模型泛化技巧“随机权重平均(Stochastic Weight Averaging, SWA)”介绍与Pytorch Lightning的SWA实现讲解
文章目录
- SWA简介
- SWA公式
- SWA常见参数
- Pytorch Lightning的SWA源码分析
-
- SWALR
- 参考资料
SWA简介
SWA,全程为“Stochastic Weight Averaging”(随机权重平均)。它是一种深度学习中提高模型泛化能力的一种常用技巧。
其思路为:对于模型的权重,不直接使用最后的权重,而是将之前的权重做个平均。
该方法适用于深度学习,不限领域、不限Optimzer,可以和多种技巧同时使用。
SWA公式
我们的模型参数记为: θ = { w 0 , w 1 , w 2 , ⋯ , w n } \theta=\{w_0, w_1, w_2, \cdots, w_n\} θ={w0,w1,w2,⋯,wn}, n n n 为模型总参数量。
对于模型的训练,会在epoch结束后保存一个副本,第 t t t 个epoch的模型参数记为 θ t \theta_t θt。
则我们模型的最终参数为:
θ ˉ = 1 T ∑ t = 1 T θ t \bar{\theta} = \frac{1}{T} \sum^T_{t=1}\theta_t θˉ=T1t=1∑Tθt
其中 T T T 表示我们有 T T T 个不同个模型参数的副本。
该公式的意思就是将前面t个模型的权重取平均,然后作为最终的模型参数。
注意事项:
- 通常只在一个epoch结束后保存模型参数副本。
- 并不是每个epoch都要保存模型副本。通常会从模型开始很好地收敛后再开始保存模型参数副本。
SWA常见参数
通常我们在使用SWA时会有如下的超参数:
- SWA Start:从第几个epoch再开始保存模型副本。若在模型还不能很好的收敛时就开始保存模型参数副本,可能会损害模型的性能。
- SWA Learning Rate:在SWA期间采用学习率。例如,我们设置在第20个epoch开始进行SWA,则在第20个epoch后就会采用你指定的SWA Learning Rate,而不是之前的。
Pytorch Lightning的SWA源码分析
本节展示一下Pytorch Lightning中对SWA的实现,以便更清晰的认识SWA。
在开始看代码前,明确几个在Pytorch Lightning实现中的几个重要的概念:
- 平均模型(self._average_model):Pytorch Lightning会将平均的后的模型存入该变量中。
- pl_module:该变量为当前的模型。
class StochasticWeightAveraging(Callback):
def __init__(
self,
swa_lrs: Union[float, List[float]], # swa的学习率
# swa_epoch_start: 从第0.8位置的epoch开始,例如一共100个epoch,那就从第81个epoch开始swa。
# 若指定整数,则会从指定的epoch开始swa。
swa_epoch_start: Union[int, float] = 0.8,
annealing_epochs: int = 10, # 模拟退火的epoch数。SWALR学习策略用的参数
annealing_strategy: str = "cos", # 模拟退火策略。SWALR学习策略用的参数
avg_fn: Optional[_AVG_FN] = None, # 平局函数,做模型参数平均时使用的函数,通常不需要指定。会使用默认的。
device: Optional[Union[torch.device, str]] = torch.device("cpu"), # 平均后的model存在哪个device上
):
...
def on_train_epoch_start(self, ...): # 在每个epoch开始前执行
if (not self._initialized) and (self.swa_start <= trainer.current_epoch <= self.swa_end):
# 初始化SWA,在整个SWA过程中只执行一遍
self._initialized = True
...
# 使用原来的optimizer
optimizer = trainer.optimizers[0]
...
