论文阅读之推荐1-Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation
Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation
- 0.0 作者简介
- 1.0 摘要
- 2.0 简介
-
- 2.1 问题解决的思考过程
-
- 2.1.1 预想流程
- 2.1.2 待解决的问题
- 2.1.3 哪些技术的帮助和支持
- 2.1.4 如何实现
- 3.0 PeterRec
-
- 3.0 一些定义
- 3.1 模型结构
-
- 3.2 预训练阶段
-
- 3.2.1 预训练目标
- 3.2.2 预训练模型结构
-
- 3.2.2.1 空洞卷积和残差结构
- 3.2.3 损失函数
- 3.3 微调阶段
-
- 3.3.1 模型补丁和插入方法
- 3.3.2 损失函数
- 4.0 实验
-
- 4.1 探究问题
- 4.2 实验配置
- 4.3 实验结果
- 参考文章
配合使用效果更佳, 文稿
0.0 作者简介

作者详情
1.0 摘要
- 发现: 推荐系统中目前还没有迁移学习的尝试;
- 想法: 微调一个大的预训练网络, 然后将该网络应用到其他推荐任务中;
- 挑战: 参数低效使用(parameter inefficient)
- 解决: Parameter-efficient transfer learning architecture (PeterRec)
2.0 简介
- 举例: 抖音用户每周观看成百上千的小视频(每个视频的平均时长大概在20秒左右)
- 已有的: 深度神经网络GRURec, NextItNet
- 存在的问题: 迁移能力弱,不具有普适性
2.1 问题解决的思考过程
2.1.1 预想流程
- 在源域(任务)中,使用user-item的有序数据,无监督的训练预训练模型,用户有大量交互数据
- 在目标域(任务)中使用该模型进行预测, 大部分为冷启或新用户
2.1.2 待解决的问题
- 在源任务数据上训练预训练模型
- 设计微调框架,在目标任务中提取用户表征
- 设计适应方法,保证微调框架在不同的目标任务使更多的参数实现共享,参数共享最大化
2.1.3 哪些技术的帮助和支持
- fine-tuning an additional output layer to project transferred knowledge from a source domain to a target domain -(微调一个额外的输出层,将特征(知识)从源任务迁移到目标任务) --> 差
- fine-tuning the last (few) hidden layers along with the output layer - (微调最后一个隐藏层) —>好
2.1.4 如何实现
- 无监督训练序列化神经网络作为预训练模型
- 预训练的模型用在监督学习的目标任务中
- 可分离的嫁接神经网络(模型补丁)
3.0 PeterRec
3.0 一些定义
源域(任务) S \mathcal{S} S: 可以是具有用户交互行为的一些小视频,新闻等
目标域(任务) T \mathcal{T} T: 另一个预测任务(用户的交互行为很少,甚至没有)
公共域 U \mathcal{U} U: S \mathcal{S} S 和 T \mathcal{T} T 中公共用户的年龄,婚姻状况等画像
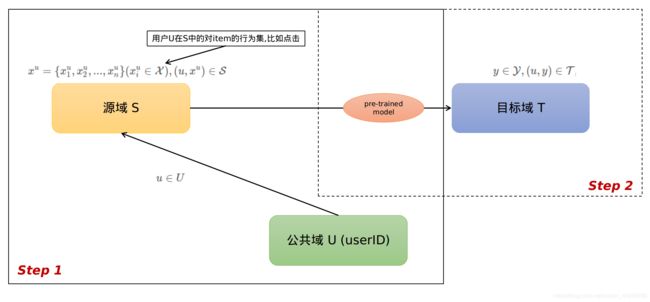
3.1 模型结构
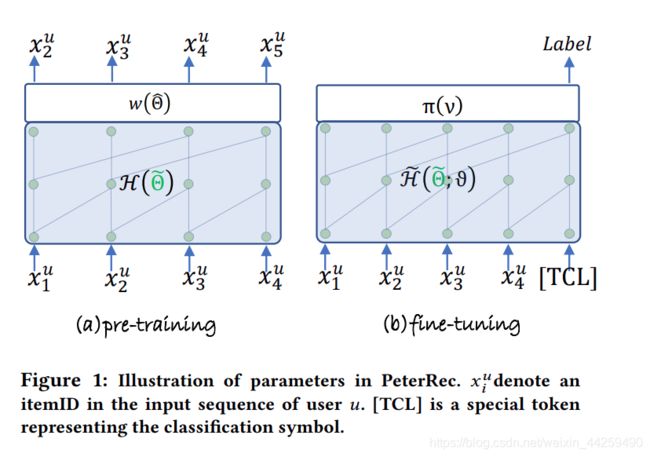
在模型结构这张图中,左边是预训练图, H ( Θ ~ ) \mathcal{H} ( \widetilde{ \Theta}) H(Θ ) 是预训练网络, Θ ~ \widetilde{ \Theta} Θ 包含embedding和卷积层, w ( Θ ^ ) w(\hat{\Theta}) w(Θ^) 和 π ( v ) \pi(v) π(v) 分别是预训练和微调的分类层, 右图微调结构 H ~ ( Θ ~ , ϑ ) \widetilde{\mathcal{H}}(\widetilde{ \Theta}, \vartheta) H (Θ ,ϑ) Θ ~ \widetilde{ \Theta} Θ 保持不变, ϑ \vartheta ϑ 就是之前说的作者提出的模型补丁部分
在预训练阶段,采用单向无监督的方式, 根据用户观看的前 k 个视频预测其可能会看的下一个视频。输入是用户在腾讯视频看过的视频 id 序列 [ x 1 , x 2 , x 3 , ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ , x n − 1 ] [x_1, x_2, x_3,······, x_n-1] [x1,x2,x3,⋅⋅⋅⋅⋅⋅,xn−1],然后通过 embedding lookup 的方式获取每一个视频的隐向量并输入到预训练网络中;输出是对应的下一个视频 id,即 [ x 2 , x 3 , ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ , x n − 1 , x n ] [x_2, x_3,······, x_n-1, x_n] [x2,x3,⋅⋅⋅⋅⋅⋅,xn−1,xn]。可以看到,PeterRec 模型不需要借助任何图像和文本特征,仅需要用户点击视频的 ID 即可,视频的向量表示完全由模型训练得到,省去了特征工程的步骤, 这种预训练方式已经被应用于 CV 和 NLP 领域,并且取得了非常认可的效果,然而并没有在推荐系统领域得到推广。
