PyTorch相关笔记(不断补充)
文章目录
- Mac M1环境安装参考文章
- 环境安装成功测试代码
- 关于MPS
- PyTorch中linspace的详细用法
- torch.randn()
- torch.sin()
- Python中item()和items()的用法
-
- item()
- items()
- PyTorch之torch.utils.data.DataLoader详解
-
- 参数说明
- 好处
- 注意
- 实例
-
- 实例1 BATCH_SIZE 刚好整除数据量
- 实例2 BATCH_SIZE 不整除数据量:会输出余下所有数据
- 关于PyTorch中的zero_grad()函数
- torch.clamp()
- numpy.transpose(images, (1,2,0))
- torch.max()
-
- torch.max(input, dim)函数
- 准确率计算
- torch.eye()函数
- torch.mul()、torch.mm()、torch.dot()和torch.mv()之间的区别
- torch.rand()
- torch.randn()
- torch.normal()
- torch.linespace()
- torch.argsort()—输出值为索引
- Pytorch关于requires_grad_(True)的理解
- 问题: grad can be implicitly created only for scalar outputs
- transforms.Normalize
- cifar10数据集_提取torchvision.datasets.CIFAR10中的图像及标签
- argparse基本用法
- tensor.copy_()
- [Python dict() 函数](https://www.runoob.com/python/python-func-dict.html)
- 什么是状态字典:state_dict?
- transform.ToTensor(), transform.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))作用
- torchvision.transforms 数据预处理:Normalize()
-
- 1、Normalize() 的作用
-
- 1.1 Normalize() 的源码
- 1.2 代码示例
- 2、ToTensor() 和 Normalize() 的结合使用
- 关于“shape”和“ndim”的一些点
- PyTorch保存与加载模型
- 代码“with torch.set_grad_enabled(False):”的作用
Mac M1环境安装参考文章
- Installing PyTorch on Apple M1 chip with GPU Acceleration
注:用pip命令安装torch

- MacBook M1配置 Pytorch(主要关注这里面的numpy重装)
- Mac M1芯片安装miniAnaconda、Jupyter、TensorFlow环境(主要关注这里面的给Jupyter添加内核步骤)
环境安装成功测试代码
import torch
import math
dtype = torch.float
device = torch.device("mps")
# Create random input and output data
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x) # 返回一个新张量,包含输入张量x中的每个元素的正弦
# Randomly initialize weights
a = torch.randn((), device=device, dtype=dtype)
b = torch.randn((), device=device, dtype=dtype)
c = torch.randn((), device=device, dtype=dtype)
d = torch.randn((), device=device, dtype=dtype)
learning_rate = 1e-6
for t in range(2000):
# Forward pass: compute predicted y
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Compute and print loss
loss = (y_pred - y).pow(2).sum().item()
if t % 100 == 99:
print(t, loss)
# Backprop to compute gradients of a, b, c, d with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_a = grad_y_pred.sum()
grad_b = (grad_y_pred * x).sum()
grad_c = (grad_y_pred * x ** 2).sum()
grad_d = (grad_y_pred * x ** 3).sum()
# Update weights using gradient descent
a -= learning_rate * grad_a
b -= learning_rate * grad_b
c -= learning_rate * grad_c
d -= learning_rate * grad_d
print(f'Result: y = {a.item()} + {b.item()} x + {c.item()} x^2 + {d.item()} x^3')
相关解读见下面几个点
关于MPS
苹果有自己的一套GPU实现API Metal。而Pytorch此次的加速就是基于Metal。具体来说,使用苹果的Metal Performance Shaders (MPS) 作为PyTorch的后端,可以实现加速GPU训练。MPS后端扩展了PyTorch框架,提供了在Mac上设置和运行操作的脚本和功能。MPS通过针对每个Metal GPU系列的独特特性进行微调的内核来优化计算性能。新设备在MPS图形框架和MPS提供的调整内核上映射机器学习计算图形和基元。
PyTorch中linspace的详细用法
“linspace”是“linear space”的缩写,中文含义为“线性等分向量”、“线性平分矢量”、“线性平分向量”。
linspace()函数详细参数为:
函数的作用是: 返回一个一维的tensor(张量),这个张量包含了从start到end(包括端点)的等距的steps个数据点
torch.linspace(start, end, steps=100, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
常用的几个参数含义:
start:开始值;
end:结束值;
steps:分割的点数,默认是100;
dtype:返回值(张量)的数据类型
函数的作用是: 返回一个一维的tensor(张量),这个张量包含了从start到end(包括端点)的等距的steps个数据点
示例:
import torch
print(torch.linspace(3,10,5))
#输出: tensor([ 3.0000, 4.7500, 6.5000, 8.2500, 10.0000])
type=torch.float
print(torch.linspace(-10,10,steps=6,dtype=type))
#输出: tensor([-10., -6., -2., 2., 6., 10.])
