代码随想录算法训练营第天十二天丨 栈与队列part03
文档讲解:代码随想录
状态:未完成
原因:今天题目所用到的队列是我之前从未接触的,第一次接触对于概念和逻辑及方法不是那么清晰,都是靠跟着卡哥的视频和对应的代码思路写出来的。所以不算完成。
239. 滑动窗口最大值
思路
此时我们需要一个队列,这个队列呢,放进去窗口里的元素,然后随着窗口的移动,队列也一进一出,每次移动之后,队列告诉我们里面的最大值是什么。
这个队列应该长这个样子:
class MyQueue {
public:
void pop(int value) {
}
void push(int value) {
}
int front() {
return que.front();
}
};每次窗口移动的时候,
- 调用que.pop(滑动窗口中移除元素的数值),
- que.push(滑动窗口添加元素的数值),
- 然后que.front()就返回我们要的最大值。
然后再分析一下,队列里的元素一定是要排序的,而且要最大值放在出队口,要不然怎么知道最大值呢。
但如果把窗口里的元素都放进队列里,窗口移动的时候,队列需要弹出元素。
那么问题来了,已经排序之后的队列 怎么能把窗口要移除的元素(这个元素可不一定是最大值)弹出呢。
大家此时应该陷入深思.....
其实队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。
那么这个维护元素单调递减的队列就叫做单调队列,即单调递减或单调递增的队列。C++中没有直接支持单调队列,需要我们自己来实现一个单调队列
不要以为实现的单调队列就是 对窗口里面的数进行排序,如果排序的话,那和优先级队列又有什么区别了呢。
来看一下单调队列如何维护队列里的元素。
动画如下:
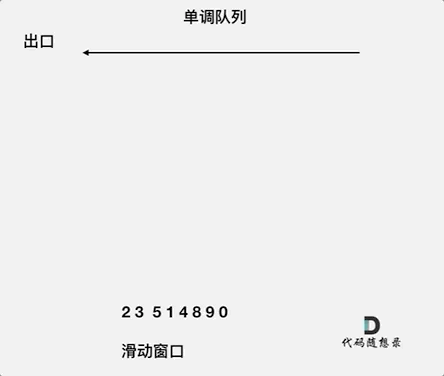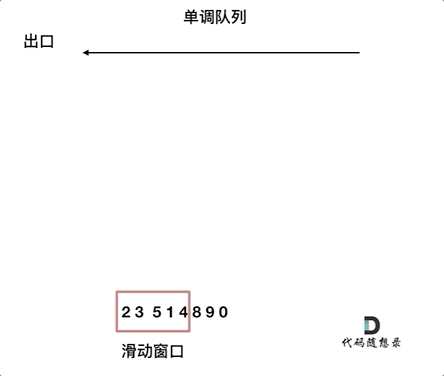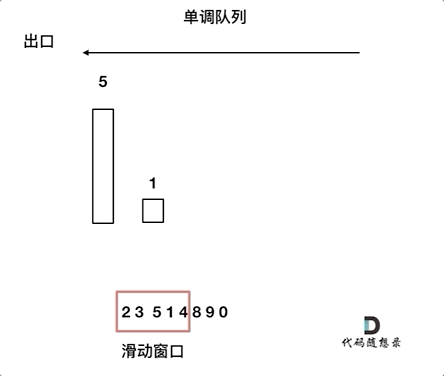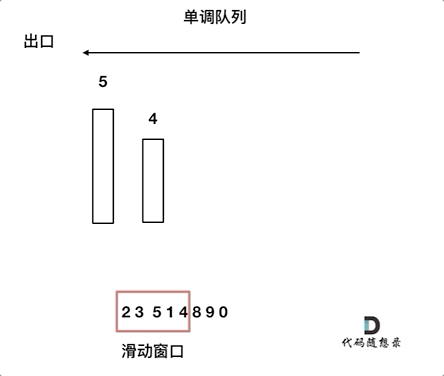
对于窗口里的元素{2, 3, 5, 1 ,4},单调队列里只维护{5, 4} 就够了,保持单调队列里单调递减,此时队列出口元素就是窗口里最大元素。
此时大家应该怀疑单调队列里维护着{5, 4} 怎么配合窗口进行滑动呢?
设计单调队列的时候,pop,和push操作要保持如下规则:
- pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- push(value):如果push的元素value大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。
为了更直观的感受到单调队列的工作过程,以题目示例为例,输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3,动画如下:
那么我们用什么数据结构来实现这个单调队列呢?
