【数据结构】线性表的顺序存储结构
个人主页:修修修也
所属专栏:数据结构
⚙️操作环境:Visual Studio 2022

一.顺序存储定义
上篇文章中介绍了线性表一共分为两种数据结构——顺序存储结构和链式存储结构.
今天我们就来一起学习一下第一种——顺序存储结构.
线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素.
线性表(a1,a2,......,an)的顺序存储示意图如下:

顺序存储结构有些像什么呢,举个例子吧.
记得大一的时候有个物理老师给我们带大学物理,第一节课刚去的时候,大家都零零散散的坐着,有的想好好听讲的就坐在前三排,有些想摸鱼划水的就坐在后两排,没抢到前面三排也没抢到后面两排的同学就只好委屈坐在了中间几排.
这时候老师进来了,一看我们坐的零零散散的样子,非常不满意,说:"我们这节课一共有80个同学,我们的教室刚好一排可以坐10个人,现在所有前8排后面的同学都向前移,直到将教室前8排的位置坐满."
我们就只好像沙丁鱼罐头一样全部向前8排的位置挪动,一个紧挨着一个坐着,最后终于全部同学都坐到前8排了,老师才不仅不慢的说:"我这个人嗓门比较小,加上教室的扩音器不太好,如果你们坐在后面讲课的声音传到你们的耳朵就大打折扣了,所以为了能更高效的上课,以后都委屈大家就像今天这样坐了."
后来每次上这个老师的课我们都像第一次那样全部坐在前8排,即便偶尔有请假的同学老师也不允许前面的位置空着,只允许从最后一排的最右边那个位置开始空.
这样上课冬天还好,夏天真是挺煎熬的,有时候大家一个挨着一个很热就不说了,主要是有时会有一些让人"难忘的销魂味道".那滋味,真是不堪回首啊.

二.顺序存储方式
线性表的顺序存储结构,说白了,和刚才的例子一样,就是在内存中找了块地儿,把一块内存空间给占用了,然后把相同的数据类型的数据元素依次存放在这块空地中.
既然线性表的每个数据元素的类型都相同,所以可以用C语言的一维数组来实现顺序存储结构,即把第一个元素存到数组下标为0的位置中,接着把线性表相邻的元素存储在数组中相邻的位置.
为了建立一个线性表,要在内存中找一块地,于是这块地的第一个位置就非常关键,它是存储空间的起始位置.
接着,我们需要先大概根据数组的长度设置一个存储容量.
有了起始位置,有了存储容量,于是我们就可以在里面增加数据了.随着数据的插入,我们线性表的长度开始变大,当线性表的长度超过存储容量时,我们就需要给顺序表扩容.
这时,我们发现描述顺序存储结构需要三个属性:
- 存储空间的起始位置:数组arr,它的存储位置就是存储空间的存储位置.
- 线性表的最大存储容量:数组长度capacity.
- 线性表的当前长度:size.
三.数组长度与线性表长度的区别
数组的长度(capacity)是存放线性表的存储空间的长度,存储分配后这个量一般是不变的.
线性表的长度是线性表中当前数据元素的个数,随着线性表插入和删除操作的进行,这个量是变化的.
从这张图上也可以看出数组长度capacity包含了当前数据占用的空间及空闲的空间,但线性表长度size只计算当前的数据占用的空间.
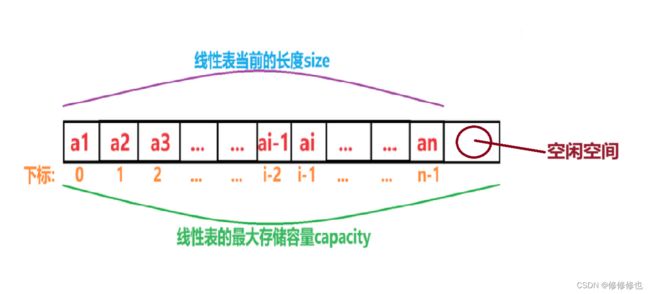 注意:在任意时刻,线性表的长度应该小于等于数组的长度.
注意:在任意时刻,线性表的长度应该小于等于数组的长度.
四.地址计算方法
C语言中的数组是从0开始第一个下标的,因此线性表的第i个元素要存储在数组下标为i-1的位置,即数据元素的序号和存放它的数组下标之间存在对应关系:
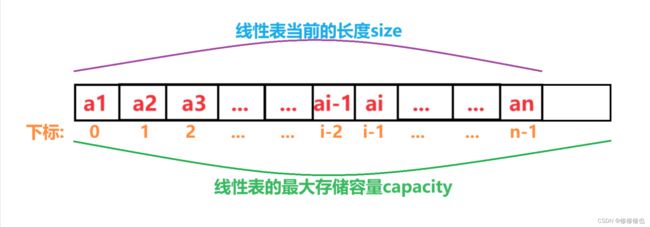
用数组存储顺序表意味着要分配固定长度的数组空间,由于线性表中可以进行插入和删除操作,因此分配的数组空间要大于等于当前线性表的长度.
内存中的地址,就和图书馆或电影院里的座位一样,都是有编号的.
存储器中的每个存储单元都有自己的编号,这个编号称为地址.
告诉大家一个秘密,大学女生宿舍一般上课时几个人都是坐在一起的,即宿舍的第一个成员位置确定后,后面其他的舍友的位置都是可以计算的.
再比如学校每学年都会进行的体测800米,舍友小A是班上第5名,我是她后面10名,那我肯定是第15名,因为5+10=15.
由于每个数据元素,不管是整型,浮点型还是字符型,它都是需要占用一定的存储单元空间的.
想进一步了解数据在内存中的存储的可以移步这篇博客:整型数据和浮点型数据在内存中的存储
我们假设一个数据元素占用的是n个存储单元,那么线性表中第i+1个数据元素的存储位置和第i个数据元素的存储位置满足下列关系(LOC表示获得存储位置的函数):
LOC(
)=LOC(
)+n
所以对于第i个数据元素的存储位置可以由a1推算得出:
LOC(
)+(i-1)*c
拿上面的图来说就是:

通过这个公式,我们可以随时算出线性表中任意位置的地址,不管它是第一个还是最后一个,都是相同的时间.
因此我们对每个线性表位置的存入或者取出数据,对于计算机来说都是相等的时间,也就是一个常数,因此用我们算法篇中学到的时间复杂度的概念来说,它的存取时间复杂度为O(1).
我们通常把具有这一特点的存储结构称为随机存取结构.
tips:随机存取结构(Random Access Structure)是一种数据结构,它允许通过直接访问数据的任意位置来读取或写入数据.
与顺序存取结构不同,顺序存取结构只能按照数据的顺序进行访问,需要逐个遍历数据才能找到目标位置.
随机存取结构通常使用数组来实现。数组是一种连续存储数据的结构,可以通过索引来直接访问数组中的任意元素。
顺序存取结构通常使用链表来实现.链表是一种非连续存储数据的结构,每个元素包含一个指针,指向下一个元素的位置,可以通过遍历链表来访问指定位置的元素。
随机存取结构的优点是可以快速访问和修改数据,时间复杂度为O(1),即常数时间。
缺点是插入和删除操作可能需要移动其他元素的位置,时间复杂度为O(n),其中n是数据的数量。
因此,在需要频繁插入和删除操作的场景中,随机存取结构可能不是最优选择。
五.顺序表的C语言实现
当我们搞明白了线性表的顺序存储结构的理论知识后,接下来就需要依据这些理论知识来使用C语言实现顺序表了,由于篇幅有限,我会另外再写一篇博客详细阐释用C语言实现顺序表的各个步骤以及顺序表的完整代码和运行效果都会包含在里面,感兴趣的朋友可以直接点击下方链接跳转到博客:
【数据结构】顺序表的C语言实现详解(附完整运行代码) https://blog.csdn.net/weixin_72357342/article/details/133817272
https://blog.csdn.net/weixin_72357342/article/details/133817272
结语
当我们搞清楚线性表的顺序存储结构后,在数据结构线性表篇我们还将一起学习线性表的链式存储结构(链表的实现)等相关知识.希望这些内容能对大家有所帮助,一起学习,一起进步!
相关文章推荐
【数据结构】什么是数据结构?【数据结构】什么是算法?
【数据结构】什么是线性表?
【数据结构】线性表的抽象数据类型
【数据结构】线性表的链式存储结构(链表的实现)
【C语言】整形数据和浮点型数据在内存中的存储
【C语言】结构体的大小是如何计算的?(结构体对齐)

数据结构线性表篇思维导图:
