Pytorch学习笔记:RNN的原理及其手写复现
目录
参考链接如下 :
RNN网络模型结构
单向循环神经网络
双向循环神经网络
RNN应用场景类型
one to many(例如诗歌生成)
many to one(文本情感分类)
many to many(词法识别,机器翻译)
Pytorch官网RNN介绍
参数
单向单层
双向单层
比较双向单层和单向单层
单向RNN与双向RNN的逐行实现
参考链接如下 :
视频链接:
29、PyTorch RNN的原理及其手写复现_哔哩哔哩_bilibili
博客链接:
循环神经网络(超详细|附代码训练)_后来后来啊的博客-CSDN博客长短时记忆网络(LSTM)(超详细 |附训练代码)_后来后来啊的博客-CSDN博客
递归神经网络(超详细|附训练代码)_后来后来啊的博客-CSDN博客
建议大家可以去看看原文论文:深度学习经典论文分析(六)-Deep Residual Learning for Image Recognition - 知乎(已翻译)
https://arxiv.org/pdf/1512.03385v1.pdf(未翻译)
RNN网络模型结构
单向循环神经网络

双向循环神经网络

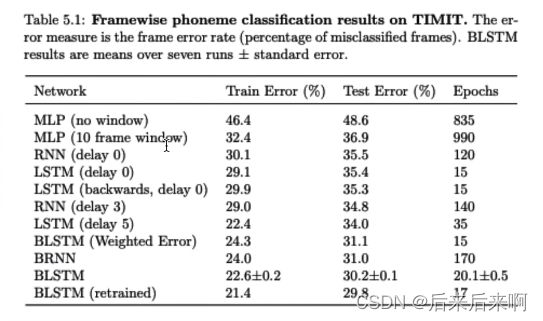
下表为不同模型在语音识别,任务分类上的表现(其中delay3,相当于拿3帧输入去更新输入,到第4帧才拿出来做预测值,有时延,但是总体性更好)
RNN应用场景类型
one to many(例如诗歌生成)

many to one(文本情感分类)
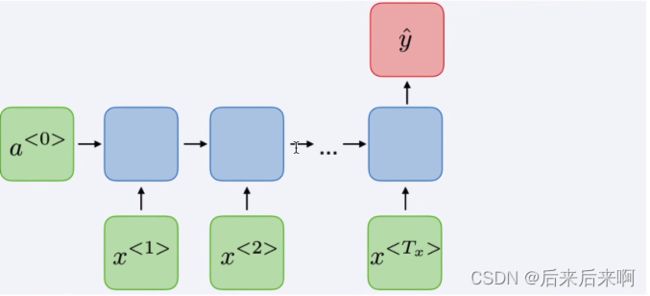
many to many(词法识别,机器翻译)
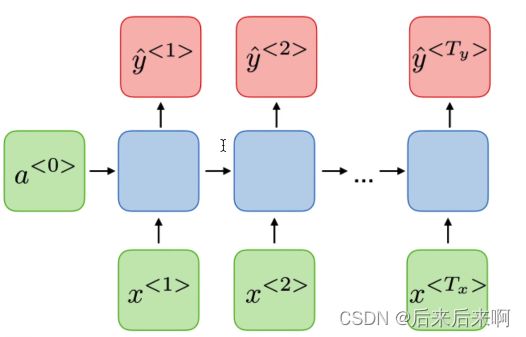

第二个(AED)更多用于更加复杂的情况下,如语音识别等
Pytorch官网RNN介绍
官网链接:RNN — PyTorch 2.0 documentation
应用多层 Elman RNN 与tanh或ReLU非线性到 输入序列。
对于输入序列中的每个元素,每个层计算以下内容 功能(计算公式):


即ht是t时刻的隐藏状态,xt是t时刻的输入状态,h(t-1)是t-1时刻的隐藏状态,h0则表示初始时刻的隐藏状态.并提供了俩种激活函数tanh和ReLU,一般状态下用的tanh激活函数
首先需要对RNN进行 实例化,提供以下参数
参数
-
input_size – 输入 x 中预期要素的数量 (输入大小,维度)
-
hidden_size – 处于隐藏状态 h 的特征数量
-
num_layers – 循环层数。例如为
num_layers=2,设置意味着将两个 RNN 堆叠在一起以形成堆叠的 RNN, 第二个 RNN 接收第一个 RNN 的输出,并且 计算最终结果。默认值:1 -
nonlinearity – 要使用的非线性。可以是
'tanh'或'relu'。默认值:'tanh' -
bias – 如果为
False,则图层不使用偏置权重b_ih和b_hh。 默认值:True -
batch_first – 如果为
True,则提供输入和输出张量 应该为 (batch, seq, feature)格式 而不是 (seq, batch, feature))格式。 请注意,这不适用于隐藏状态或单元格状态。请参阅的 有关详细信息,请参阅下面的输入/输出部分。默认值:False -
dropout – 如果非零,则在每个输出端引入 Dropout 层 RNN 层(最后一层除外),概率等于
dropout。默认值:0 -
bidirectional – 如果为
True,则变为双向 RNN。默认值:False
双向图在上有说过,可返回上面查看
以下是原文,若觉得翻译不准确,可自行翻译:
-
input_size – The number of expected features in the input x
-
hidden_size – The number of features in the hidden state h
-
num_layers – Number of recurrent layers. E.g., setting
num_layers=2would mean stacking two RNNs together to form a stacked RNN, with the second RNN taking in outputs of the first RNN and computing the final results. Default: 1 -
nonlinearity – The non-linearity to use. Can be either
'tanh'or . Default:'tanh' -
bias – If
False, then the layer does not use bias weights b_ih and b_hh. Default:True -
batch_first – If , then the input and output tensors are provided as (batch, seq, feature) instead of (seq, batch, feature). Note that this does not apply to hidden or cell states. See the Inputs/Outputs sections below for details. Default:
TrueFalse -
dropout – If non-zero, introduces a Dropout layer on the outputs of each RNN layer except the last layer, with dropout probability equal to
dropout. Default: 0 -
bidirectional – If
True, becomes a bidirectional RNN. Default:False
Inputs: input, h_0

注意点:输入一般是三维的,为sequence length * batch size * input_size(即是后面解释的输入特征)
h_0也是三个维度,第一个维度一般是是否是双向或者是否是多层决定的,若只有一层的且单向则为1
Outputs: output, h_n

注意输出是:sequence length * batch size * hidden_size
可能有小伙伴会对这三个有疑惑,那么可以看看其他博客来解答自己心中的疑惑:
sequence_length是什么
在机器学习和自然语言处理中,"sequence_length"(序列长度)通常指的是输入序列中的元素数量。对于文本数据来说,序列长度可以表示为单词、字符或其他标记的数量。在深度学习模型中,序列长度是一个重要的参数,它影响着模型的输入和输出的维度。
例如,在使用循环神经网络(RNN)或者Transformer模型处理文本时,输入序列通常被分割成固定长度的小块进行处理。序列长度可以通过填充(padding)或截断(truncation)来统一到相同的长度,以便于模型的训练和推理。
在模型的配置或参数设置中,你可能会看到一个参数叫做"sequence_length",用于指定输入序列的最大长度。这个参数可以根据你的数据集和任务需求进行调整。
tf.nn.bidirectional_dynamic_rnn中的sequence_length理解_Takoony的博客-CSDN博客
batch_size是什么
"batch size"(批大小)是指在训练神经网络时,一次输入模型的样本数量。在深度学习中,通常会将训练数据集分成多个批次进行训练,个批次包含一定数量的样本。
使用批处理训练的好处之一是可以通过并行计算来提高训练效率。相比于单个样本逐个输入模型进行训练,通过一次性输入多个样本,可以利用现代计算设备(如GPU)的并行计算能力,加快模型训练的速度。
批大小的选择对于模型的训练和泛化性能有一定影响。较大的批大小可以提高计算效率,但可能会导致模型过拟合。较小的批大小可以提供更多的梯度更新,但也可能增加训练时间和计算开销。
在选择批大小时,需要根据具体的任务和计算资源进行权衡。通常情况下,批大小是作为模型训练的超参数之一,需要进行调优以获得最佳的结果。
Batch Size的理解_Altoria.的博客-CSDN博客机器学习中的batch_size是什么?_batch size_勤奋的大熊猫的博客-CSDN博客
输入特征是什么:
在循环神经网络(RNN)中,输入特征表示的是模型接收的每个时间步的输入数据。RNN是一种适用于序列数据的神经网络模型,它通过在每个时间步上接收一个输入,同时保留一个隐藏状态来对序列进行建模。
对于文本数据来说,输入特征通常是将文本转化为数值表示。常见的方法包括使用词嵌入(word embedding)将每个单词映射到一个固定维度的向量表示,或者使用字符级别的编码方式。
以语言模型为例,输入特征可以是一个句子中前N-1个单词的词嵌入表示。在每个时间步,RNN会接收一个单词的词嵌入作为输入,并更新隐藏状态。下一个时间步的输入将是下一个单词的词嵌入,以此类推。
需要注意的是,RNN的输入特征可以根据具体的任务和数据集进行设计和调整。它可以是单词级别、字符级别或其他更高级别的表示形式,取决于解决的问题和可用的数据。
Pytorch中对RNN输入和输出的形状总结_rnn输入输出_会唱歌的猪233的博客-CSDN博客
举个简单例子:
单向单层
import torch
import torch.nn as nn
#1. 实例化一个单向,单层RNN
single_rnn = nn.RNN(4, 3, 1, batch_first=True) #(输入特征为4),hidden size为3,
input = torch.randn(1, 2, 4) #bs * sl * fs(输入特征)
output, h_n = (single_rnn(input))#输出整个状态的输出(output),及最后状态(h_n)
print(output) #输出向量1*2*3,1是batch size,2是sequence length,3是hidden size
print(h_n)输出结果为



