HashMap遍历使用entrySet的效率真的比keyset高?
HashMap是一个比较常用的映射。当我们遍历的时候会怎样写呢?
我一开始时这样写的:
for (String s : map.keySet()){
map.get(s);
}
for (Object result: map.values()) {
if (result != null){
result.toString();
}
}然而,这样写真的好吗?
某次上网看到这样的写法:
for (Map.Entry entry: map.entrySet()) {
if (entry != null){
entry.getValue();
count++;
}
} 大家都认可这是效率最高的遍历方法,那么为什么呢?
我首先写了简单的方法测试一下这三种方法遍历所用的时间:
@Test
public void test(){
Map map = new HashMap<>();
for (int i = 0; i<10000; i++){
map.put("test" + i, i);
}
//第一种遍历
long star1 = System.nanoTime();
for (int i = 0; i<10000; i++){
for (Map.Entry entry: map.entrySet()) {
if (entry != null){
entry.getValue();
}
}
}
System.out.println("entrySet:" + ((System.nanoTime()-star1)/10000));
//第二种遍历
long star2 = System.nanoTime();
for (int i = 0; i<10000; i++){
for (String s : map.keySet()){
map.get(s);
}
}
System.out.println("keySet" + ((System.nanoTime()-star2)/10000));
//第三种遍历
long star3 = System.nanoTime();
for (int i = 0; i<10000; i++){
for (Object result: map.values()) {
if (result != null){}
}
}
System.out.println("values" + ((System.nanoTime()-star3)/10000));
} 对10000个key,value的hashMap进行10000遍历,取平均值的结果:
entrySet:79827
keySet115419
values71514可见HashMap.entrySet()方法遍历确实是快一点。那么就想知道为什么这个方法运行速度快呢?
这里需要从HashMap的数据结构说起:
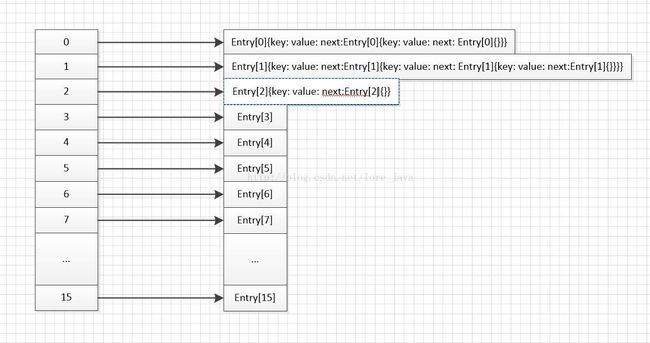
如图,是hashMap的数据结构图。画成这样,程序员看一眼就很清楚结构了。首先它是基于一个可扩容的数组排列的。一般对应的key会有它的hash码,根据hash%16(数组长度)决定该条数据排列在哪个角标的后面。比如hash值为16的数据就会排在0后面,hash值18的就会排在2后面。
那么如果在hash值为16的数据put进hashMap之后,又put进一个hash值为0或者key为null的数据。此时,原先hash值为16的数据会指向新数据的next字段,从而形成一个单链表。
简单说明了hashMap数据的存储过程,再来看看这些方法是怎么遍历的:
第一种,实际就是通过map.entrySet()获取对应的Entry,然后获取Entry中的value属性。这个方法具体是怎么获取Entry的呢?
首先就是遍历数组,再遍历数组每个元素后面对应的链表,这种方式其实就是实现hashMap的原理。
第二种,首先遍历出hashMap的所有的key,再次根据key去查找对应的值,而单链表的特性大家都知道,增删快,查找慢。
第三种,只遍历value速度确实比第一种快,但实用性比较低。
HashMap相关源码参考