# 使用SWALR学习率策略(SWA Learning Scheduler),后面会讲
self._swa_scheduler = cast(
LRScheduler,
SWALR(
optimizer,
swa_lr=self._swa_lrs, # type: ignore[arg-type]
anneal_epochs=self._annealing_epochs,
anneal_strategy=self._annealing_strategy,
last_epoch=trainer.max_epochs if self._annealing_strategy == "cos" else -1,
),
)
# end if, 初始化代码结束。
# 接下来是SWA在epoch开始前的处理逻辑
if (self.swa_start <= trainer.current_epoch <= self.swa_end):
# 在SWA期间,每个epoch开始前将当前的模型参数更新到“平均模型”上。
self.update_parameters(self._average_model, pl_module, self.n_averaged, self._avg_fn)
if trainer.current_epoch == self.swa_end + 1:
# 到最后结束的时候,将平均模型的参数迁移到模型上。
self.transfer_weights(self._average_model, pl_module)
@staticmethod
def update_parameters(
average_model: "pl.LightningModule", model: "pl.LightningModule", n_averaged: Tensor, avg_fn: _AVG_FN
) -> None:
for p_swa, p_model in zip(average_model.parameters(), model.parameters()):
device = p_swa.device
p_swa_ = p_swa.detach()
p_model_ = p_model.detach().to(device)
src = p_model_ if n_averaged == 0 else avg_fn(p_swa_, p_model_, n_averaged.to(device))
p_swa_.copy_(src)
n_averaged += 1
@staticmethod
def avg_fn(averaged_model_parameter: Tensor, model_parameter: Tensor, num_averaged: Tensor) -> Tensor:
return averaged_model_parameter + (model_parameter - averaged_model_parameter) / (num_averaged + 1)
从上述Pytorch Lightning对SWA实现的源码中我们可以获得以下信息:
- 使用SWA需要指定
SWA学习率和从哪个epoch开始这两个最重要的参数。 - 在开始SWA后,将会使用新的“swa_lrs”学习率和新的“SWALR”学习率策略。(但在“退火”期间,会参考模型原本的学习率)
- 每个epoch开始前,会把上一个epoch学习到的模型参数更新到“平均模型”上。
- SWA期间,使用的Optimizer和之前一样。例如你模型训练时用的是Adam,则SWA期间也用Adam。
SWALR
在上面我们提到了Pytorch Lightning实现中,在SWA期间使用的是SWALR。
SWALR使用的是“模拟退火”策略,简单来说就是:学习率是从原本的学习率逐渐过度到SWA学习率的。例如,原本你使用的学习率是0.1,指定的SWA学习率为0.01,从第20个epoch开始进行SWA。那么并不是到第20个epoch后学习率立刻从0.1变到0.01,而是从0.1逐渐过度到0.01,过度的epoch数就是指定的annealing_epochs参数,而过度时减小的策略就是annealing_strategy参数。
这里不使用难以理解的源码或数学,而是来通过几组实验来直观的观察一下SWALR策略下的学习率的变化来进行解释:
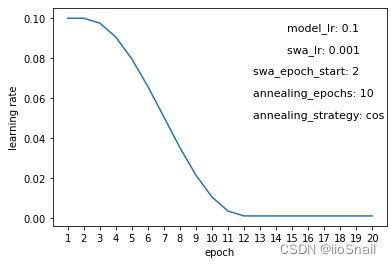





上述实验为:模型训练过程中学习率随epoch的变化,横坐标为epoch,纵坐标为这个epoch使用的学习率。其中图上的几个参数分别为:
- model_lr:模型一开始使用的学习率。
- swa_lr:用户指定的swa学习率
- swa_epoch_start:从第几个epoch开始swa
- annealing_epoch:模拟退火的epoch数
- annealing_strategy:模拟退火策略。目前仅支持“cos”和“linear”两种。
例如对于图一意思就是:模型一开始在Optimizer上指定的学习率是0.1,SWA学习率为0.001,从第2个epoch开始进行SWA,总共进行10(annealing_epochs) 个epoch将学习率从0.1逐渐过度到0.001,学习率调整使用cos策略。
从上述图中很容易得出以下结论:
- 所谓的SWALR学习率策略就是让学习率从原来的学习率逐渐过度到swa学习率。过度的epoch数就是annealing_epoch
- 若你指定的swa学习率和之前的是一样的,那么SWALR相当于什么都没做。(图二)
- 若你指定的swa学习率比之前的学习率高,那么学习率就会逐渐升高(图三)。不过通常不会这么做,通常swa_lr要比model_lr小才对,因为到后面模型都稳定了,不能再用更高的学习率了。