torch.linspace(-10, 10, steps=21,dtype=type)
#输出: tensor([-10., -9., -8., -7., -6., -5., -4., -3., -2., -1., 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
torch.randn()
有时我们想通过从某个特定的概率分布中随机采样来得到张量中每个元素的值。例如,当我们构造数组来作为神经网络中的参数时,我们通常会随机初始化参数的值。以下代码创建一个形状为(3, 4)的张量。其中的每个元素都从均值为0、标准差为1的标准高斯分布(正态分布)中随机采样
torch.randn(3, 4)
输出:
tensor([[-0.5582, -0.0443, 1.6146, 0.6003],
[-1.7652, 1.3074, 0.5233, 1.4372],
[ 0.2452, 2.2281, 1.3483, 0.1783]])
torch.sin()
函数说明:
返回一个新张量,包含输入input张量每个元素的正弦。
torch.sin(input, out=None) → Tensor
参数:
input (Tensor) – 输入张量
out (Tensor, optional) – 输出张量
示例:
>>> a = torch.randn(4)
>>> a
-0.6366
0.2718
0.4469
1.3122
[torch.FloatTensor of size 4]
>>> torch.sin(a)
-0.5944
0.2684
0.4322
0.9667
[torch.FloatTensor of size 4]
Python中item()和items()的用法
item()
item()的作用是取出单元素张量的元素值并返回该值,保持该元素类型不变。
听起来和使用索引来取值的作用好像一样,接下来我们看一看使用两种方法取元素值的区别:
首先定义一个张量:

1、直接使用索引取值:

2、使用item()取出

由此可以看出使用item()函数取出的元素值的精度更高,所以在求损失函数等时我们一般用item()
items()
items()的作用是把字典中的每对key和value组成一个元组,并把这些元祖放在列表中返回。
举个例子:
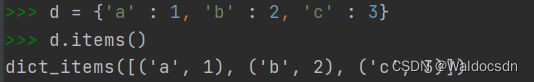
PyTorch之torch.utils.data.DataLoader详解

参数说明
- dataset: 输入的数据集
- batch_size(数据类型:int)
批训练数据量的大小,根据具体情况设置即可(默认:1)。PyTorch训练模型时调用数据不是一行一行进行的(这样太没效率),而是一捆一捆来的。这里就是定义每次喂给神经网络多少行数据,如果设置成1,那就是一行一行进行。每次是随机读取大小为batch_size。如果dataset中的数据个数不是batch_size的整数倍,这最后一次把剩余的数据全部输出。若想把剩下的不足batch size个的数据丢弃,则将drop_last设置为True,会将多出来不足一个batch的数据丢弃。 - shuffle(数据类型:bool)
洗牌。默认设置为False。在每次迭代训练时是否将数据洗牌,默认设置是False。将输入数据的顺序打乱,是为了使数据更有独立性,但如果数据是有序列特征的,就不要设置成True了。 - collate_fn:(数据类型 callable,没见过的类型)
将一小段数据合并成数据列表,默认设置是False。如果设置成True,系统会在返回前会将张量数据(Tensors)复制到CUDA内存中。 - batch_sampler:(数据类型 Sampler)
批量采样,默认设置为None。但每次返回的是一批数据的索引(注意:不是数据)。其和batch_size、shuffle 、sampler and drop_last参数是不兼容的。我想,应该是每次输入网络的数据是随机采样模式,这样能使数据更具有独立性质。所以,它和一捆一捆按顺序输入,数据洗牌,数据采样,等模式是不兼容的。 - sampler:(数据类型 Sampler)
采样,默认设置为None。根据定义的策略从数据集中采样输入。如果定义采样规则,则洗牌(shuffle)设置必须为False。 - num_workers:(数据类型 Int)
工作者数量,默认是0。使用多少个子进程来导入数据。设置为0,就是使用主进程来导入数据。注意:这个数字必须是大于等于0的,负数估计会出错。 - pin_memory:(数据类型 bool)
内存寄存,默认为False。在数据返回前,是否将数据复制到CUDA内存中。 - drop_last:(数据类型 bool)
丢弃最后数据,默认为False。设置了 batch_size 的数目后,最后一批数据未必是设置的数目,有可能会小些。这时你是否需要丢弃这批数据。 - timeout:(数据类型 numeric)
超时,默认为0。是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。 所以,数值必须大于等于0。 - worker_init_fn:(数据类型 callable,没见过的类型)
子进程导入模式,默认为Noun。在数据导入前和步长结束后,根据工作子进程的ID逐个按顺序导入数据。
好处
torch.utils.data.DataLoader 主要是对数据进行 batch 的划分。在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。就是做一个数据的初始化。使用DataLoader的好处是,可以快速的迭代数据。用于生成迭代数据非常方便。
注意
除此之外,特别要注意的是输入进函数的数据一定得是可迭代的。如果是自定的数据集的话可以在定义类中用def__len__、def__getitem__定义。
实例
实例1 BATCH_SIZE 刚好整除数据量
"""
批训练,把数据变成一小批一小批数据进行训练。
DataLoader就是用来包装所使用的数据,每次抛出一批数据
"""
import torch
import torch.utils.data as Data
BATCH_SIZE = 5 # 批训练的数据个数
x = torch.linspace(1, 10, 10) # 训练数据
print(x)
y = torch.linspace(10, 1, 10) # 标签
print(y)
# 把数据放在数据库中
torch_dataset = Data.TensorDataset(x, y) # 对给定的 tensor 数据,将他们包装成 dataset
loader = Data.DataLoader(
# 从数据库中每次抽出batch size个样本
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
def show_batch():
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
# training
print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y))
show_batch()
输出结果:
tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
tensor([10., 9., 8., 7., 6., 5., 4., 3., 2., 1.])
step:0, batch_x:tensor([8., 9., 3., 5., 6.]), batch_y:tensor([3., 2., 8., 6., 5.])
step:1, batch_x:tensor([ 4., 7., 10., 2., 1.]), batch_y:tensor([ 7., 4., 1., 9., 10.])
step:0, batch_x:tensor([ 4., 9., 10., 1., 5.]), batch_y:tensor([ 7., 2., 1., 10., 6.])
step:1, batch_x:tensor([8., 2., 3., 7., 6.]), batch_y:tensor([3., 9., 8., 4., 5.])
step:0, batch_x:tensor([10., 3., 6., 9., 5.]), batch_y:tensor([1., 8., 5., 2., 6.])
step:1, batch_x:tensor([7., 4., 8., 1., 2.]), batch_y:tensor([ 4., 7., 3., 10., 9.])
说明:共有 10 条数据,设置 BATCH_SIZE 为 5 来进行划分,能划分为 2 组(step 为 0 和 1)。这两组数据互斥。
实例2 BATCH_SIZE 不整除数据量:会输出余下所有数据
将上述代码中的 BATCH_SIZE 改为 4 :
"""
批训练,把数据变成一小批一小批数据进行训练。
DataLoader就是用来包装所使用的数据,每次抛出一批数据
"""
import torch
import torch.utils.data as Data
BATCH_SIZE = 4 # 批训练的数据个数
x = torch.linspace(1, 10, 10) # 训练数据
print(x)
y = torch.linspace(10, 1, 10) # 标签
print(y)
# 把数据放在数据库中
torch_dataset = Data.TensorDataset(x, y) # 对给定的 tensor 数据,将他们包装成 dataset
loader = Data.DataLoader(
# 从数据库中每次抽出batch size个样本
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
def show_batch():
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
# training
print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y))
show_batch()
输出结果:
tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
tensor([10., 9., 8., 7., 6., 5., 4., 3., 2., 1.])
step:0, batch_x:tensor([10., 6., 5., 8.]), batch_y:tensor([1., 5., 6., 3.])
step:1, batch_x:tensor([1., 7., 4., 9.]), batch_y:tensor([10., 4., 7., 2.])
step:2, batch_x:tensor([3., 2.]), batch_y:tensor([8., 9.])
step:0, batch_x:tensor([ 7., 10., 9., 3.]), batch_y:tensor([4., 1., 2., 8.])
step:1, batch_x:tensor([5., 4., 2., 8.]), batch_y:tensor([6., 7., 9., 3.])
step:2, batch_x:tensor([6., 1.]), batch_y:tensor([ 5., 10.])
step:0, batch_x:tensor([10., 9., 1., 7.]), batch_y:tensor([ 1., 2., 10., 4.])
step:1, batch_x:tensor([4., 8., 2., 6.]), batch_y:tensor([7., 3., 9., 5.])
step:2, batch_x:tensor([5., 3.]), batch_y:tensor([6., 8.])
说明:共有 10 条数据,设置 BATCH_SIZE 为 4 来进行划分,能划分为 3 组(steop 为 0 、1、2)。分别有 4、4、2 条数据。
关于PyTorch中的zero_grad()函数
zero_grad()函数的应用:
在pytorch中做随机梯度下降时往往会用到zero_grad()函数,相关代码如下:
| 函数 | 作用 |
|---|---|
| optimizer.zero_grad() | 将模型的参数梯度初始化为0 |
| outputs=model(inputs) | 前向传播计算预测值 |
| loss = cost(outputs, y_train) | 计算当前损失 |
| loss.backward() | 反向传播计算梯度 |
| optimizer.step() | 更新所有参数 |
zero_grad()函数的作用:
根据pytorch中backward()函数的计算,当网络参量进行反馈时,梯度是累积计算而不是被替换,但在处理每一个batch时并不需要与其他batch的梯度混合起来累积计算,因此需要对每个batch调用一遍zero_grad()将参数梯度置0。
另外,如果不是处理每个batch清除一次梯度,而是两次或多次再清除一次,相当于提高了batch_size,对硬件要求更高,更适用于需要更高batch_size的情况。
torch.clamp()
torch.clamp(input, min, max, out=None) → Tensor
将输入input张量每个元素夹紧到区间 [min,max],并返回结果到一个新张量。
操作定义如下:
| min, if x_i < min
y_i = | x_i, if min <= x_i <= max
| max, if x_i > max
参数:
- input (Tensor) – 输入张量
- min (Number) – 限制范围下限
- max (Number) – 限制范围上限
- out (Tensor, optional) – 输出张量
例子:
>>> a = torch.randn(4)
>>> a
1.3869
0.3912
-0.8634
-0.5468
[torch.FloatTensor of size 4]
>>> torch.clamp(a, min=-0.5, max=0.5)
0.5000
0.3912
-0.5000
-0.5000
[torch.FloatTensor of size 4]
torch.clamp(input, min, *, out=None) → Tensor
将输入input张量每个元素的限制到不小于min,并返回结果到一个新张量。
参数:
- input (Tensor) – 输入张量
- value (Number) – 限制范围下限
- out (Tensor, optional) – 输出张量
>>> a = torch.randn(4)
>>> a
1.3869
0.3912
-0.8634
-0.5468
[torch.FloatTensor of size 4]
>>> torch.clamp(a, min=0.5)
1.3869
0.5000
0.5000
0.5000
[torch.FloatTensor of size 4]
torch.clamp(input, *, max, out=None) → Tensor
将输入input张量每个元素的限制到不大于max,并返回结果到一个新张量。
参数:
- input (Tensor) – 输入张量
- value (Number) – 限制范围上限
- out (Tensor, optional) – 输出张量
>>> a = torch.randn(4)
>>> a
1.3869
0.3912
-0.8634
-0.5468
[torch.FloatTensor of size 4]
>>> torch.clamp(a, max=0.5)
0.5000
0.3912
-0.8634
-0.5468
[torch.FloatTensor of size 4]
numpy.transpose(images, (1,2,0))
有一段代码:
def imshow(img,text,should_save=False):
npimg = img.numpy() # 将torch.FloatTensor 转换为numpy
plt.axis("off") # 不显示坐标尺寸
if text:
plt.text(75, 8, text, style='italic',fontweight='bold',
bbox={'facecolor':'white', 'alpha':0.8, 'pad':10}) # facecolor前景色
# pytorch 图片的显示问题
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
解释这句话:plt.imshow(np.transpose(npimg, (1, 2, 0)))。因为在plt.imshow在现实的时候输入的是(imagesize,imagesize,channels),而def imshow(img,text,should_save=False)中,参数img的格式为(channels,imagesize,imagesize),这两者的格式不一致,我们需要调用一次np.transpose函数,即np.transpose(npimg,(1,2,0)),将npimg的数据格式由(channels,imagesize,imagesize)转化为(imagesize,imagesize,channels),进行格式的转换后方可进行显示。
总结一下,pytorch在载入数据集是元组tuple的形式,里面包括了数据及标签,其中的数据可以转换为torch .Tensor的形式,方便后面计算使用。在显示数据的时候,需要将torchtensor转换为numpy。
在pytorch中,读入图片并进行显示的方式有两种。
方式一
将读取出来的torch.FloatTensor转换为numpy,然后将其(1 ,imagesize,imagesize)给reshape一下,变成(imagesize,imagesize)的形式,最后进行显示,上代码:
# dataset的格式为:([torch.FloatTensor of size 1x28x28],3) 其中图片的格式为(1x28x28)图片的标签为3
# 这里我们只取这一张图片本身,先不管它的标签。
img=dataset[0]
# First 将 torch.FloatTensor 转换为 numpy的格式
img=img.numpy()
# Second 将shape(1,28,28)转化为(28,28)
img=img.reshape(28,28)
# Third 调用plt 将图片显示出来
plt.imshow(img,cmap='gray')
plt.show()
#然后就可以显示图片了
方式二:调用torch的接口
