Spark-GraphFrames入门使用示例
Spark-GraphFrames入门使用示例
- GraphFrames简介
-
- GraphFrames库的优势
- 使用GraphFrames库
-
- 使用图例
- 创建GraphFrame实例
- 视图和图操作
-
- GraphFrame提供四种视图:返回类型都是DataFrame
- 通过GraphFrame提供的三个属性:degrees、inDegrees、 outDegrees可以获得顶点的度、入度和出度。
- 模式发现
-
- 在这里插入图片描述
- 加载和保存图
-
- 图保存
- 图加载
GraphFrames简介
GraphFrames是Apache Spark上的图处理框架。
- Pregel Google:内部的分布 式图计算框架
- Giraph :运行在Hadoop之上的类 Pregel图计算框架
- PowerGraph: 一个支持异步执行方式、利用 共享内存的并行图计算框架
- Graphx: Spark平台下,面向大规 模图计算的组件
GraphFrames库的优势
- 将Spark中的Graph算法统一到 DataFrame接口的Graph操作API接口
- 强力的查询:项目托管在Github上,它基于DataFrame构建 [托管到GitHub上的好处,懂得都懂]
- 基于Spark平台的并行图计算库,受益于DataFrame的高性能和可拓展性
- 多语言支持:支持的语言包括Scala、Java、Python
- 保存和载入图模型:GraphFrames完全支持DataFrame结构的数据源,允许使用熟悉的Parquet、JSON、和CSV读写图。
使用GraphFrames库
目前博主知道的三种方式是
1.目前GraphFrames库还没有并入Spark项目中,使用该库时,要安装GraphFrames包:
$pyspark --packages graphframes:graphframes:0.5.0-spark2.1-s_2.11
2.使用SparkConf的spark.jars.packages属性指定依赖包:
from pyspark import SparkConf
conf = SparkConf().set('spark.jars.packages'
,'graphframes:graphframes:0.5.0-spark2.1-s_2.11')
3.在SparkSession中配置:(Spark2.x版本)
from pyspark.sql import SparkSession
spark = SparkSession.builder.config('spark.jars.packages' ,'graphframes:graphframes:0.5.0-spark2.1-s_2.11') .getOrCreate()
使用图例
博主使用的就是第一种,这里附上图例
下图是安装好之后的使用,没有显示下包的过程。
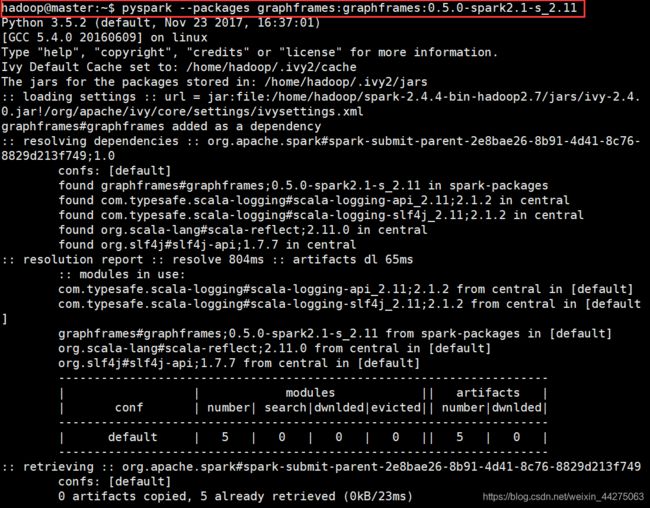
具体下包的过程图是这样的,嗯一共五个modules,其中scala-lang是需要较长时间的,请忽略本人的渣渣网速,诶

最后再温馨提示一下新手小白,第三种配置需要注意spark的版本,1.0的版本的话可能会出现报错现象,继续往下演示。
创建GraphFrame实例
GraphFrame是GraphFrames API的核心抽象编程模型,是图的抽象。
- 顶点DataFrame:必须包含列名为“id”的列,作为顶点的唯一标识d表示顶点V队列
G∈ - 边DataFrame:必须包含列名为“src”和“dst”的列,保存头和尾的唯一标识id
>>> from graphframes import *
>>> vertices = spark.createDataFrame([ ("a", "Alice", 34),("b", "Bob", 36)] , ["id", "name", "age"])
>>> edges = spark.createDataFrame([ ("a", "b", "friend")] , ["src", "dst", "relationship"])
>>> from graphframes import GraphFrame
>>> graph = GraphFrame(vertices,edges)
图例如下:

这里习惯性的查看一下具体的方法名有哪些,有兴趣的童鞋最好研读一下文档或者案例
GraphFrames用户指南-Python — Databricks文档.
视图和图操作
GraphFrame提供四种视图:返回类型都是DataFrame
- 顶点表视图:
graph.Vertices.show() - 边表视图:
graph.edges.show() - 三元组(Triplet)视图:
graph.triplets.show() - 模式(Pattern)视图

对应的代码片如下:
>> graph.vertices.show()
+---+-----+---+
| id| name|age|
+---+-----+---+
| a|Alice| 34|
| b| Bob| 36|
+---+-----+---+
#顶点表视图
>> graph.edges.show()
+---+---+------------+
|src|dst|relationship|
+---+---+------------+
| a| b| friend|
+---+---+------------+
#边表视图
>> graph.triplets.show()
+--------------+--------------+-----------+
| src| edge| dst|
+--------------+--------------+-----------+
|[a, Alice, 34]|[a, b, friend]|[b, Bob, 36]|
+--------------+--------------+-----------+
#三元组(Triplet)视图
通过GraphFrame提供的三个属性:degrees、inDegrees、 outDegrees可以获得顶点的度、入度和出度。
代码片如下:
>>> graph.degrees.show()
+---+------+
| id|degree|
+---+------+
| b| 1|
| a| 1|
+---+------+
#degrees顶点的度
>> graph.inDegrees.show()
+---+--------+
| id|inDegree|
+---+--------+
| b| 1|
+---+--------+
#inDegrees顶点的入度
>> graph.outDegrees.show()
+---+---------+
| id|outDegree|
+---+---------+
| a| 1|
+---+---------+
#outDegrees顶点的出度
模式发现
采用形如“(a)-[e]->(b)”的模式描述有向边
>>> motifs = graph.find("(a)-[e]->(b)")
>>> motifs.show()

模式视图是DataFrame类型的,同样可以进一步进行查询、过滤和统计操作。
>>> motifs.filter("b.age > 30").show()
这里由于示例的图比较简单,所以过滤出来的效果跟find()的结果一样,可以尝试构建更复杂的有向图、无向图、二分图、多重图等尝试进行查询操作,更进一步的理解和掌握。

加载和保存图
图保存
图可以以多种格式进行保存,例如:
csv/json/parquet/text
想研究的童鞋可以看看write下的一些方法

- 示例代码片如下:
>>> graph.vertices.write.parquet("hdfs://xdata-m1:8020/user/ua50/vertices")
>>> graph.edges.write.parquet("hdfs://xdata-m1:8020/user/ua50/edges")
#注意这个保存路径是hdfs的
博主演示的是保存在linux下的,注意图保存的是文件夹,如下图:
- parquet的图保存


- json的图保存,这个格式比较便于查看,请看下图
graph.vertices.write.json("/home/hadoop/spark-graphX/vertices_json")
>>>ls
>>>part-00000-7a9d9acc-50a6-43ec-8b4b-3f29e8546a98-c000.json _SUCCESS
具体查看的效果是这样的,是不是比较简洁易读:

图加载
>>> v = spark.read.parquet("hdfs://xdata-m1:8020/user/ua50/vertices")
>>> e = spark.read.parquet("hdfs://xdata-m1:8020/user/ua50/edges")
>>> newGraph=GraphFrame(v, e)
图加载可以理解为对图的顶点和边的持久化,可以随时调用和加载。
Spark-GraphX图计算入门示例到此尾声,如有纰漏,欢迎各位指出~