- 若annealing_epoch数较小,那么“退火”速度较快,即从model_lr到swa_lr的过度速度就较快(图四),反正则慢。
- “cos”退火策略下学习率变化是先慢,然后快,最后再慢。(图五),而“linear”实现线性策略变化速度是一样的。(图六)
实验环境与代码如下:
lightning==2.0.1
pytorch==1.13.0
实验代码如下:
import torch
import torch.nn as nn
import lightning.pytorch as pl
from lightning.pytorch.callbacks import StochasticWeightAveraging
from matplotlib import pyplot as plt
import numpy as np
def plot_swa_lr_curve(model_lr, # 模型的学习率
swa_lr, # swa的学习率
swa_epoch_start=2, # 从哪个epoch开始swa
annealing_epochs=10, # 模拟退火的epoch数
annealing_strategy='cos' # 模拟退火策略
):
lrs = []
# 定义一个简单的模型,用于测试
class SimpleModel(pl.LightningModule):
def __init__(self):
super(SimpleModel, self).__init__()
self.linear = nn.Linear(1, 1)
def training_step(self, batch, batch_idx, *args, **kwargs):
return nn.functional.mse_loss(self.linear(torch.rand(4, 1)), torch.rand(4, 1))
def configure_optimizers(self):
# 使用model_lr作为测试模型的学习率
return torch.optim.SGD(self.parameters(), lr=model_lr)
# 重写一下StochasticWeightAveraging,用于记录学习率变化
class MyStochasticWeightAveraging(StochasticWeightAveraging):
def on_train_epoch_start(self, *args, **kwargs):
super().on_train_epoch_start(*args, **kwargs)
if hasattr(self._swa_scheduler, "_last_lr"):
# 记录lr的变化
lrs.append(self._swa_scheduler._last_lr[0])
else:
lrs.append(model_lr)
# 定义trainer进行训练
trainer = pl.Trainer(
callbacks=[MyStochasticWeightAveraging(swa_lrs=swa_lr, swa_epoch_start=swa_epoch_start,
annealing_epochs=annealing_epochs,
annealing_strategy=annealing_strategy)],
max_epochs=20,
num_sanity_val_steps=0,
enable_progress_bar=False, # Use custom progress bar
accelerator='cpu',
)
# 训练模型
trainer.fit(SimpleModel(), train_dataloaders=range(10))
plt.plot(np.arange(1, len(lrs)+1).astype(dtype=np.str), lrs)
plt.xlabel("epoch")
plt.ylabel("learning rate")
plt.text(0.7, 0.9, "model_lr: %s" % model_lr, fontsize=11, transform=plt.gca().transAxes)
plt.text(0.7, 0.8, "swa_lr: %s" % swa_lr, fontsize=11, transform=plt.gca().transAxes)
plt.text(0.6, 0.7, "swa_epoch_start: %s" % swa_epoch_start, fontsize=11, transform=plt.gca().transAxes)
plt.text(0.6, 0.6, "annealing_epochs: %s" % annealing_epochs, fontsize=11, transform=plt.gca().transAxes)
plt.text(0.6, 0.5, "annealing_strategy: %s" % annealing_strategy, fontsize=11, transform=plt.gca().transAxes)
plt.show()
print("lrs:", lrs) # 输出lr的变化
return lrs
plot_swa_lr_curve(0.1, 0.001)
参考资料
Averaging Weights Leads to Wider Optima and Better Generalization(原论文): https://arxiv.org/abs/1803.05407
PyTorch 1.6 now includes Stochastic Weight Averaging: https://pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging/