ELK+kafka分布式日志采集分析
ELK+kafka分布式日志采集分析
- 1 kafka的介绍
-
- 1.1 ELK+kafka的优点
- 1.2 部署架构
- 2 Elasticsearch的部署
- 3 kafka的部署(server3,server4,server5)
-
- 3.1 JDK环境
- 3.2 kafka的部署
- 3.3 zookeeper的部署
- 3.4 kafka集群的使用
- 4 Filebeat的部署(server6)
- 5 Logstash的部署
- 6 Kibana的部署(server7)
- 7 搭建Cerebro Elasticsearch监控
1 kafka的介绍
kafka是一个发布订阅消息系统,由topic区分消息种类,每个topic中可以有多个partition,每个kafka集群有一个多个broker服务器组成,producer可以发布消息到kafka中,consumer可以消费kafka中的数据。kafka就是生产者和消费者中间的一个暂存区,可以保存一段时间的数据保证使用
zookeeper作为解决分布式一致性问题的工具而被kafka依赖。而分布式模式,即去中心化的集群模式,需要让消费者知道现在有哪些生产者(对于消费者而言,kafka就是生产者)是可用的。如果没了zk每次消费者在消费之前都去尝试连接生产者测试下是否连接成功,效率就会变得很低
Kafka使用zk的分布式协调服务,将生产者,消费者,消息储存(broker,用于存储信息,消息读写等)结合在一起。同时借助zk,kafka能够将生产者,消费者和broker在内的所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现生产者的负载均衡
1.1 ELK+kafka的优点
单纯使用EIK实现分布式日志收集缺点:
- 当产生日志的服务节点越来越多,Logstash也需要部署越来越多,扩展不好。 读取IO文件,可能会产生日志丢失
- 读取文件不是实时性,中间需要引入到Kafka,日志实时发布到Kafka,Logstash订阅并实时获取消息
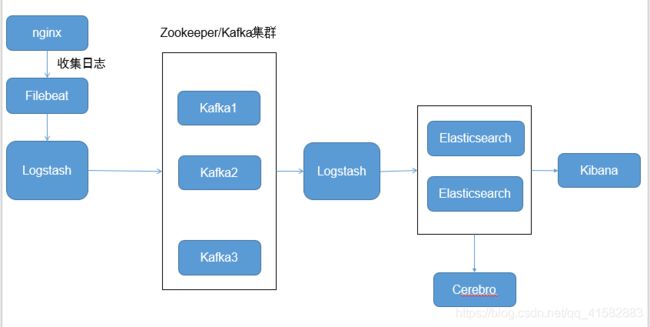
1.2 部署架构
实验环境:关闭防火墙和selinux
| 软件 | 主机 |
|---|---|
| es1 | server1 |
| es2 | server2 |
| kafka1 | server3 |
| kafka2 | server4 |
| kafka3,logstash | server5 |
| nginx,filebeat | server6 |
| kibana,Cerebro | server7 |
Filebeat->Logstash->Kafka->Logstash->Elasticsearch->Kibana
2 Elasticsearch的部署
- ES集群前面已经部署过,参考博客:Elasticsearch的部署
3 kafka的部署(server3,server4,server5)
kafka是一个消息队列服务器,kafka服务称为broker(中间人),消息发送者称为生产者,消息接受者称为消费者,通过部署多个broker提供高可用的消息服务集群,典型的是三个broker;消息以topic的方式发送到broker,消费者订阅topic,实现按需取用的消费模式;创建topic需要指定replication-factor(复制数目,通常=broker数目);每个topic可能有多个分区,每个分区的消息内容不会重复。
3.1 JDK环境
(1) 安装java环境:rpm -ivh jdk-8u121-linux-x64.rpm
3.2 kafka的部署
(1)下载kafka
wget http://mirror.bit.edu.cn/apache/kafka/1.0.0/kafka_2.12-1.0.0.tgz
(2)解压并做软链接
tar zxf kafka_2.12-2.8.0.tgz -C /usr/local/
cd /usr/local/
ln -s /usr/local/kafka_2.12-2.8.0/ /usr/local/kafka
(3)编辑kafka的server.properties配置文件
cat /usr/local/kafka/config/server.properties |grep -v ^#
broker.id=3
listeners=PLAINTEXT://172.25.12.3:9092
host.name=172.25.12.3
message.max.bytes=12695150
compression.codec=snappy
max.partition.fetch.bytes=4194304
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/local/kafka/logs
num.partitions=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=172.25.12.3:2181,172.25.12.4:2181,172.25.12.5:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
(4)编辑kafka服务的启动脚本
vim /etc/systemd/system/kafka.service
[Unit]
Description=Apache Kafka server (broker)
After=network.target zookeeper.service
[Service]
#Type=simple
#Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/java/jdk-11.0.1/bin"
#User=root
#Group=root
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
3.3 zookeeper的部署
使用kafka自带的zookeeper
(1)编辑kafka的zookeeper.properties配置文件
cat /usr/local/kafka/config/zookeeper.properties |grep -v ^#
dataDir=/usr/local/kafka/zookeeper/data
datalogDir=/usr/local/kafka/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.2=172.25.12.3:2888:3888
server.3=172.25.12.4:2888:3888
server.4=172.25.12.5:2888:3888
(2)对每个zookeeper集群设置一个myid,必须与上面的zookeeper.properties配置文件下面的server.xxx的ID对应,有几个集群就需要设置几个ID
echo 2 > /usr/local/kafka/zookeeper/data/myid
(3)编辑zookeeper服务的启动脚本
vim /etc/systemd/system/zookeeper.service
[Unit]
Description=Zookeeper service
After=network.target
[Service]
#Type=simple
#Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/java/jdk-11.0.1/bin"
#User=root
#Group=root
ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties
ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
3.4 kafka集群的使用
(1)启动kafka集群
注意要先启动zookeeper,再启动kafka
systemctl enable --now zookeeper kafka
(2)查看其群的角色:netstat -nlpt | grep -E "2181|2888|3888"
有2888端口的是的是,目前server4节点为leader
![]()
![]()
![]()
(3)创建并查看topic
[root@server3 ~]# cd /usr/local/kafka/bin/
## zookeeper指定其中一个节点即可,集群之间会自动同
[root@server3 bin]# ./kafka-topics.sh --create --zookeeper 172.25.12.4:2181 --replication-factor 1 --partitions 1 --topic alia
Created topic alia.
[root@server3 bin]# ./kafka-topics.sh --list --zookeeper 172.25.12.4:2181
111http_log
__consumer_offsets
alia
[root@server3 bin]# ./kafka-topics.sh --describe --zookeeper 172.25.12.4:2181 --topic alia
Topic: alia TopicId: Wn2VYU5oS2G_tep4VQ0jTg PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: alia Partition: 0 Leader: 3 Replicas: 3 Isr: 3
(4)模拟生产者和消费者
- 启动Producer并发送消息,执行如下脚本
[root@server3 bin]# ./kafka-console-producer.sh --broker-list 172.25.12.4:9092 --topic alia
>
- 另一个终端,启动Consumer,并订阅我们上面创建的名称为alia的Topic中生产的消息,执行如下脚本
[root@server4 bin]# cd /usr/local/kafka/bin/
[root@server4 bin]# ./kafka-console-consumer.sh --bootstrap-server 172.25.12.4:9092 -from-beginning --topic alia
>
- 生产者写入数据
![]()
- 从开始位置消费数据
![]()
此时kafka集群已经搭建完成了
(5)删除toplic: ./kafka-topics.sh --delete --zookeeper 172.25.12.3:2181 --topic alia
4 Filebeat的部署(server6)
(1) Filebeat的部署参考博客:Filebeat
(2)安装nginx
(3)修改 Filebeat的配置文件(实现数据采集后从filebeat——>Logstash)
- filebeat的配置文件:
cat /etc/filebeat/filebeat.yml | grep -v "#"
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log ## 采集nginx的日志路径
codec: 'plain'
fields:
topic: nginx-log
fields_under_root: true
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.kibana:
output.logstash:
hosts: ["172.25.12.5:5044"] ## logstash接收数据
codec: json
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
(4)启动filebeat:systemctl start filebeat.service
5 Logstash的部署
(1)Logstash的部署
(2)数据从filebeat——>kafka
vim /etc/logstash/conf.d/o_kafka.conf
input {
beats {
port => 5044
codec => json
}
}
output {
kafka {
bootstrap_servers => "172.25.12.3:9092,172.25.12.4:9092,172.25.12.5:9092"
topic_id => "nginx-log"
codec => json
}
}
(3)数据从 kafka——>ES
tvim /etc/logstash/conf.d/o_es.conf
input {
kafka {
bootstrap_servers => "172.25.12.3:9092,172.25.12.4:9092,172.25.12.5:9092"
topics => ["http-log"]
}
}
output {
elasticsearch {
hosts => ["http://172.25.12.1:9200"]
index => "nginx-%{+YYYY.MM.dd}"
}
}
(4) logstash -f /etc/logstash/conf.d/ &
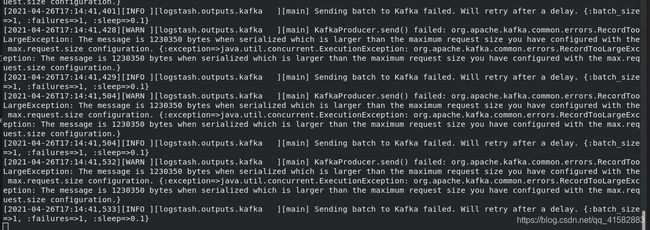

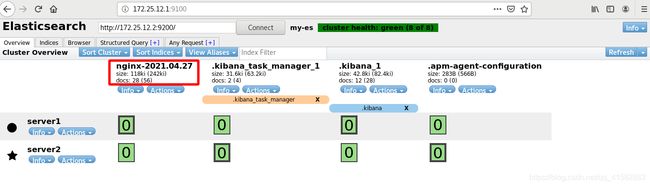
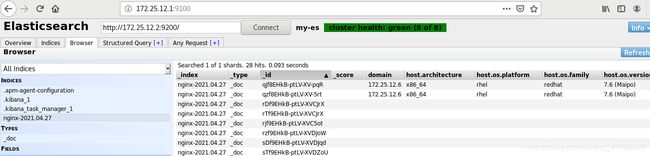
6 Kibana的部署(server7)
(1)参考博客Kibana的部署


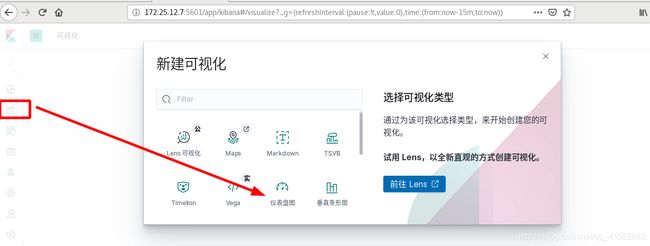

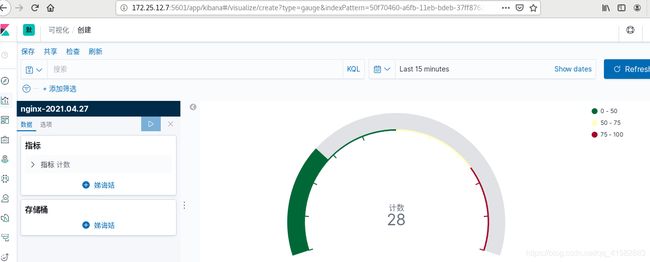



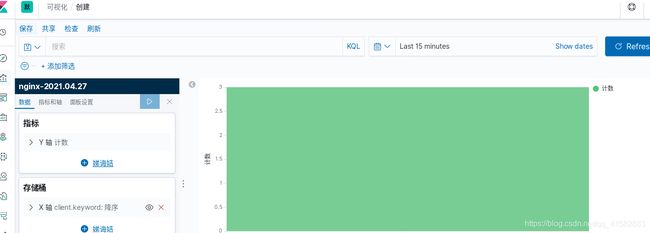

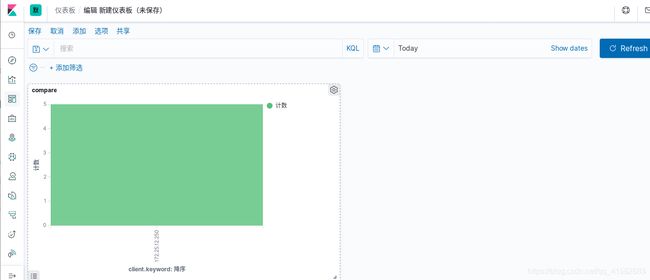
在server1上访问server6,日志数据同步更新


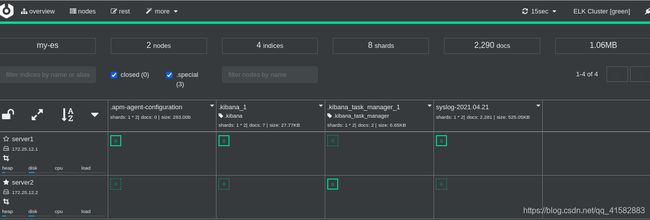
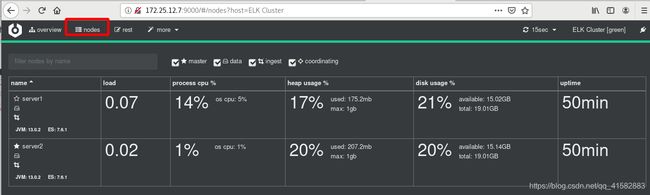
7 搭建Cerebro Elasticsearch监控
wget https://github.com/lmenezes/cerebro/releases/download/v0.8.1/cerebro-0.8.1.tgz
tar xzf cerebro-0.8.1.tgz
vim /etc/cerebro/application.conf
hosts = [
{
host = "http://172.25.12.1:9200"
name = "ELK Cluster"
},
# Example of host with authentication
#{
# host = "http://some-authenticated-host:9200"
# name = "Secured Cluster"
# auth = {
# username = "username"
# password = "secret-password"
# }
#}
]
启动服务:
[root@server7 ~]# cerebro-0.8.1/bin/cerebro
[info] play.api.Play - Application started (Prod)
[info] p.c.s.AkkaHttpServer - Listening for HTTP on /0:0:0:0:0:0:0:0:9000