img=torchvision.utils.make_grid(img).numpy()
plt.imshow(np.transpose(img,(1,2,0)))
plt.show()
这里用np.transpose(img,(1,2,0))将图片的格式由(channels,imagesize,imagesize)转化为(imagesize,imagesize,channels),这样plt.show()就可以显示图片了。
torch.max()
torch.max(input, dim)函数
在分类问题中,通常需要使用max()函数对softmax函数的输出值进行操作,求出预测值索引。下面讲解一下torch.max()函数的输入及输出值都是什么。
output = torch.max(input, dim)
输入
input是Softmax函数输出的一个tensordim是max函数索引的维度0/1,0是每列的最大值,1是每行的最大值
输出
- 函数会返回两个
tensor,第一个tensor是每行的最大值,softmax的输出中最大的是1,所以第一个tensor是全1的tensor;第二个tensor是每行最大值的索引。
我们通过一个实例可以更容易理解这个函数的用法:
import torch
a = torch.tensor([[1,5,62,54], [2,6,2,6], [2,65,2,6]])
print(a)
输出:
tensor([[ 1, 5, 62, 54],
[ 2, 6, 2, 6],
[ 2, 65, 2, 6]])
索引每行的最大值:
torch.max(a, 1)
输出:
torch.return_types.max(
values=tensor([62, 6, 65]),
indices=tensor([2, 3, 1]))
在计算准确率时第一个tensor的“values”属性是不需要的,所以我们只需提取第二个tensor,并将tensor格式的数据转换成array格式。
torch.max(a, 1)[1].numpy()
输出:
array([2, 3, 1], dtype=int64)
*注:在有的地方我们会看到torch.max(a, 1).data.numpy()的写法,这是因为在早期的pytorch的版本中,variable变量和tenosr是不一样的数据格式,variable可以进行反向传播,tensor不可以,需要将variable转变成tensor再转变成numpy。现在的版本已经将variable和tenosr合并,所以只用torch.max(a,1).numpy()就可以了。
准确率计算
pred_y = torch.max(predict, 1)[1].numpy()
y_label = torch.max(label, 1)[1].data.numpy()
accuracy = (pred_y == y_label).sum() / len(y_label)
torch.eye()函数

torch.mul()、torch.mm()、torch.dot()和torch.mv()之间的区别
- torch.mul()是矩阵的点乘,即对应的位相乘,要求shape一样, 返回的还是个矩阵
- torch.mm()是矩阵正常的矩阵相乘,(a, b)* ( b, c ) = ( a, c )
- torch.dot()类似于mul(),它是向量(即只能是一维的张量)的对应位相乘再求和,返回一个tensor数值
- torch.mv()是矩阵和向量相乘,类似于torch.mm()
import torch
A = torch.tensor([[1,2,3],
[4,5,6]])
x = torch.tensor([1,2,3])
torch.mv(A, x) # 第一个参数是矩阵,第二个参数只能是一维向量
输出:tensor([14, 32])
等价于A * X^T
torch.rand()

torch.randn()

torch.normal()

torch.linespace()

torch.argsort()—输出值为索引
第一步:先定义一个array数据
import numpy as np
x=np.array([2,4,5,3,-10,1])
第二步:输出结果:
y=np.argsort(x)
print(y)
输出结果为:y=[4 5 0 3 1 2]
第三步:总结:
argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引号)
例如:x[4]=-10最小,所以y[0]=4,
同理:x[2]=5最大,所以y[5]=2。
看以下官方案例:
One dimensional array:一维数组
>>> x = np.array([3, 1, 2])
>>> np.argsort(x)
array([1, 2, 0])
Two-dimensional array:二维数组
>>> x = np.array([[0, 3], [2, 2]])
>>> x
array([[0, 3],
[2, 2]])
>>> np.argsort(x, axis=0) #按列排序
array([[0, 1],
[1, 0]])
>>> np.argsort(x, axis=1) #按行排序
array([[0, 1],
[0, 1]])
>>> x = np.array([3, 1, 2])
>>> np.argsort(x) #按升序排列
array([1, 2, 0])
>>> np.argsort(-x) #按降序排列
array([0, 2, 1])
Pytorch关于requires_grad_(True)的理解
import torch
x = torch.tensor([1, 2], dtype=torch.float32, requires_grad=True)
a = torch.tensor([3, 4], dtype=torch.float32, requires_grad=True)
y = x * 2 + a
y.requires_grad_(True)
z = torch.mean(y)
z.backward()
print(x.grad, x.requires_grad)
print(a.grad, a.requires_grad)
print(y.grad, y.requires_grad)
print(z.grad, z.requires_grad)
# 以下结果需要设置a的requires_grad=False或取消这个参数。
# tensor([1., 1.]) True
# None False
# None True
# None True
问题: grad can be implicitly created only for scalar outputs
Autograd:自动求导
torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性.
