ChatGPT的狂飙之路
ChatGPT的狂飙之路
第一章:AI顶流-闪耀互联网世界的新宠
根据UBS发布的研究报告显示,ChatGPT在1月份的月活跃用户数已达1亿,成为史上用户数增长最快的消费者应用。TikTok在全球上线后花了大约9个月的时间才增加了1亿用户,而Instagram则花了两年半的时间。

[7]
---在线课程供应商Study.com向1000名18岁以上的学生发起一项调查,结果显示美国89%的学生使用ChatGPT完成作业。
---2023年2月2日,微软官方公告表示,旗下所有产品将全线整合ChatGPT,除此前宣布的搜索引擎必应、Office外,微软还将在云计算平台Azure中整合ChatGPT,Azure的OpenAI服务将允许开发者访问AI模型。
---2023年2月4日消息,以色列总统艾萨克·赫尔佐格(Isaac Herzog)发表了部分由人工智能(AI)撰写的演讲,成为首位公开使用ChatGPT的世界领导人。[11]
ChatGPT作为一款现象级自然语言处理(NLP)工具,在全球掀起了人工智能的浪潮。这款由美国OpenAI公司研发的聊天机器人程序,于2022年11月30日发布。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码,写论文等任务。
那么如此强大的模型,到底是如何诞生又一步步演变而来的呢?
[1]
第二章:GPT家族-从男孩到男人的崛起之路
到底什么是ChatGPT?
我们先来看一下ChatGPT自己的回答:


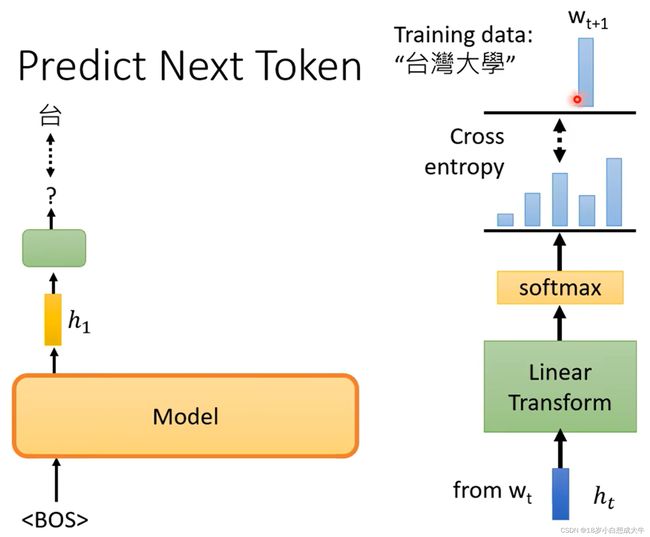
ChatGPT本质是一个大型语言模型(Large Language Models,LLMs),通过输入给LLM合适的数据集,设置相应task的损失函数计算模型的输出与我们期望输出之间的差距,再使用梯度下降策略对模型参数进行更新,从而让模型在测试时可以完成我们需求的任务;


ChatGPT不是一蹴而就的,初代版本是在2018年OpenAI推出的GPT1,而后经过GPT2,GPT3,InstructGPT的发展,才演化出来了今天我们看到的ChatGPT,接下来将详细介绍每个版本的GPT。
GPT1梦开始的地方:2018年OpenAI推出GPT的开山之作Improving Language Understanding by Generative Pre-Training,模型以Transformer的Decoder为基础架构进行堆叠,先在大量语料上进行预训练,再通过不同的下游任务进行微调。

[2]
与谷歌的Bert不同的是,GPT重点利用Decoder中的Masked Self-Attention,使模型只能通过上文信息来预测下文信息,而不是像Bert一样通过上下文信息来做完形填空题,这使得GPT具有更强的生成能力。
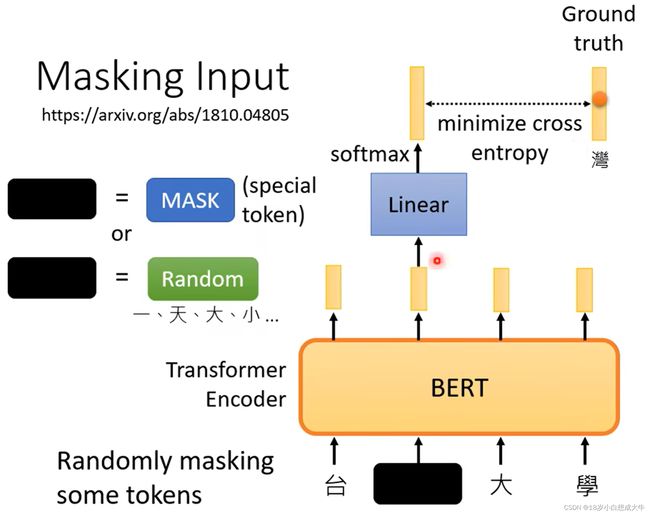
[3], 图左:Bert,图右:GPT
GPT1一经面世就以绝对的performance吊打一众NLP模型,为后续GPT的发展奠定了基础。
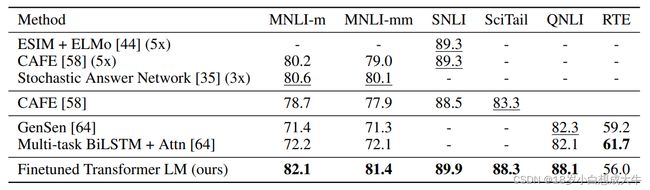
[2]
GPT2大力出奇迹:由于微调阶段需要不同任务大量的数据集,造成高昂的标注成本,所以GPT2舍弃了GPT1的微调,只使用更大规模多领域的语料进行预训练,相较于GPT1的1.17亿参数量和5G的预训练数据量,GPT2模型参数增加到15亿,预训练数据量达到40G;
强大的参数规模以及数据量使得GPT2在各种Zero-shot Learning的setting上达到绝对的SOTA.

[4]
GPT3既然追求刺激,那就贯彻到底:在增大网络模型参数和数据量的趋势下,模型效果出奇的好,这使得GPT3更加关注了对“大”的执念。2020年推出的GPT3,拥有100倍于GPT2的1750亿参数,预训练数据量更是达到45TB傲视群雄;

[4]
GPT3也首次使用Prompt学习开启了NLP领域的学习新范式。
传统的Finetune学习是在预训练好的Backbone后加Linear层进行参数的微调,虽然能够取得适应各种任务的效果,但实际上破坏了Backbone内部的参数系统;
而Prompt学习则是通过调整数据输入的形式,让“任务”走向“模型”,充分挖掘了模型本身的能力;
[4]
InstructGPT开启家族新篇章:为了让GPT的回答更像人类一样,对解决任务是有帮助的(Helpful),诚实的不会误导人类(Honest),不带歧视偏见的(Harmless),更强大的InstructGPT诞生了。
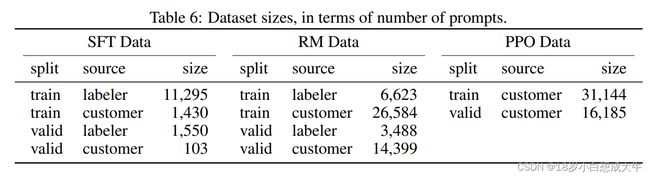
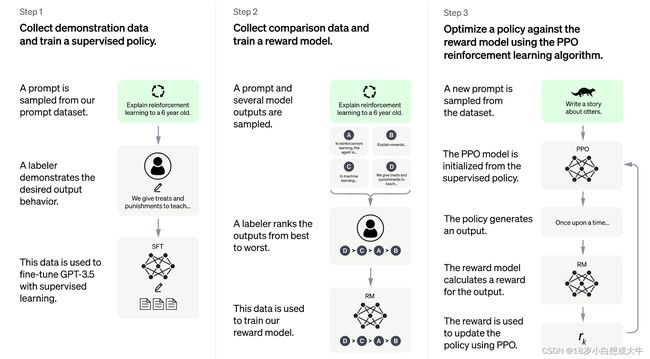
InstructGPT的训练过程分为三个阶段:

[5]
- 第一阶段:利用人类标注的数据对GPT3进行有监督的微调:
OpenAI通过40个人的标注团队生产了一部分的提示数据(Prompt dataset),并用这部分数据对GPT3进行有监督的微调(Supervised Finetune),使得此时的模型具备一定“人类”的偏向;
- 第二阶段:引入RLHF思想,训练奖励模型RM
给第一阶段训练好的模型输入prompt,标注团队将模型输出的k个不同回答按人类的喜好进行排序,再通过以下损失函数训练一个新的GPT3模型作为Reward Model;

[5]
- 第三阶段:RM+PPO-ptx=InstructGPT
将prompt输入给第一阶段的模型,输出的回答通过二阶段的RM模型进行打分,最后通过PPO-ptx算法优化一阶段的模型,得到最终的InstructGPT;之所以要再PPO的基础上加ptx项,是为了防止模型在人工标注的数据集上过拟合,所以在其他下游任务上进行一定的微调;
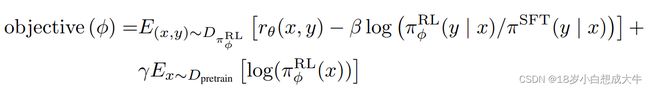
[5]
InstructGPT实际上已经能进行上下文对话了,并且生成的结果也更符合人类期待的反馈,但数据量的限制导致模型的表现仍没有达到一个更类人的效果。
[5]
ChatGPT-GPT集大成者:根据OpenAI的官方说明,ChatGPT的训练方式跟InstructGPT完全一致,只不过ChatGPT在GPT3.5上进行微调(GPT3.5是OpenAI在2021年Q4训练的InstructGPT模型,在自动编写代码方面有较强的能力),另外是数据集不同,具体的标注团队规模与数据集规模目前还并未透露。
[1]
第三章:凛冬中的焰火-掀起资本炒作狂潮
AIGC:AI Generated Content,是指利用人工智能技术来生成内容,AIGC也被认为是继UGC(用户生成内容)、PGC(专家生产内容)之后的新型内容生产方式,AI绘画、AI写作等都属于AIGC的分支。
AIGC上游主要包括数据供给方、算法机构、创作者生态以及底层配合工具等,中游主要是文字、图像、音频和视频处理厂商,其中玩家众多,下游主要是各类内容创作及分发平台以及内容服务机构等。
而ChatGPT在产业链中游起着数字内容智能编辑的角色,可以通过内容设计,内容生成等方式将数字内容或者使用接口释放给下游,从而帮助企业实现盈利。
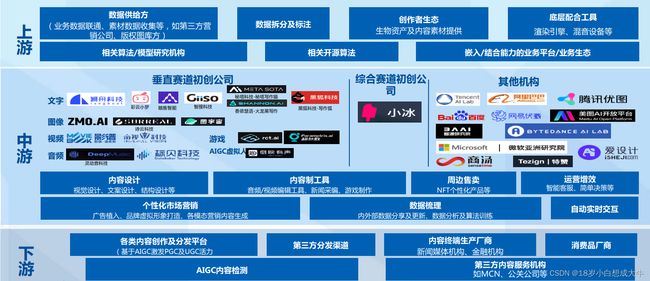
[6,7]
在ChatGPT猛烈的攻势下,其余各大厂商坐不住了。

[7]
在ChatGPT发布后,谷歌CEO在公司内部发布了“红色警报” (Code Red),敦促团队解决ChatGPT对公司搜索引擎业务构成的威胁,同时批准了在谷歌搜索引擎中加入AI聊天机器人的计划。
2月4日,谷歌注资3亿美元投资ChatGPT竞品——Anthropic,谷歌将获得约10%的股份, Anthropic计划将次轮资金用于购买谷歌云计算部门的计算资源;Anthropic开发了一款名为Claude的智能聊天机器人,据称可与ChatGPT相媲美(仍未发布)。
Anthropic和Open AI渊源颇深,其联合创始人曾担任OpenAI 研究副总裁

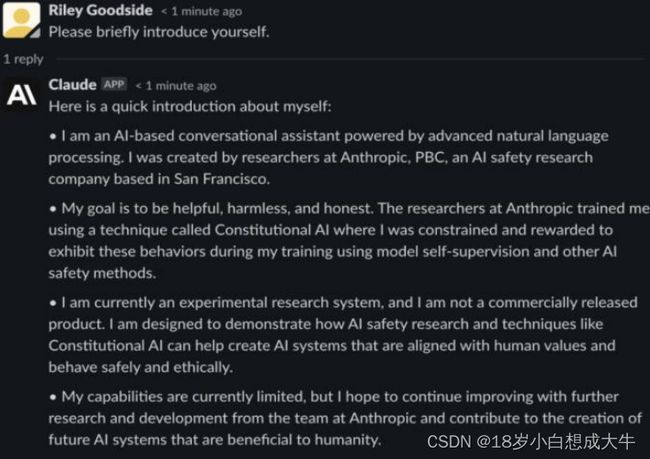
[7,8],图左:Anthropic,图右:聊天机器人Claude
资本的嗅觉永远是最灵敏的,利用 ChatGPT 写稿和发稿的 Buzzfeed,股价在两个交易日内涨超三倍。与此同时,大洋彼岸的东方A股也迎来了ChatGPT情绪炒作的高潮,继2022年底的消费龙头西安饮食以及数字经济龙头恒久科技之后,汉王科技以ChatGPT龙头的身份强势7连板,股价在一周内实现翻倍,占据了A股市场为数不多的短线资金。火热的题材炒作甚至已经从ChatGPT概念炒作到了上游CPO(Co-packagedoptics)算力题材,以及反ChatGPT的数字水印(用于确保数字内容质量和真实性的一种技术)题材;典型代表二波ChatGPT龙头鸿博股份也以5连板的姿态引领市场的资金,强势席卷特斯拉、固态电池、光伏等一众概念;
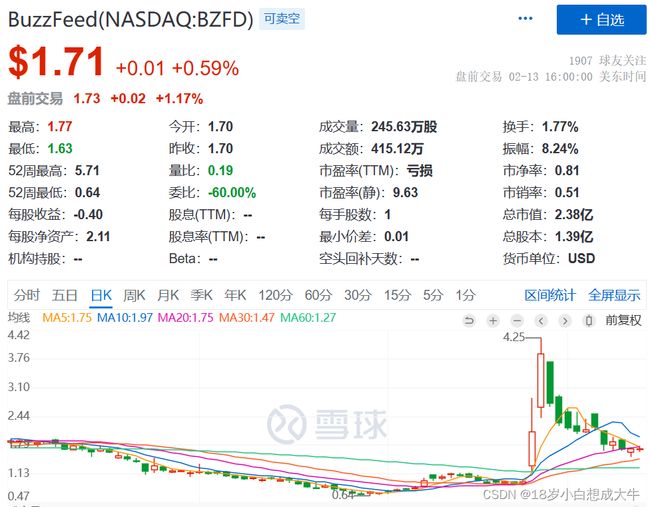

[9]
第四章:关于ChatGPT+的展望
ChatGPT仍属于GPT3.5系列的作品,未来OpenAI还回推出更为强大的GPT4,据传说GPT4是一个超大规模的跨模态生成模型,虽然OpenAI 尚未发布关于该模型的官方信息,但我们可以预先展望一下:
更大规模的语料训练:既然大模型+大数据的技术路线已被证实有效,那GPT4很有可能继续增加语料训练的规模,GPT4的数据集要比以往GPT大至少一个数量级,也就是说它可能在10万亿个token的数据集上进行训练[10];
更为准确的内容输出:ChatGPT输出的内容仍存在不真实、虚假的缺点现象,GPT4有可能通过更为先进的算法更大规模的模型参数,对输出内容进行进一步的矫正;
强大的跨模态生成能力:目前的ChatGPT仅局限于文本的生成,未来的GPT4有可能整合了文本生成图像、文本生成视频、视频文案生成,文本指导视频编辑,视频续写等一系列功能;
ChatGPT的热度不会戛然而止,但到底是情绪炒作还是基本面的改善,还有待时间的验证;
ChatGPT到底是真的颠覆了以往模型对语言内容理解,还是仅仅因为超大数据+超大模型的加持下,产生了一个特大号版本的“聊天机器”,也仍需要更多的评价标准来验证;
但无论ChatGPT能做到什么程度,在数字经济为大发展方向的今天,在人工智能逐渐能取代低价值劳动力的今天,我们应该成为什么角色,才能不被时代的浪潮抛弃,是面对现在的ChatGPT以及未来更多的‘ChatGPT’最值得思考的问题;
参考文献:
1. https://openai.com/blog/chatgpt/
2. https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
3. https://www.bilibili.com/video/BV1Wv411h7kN/?spm_id_from=333.337.search-card.all.click
4. https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
5. https://arxiv.org/pdf/2203.02155.pdf
6. http://www.caict.ac.cn/,
7. https://www.gtja.com/content/business/research/profile.html
8. https://finance.sina.com.cn/
9. https://xueqiu.com/
10. https://www.163.com/dy/article/HQBAUOM3051193U6.html
11. https://baike.baidu.com/item/ChatGPT/62446358?fr=aladdin