网络,其初始化使他们能够有效地训练。基于这些结果,我们阐明了彩票假说:密集的、随机初始化的、前馈网络包含子网络(中奖票),这些子网络在孤立地训练时,在类似数量的迭代中达到与原始网络相当的测试精度。我们发现的中奖彩票赢得了初始化彩票:它们的连接具有使训练特别有效的初始权重。我们提出了一个算法来识别中奖彩票和一系列的实验,支持彩票的假设和这些偶然的初始化的重要性。我们不断发现中奖彩票的大小小于MNIST和CIFAR 10的几个全连接和卷积前馈架构的10-20%。超过这个大小,我们发现的中奖彩票比原始网络学习得更快,并达到更高的测试精度。
1 INTRODUCTION 引言
用于从神经网络中消除不必要的权重的技术(修剪)(LeCun等人,Hassibi & Stork,1993; Han等人,2015; Li等人,2016)可以减少参数计数超过90%,而不会影响精度。这样做减小了尺寸(Han等人,2015;欣顿等人,2015)或能量消耗(Yang等人,2017; Molchanov等人,2016; Luo等人,2017),使推理更有效。然而,如果网络的大小可以减小,为什么我们不训练这个更小的架构,而不是为了使训练更有效呢?当代的经验是,通过修剪发现的架构从一开始就很难训练,达到的准确性低于原始网络。(1“从头开始训练修剪模型比重新训练修剪模型的性能更差,这可能表明训练容量较小的网络的难度。”(Li例如,2016年)“在重新训练期间,最好是保留初始训练阶段的权重,用于幸存的修剪连接,而不是重新初始化修剪的层…梯度下降能够在网络初始训练时找到一个好的解决方案,但在重新初始化一些层并重新训练它们之后就不能了。(Han例如,2015年))
考虑一个例子。在图1中,我们从MNIST的全连接网络和CIFAR10的卷积网络中随机采样和训练子网络。随机抽样模型的非结构化修剪LeCun等人使用的效果。(1990)和Han et al.(2015年)。在不同的稀疏度水平上,虚线跟踪最小验证损失(作为网络学习速度的代理,我们使用提前停止标准结束训练的迭代。我们在本文中采用的特定早期停止标准是训练期间最小验证损失的迭代。有关此选项的更多详细信息,请参见附录C。)的迭代和该迭代的测试准确度。网络越稀疏,学习速度越慢,最终的测试精度。

图1:在以各种规模开始训练时,MNIST的Lenet架构和CIFAR 10的Conv-2、Conv-4和Conv-6架构(参见图2)的迭代(左)和该迭代(右)的测试精度。虚线是随机采样的稀疏网络(十次试验的平均值)。实线表示中奖票(平均五次试训)。
在本文中,我们证明了始终存在较小的子网络,这些子网络从一开始就进行训练,并且在达到类似测试精度的同时,学习速度至少与较大的子网络一样快。图1中的实线显示了我们发现的网络。基于这些结果,我们陈述彩票假说。
彩票假说 一个随机初始化的密集神经网络包含一个子网络,该子网络被初始化,使得在孤立训练时,它可以在训练最多相同次数的迭代后匹配原始网络的测试精度。
更正式地,考虑密集前馈神经网络f(x;初始参数θ = θ0 Dθ。当在训练集上使用随机梯度下降(SGD)进行优化时,f在迭代j处达到最小验证损失l,测试精度为a。此外,考虑训练f(x; m θ),其中掩码m ∈ {0,1}| θ角|其初始化为m θ0。当在相同的训练集上使用SGD进行优化时(m固定),f在迭代j时达到最小验证损失l,测试精度为a。彩票假说预测,其中j ≤ j(相称训练时间),a ≥ a(相称准确度),且m 0| θ角|(参数较少)。
我们发现,一个标准的修剪技术自动从全连接和卷积前馈网络中发现这样的可训练子网络。我们将这些可训练的子网络f(x; m θ0),因为我们找到的那些已经赢得了具有权重和能够学习的连接的组合的初始化彩票。当它们的参数被随机地重新初始化(f(x; m θ 0),其中θ 0 Dθ),我们的中奖票不再与原始网络的性能相匹配,这证明了这些较小的网络除非进行适当的初始化,否则无法有效地训练。