要阻止一个张量被跟踪历史,可以调用 .detach() 方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。
为了防止跟踪历史记录(和使用内存),可以将代码块包装在 with torch.no_grad(): 中。在评估模型时特别有用,因为模型可能具有 requires_grad = True 的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
还有一个类对于autograd的实现非常重要:Function。
Tensor 和 Function 互相连接生成了一个无圈图(acyclic graph),它编码了完整的计算历史。每个张量都有一个 .grad_fn 属性,该属性引用了创建 Tensor 自身的Function(除非这个张量是用户手动创建的,即这个张量的 grad_fn 是 None )。
如果需要计算导数,可以在 Tensor 上调用 .backward()。如果 Tensor 是一个标量(即它包含一个元素的数据),则不需要为 backward() 指定任何参数,但是如果它有更多的元素,则需要指定一个 gradient 参数,该参数是形状匹配的张量。
若遇到: grad can be implicitly created only for scalar outputs
根据文档 如果 Tensor 是一个标量(即它包含一个元素的数据),则不需要为 backward() 指定任何参数,但是如果它有更多的元素,则需要指定一个 gradient 参数,该参数是形状匹配的张量。
所以当:
x = torch.ones(2,requires_grad=True)
print(x)
z = x + 2
print(z)
z.backward()
print(x.grad)
# 出现grad can be implicitly created only for scalar outputs
# 因为此时的 z 并不是一个标量(即它包含一个元素的数据)
# 意思是只有对标量输出它才会计算梯度,而求一个矩阵对另一矩阵的导数束手无策。
RuntimeError: grad can be implicitly created only for scalar outputs
即:
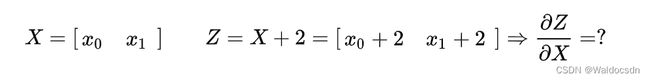
那么我们只要想办法把矩阵转变成一个标量不就好了?比如我们可以对z求和,然后用求和得到的标量在对x求导,这样不会对结果有影响,例如:
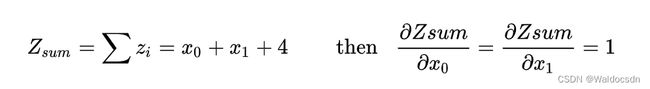
我们可以看到对z求和后再计算梯度没有报错,结果也与预期一样:
x = torch.ones(2,requires_grad=True)
z = x + 2
z.sum().backward()
print(x.grad)
>>> tensor([1., 1.])
再回到文档但是如果它有更多的元素,则需要指定一个 gradient 参数,该参数是形状匹配的张量。

也就是对于矩阵求导来说,需要一个额外的参数矩阵和需要求导的矩阵做点乘。 一般点乘的矩阵为全1的对应形状的矩阵。 也就是乘以全1的矩阵,等价于sum()。
参考 Pytorch autograd, backward详解
也就是 比如:
x = torch.tensor([2., 1.], requires_grad=True)
y = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
z = torch.mm(x.view(1, 2), y)
print(f"z:{z}")
z.backward(torch.Tensor([[1., 0]]), retain_graph=True)
print(f"x.grad: {x.grad}")
print(f"y.grad: {y.grad}")
>>> z:tensor([[5., 8.]], grad_fn=<MmBackward>)
x.grad: tensor([[1., 3.]])
y.grad: tensor([[2., 0.],
[1., 0.]])
结果解释如下:

上面这里并没使用全为1的矩阵, 因此grad_tensors 如果自定义,会产生对应自定义产生的结果。一般来说都定义为全1的矩阵。(可以看作等价与sum())
transforms.Normalize
cifar10数据集_提取torchvision.datasets.CIFAR10中的图像及标签
torchvision.datasets中包含了很多常用的数据集,比如mnist,fashion-mnist,cifar10等。这些数据集都是以压缩包的格式存储的,有时候我们特别想将这些数据集解压出来,将数据和标签分布存储在不同的文件夹下。下面是一个处理cifar10数据集的例子,其它数据集处理类似,源码如下:
import torch
import torchvision
import torchvision.transforms as transforms
import os
import numpy as np
from skimage import io
import matplotlib.pyplot as plt
trainset = torchvision.datasets.CIFAR10(root='/mnt/liguanlin/DataSets/cifar', train=True,
download=True,transform=None)
testset = torchvision.datasets.CIFAR10(root='/mnt/liguanlin/DataSets/cifar', train=False,
download=True, transform=None)
train_set_size = len(trainset)
print(train_set_size)
test_set_size = len(testset)
print(test_set_size)
print(type(trainset[0])) # 有几个注意的点:
- 加载数据集时,要想好什么时候添加transforms.ToTensor()转换
trainset = torchvision.datasets.CIFAR10(root='/mnt/liguanlin/DataSets/cifar', train=True,
download=True,transform=None)
即如上,需要设置transform=None。如果不经过任何转换,则trainset中保存的图片的格式是
由于是
- 如何在trainset中找到图片对象和标签
for i in range(train_set_size):
img_path = '/mnt/liguanlin/DataSets/cifar/train/{i}.png'.format(i=i+1)
sample = trainset[i][0]
sample.save(img_path)
trainset_labels[i] = trainset[i][1]
如上,trainset中保存的是所有图片的一个tuple,tuple的第一个元素是Image对象,第二个元素是标签。
所以如果我们要获取第i个tuple的图片和标签,可以这样搞:
sample = trainset[i][0]
trainset_labels[i] = trainset[i][1]
3,对于标签的存储使用的是np.savetxt 直接将标签组成的一维的numpy array存储起来即可。
argparse基本用法
- 文章 1
- 文章 2
tensor.copy_()
tensor.copy_(src)
将src中的元素复制到tensor中并返回这个tensor; 两个tensor应该有相同shape
例子:
x = torch.tensor([[1,2], [3,4], [5,6]])
y = torch.rand((3,2))
print(y)
y.copy_(x)
print(y)
输出:
tensor([[0.1604, 0.0176],
[0.3737, 0.2009],
[0.1438, 0.8394]])
tensor([[1., 2.],
[3., 4.],
[5., 6.]])