微调(finetune)阶段是根据用户在腾讯视频的观看记录,预测其可能会在 QQ 看点感兴趣的视频。输入是 [ x 1 , x 2 , x 3 , ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ , x n − 1 , x n , [ C L S ] ] [x_1, x_2, x_3,······, x_n-1, x_n, [CLS] ] [x1,x2,x3,⋅⋅⋅⋅⋅⋅,xn−1,xn,[CLS]],其中 [ x 1 , x 2 , x 3 , ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ , x n − 1 , x n ] [x_1, x_2, x_3,······, x_n-1, x_n] [x1,x2,x3,⋅⋅⋅⋅⋅⋅,xn−1,xn] 为用户在腾讯视频看过的视频 ID 序列, [ C L S ] [CLS] [CLS] 是一个特殊的记号,表示在这个位置输出分类结果;输出 Label 是 QQ 看点的视频 ID,即预测用户在 QQ 看点可能会看的 top-N 个视频 ID。
3.2 预训练阶段
3.2.1 预训练目标
通过训练一个有序的user-item序列,来预测用户对下一个item行为的概率
p ( x u ; Θ ) = Π i = 1 n p ( x i u ∣ x 1 u , . . . x i − 1 u ; Θ ) p(x^u; \Theta) = \Pi^n_{i=1}p(x^u_i|x^u_1, ...x^u_{i-1}; \Theta) p(xu;Θ)=Πi=1np(xiu∣x1u,...xi−1u;Θ)
Θ \Theta Θ包含神经网络的参数 Θ ~ \widetilde{ \Theta} Θ 和分类层的参数 Θ ^ \hat{\Theta} Θ^
但,有研究证明,用户的对item的行为其实不是严格有序的,如果用户对item1, item2, item3都进行的点击,那么其实item的顺序不一定必须是1,2,3;也可以是2,1,3, 因此作者随机的mask掉一些item,来缓解严格有序的问题;
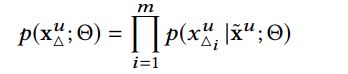
3.2.2 预训练模型结构
3.2.2.1 空洞卷积和残差结构
空洞卷积作用: 增加感受野
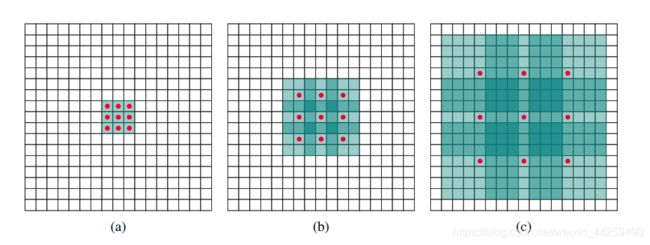
残差结构作用: 保留原始特征,防止梯度爆炸
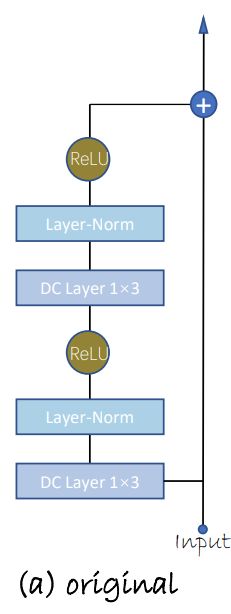
3.2.3 损失函数
目标是最大化预测概率,那么优化的目标就是最小化交叉熵(CE)
![]()
3.3 微调阶段
输入是 [ x 1 , x 2 , x 3 , ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ , x n − 1 , x n , [ C L S ] ] [x_1, x_2, x_3,······, x_n-1, x_n, [CLS] ] [x1,x2,x3,⋅⋅⋅⋅⋅⋅,xn−1,xn,[CLS]],其中 [ x 1 , x 2 , x 3 , ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ , x n − 1 , x n ] [x_1, x_2, x_3,······, x_n-1, x_n] [x1,x2,x3,⋅⋅⋅⋅⋅⋅,xn−1,xn] 为用户在腾讯视频看过的视频 ID 序列, [ C L S ] [CLS] [CLS] 是一个特殊的记号,表示在这个位置输出分类结果;输出 Label 是 QQ 看点的视频 ID,即预测用户在 QQ 看点可能会看的 top-N 个视频 ID。
3.3.1 模型补丁和插入方法

为了实现对预训练网络参数的最大化共享,微调阶段仅对预训练模型做了两处改动
- 在参差模块中串行的增加了模型补丁, 且参数量是原始空洞卷积的不到1/10
- 直接移除预训练 softmax 层,然后添加新任务的分类层。
3.3.2 损失函数
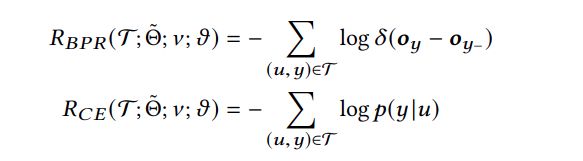
4.0 实验
4.1 探究问题
- 无监督的预训练模型是否对下游的其他推荐任务有帮助
- 对比整个模型的更新,PeterRec和模型补丁表现如何
- PeterRec对冷启的效果如何
- PeterRec是否有其他的发现
4.2 实验配置
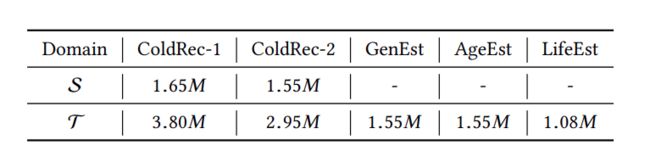
训练集: 70%
验证集: 3%
测试集: 27%
超参: GPU-Tesla P40 embedding维度256 学习率 0.001 batch size 512 卷积核大小 3
4.3 实验结果
-
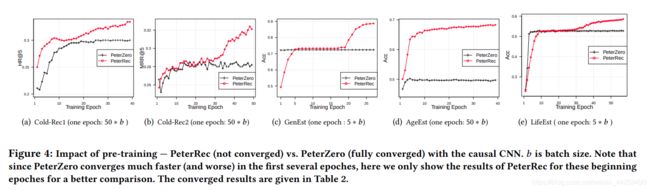
PeterRec在有预训练模型的情况下效果会更好
-
以下是几种微调方式比较,如图 5 所示。图中证实 PeterRec 仅仅微调模型补丁和 softmax 层参数达到了跟微调所有参数一样的效果,但是由于仅有少数参数参与优化,可以很好的抗过拟合现象。
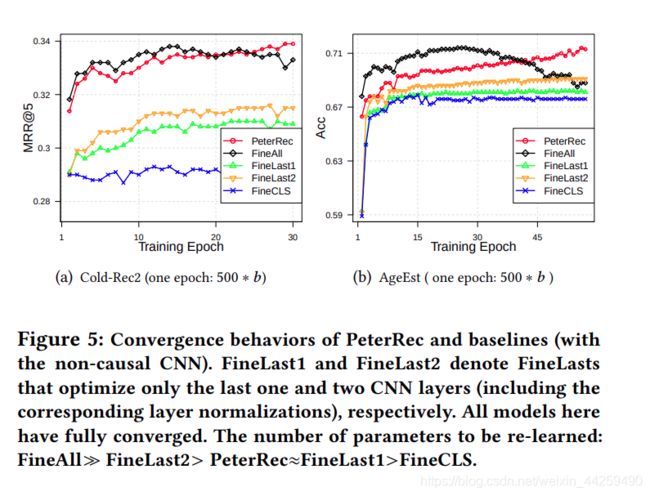
-
这一实验将 PeterRec 与常规的比较知名的 baseline 进行比较,包括冷启动推荐效果和用户画像预测效果, 精确率的比较
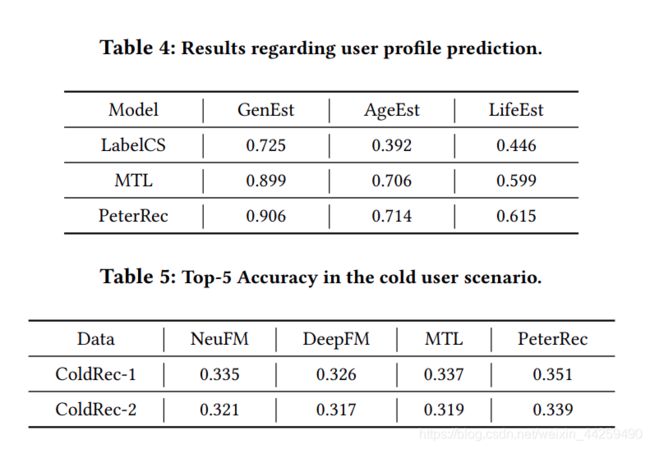
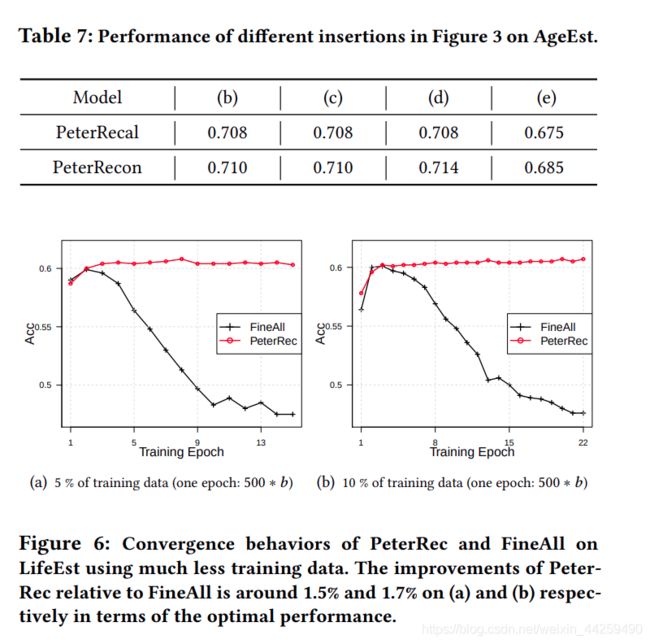
4. 在少量标签有效的情况下 PeterRec 效果。可以发现 PeterRec 不仅超过 FineAll,而且相对于 FineAll 微调过程几乎不会出现过拟合现象。
参考文章
https://arxiv.org/pdf/2001.04253.pdf
https://github.com/fajieyuan/sigir2020_peterrec
https://cloud.tencent.com/developer/article/1630031
https://blog.csdn.net/abcdefg90876/article/details/109505669