识别中奖彩票 我们通过训练网络并修剪其最小量级的权重来识别中奖彩票。剩下的未修剪的连接构成了中奖彩票的体系结构。在我们的工作中,每个未修剪的连接的值在训练之前从原始网络重置为初始值。这构成了我们的中心实验:
- 随机初始化一个神经网络f(x; θ0)(其中θ0 Dθ)。
- 训练网络进行j次迭代,得到参数θj。
- 修剪θj中的参数的p%,创建掩码m。
- 将其余参数重置为它们在θ0中的值,创建中奖票f(x; m θ0)。
如上所述,这种修剪方法是一次性的:网络被训练一次,修剪p%的权重,并且重置幸存的权重。然而,在本文中,我们关注的是迭代修剪,即在n轮中重复训练、修剪和重置网络;每一轮修剪在前一轮中幸存的权重的p ~ 1 n %。我们的研究结果表明,迭代修剪找到的中奖票,匹配的准确性,在较小的尺寸比一杆修剪的原始网络。
结果。 我们在MNIST的全连接架构和CIFAR10的卷积架构中,通过几种优化策略(SGD,动量和Adam),使用dropout,weight decay,batchnorm和residual connections等技术确定了获胜门票。我们使用非结构化修剪技术,因此这些中奖彩票是稀疏的。在更深层的网络中,我们基于修剪的中奖彩票搜索策略对学习率很敏感:它需要预热来以较高的学习率找到中奖票。我们发现的中奖彩票是原来大小的网络(规模较小)的10-20%(或更少)。在这个规模下,它们在最多相同数量的迭代(相称的训练时间)中达到或超过原始网络的测试准确度(相称的准确度)。当随机重新初始化时,中奖彩票的表现要差得多,这意味着结构本身不能解释中奖彩票的成功。
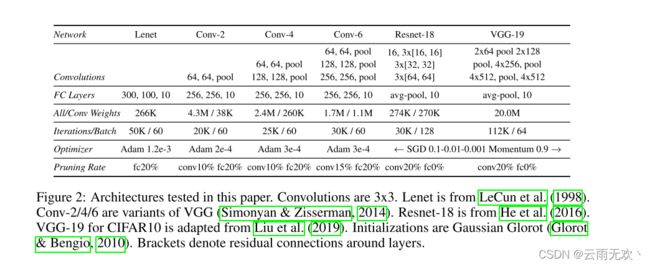
图2:本文中测试的架构。卷积是3x 3。Lenet来自LeCun et al.(1998)。Conv-2/4/6是VGG的变体(Simonyan & Zisserman,2014)。Resnet-18来自He et al.(2016年)。CIFAR 10的VGG-19改编自Liu et al.(2019年)。初始化是Gaussian Glorot(Glorot & Bengio,2010)。括号表示层周围的剩余连接。
彩票猜想回到我们的激励问题 我们将我们的假设扩展到一个未经测试的猜想,即SGD寻找并训练一个初始化良好的权重子集。随机初始化的密集网络比修剪产生的稀疏网络更容易训练,因为有更多可能的子网络,训练可能会从中恢复中奖彩票。
Contributions.
- 我们证明,修剪揭示可训练的子网络,达到测试精度相媲美的原始网络,他们在一个相当数量的迭代。
- 我们发现,修剪找到了学习速度比原始网络更快的中奖彩票,同时达到了更高的测试准确率和更好的泛化能力。
- 我们提出彩票假说作为神经网络组成的新视角来解释这些发现。
暗示。 本文对彩票假说进行了实证研究。现在我们已经证明了中奖彩票的存在,我们希望利用这一知识:
提高培训绩效。由于中奖彩票可以从一开始就孤立地训练,因此希望我们可以设计出搜索中奖彩票并尽早修剪的训练方案。
设计更好的网络。获胜的门票揭示了稀疏架构和初始化的组合,特别擅长学习。我们可以从中奖中获得灵感,设计出具有相同属性的新架构和初始化方案,这些都有利于学习。我们甚至可以将为一个任务发现的中奖彩票转移到许多其他任务。
提高我们对神经网络的理论理解。我们可以研究为什么随机初始化的前馈网络似乎包含中奖票和对优化的理论研究的潜在影响(Du等人,2019)和泛化(Zhou等人,2018; Arora等人,2018年)。
2 WINNING TICKETS IN FULLY-CONNECTED NETWORKS在全连接网络中赢取门票