[Finished in 1.9s]
Python dict() 函数
什么是状态字典:state_dict?
在PyTorch中,torch.nn.Module模型的可学习参数(即权重和偏差)包含在模型的参数中,(使用model.parameters()可以进行访问)。 state_dict是Python字典对象,它将每一层映射到其参数张量。注意,只有具有可学习参数的层(如卷积层,线性层等)的模型才具有state_dict这一项。目标优化torch.optim也有state_dict属性,它包含有关优化器的状态信息,以及使用的超参数。
因为state_dict的对象是Python字典,所以它们可以很容易的保存、更新、修改和恢复,为PyTorch模型和优化器添加了大量模块。
下面通过从简单模型训练一个分类器中来了解一下state_dict的使用。
# 定义模型
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化模型
model = TheModelClass()
# 初始化优化器
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 打印模型的状态字典
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# 打印优化器的状态字典
print("Optimizer's state_dict:")
for var_name in optimizer.state_dict():
print(var_name, "\t", optimizer.state_dict()[var_name])
输出:
Model's state_dict:
conv1.weight torch.Size([6, 3, 5, 5])
conv1.bias torch.Size([6])
conv2.weight torch.Size([16, 6, 5, 5])
conv2.bias torch.Size([16])
fc1.weight torch.Size([120, 400])
fc1.bias torch.Size([120])
fc2.weight torch.Size([84, 120])
fc2.bias torch.Size([84])
fc3.weight torch.Size([10, 84])
fc3.bias torch.Size([10])
Optimizer's state_dict:
state {}
param_groups [{'lr': 0.001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4675713712, 4675713784, 4675714000, 4675714072, 4675714216, 4675714288, 4675714432, 4675714504, 4675714648, 4675714720]}]
transform.ToTensor(), transform.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))作用

torchvision.transforms 数据预处理:Normalize()
1、Normalize() 的作用
Normalize() 是pytorch中的数据预处理函数,包含在 torchvision.transforms 模块下。一般用于处理图像数据,其输入数据格式是 torch.Tensor,而不是 np.array。
1.1 Normalize() 的源码
看一下 Normalize() 函数的源码:
class Normalize(torch.nn.Module):
"""Normalize a tensor image with mean and standard deviation.
This transform does not support PIL Image.
Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``
channels, this transform will normalize each channel of the input
``torch.*Tensor`` i.e.,
``output[channel] = (input[channel] - mean[channel]) / std[channel]``
.. note::
This transform acts out of place, i.e., it does not mutate the input tensor.
Args:
mean (sequence): Sequence of means for each channel.
std (sequence): Sequence of standard deviations for each channel.
inplace(bool,optional): Bool to make this operation in-place.
"""
大意是:使用均值和标准差对输入的tensor的每个通道进行标准化,计算公式是:
output[channel] = (input[channel] - mean[channel]) / std[channel]
这里要与正态分布标准化进行区分,将一个正态分布转化为标准正态分布(即高斯分布)的公式为 Z=(X-mean)/variance,这里的分母是方差而不是标准差。
1.2 代码示例
这里用代码来演示一下Normalize()的作用:
import numpy as np
from torchvision import transforms
data = np.array([
[0., 5, 10, 20, 0],
[255, 125, 180, 255, 196]
]) # 因为 Normalize() 的输入必须是 float 类型,所以这里定义一个 np.float64类型的 array
tensor = transforms.ToTensor()(data)
norm = transforms.Normalize((0.5), (0.5)) # mean=0.5 std=0.5
print(f"tensor = {tensor}")
print(f"norm(tensor) = {norm(tensor)}")
"""
tensor = tensor([[[ 0., 5., 10., 20., 0.],
[255., 125., 180., 255., 196.]]], dtype=torch.float64)
norm(tensor) = tensor([[[ -1., 9., 19., 39., -1.],
[509., 249., 359., 509., 391.]]], dtype=torch.float64)
"""
很容易可以验证:
(0 - 0.5) / 0.5 = -1
(5 - 0.5) / 0.5 = 9
(255 - 0.5) / 0.5 = 509
2、ToTensor() 和 Normalize() 的结合使用
在图像预处理中,Normalize() 通常和 ToTensor() 一起使用。
首先 ToTensor() 将 [0,255] 的像素值归一化为 [0,1],然后使用 Normalize(0.5, 0.5) 将 [0,1] 进行标准化为 [-1,1]