使用deque最为合适,在文章栈与队列:来看看栈和队列不为人知的一面 (opens new window)中,我们就提到了常用的queue在没有指定容器的情况下,deque就是默认底层容器。
基于刚刚说过的单调队列pop和push的规则,代码不难实现,如下:
class MyQueue{
Deque deque = new LinkedList<>();
//弹出元素时,比较当前要弹出的数值是否等于队列出口的数值,如果相等则弹出
//同时判断队列当前是否为空
void poll(int val){
if (!deque.isEmpty() && deque.peek() == val){
deque.poll();
}
}
//添加元素时,如果要添加的元素大于入口处的元素,就将入口处的元素弹出
//保证队列元素单调递减
//比如此时队列元素 3,1。 2将要入队,比1大。所以1弹出,此时队列:3,2
void add(int val){
while (!deque.isEmpty() && val > deque.getLast()){
deque.removeLast();
}
deque.add(val);
}
//队列队顶元素始终为最大值
int peek(){
return deque.peek();
}
}
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if (nums.length == 1){
return nums;
}
int len = nums.length - k + 1;
//存放结果元素的数组
int[] res = new int[len];
int num = 0;
//自定义队列
MyQueue myQueue = new MyQueue();
//先将前 k 个元素放入队列
for (int i = 0; i < k; i++) {
myQueue.add(nums[i]);
}
res[num++] = myQueue.peek();
for (int i = k; i < nums.length; i++) {
//滑动窗口移除最前面的元素,移除是判断该元素是否放入队列
myQueue.poll(nums[i - k]);
//滑动窗口加入最后的元素
myQueue.add(nums[i]);
//记录对应的最大值
res[num++] = myQueue.peek();
}
return res;
}
} 上述思路是我将卡哥的代码随想录的思路完整的抄录了下来,方便以后自己查阅。上述代码是我对着卡哥的思路和代码敲出来的,跟着写一次之后思路会情绪很多,希望二刷的时候能吃透该题。
347.前 K 个高频元素
思路
这道题目主要涉及到如下三块内容:
- 要统计元素出现频率
- 对频率排序
- 找出前K个高频元素
首先统计元素出现的频率,这一类的问题可以使用map来进行统计。
然后是对频率进行排序,这里我们可以使用一种 容器适配器就是优先级队列。
什么是优先级队列呢?
其实就是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
什么是堆呢?
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
本题我们就要使用优先级队列来对部分频率进行排序。
为什么不用快排呢, 使用快排要将map转换为vector的结构,然后对整个数组进行排序, 而这种场景下,我们其实只需要维护k个有序的序列就可以了,所以使用优先级队列是最优的。
此时要思考一下,是使用小顶堆呢,还是大顶堆?
有的同学一想,题目要求前 K 个高频元素,那么果断用大顶堆啊。
那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。
而且使用大顶堆就要把所有元素都进行排序,那能不能只排序k个元素呢?
所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
寻找前k个最大元素流程如图所示:(图中的频率只有三个,所以正好构成一个大小为3的小顶堆,如果频率更多一些,则用这个小顶堆进行扫描)

import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
/*Comparator接口说明:
* 返回负数,形参中第一个参数排在前面;返回正数,形参中第二个参数排在前面
* 对于队列:排在前面意味着往队头靠
* 对于堆(使用PriorityQueue实现):从队头到队尾按从小到大排就是最小堆(小顶堆),
* 从队头到队尾按从大到小排就是最大堆(大顶堆)--->队头元素相当于堆的根节点
* */
class Solution {
public int[] topKFrequent(int[] nums, int k) {
Map map = new HashMap<>();//key 为数组中的元素值,val 为对应的出现的次数
for (int num : nums) {
map.put(num,map.getOrDefault(num,0) + 1);
}
//在优先队列中存储二元组(num,cnt),cnt 表示元素值 num 在数组中出现的次数
//出现次数按从对头到队尾的顺序是从小到大排,出现次数最低的在队头【相当于小顶堆】
//(pair1,pair2)->pair1[1]-pair2[1] 是一个比较函数,用来定义元素的优先级。在这个比较函数中,通过比较数组的第二个元素的大小来确定优先级。
PriorityQueue pq = new PriorityQueue<>((pair1,pair2) -> pair1[1] - pair2[1]);
for (Map.Entry entry : map.entrySet()) {
if (pq.size() < k){//小顶堆元素个数小于k 个时直接加
pq.add(new int[]{entry.getKey(),entry.getValue()});
}else {
if (entry.getValue() > pq.peek()[1]){//当前元素出现次数大于小顶堆的根节点【这k个元素中出现次数最少的那个】
pq.poll();//弹出队头元素【小顶堆的根节点】。即把堆中里出现次数最少的那个的删除,留下的就是出现次数多的了
pq.add(new int[]{entry.getKey(),entry.getValue()});
}
}
}
int[] ans = new int[k];//依次弹出小顶堆,先弹出的是堆的根,出现次数少,后面弹出的出现次数多
for (int i = k - 1; i >= 0; i--) {
ans[i] = pq.poll()[0];
}
return ans;
}
} 以上为我做题时候的相关思路,语言组织能力较弱,有错误望指正。