为什么是1*2*3![]()
双向单层
#2.双向单层RNN
bidirectional_rnn = nn.RNN(4, 3, 1, batch_first=True,bidirectional=True) #(输入特征为4),hidden size为3,
bi_output, bi_b_n = bidirectional_rnn(input)比较双向单层和单向单层
print(bi_output.shape)
print(bi_b_n.shape)
print(output.shape)
print(h_n.shape)out:

单向RNN与双向RNN的逐行实现
import torch
import torch.nn as nn
bs, T = 2,3 #批大小,输入序列长度
input_size, hidden_size = 2,3 #输入特征大小,隐含层特征大小
input = torch.randn(bs, T, input_size) #随机初始化一个输入特征序列
h_prev = torch.zeros(bs, hidden_size) #初始隐含状态
#step1 调用Pytroch RNN API
rnn = nn.RNN(input_size, hidden_size, batch_first=True)
rnn_output, state_final = (input, h_prev.unsqueeze(0))
print(rnn_output)
print(state_final)以上就会打印出单向rnn
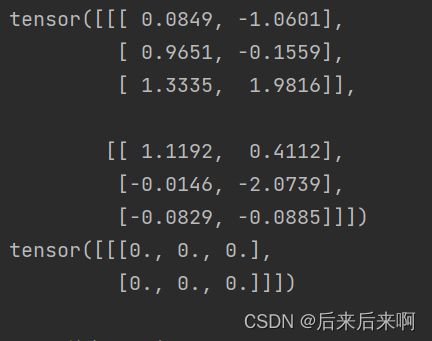
#step2 手写一个rnn_forward函数,实现单向RNN的计算原理
def rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev):
bs, T, input_size = input.shape
h_dim = weight_ih.shape(0)
h_out = torch.zeros(bs, T, h_dim)#初始化一个输出(状态)矩阵
for t in range(T):
x = input[:, t, :].unsqueeze(2) #获取当前时刻输入特征,大小为bs *input_size(*1)(扩充一维,在第三维)
w_ih_batch = weight_ih.unsqueeze(0).tile(bs, 1, 1) #bs * h_dim * input_size
w_hh_batch = weight_ih.unsqueeze(0).tile(bs, 1, 1)#bs * h_dim * h_dim
w_times_x = torch.bmm(w_ih_batch, x).squeeze(-1) #bs * h_dim
w_times_h = torch.bmm(w_hh_batch, h_prev.unsqueeze(2)).squeeze(-1) #bs * h_dim
h_prev=torch.tanh(w_times_x + bias_ih + w_times_h + bias_hh)
h_out[:, t, :] = h_prev
return h_out,h_prev.unsqueeze(0)
#验证下rnn_forward的准确性
for k,v in rnn.named_parameters():
print(k, v)
out:

分别对应公式中的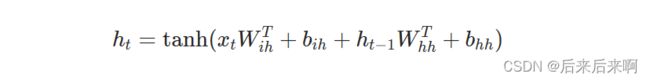
Wih,Whh,bih,bhh
# 从参数字典中获取相应的参数
weight_ih = rnn_params['weight_ih_l0']
weight_hh = rnn_params['weight_hh_l0']
bias_ih = rnn_params['bias_ih_l0']
bias_hh = rnn_params['bias_hh_l0']
# 调用自定义的rnn_forward函数
custom_rnn_output, custom_state_final = rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev)
print("\n rnn forward function output:")
print(custom_state_final)
print(custom_rnn_output)
根据原视频打出的代码
#step3 手写一个bidirectional_rnn_forward函数,实现双向rnn的计算原理
def bidirectional_rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev,\
weight_ih_reverse, weight_hh_reverse, bias_ih_reverse, bias_hh_reverse, h_prev_reverse):
bs, T, input_size = input.shape
h_dim = weight_ih.shape[0]
h_out = torch.zeros(bs, T, h_dim*2) # 初始化一个输出(状态)矩阵, 注意双向是俩倍的特征大小
forward_output = rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev)[0] #forward layer
""""https://pytorch.org/docs/stable/generated/torch.flip.html 反转张量的函数"""
backward_output = rnn_forward(torch.flip(input, [1]), weight_ih_reverse, weight_hh_reverse,
bias_ih_reverse, bias_hh_reverse, h_prev_reverse)[0] #backward layer
h_out[:, :, :h_dim] = forward_output
h_out[:, :, h_dim:] = backward_output
return h_out, h_out[:, -1, :].resahpe((bs, 2, h_dim)).transpose(0,1)
# 验证一下bidirectional_rnn_forward正确性
bi_rnn = nn.RNN(input_size, hidden_size, batch_first=True,bidirectional=True)
h_prev = torch.zeros(2, bs, hidden_size)
bi_rnn_output, bi_state_final = bi_rnn(input, h_prev)
# for k,v in rnn.named_parameters():
# print(k, v)
custom_bi_rnn_output,custom_bi_state_final = bidirectional_rnn_forward(input, bi_rnn.weight_ih_l0, bi_rnn.weight_hh_l0, bi_rnn.bias_ih_l0, bi_rnn.bias_hh_l0, h_prev[0],\
bi_rnn.weight_ih_l0_reverse, bi_rnn.weight_hh_l0_reverse, bi_rnn.bias_ih_l0_reverse, bi_rnn.bias_hh_l0_reverse, h_prev[1])出现报错
于是在在返回结果时,将双向RNN的最后一个时间步的输出和第一个时间步的输出分别取出,并使用torch.stack函数将它们堆叠在一起,以保持与nn.RNN的输出形状一致。
修改后得到以下代码
#step3 手写一个bidirectional_rnn_forward函数,实现双向rnn的计算原理
def bidirectional_rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev,\
weight_ih_reverse, weight_hh_reverse, bias_ih_reverse, bias_hh_reverse, h_prev_reverse):
bs, T, input_size = input.shape
h_dim = weight_ih.shape[0]
h_out = torch.zeros(bs, T, h_dim*2) # 初始化一个输出(状态)矩阵, 注意双向是俩倍的特征大小
forward_output = rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev)[0] #forward layer
""""https://pytorch.org/docs/stable/generated/torch.flip.html 反转张量的函数"""
backward_output = rnn_forward(torch.flip(input, [1]), weight_ih_reverse, weight_hh_reverse,
bias_ih_reverse, bias_hh_reverse, h_prev_reverse)[0] #backward layer
h_out[:, :, :h_dim] = forward_output
h_out[:, :, h_dim:] = backward_output
return h_out, torch.stack([h_out[:, -1, :h_dim], h_out[:, 0, h_dim:]], dim=0)
# 验证一下bidirectional_rnn_forward正确性
bi_rnn = nn.RNN(input_size, hidden_size, batch_first=True,bidirectional=True)
h_prev = torch.zeros(2, bs, hidden_size)
bi_rnn_output, bi_state_final = bi_rnn(input, h_prev)
# for k,v in rnn.named_parameters():
# print(k, v)
custom_bi_rnn_output,custom_bi_state_final = bidirectional_rnn_forward(input, bi_rnn.weight_ih_l0, bi_rnn.weight_hh_l0, bi_rnn.bias_ih_l0, bi_rnn.bias_hh_l0, h_prev[0],\
bi_rnn.weight_ih_l0_reverse, bi_rnn.weight_hh_l0_reverse, bi_rnn.bias_ih_l0_reverse, bi_rnn.bias_hh_l0_reverse, h_prev[1])
print("pytorch API out:")
print(rnn_output)
print(state_final)
print("\n custom bidirectional_rnn_forward function output:")
print(custom_bi_state_final)
print(custom_bi_rnn_output)out:
建议没有搞懂这串代码的小伙伴可以去看看原视频,是个很优秀的up主做的:29、PyTorch RNN的原理及其手写复现_哔哩哔哩_bilibili
或者去看看另一篇注释更多的博客:【NLP】RNN理解(Pytorch实现)_rnn 源码实现_myaijarvis的博客-CSDN博客
今天就到这啦,各位宝们晚安啦