ToTensor() 和Normalize() 结合使用的代码示例:
import numpy as np
from torchvision import transforms
data = np.array([
[0, 5, 10, 20, 0],
[255, 125, 180, 255, 196]
], dtype=np.uint8)
tensor = transforms.ToTensor()(data)
norm = transforms.Normalize(0.5, 0.5)
print(f"tensor = {tensor}")
print(f"norm(tensor) = {norm(tensor)}")
"""
tensor = tensor([[[0.0000, 0.0196, 0.0392, 0.0784, 0.0000],
[1.0000, 0.4902, 0.7059, 1.0000, 0.7686]]])
norm(tensor) = tensor([[[-1.0000, -0.9608, -0.9216, -0.8431, -1.0000],
[ 1.0000, -0.0196, 0.4118, 1.0000, 0.5373]]])
"""
使用 transforms.Compose() 函数进行图像预处理:
from torchvision import transforms
import cv2
filePath = "Dataset/FFHQ/00000.png"
img = cv2.imread(filePath)
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
img = transform(img)
print(img)
"""
tensor([[[ 0.1451, 0.1294, 0.1059, ..., 0.2157, 0.2000, 0.1843],
[ 0.1529, 0.1137, 0.1294, ..., 0.1843, 0.1843, 0.1922],
[ 0.1216, 0.1137, 0.1529, ..., 0.2314, 0.1686, 0.1529],
...,
[-0.8118, -0.7961, -0.7725, ..., 0.0980, 0.0824, 0.0588],
[-0.8196, -0.8196, -0.8039, ..., 0.0588, 0.0353, 0.0275],
[-0.8667, -0.8510, -0.8275, ..., 0.0431, 0.0431, 0.0510]]])
"""
关于“shape”和“ndim”的一些点
- 代码示例
代码块1:
import numpy as np
a = np.array([1,2,3,3])
print('a的shape是:')
print(a.shape)
b = np.array([[1,1],[1,1],[1,1]])
print('b的shape是:')
print(b.shape)
输出为:
a的shape是:
(4,)
b的shape是:
(3, 2)
代码块2:
import numpy as np
a = np.array([1,2,3,3])
print('a的维度是:')
print(a.ndim)
b = np.array([[1,1],[1,1],[1,1]])
print('b的维度是:')
print(b.ndim)
输出为:
a的维度是:
1
b的维度是:
2
-
代码讲解
2.1 维度判断方式:- 根据shape中数字个数判断。如代码块1所示,a中的输出为(4,),有一个数字,那么a是一维;b中的输出为(3,2),有两个数字(分别为3和2),则b是二维。
- 根据ndim方法判断如代码块2所示。可以直接运用ndim进行维度的输出。
2.2 shape中数字的含义:
如代码块1:
3. a.shape 输出 (4,),其中只有一个数字4,表示一维;数字4表示含有4个数据。
4. b.shape 输出 (3,2),其中含有两个数字(分别是3,2)表示二维数组。3,2的含义为:3表示其中含有3个一维数组,2表示一维数组中含有2个数据
PyTorch保存与加载模型
首先定义一个简单的模型,这里使用一个两层的全连接神经网络作为例子:
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = nn.functional.relu(x)
x = self.fc2(x)
return x
然后创建一个模型实例:
net = Net()
接下来,训练模型并保存:
import torch.optim as optim
# 定义优化器和损失函数
optimizer = optim.SGD(net.parameters(), lr=0.01)
criterion = nn.MSELoss()
# 训练模型
for epoch in range(100):
# 输入数据和标签
input_data = torch.randn(32, 10)
labels = torch.randn(32, 1)
# 清零梯度
optimizer.zero_grad()
# 前向传播,计算损失
output = net(input_data)
loss = criterion(output, labels)
# 反向传播,更新参数
loss.backward()
optimizer.step()
# 保存模型
torch.save(net.state_dict(), 'model.pt')
最后,加载模型并使用:
# 创建模型实例
net = Net()
# 加载模型参数
net.load_state_dict(torch.load('model.pt'))
# 使用模型进行预测
input_data = torch.randn(1, 10)
output = net(input_data)
print(output)
在这个例子中,定义了一个简单的神经网络模型,训练模型并将模型参数保存到文件中。然后,我们重新创建了一个模型实例,并从文件中加载了模型参数。最后,我们使用加载的模型进行预测。
代码“with torch.set_grad_enabled(False):”的作用
这行代码的作用是关闭PyTorch的自动求导功能。PyTorch的自动求导机制可以记录张量的计算历史,并且可以在反向传播时自动计算梯度,方便地进行深度学习模型的训练。但是,有些情况下我们不需要梯度信息,例如在推断(inference)阶段或者是在对模型进行评估时,我们只需要利用前向传播计算出模型的预测结果,而不需要进行反向传播计算梯度。此时,关闭自动求导功能可以减少计算开销,提高程序的运行效率。
具体而言,with torch.set_grad_enabled(False)是一个上下文管理器,它会在代码块内部关闭自动求导功能。例如,下面的代码块将会计算模型在测试集上的准确率,但是不需要梯度信息:
with torch.set_grad_enabled(False):
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))
在上面的代码中,我们使用了with torch.set_grad_enabled(False)来关闭自动求导功能,然后在代码块内部计算模型的预测结果,并根据预测结果计算模型在测试集上的准确率。由于我们不需要梯度信息,因此关闭自动求导功能可以减少计算开销,提高程序的运行效率。当代码块执行完毕后,自动求导功能会自动恢复到之前的状态。