在本节中,我们将评估彩票假设应用于在MNIST上训练的全连接网络。我们使用Lenet-300-100架构(LeCun等人,1998),如图2所示。我们遵循第1节的大纲:在随机初始化和训练网络之后,我们修剪网络并将剩余的连接重置为它们的原始初始化。我们使用一个简单的逐层剪枝启发式算法:移除每一层内具有最低量值的权重的百分比(如在Han等人中)。(2015))。到输出的连接以网络其余部分的速率的一半被修剪。我们在附录G中探索了其他超参数,包括学习率,优化策略(SGD,动量),初始化方案和网络大小。

图3:随着训练的进行,在Lenet上测试准确性(迭代修剪)。每条曲线是五次试验的平均值。标签是Pm-修剪后网络中剩余的权重的分数。误差线是任何试验的最小值和最大值。
注意 Pm = m 0| θ角|是掩模m的稀疏性,例如,当修剪75%的权重时,Pm = 25%。
![]()
迭代修剪。我们发现的中奖彩票比原始网络学习得更快。图3绘制了当训练迭代修剪到各种程度的获胜票据时的平均测试准确度。误差线是五次运行的最小值和最大值。对于第一轮修剪,网络学习得更快,并且修剪得越多,测试精度就越高(图3中的左图)。包括来自原始网络的权重的51.3%的中奖票(即,Pm = 51.3%)比原始网络更快地达到更高的测试精度,但比Pm = 21.1%时慢。当Pm <21.1%时,学习减慢(中间图)。当Pm = 3.6%时,获胜票回归到原始网络的性能。类似的模式在本文中反复出现。
图4a总结了在每次迭代迭代修剪20%时所有修剪级别的这种行为(蓝色)。左边是每个网络达到最小验证损失的迭代(即,当早期停止标准将停止训练时)与修剪后剩余权重的百分比的关系;中间是该迭代的测试精度。我们使用满足早期停止标准的迭代作为网络学习速度的代理。
当Pm从100%下降到21%时,获胜的票学习得更快,此时提前停止比原始网络早38%。进一步的修剪导致学习变慢,返回到Pm = 3.6%时原始网络的早期停止性能。检验精度随剪枝的增加而提高,当Pm = 13.5%时,检验精度提高了0.3个百分点以上;在这一点之后,精度降低,返回到原始网络的水平,当Pm = 3.6%时。
在早期停止时,训练准确性(图4a,右)以类似于测试准确性的模式随着修剪而增加,似乎意味着中奖彩票更有效地优化,但不会更好地推广。然而,在迭代50,000次时(图4b),迭代修剪的获胜门票仍然可以看到高达0.35个百分点的测试准确度提高,尽管几乎所有网络的训练准确度都达到了100%(附录D,图12)。这意味着训练准确度和测试准确度之间的差距对于赢得门票来说更小,这表明泛化能力有所提高。
随机重新初始化。为了测量获胜票据的初始化的重要性,我们保留获胜票据的结构(即,掩模m),但随机采样新的初始化θ 0 Dθ。我们随机将每张中奖彩票重新初始化三次,在图4中,每个点总共初始化15次。我们发现,初始化是至关重要的一张中奖票的功效。图3中的右图显示了迭代修剪的实验。除了原始网络和中奖彩票在Pm = 51%和21%时进行随机重新初始化实验。当中奖彩票被修剪时,它们学习得更快,当随机重新初始化时,它们学习得越来越慢。
该实验的更广泛结果是图4a中的橙子线。与中奖不同的是,重新初始化的网络比原始网络学习得更慢,并且在很少修剪之后就失去了测试准确性。当Pm = 21.1%时,平均重新初始化的迭代中奖票据的测试准确度从原始准确度下降,相比之下,中奖票据的测试准确度为2.9%。当Pm = 21%时,获胜票据达到最小验证损失的速度比重新初始化时快2.51倍,并且准确率高半个百分点。当Pm ≥ 5%时,所有网络的训练准确率均达到100%;因此,图4b示出了获胜票的推广比随机重新初始化时好得多。这个实验支持彩票假说对初始化的强调:原始初始化经受住修剪并从中受益,而随机重新初始化的性能立即受到损害并稳定地降低。
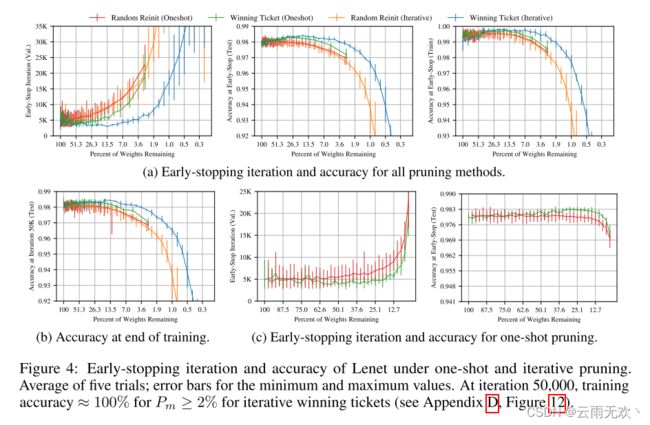 图4:在一次和迭代修剪下Lenet的早期停止迭代和准确性。五次试验的平均值;最小值和最大值的误差条。在迭代50,000次时,对于迭代获胜票,Pm ≥ 2%的训练准确率≈ 100%(参见附录D,图12)。
图4:在一次和迭代修剪下Lenet的早期停止迭代和准确性。五次试验的平均值;最小值和最大值的误差条。在迭代50,000次时,对于迭代获胜票,Pm ≥ 2%的训练准确率≈ 100%(参见附录D,图12)。
一次性修剪。虽然迭代修剪提取较小的中奖彩票,但重复训练意味着找到它们的成本很高。一次性修剪使得可以在没有这种重复训练的情况下识别中奖彩票。图4c示出了单次修剪(绿色)和随机重新初始化(红色)的结果;一次修剪确实能找到中奖票。当67.5% ≥ Pm ≥ 17.6%时,平均中奖票比原始网络更早达到最小验证精度。当95.0% ≥ Pm ≥ 5.17%时,测试精度高于原网络。然而,迭代修剪的中奖票学习更快,并在较小的网络规模下达到更高的测试精度。图4c中的绿色线和红线再现在图4a的对数轴上,使得该性能差距清楚。由于我们的目标是确定最小的可能中奖彩票,我们专注于迭代修剪在整个论文的其余部分。
3 WINNING TICKETS IN CONVOLUTIONAL NETWORKS卷积网络中的中奖票
在这里,我们将彩票假设应用于CIFAR 10上的卷积网络,增加了学习问题的复杂性和网络的大小。我们考虑图2中的Conv-2,Conv-4和Conv-6架构,它们是VGG(Simonyan & Zisserman,2014)家族的缩小变体。该网络具有两个、四个或六个卷积层,然后是两个全连接层;最大池化发生在每两个卷积层之后。这些网络覆盖了从几乎完全连接到传统卷积网络的范围,在Conv-2中卷积层中的参数不到1%,在Conv-6.3中接近三分之二。
寻找中奖彩票 图5中的实线(顶部)示出了在来自图2的每层修剪率下对Conv-2(蓝色)、Conv-4(橙子)和Conv-6(绿色)的迭代彩票实验。第2节中Lenet的模式重复:当网络被修剪时,与原始网络相比,它学习得更快,并且测试精度提高。在这种情况下,结果更加明显。对于Conv-2(Pm = 8.8%),中奖彩票证达到最小验证损失的速度最多为3.5倍,对于Conv-4(Pm = 9.2%)为3.5倍,对于Conv-6(Pm = 15.1%)为2.5倍。Conv-2(Pm = 4.6%)、Conv-4(Pm = 11.1%)和Conv-6(Pm = 26.4%)的测试准确度最多提高3.4个百分点。当Pm > 2%时,所有三个网络都保持高于其原始平均测试准确度。

图5:当迭代修剪和随机重新初始化时,Conv-2/4/6架构的早期停止迭代以及测试和训练精度。每条实线是五次试验的平均值;每条虚线是十五次重新初始化(每次试验三次)的平均值。右下图绘制了在与原始网络的最后一次训练迭代相对应的迭代处的中奖票的测试准确度(Conv-2为20,000,Conv-4为25,000,Conv-6为30,000);在此迭代中,对于获胜彩票,Pm ≥ 2%的训练准确率≈ 100%(参见附录D)。
与第2节一样,早期停止迭代的训练精度随着测试精度的提高而提高。然而,在Conv-2的迭代20,000次,Conv-4的迭代25,000次,Conv-6的迭代30,000次(迭代对应于原始网络的最终训练迭代),当Pm ≥ 2%时,所有网络的训练准确度达到100%(附录D,图13),并且获胜门票仍然保持较高的测试准确度(图5右下角)。这意味着测试和训练准确率之间的差距对于赢得门票来说更小,表明它们的泛化能力更好。
随机重新初始化。我们重复第2节中的随机重新初始化实验,如图5中的虚线所示。这些网络在继续修剪时再次花费越来越长的时间来学习。正如Lenet在MNIST上的情况一样(第2节),随机重新初始化实验的测试精度下降得更快。然而,不像Lenet,测试精度在早期停止时间最初保持稳定,甚至提高了Conv-2和Conv-4,这表明,在中等水平的修剪结构的中奖门票可能会导致更好的准确性。
