2022年亚太杯APMCM数学建模大赛E题有多少核弹可以摧毁地球求解全过程文档及程序
2022年亚太杯APMCM数学建模大赛
E题 有多少核弹可以摧毁地球
原题再现
1945年8月6日,第二次世界大战即将结束。为了尽快结束战争,美国在日本广岛投下了下一颗名为“小男孩”的原子弹。这样一颗原子弹在广岛炸死了20万人,广岛的所有建筑物都倒塌了。这是人类历史上第一次将原子弹付诸实践,也让许多人第一次意识到原子弹的可怕威力。
核武器是指与核反应有关的巨大致命武器,包括氢弹、原子弹、中子弹等。核武器是人类有史以来最强大的武器之一,经常让人想起毁灭天地的场景。原子弹的瞬间爆炸温度可以达到数千万度。原子弹的爆炸当量约为数万至数十万吨TNT当量。原子弹的爆炸及其辐射范围可以摧毁一座城市。
由于原子弹的可怕威力,许多国家希望用它来威慑其他国家,保护自己的国家免受外国入侵。二战后,世界各国开始疯狂研发制造原子弹,甚至制造出了“大伊万”等破坏性武器。
“大伊凡”是目前世界上已知威力最大的核弹,也就是苏联时期建造的“沙皇炸弹”。它不仅是世界上威力最大的核弹,也是最大的核弹。“沙皇炸弹”有多大?数据显示,它的长度为8米,直径为2.1米,重量高达27吨,设计TNT当量为50兆吨。苏联原计划设计相当于100兆吨的导弹,但由于破坏力太大,无法找到合适的试验场,因此功率降低了一半。即便如此,沙皇炸弹仍然是世界上最强大的核武器。“小男孩”的爆炸威力约为14000吨TNT当量,使广岛成为一片废墟,而“沙皇炸弹”的威力可与数十甚至数百名“小男孩“相媲美。“沙皇炸弹”在苏联新地岛试爆后,甚至在一些远至美国的州也探测到了5级左右的地震,导致欧亚大陆向南移动了9毫米。
许多人认为这些核武器可以毁灭地球好几次。事实真的是这样吗?就人类开发的核武器的威力而言,如果它们摧毁了地球,并不意味着它们可以把地球炸成碎片,而是意味着人类和地球上生物的生存环境已经被破坏。
APMCM组织委员会要求您的团队处理当前的报告和未来的核武器预测。他们提供了数据集2022_APMCM_E_data.csv来帮助您进行研究。请收集相应的数据,建立数学模型,并回答以下问题。
要求
1.基础数据分析
a) 哪些国家曾经拥有核武器?
b) 在过去20年中,哪个国家的核武器库存减少或增加最多?
c) 哪五年的核武器试验最多?
d) 在过去10年中,哪个国家在核武器研究方面最活跃?
e) 哪个国家从“不考虑核武器”到“拥有核武器”的转变最快?
2.预测核武器的数量
a) 根据所附数据或您收集的数据,建立一个数学模型来预测核武器的数量,并预测未来100年内拥有核武器的国家;
b) 预测未来100年核武器数量的变化趋势,2123年核武器总数,以及每个国家的核武器数量。
3.保护我们的星球
a) 建立核武器引爆位置的数学模型,计算出摧毁地球至少需要多少枚核弹?
b) 根据数学模型,核弹目前拥有的最大破坏力是多少?足以毁灭地球吗?
c) 为了保护地球和我们赖以生存的环境,世界核弹的总数应该限制在什么范围内,理论上已经拥有核武器的国家应该限制在哪些范围内?
4.准备一篇非技术性文章(最多1页)。请给联合国写一篇非技术性的文章(最多1页),解释你的团队的调查结果,并为所有国家提出一些建议。
整体求解过程概述(摘要)
核武器是人类历史上发展起来的最强大的武器,正是因为核武器的力量,各国才希望通过核武器的威慑作用来保护自己。核武器虽然威力巨大,但一旦爆炸,就会释放出巨大的能量,对生态环境造成严重破坏。
针对第一个问题,本文根据问题中各国核武器的相关数据进行了基础数据分析。首先,设想所有国家拥有的核武器的状况、储存的核武器数量和进行的核试验数量。使用python遍历相关数据,完成描述性统计分析。构建临界权重评分模型,选取7个指标对不同国家对核武器的态度进行评分,判断朝鲜是最积极的核武器国家。
对于第二个问题,为了预测未来核武器的数量和趋势,本文构建了一个基于ARIMA时间序列分析的预测模型。首先,对数据进行预处理,并进行ADF稳定性测试和白噪声测试。然后,我们对模型进行评估和测试,以找到最合适的超级参数来引入预测模型。接下来,引入了各国核武器拥有状况和储存情况的数据,并进行了预测和数值分析。最后,我们得出的结论是,2123年的核武器总数将达到2152件,每个国家的核武器数量都将达到2150件。
对于第三个问题,本文给出了破坏地球的两个定义。一种是用核武器把地球炸成碎片。通过对地球引力结合能和核武器爆炸能力的计算,发现目前核武器的数量远远不够。第二个定义是用核武器及其辐射摧毁地球上的大多数生物。我们将世界地图转换为灰度图像,建立DBSCAN聚类模型,并设置核武器的爆炸半径和传播半径,以获得最终摧毁地球的核弹总数。
针对第四个问题,我们向联合国提交了一篇非技术性文章,用之前的模型分析结果解释了我们团队对核武器的看法和相关发现,并为所有国家提出了几点建议。我们认为,发展核武器的最终目标是消除核武器。
模型假设:
为了简化建模,我们做了以下假设:
1) 假设收集的数据忽略了信息披露程度的影响。
2) 假设地球被破坏的标准不是地球破碎,而是地球表面的生态环境受到严重破坏。
3) 本文对核武器数量的分析仅限于收集到的数据中的国家,其他国家没有进行分析。
问题分析:
问题一分析
问题1的主要目的是对数据进行基本分析,其中包含五个小问题:
问题a:数据中的状态=3(国家地位核武器.csv)表明该国当年拥有核武器。因此,通过遍历数据,我们可以发现,状态=3的国家就是曾经拥有核武器的国家。
问题b:为了更准确地分析问题,我们将首先可视化核武器库存数据(nuclear-chirf-stock.csv),然后分析哪个国家的核武器库存减少或增加最多。由于存在不同的措施,因此开发了两种方法来更全面地分析问题。第一个是每个国家最后一年的核武器数量与最早一年的数量之间的差异。第二种方法是观察每个国家核武器数量的差异。然后对两种方法的结果进行了比较。如果它们是一致的,则可以更好地解释结果的准确性。
问题c:首先,每年的核武器试验次数是通过处理核武器试验的次数得出的。然后,计算每个“5年”内发生的核武器试验次数,经过比较可以得出核武器试验最多的5年。
问题d:通过建立CRITIC模型,结合核武器试验数据,对每个国家的核武器研究活动进行评分,从而得出核武器研究最活跃的国家。
问题e:我们将分析选定的曾经拥有核武器的国家,减去状态=3的最早年份和状态=0的最晚年份,得出这些国家从“不考虑核武器”变为“拥有核武器”的时间间隔,然后进行比较,得出结果。
问题二分析
问题二的主要目的是预测核武器,包括预测未来的核武器国家和预测未来核武器的数量。根据数据分析,我们选择建立基于ARIMA的核武器数量预测模型,建立流程图如下
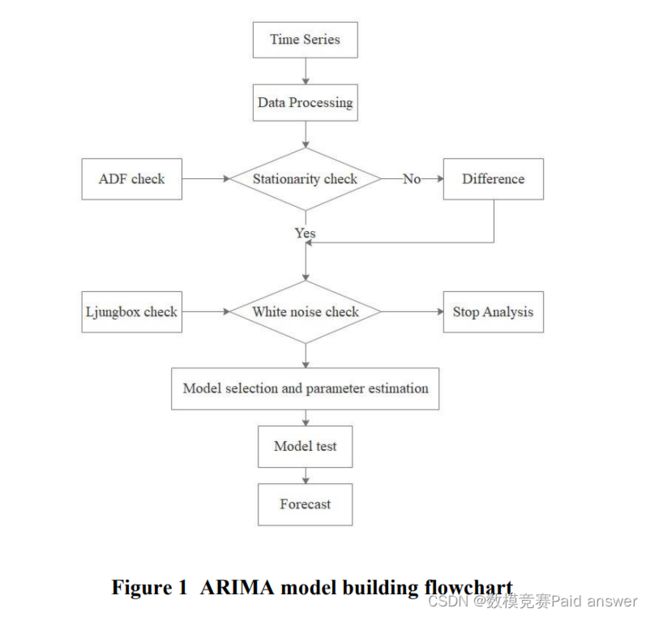
从图中可以看出,我们需要首先对时间序列数据进行预处理。由于ARIMA模型建立的先决条件要求,我们需要进行平稳性测试和白噪声测试。在通过平稳性测试和白噪声测试后,进行了模型估计和测试,最终可以成功地建立ARIMA模型。
建立基于ARIMA的核武器数量预测模型,预测未来100年拥有核武器的国家和核武器数量的变化趋势,预测2123年世界核武器总数和每个国家的核武器数。
问题三分析
破坏地球有不同的定义。为了更全面地分析这个问题,我们建立了两个破坏地球的定义。第一个定义是撕裂地球,并在第一个定义的基础上进行了适当的分析。第二个定义是对地球表面的生态环境造成严重破坏。基于这一定义,我们将通过以人口密度为标准的DBSCAN聚类算法建立核武器的爆炸位置模型,然后分析和解决问题,判断摧毁地球需要多少核武器,并计算世界上核武器的极限。
问题四分析
根据上述解决方案的结果和我们的调查结果,我们将向联合国撰写一篇非技术性文章,为所有国家提出建议。
模型的建立与求解整体论文缩略图


全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
部分程序如下:
import pandas as pd
def CountriesThatHaveNuclearBombs():
data = pd.read_csv('../data/country-position-nuclear-weapons.csv').values.tolist()
countries = {}
for i in data:
if i[3] == 3:
countries[i[0]] = i[2]
return countries
if __name__ == '__main__':
res = CountriesThatHaveNuclearBombs()
for item in res:
print(item + ' has nuclear until ' + str(res[item]) + ' year')
import pandas as pd
import matplotlib.pyplot as plt
def draw(countries, years, datas):
plt.title('Nuclear Growth')
plt.xlabel('years')
plt.ylabel('num')
for data in datas:
plt.plot(years, data, marker='o', markersize=3)
plt.legend(countries)
plt.show()
if __name__ == '__main__':
data = pd.read_csv('../data/nuclear-warhead-stockpiles.csv').values.tolist()
datas=[]
countries = []
temp = []
years=[]
for i in range(2003, 2023):
years.append(i)
for i in data:
countries.append(i[0])
if i[2] > 2002:
temp.append(i[3])
if i[2] == 2022:
datas.append(temp)
temp = []
countries_data = list(set(countries))
countries_data.sort(key=countries.index)
draw(countries_data,years,datas)
del countries_data[-4]
del countries_data[-1]
del datas[-4]
del datas[-1]
draw(countries_data,years,datas)
import pandas as pd
from matplotlib import pyplot as plt
import plotly.express as px
from matplotlib import pyplot as plt
import seaborn as sns
import statsmodels.api as sm
data = pd.read_csv('../data/number-of-nuclear-weapons-tests.csv').values.tolist()
res = []
temp = []
years = []
for i in range(1945, 2020):
years.append(i)
# print(years)
for i in years:
for item in data:
if item[2] == i:
temp.append(item[3])
num = 0
for j in temp:
num += j
res.append(num)
num = 0
temp = []
print(res)
res = pd.DataFrame(res, columns=['num'])
# res.index=pd.Index(sm.tsa.datetools.dates_from_range('1945', '2019'))
print(res)
fiveyears = []
fiveyearsnum = []
print(len(res.index))
for index in range(0, len(res.index) - 4):
fiveyearsnum.append(res[index:index + 5].values.transpose().tolist()[0][0] +
res[index:index + 5].values.transpose().tolist()[0][
1] + res[index:index + 5].values.transpose().tolist()[0][2] + \
res[index:index + 5].values.transpose().tolist()[0][3] + res[index:index +
5].values.transpose().tolist()[0][
4])
# +'to'+str(i+4)
[fiveyears.append(str(i)) for i in range(1945,2016)]
print(fiveyears)
print(fiveyearsnum)
plt.figure(figsize=(15, 10))
plt.plot(fiveyears,fiveyearsnum)
plt.xticks(rotation=90)
# Control chart notes
plt.annotate('The Max value is %d in %s' %
(max(fiveyearsnum),fiveyears[fiveyearsnum.index(max(fiveyearsnum))]), # Control the
content of comments
xy=(fiveyearsnum.index(max(fiveyearsnum)), max(fiveyearsnum)), #
The point to comment, y1.index(max(y1)): The index of the maximum value in y1,
# max(y1):The maximum value in y1
xytext=(20, 400), # The location of the comment display
fontsize=30,
arrowprops=dict(facecolor='black', width=0.5, headwidth=5) # Control
arrow color, width, arrow width
# arrowprops=dict(arrowstyle=''<->'') # Try this
)
plt.show()