Linux | 功能场景化Linux操作备忘录
Linux | 功能场景化Linux操作备忘录
- shell脚本中使脚本命令等待执行
-
- 场景复现:
- `sleep`命令详解:
- 使用方式:
- 将文件从UTF-8转编码成GBK,并输出文件
-
- 场景复现:
- `iconv`命令详解
- `awk`命令详解
-
- 使用方式
- 使用示例
- 长期使用后,磁盘内存不足,快速定位工作目录下的大文件
-
- 场景复现:
- `du`命令详解
- `sort`命令详解
- 删除目录下所有后缀为.txt的文件,且文件数量巨大
-
- 场景复现:
- `xargs`命令详解
- 扩展
- 将结果文件按指定列重排序
-
- 场景复现:
- MPP数据库中文显示异常
-
- 场景复现:
- 问题分析:
- 问题小结:
- 文件读写权限修改
-
- 场景复现:
- 问题分析:
- 问题小结:
- clickhouse客户端执行sql文件
-
- 问题复现:
- 问题分析:
shell脚本中使脚本命令等待执行
场景复现:
sleep命令详解:
- [功能]:Linux Shell脚本中执行下一条命令之前等待设置,可以调用
sleep、usleep sleep [--help] [--version] number[smhd]- [描述]:
–help : 显示辅助讯息
–version : 显示版本编号
number : 时间长度,后面可接 s、m、h 或 d
其中 s 为秒,m 为 分钟,h 为小时,d 为日数
sleep 1 等待1秒,默认单位:秒
usleep 1000 等待1000微秒,默认单位:微秒
使用方式:
- sleep 1s 表示延迟一秒
- sleep 1m 表示延迟一分钟
- sleep 1h 表示延迟一小时
- sleep 1d 表示延迟一天
将文件从UTF-8转编码成GBK,并输出文件
场景复现:
数据开发过程中,有一结果文件编码为utf-8,需要转为GBK编码并重定向输出新文件。
- Linux代码模板
iconv -f UTF-8 -t GBK RESULT_DATA_utf8.txt -o RESULT_DATA_gbk.txt
awk '{print $0"\r"}' RESULT_DATA_gbk.txt > RESULT_DATA_gbk1.txt
iconv命令详解
-
[功能]:对于给定文件把它的内容从一种编码转换成另一种编码。
-
[描述]:
-f encoding :把字符从encoding编码开始转换。
-t encoding :把字符转换到encoding编码。
-l :列出已知的编码字符集合
-o file :指定输出文件
-c :忽略输出的非法字符
-s :禁止警告信息,但不是错误信息
--verbose :显示进度信息
-f和-t所能指定的合法字符在-l选项的命令里面都列出来了。
awk命令详解
awk是一个强大的文本分析工具,简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
使用方式
awk '{pattern + action}' {filenames}
其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。(类似的像Python中的格式化函数str.format(),但是功能和用途相较下,个人认为比Python中处理更强大)
此处附上str.format()的菜鸟教程链接:Python format 格式化函数
使用示例
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
[root@www ~]# last -n 5 <==仅取出前五行
root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in
root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41)
root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48)
dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00)
root tty1 Fri Sep 5 14:09 - 14:10 (00:01)
awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 “[tab]键”,所以$1表示登录用户,$3表示登录用户ip,以此类推。
# 显示/etc/passwd的账户
cat /etc/passwd |awk -F ':' '{print $1}'
root
daemon
bin
sys
这种是awk+action的示例,每行都会执行action{print $1}。
-F指定域分隔符为':'。
# 搜索/etc/passwd有root关键字的所有行
awk -F: '/root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
# 搜索/etc/passwd有root关键字的所有行,并显示对应的shell
awk -F: '/root/{print $7}' /etc/passwd
/bin/bash
这里指定了action{print $7},输出的是以:分隔的第7个域。
长期使用后,磁盘内存不足,快速定位工作目录下的大文件
场景复现:
长期进行数据开发和数据分析,不可避免的会产生很多的文件,有些在情景使用完之后,未能及时清理掉,就会占用磁盘内存,久而久之,有限对的磁盘必然会出现内存不足的情况,需要我们及时定位大文件,清理内存,确保系统正常使用。
- Linux代码模板
# 显示占磁盘内存最大的10个文件
du -a | sort -n -r | head -n 10
#查看当前路径下1000M以上文件
find ./ -type f -size +1000M -print0 | xargs -0 du -h | sort -nr
du命令详解
-
[功能]:du命令用来查看目录或文件所占用磁盘空间的大小。常用选项组合为:du -sh
-
[描述] :
-h:以人类可读的方式显示
-a:显示目录占用的磁盘空间大小,还要显示其下目录和文件占用磁盘空间的大小
-s:显示目录占用的磁盘空间大小,不要显示其下子目录和文件占用的磁盘空间大小
-c:显示几个目录或文件占用的磁盘空间大小,还要统计它们的总和
--apparent-size:显示目录或文件自身的大小
-l :统计硬链接占用磁盘空间的大小
-L:统计符号链接所指向的文件占用的磁盘空间大小 -
常见使用:
du -h:以人类能看懂的方式查看目录或文件所占用磁盘空间的大小。
du -a:使用此选项时,显示目录和目录下子目录和文件占用磁盘空间的大小。
du -hc:查看目录或文件所占用磁盘空间的大小,并统计总和
sort命令详解
- [功能]:sort 可针对文本文件的内容,以行为单位来排序。
- [描述] :(仅列出常用的参数,详细见菜鸟教程 | Linux sort 命令)
-n 依照数值的大小排序。
-r 以相反的顺序来排序。
-u 意味着是唯一的(unique),输出的结果是去完重了的。
-o<输出文件> 将排序后的结果存入指定的文件。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
[-k field1[,field2]] 按指定的列进行排序。
file:多个文件一起排序,要使用空格分隔。 - 常用的是:
sort -nr和sort -r,两者区别为:sort -nr按数字降序排序,sort -r按字符进行排序
删除目录下所有后缀为.txt的文件,且文件数量巨大
场景复现:
在某一工作目录下,有.jpg文件和.txt文件,由于测试数据有误,需要删除一批次程序输出的错误txt数据。
# 用 rm 删除太多的文件时候,可能得到一个错误信息:/bin/rm Argument list too long.
#用 find | xargs 组合完美解决:
find . -type f -name "*.txt" -print0 | xargs -0 rm -f
xargs命令详解
- [功能]:
1.xargs(英文全拼: eXtended ARGuments)是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。
2.xargs 是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令。 - [描述] :仅列出常用的参数,详细见菜鸟教程 | Linux xargs 命令)
-n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。
-t 表示先打印命令,然后再执行。
-i 或者是-I,这得看linux支持了,将xargs的每项名称,一般是一行一行赋值给 {},可以用 {} 代替。
-d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分隔符。
扩展
类似操作还有:
- 复制所有图片文件到 /data/images 目录下:
ls *.jpg | xargs -n1 -I {} cp {} /data/images
- 查找所有的 log 文件,并且将它们压缩打包
find ./logs/ -type f -name "*.log" -print | xargs tar -czvf images.tar.gz
将结果文件按指定列重排序
场景复现:
有一份文件导入后,需要重新按第三列字段进行重新排序并输出成新文件,字段分隔符为竖线。
sort -t -k按指定字段排序
sort -t : -k n 表示以:作为字段分隔符,按照第n个字段排序
# 先查看排序结果的前10行,竖线需要用反斜杠转义
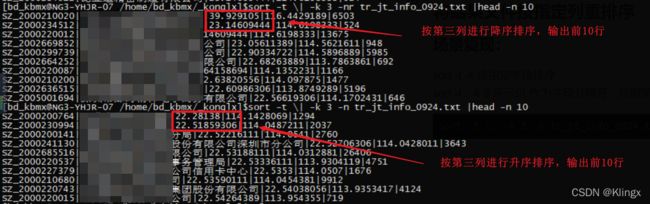
sort -t \| -k 3 -nr tr_jt_info_0924.txt | head -n 10
# 查看无误后,再对数据进行排序输出(多种实现方式,第二种标准错误与标准输出一起更好)
sort -t \| -k 3 -nr tr_jt_info_0924.txt -o tr_jt_info_0924_sort.txt
sort -t \| -k 3 -nr tr_jt_info_0924.txt > tr_jt_info_0924_sort.txt 2>&1
MPP数据库中文显示异常
场景复现:
在新配置的机器上,测试连接PostgreSQL,查询表列名信息时,出现中文显示异常情况。
问题分析:
1.中文编码问题,首先想到的是编码问题,会话使用的是SecureCRT,我们先在会话选项>>外观>>字符编码中查看会话的字符编码是什么,可以看到当前编码为GB2312

2.接着我们进入MPP库中,查看报错提示:ERROR: character with byte sequence 0xe7 0x99 0xbb in encoding "UTF8" 报错提示很明显,编码不一致,我们需要统一字符编码为GB2312。
[user@SSDSJ-ETL11 ~]$ sh gompp_sz.sh
Password for user szdm:
\encoding GBK
psql (9.6.23, server 9.4.24)
Type "help" for help.
szdm=> \encoding GBK
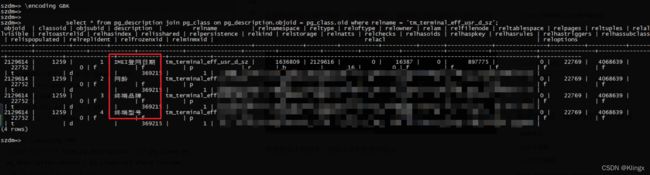
szdm=> select * from pg_description join pg_class on pg_description.objoid = pg_class.oid where relname = 'tm_terminal_eff_usr_d_sz';
发现查询不报错了,但是中文不能正常显示,按理说正常显示应该是这样的:
3.最后我们继续排查,发现会话的终端设置出了问题,会话选项>>仿真>>终端,机器的终端为VT100,而CRT中我们仿真的终端为Linux,需要修改终端。
# 查看Linux的终端类型
[user@SSDSJ-ETL11 ~]$ set | grep TERM
TERM=vt100

问题小结:
有针对的基于报错日志提示,定位问题可能出现的地方,同时需要回想正常时候前,有哪些变更设置或变量的操作,问题往往就出现在这些操作上。
文件读写权限修改
场景复现:
在项目中,需要修改对应脚本的内容,需要先修改读写权限,修改完成后恢复原先的读写权限。
问题分析:
针对批量的文件使用chmod命令对文件进行读写权限的修改。
- 常见的操作:
chmod 777 file_name # 将文件设置为所有用户可读写权限
chmod 664 file_name # 将文件设置为其他用户读权限,所有者和群组读写权限
问题小结:
读写权限的修改,主要是操作的规范,防止对文件进行误操作。因此常用的命令可以编辑成快捷方式快速调取。
clickhouse客户端执行sql文件
问题复现:
有一sql语句,由于长度过长无法在客户端中输入执行,故需打包成sql文件,以文件方式进行执行并输出结果。
问题分析:
熟悉clickhouse-client的参数,执行sql文件。
具体示例如下:
clickhouse-client --host 127.0.0.1 --user database --password password --query="$(cat /usr/local/app/filename.sql)"