丢弃。Dropout(Srivastava等人,2014;欣顿等人,2012)通过随机禁用一部分单元(即,随机采样子网络)。Baldi & Sadowski(2013)将dropout描述为同时训练所有子网络的集合。由于彩票假说表明,这些子网络中的一个包含中奖彩票,因此很自然地会问,dropout和我们寻找中奖彩票的策略是否相互作用。
图6示出了训练Conv-2、Conv-4和Conv-6的结果,其中丢失率为0.5。虚线是没有dropout的网络性能(图5中的实线)。4我们在dropout训练时继续发现中奖彩票。Dropout提高了初始测试准确率(Conv-2、Conv-4和Conv-6的平均准确率分别为2.1、3.0和2.4个百分点),迭代修剪进一步提高了准确率(平均分别增加了2.3、4.6和4.7个百分点)。学习变得更快,与以前一样,迭代修剪,但在Conv-2的情况下不太明显。
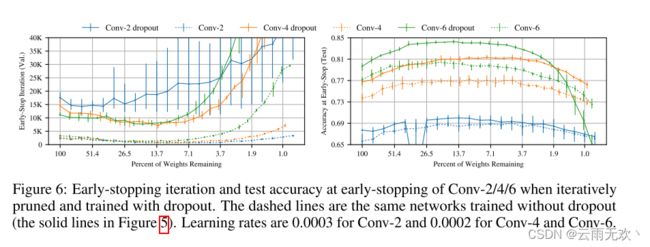 图6:Conv-2/4/6在迭代修剪和使用dropout进行训练时的早停止迭代和测试精度。虚线是没有丢失训练的相同网络(图5中的实线)。Conv-2的学习率为0.0003,Conv-4和Conv-6的学习率为0.0002。
图6:Conv-2/4/6在迭代修剪和使用dropout进行训练时的早停止迭代和测试精度。虚线是没有丢失训练的相同网络(图5中的实线)。Conv-2的学习率为0.0003,Conv-4和Conv-6的学习率为0.0002。
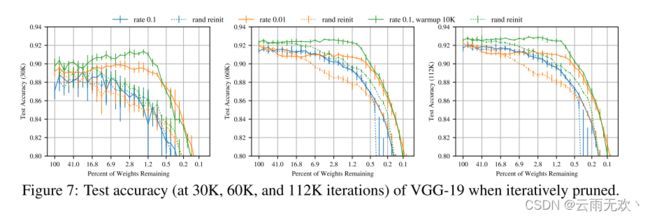
图7:迭代修剪时VGG-19的测试精度(在30 K、60 K和112 K迭代下)。
这些改进表明,我们的迭代修剪策略以互补的方式与dropout相互作用。Srivastava等人(2014)观察到dropout在最终网络中诱导稀疏激活;丢失引起的稀疏性可能使网络准备好被修剪。如果是这样,则可以使用以权重为目标的丢弃技术(Wan et al.2013)或学习每权重丢弃概率(Molchanov等人,2017; Louizos等人,2018)可以使中奖门票更容易找到。
4 VGG AND RESNET FOR CIFAR10 CIFAR10的VGG和RESNET
在这里,我们研究的彩票假设网络唤起的架构和技术在实践中使用。具体来说,我们考虑VGG风格的深度卷积网络(CIFAR 10上的VGG-19-Simonyan & Zisserman(2014))和残差网络(CIFAR 10上的Resnet-18-He et al.(2016))。5这些网络使用batchnorm,权重衰减,降低学习率计划和增强训练数据进行训练。我们继续为所有这些架构找到中奖彩票;然而,我们用于找到它们的方法,迭代修剪,对所使用的特定学习率敏感。在这些实验中,我们没有测量提前停止时间(对于这些较大的网络,这与学习率计划有关),而是在训练过程中的几个时刻绘制准确度,以说明准确度提高的相对速度。
全局修剪。在Lenet和Conv-2/4/6上,我们以相同的速率分别修剪每个层。对于Resnet-18和VGG-19,我们稍微修改了这个策略:我们在全局范围内修剪这些更深的网络,在所有卷积层中共同删除最低幅度的权重。在附录I.1中,我们发现全局修剪为Resnet-18和VGG-19识别出较小的中奖彩票。我们对这种行为的推测解释如下:对于这些更深层次的网络,某些层的参数远远多于其他层。例如,VGG-19的前两个卷积层有1728和36864个参数,而最后一个有235万个参数。当所有层都以相同的速率修剪时,这些较小的层成为瓶颈,阻止我们识别最小的可能中奖彩票。全局修剪可以避免这个陷阱。
VGG-19 我们研究了由Liu等人改编为CIFAR 10的变体VGG-19。(2019);我们使用相同的训练机制和超参数:160个历元(112,480次迭代),SGD动量(0.9),并在80和120个时期将学习率降低10倍。这个网络有两千万个参数。图7显示了在两个初始学习速率下对VGG-19进行迭代修剪和随机重新初始化的结果:0.1(用于Liu et al.(2019))和0.01。在较高的学习率,迭代修剪没有找到中奖的门票,性能并不比修剪网络随机重新初始化。然而,在较低的学习率下,通常的模式重新出现,当Pm ≥ 3.5%时,子网络保持在原始准确率的1个百分点以内。(They没有中奖的彩票,因为它们与原始的准确性不匹配。)当随机重新初始化时,子网络失去准确性,因为它们以与本文中其他实验相同的方式被修剪。尽管这些子网络在训练早期比未修剪的网络学习得更快(图7左),但由于初始学习率较低,这种准确性优势在训练后期会受到侵蚀。然而,这些子网络仍然比重新初始化时学习得更快。
为了弥补较低学习率的彩票行为与较高学习率的准确性优势之间的差距,我们探索了从0到初始学习率的线性学习率预热在k次迭代中的效果。在学习率为0.1的情况下,使用预热(k = 10000,绿色线)训练VGG-19将未修剪网络的测试准确度提高了约一个百分点。预热使得可以找到中奖彩票,当Pm ≥ 1.5%时超过该初始精度。
Resnet-18. Resnet-18(He等人,2016)是一个20层卷积网络,具有为CIFAR 10设计的剩余连接。它有271,000个参数。我们使用SGD和动量(0.9)训练网络30,000次迭代,在20,000和25,000次迭代时将学习率降低10倍。图8示出了在学习速率0.1下的迭代修剪和随机重新初始化的结果(在He等人中使用)。(2016))和0.01。这些结果在很大程度上反映了VGG的结果:迭代修剪在较低的学习速率而不是较高的学习速率找到获胜的票。在较低学习率下的最佳中奖票的准确率(当41.7% ≥ Pm ≥ 21.9%时为89.5%)福尔斯原始网络在较高学习率下的准确率(90.5%)。在较低的学习速率下,获胜的彩票最初学习得更快(图8的左图),但在训练后期以较高的学习速率福尔斯于未修剪的网络(右图)。用预热训练的获胜门票在较高的学习率下缩小了与未修剪网络的准确性差距,在Pm = 27.1%时,学习率为0.03(预热,k = 20000),达到90.5%的测试准确性。对于这些超参数,当Pm ≥ 11.8%时,我们仍然可以找到中奖彩票。然而,即使进行了热身,我们也无法找到超参数,从而可以在原始学习率0.1下识别中奖彩票。
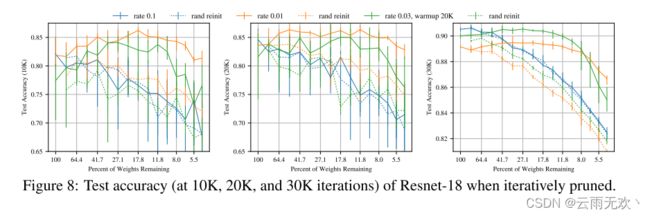
图8:迭代修剪时Resnet-18的测试精度(在10 K,20 K和30 K迭代时)。
5 DISCUSSION讨论
关于神经网络修剪的现有工作(例如,Han et al.(2015))证明了神经网络学习的函数通常可以用更少的参数来表示。修剪通常通过训练原始网络、移除连接和进一步微调来进行。实际上,初始训练初始化修剪网络的权重,以便它可以在微调期间孤立地学习。我们试图确定类似的稀疏网络是否可以从一开始就学习。我们发现,本文研究的架构可靠地包含这样的可训练的子网络,彩票假设提出,这种属性一般适用。我们的实证研究的存在和性质的中奖彩票邀请一些后续问题。
中奖票初始化的重要性。当随机重新初始化时,获胜的票学习得更慢,并且实现更低的测试准确性,这表明初始化对其成功很重要。这种行为的一个可能的解释是这些初始权重接近它们的最终值在最极端的情况下,它们已经被训练。然而,附录F中的实验显示了相反的情况,即中奖彩票的权重比其他权重移动得更远。这表明初始化的好处与优化算法、数据集和模型有关。例如,中奖彩票初始化可能落在损失景观的区域中,该区域特别适合于由所选择的优化算法进行优化。
Liu et al.(2019)发现,修剪后的网络在随机重新初始化时确实是可训练的,这似乎与传统观点和我们的随机重新初始化实验相矛盾。例如,在VGG-19(我们共享相同的设置)上,他们发现修剪高达80%并随机重新初始化的网络与原始网络的准确性相匹配。我们在图7中的实验证实了在该稀疏水平下的这些发现(低于Liu et al.不提供数据)。然而,在进一步修剪之后,初始化很重要:当VGG-19被修剪高达98.5%时,我们发现中奖彩票;当重新初始化时,这些票据达到低得多的准确度。我们假设-达到一定程度的稀疏性-高度过参数化的网络可以被成功地修剪、重新初始化和重新训练;然而,超过这一点,极度修剪的、不太严重的过参数化网络仅在偶然初始化的情况下保持准确性。
彩票结构的重要性。产生中奖票的初始化被安排在特定的稀疏架构中。由于我们通过大量使用训练数据来发现中奖彩票,因此我们假设中奖彩票的结构编码了一种针对手头学习任务定制的归纳偏差。Cohen & Shashua(2016)表明,嵌入深度网络结构中的归纳偏差决定了它可以比浅层网络更有效地分离参数的数据种类;尽管Cohen & Shashua(2016)专注于卷积网络的池化几何,但类似的效果可能与中奖彩票的结构有关,即使在严重修剪时也能学习。
改进的中奖彩票的推广。我们可靠地找到了泛化能力更好的中奖彩票,超过了原始网络的测试精度,同时匹配了其训练精度。测试精度随着我们的修剪而增加,然后降低,形成奥卡姆山(Rasmussen & Ghahramani,2001),其中原始的,过度参数化的模型具有太多的复杂性(可能是过度拟合),而极度修剪的模型太少。关于压缩和推广之间关系的传统观点是,紧凑的假设可以更好地推广(Rissanen,1986)。最近的理论工作显示了神经网络的类似联系,证明了可以进一步压缩的网络的更严格的泛化边界(Zhou et al.(2018)进行修剪/量化和Arora et al.(2018)的噪声鲁棒性)。彩票假说为这种关系提供了一个补充的视角,即更大的网络可能明确地包含更简单的表示。
神经网络优化的含义。中奖的彩票可以达到与原始的、未修剪的网络相当的精度,但参数要少得多。这一观察结果与最近关于过度参数化在神经网络训练中的作用的研究有关。例如,Du等人。(2019)证明了用SGD训练的充分过参数化的双层relu网络(具有固定大小的第二层)收敛到全局最优值。因此,一个关键问题是,中奖彩票的存在是否是SGD将神经网络优化到特定测试精度的必要条件或充分条件。我们推测(但没有经验表明),SGD寻找并训练一个初始化良好的子网络。按照这种逻辑,超参数化网络更容易训练,因为它们有更多的子网络组合,这些组合是潜在的中奖彩票。
6 LIMITATIONS AND FUTURE WORK局限性和未来工作
我们只考虑较小数据集(MNIST,CIFAR10)上以视觉为中心的分类任务。我们不研究更大的数据集(即Imagenet(Russakovsky et al.迭代修剪是计算密集型的,需要连续训练网络15次或更多次以进行多次试验。在未来的工作中,我们打算探索更有效的方法来寻找中奖彩票,这将使人们有可能在更多的资源密集型环境中研究彩票假说。
稀疏修剪是我们找到中奖彩票的唯一方法。尽管我们减少了参数计数,但由此产生的架构并没有针对现代库或硬件进行优化。在未来的工作中,我们打算从广泛的当代文献中研究其他修剪方法,如结构化修剪(这将产生针对当代硬件优化的网络)和非幅度修剪方法(这可以产生更小的中奖彩票或更早地找到它们)。
我们发现的中奖彩票具有初始化,允许它们在尺寸太小的情况下匹配未修剪网络的性能,而随机初始化的网络无法做到这一点。在未来的工作中,我们打算研究这些初始化的属性,与修剪网络架构的归纳偏差相一致,使这些网络特别擅长学习。
在更深层的网络(Resnet-18和VGG-19)上,迭代修剪无法找到中奖彩票,除非我们用学习率预热来训练网络。在未来的工作中,我们计划探索为什么预热是必要的,以及对我们识别中奖彩票的方案的其他改进是否可以避免这些超参数修改的需要。
7 RELATED WORK相关工作
在实践中,神经网络往往会被过度参数化。蒸馏(Ba & Caruana,2014;欣顿等人,2015)和修剪(LeCun等人,1990; Han等人,2015)依赖于可以在保持准确性的同时减少参数的事实。即使有足够的容量来记忆训练数据,网络也会自然地学习更简单的函数(Zhang et al.2016; Neyshabur等人,2014; Arpit等人,2017年)。当代经验(Bengio等人,2006;欣顿等人,2015; Zhang等人,2016)和图1表明,过参数化网络更容易训练。我们表明,密集的网络包含稀疏的子网络能够学习自己从原来的初始化。其他几个研究方向旨在训练小型或稀疏网络。
在训练之前。Squeezenet(Iandola等人,2016)和MobileNets(霍华德等人,2017)是专门设计的图像识别网络,比标准架构小一个数量级。Denil等人(2013)将权重矩阵表示为较低秩因子的乘积。Li等人(2018)将优化限制在参数空间的一个小的随机采样子空间(这意味着所有参数仍然可以更新);它们成功地在该限制下训练网络。我们表明,一个甚至不需要更新所有参数来优化网络,我们发现中奖票通过一个原则性的搜索过程,涉及修剪。我们对这类方法的贡献是证明稀疏的,可训练的网络存在于更大的网络中。
训练结束后。蒸馏(Ba & Caruana,2014;欣顿等人,2015)训练小型网络来模仿大型网络的行为;较小的网络更容易在此范例中训练。最近的修剪工作压缩大型模型以利用有限的资源(例如,在移动的设备上)。虽然修剪是我们实验的核心,但我们研究了为什么训练需要使修剪成为可能的过参数化网络。LeCun等.(1990)和Hassibi & Stork(1993)首先探索了基于二阶导数的剪枝。最近,Han et al.(2015)表明,基于每个权重幅度的修剪大大减少了图像识别网络的大小。Guo et al.(2016)恢复修剪的连接,因为它们再次变得相关。Han et al.(2017)和Jin et al.(2016)在修剪小权重并微调幸存权重后,恢复修剪的连接以增加网络容量。其他提出的修剪试探法包括基于激活的修剪(Hu等人,2016),冗余(Mariet & Sra,2016; Srinivas和Babu,2015 a)、每层二阶导数(Dong等人,2017)和能量/计算效率(Yang等人,2017)(例如,修剪卷积滤波器(Li等人,2016; Molchanov等人,2016; Luo等人,2017)或通道(He等人,2017))。Cohen等人(2016)观察到卷积滤波器对初始化敏感(“滤波器彩票”);在整个训练过程中,他们随机重新初始化不重要的过滤器
在训练的时候。Bellec等人(2018)使用稀疏网络进行训练,并使用新的随机连接替换达到零的权重。Srinivas等人(2017)和Louizos等人(2018)学习最小化非零参数数量的门控变量。Narang等人(2017)将基于幅度的修剪集成到训练中。Gal & Ghahramani(2016)表明,dropout近似于高斯过程中的贝叶斯推断。关于训练期间辍学学习辍学概率的贝叶斯观点(Gal等人,2017; Kingma等人,2015; Srinivas & Babu,2016)。学习按权重、按单位(Srinivas & Babu,2016)或自然结构化丢弃概率(Molchanov等人,2016)的技术。2017; Neklyudov等人,2017)或明确地(Louizos等人,2017; Srinivas & Babu,2015 b)在训练期间修剪和稀疏网络,因为某些权重的丢弃概率达到1。相比之下,我们至少训练网络一次以找到中奖彩票。这些技术也可能找到中奖彩票,或者通过引入稀疏性,可能与我们的方法有益地相互作用。