记一次Clickhouse 复制表同步延迟排查
现象
数据从集群中一个节点写入之后,其他两个节点无法及时查询到数据,等了几分钟。因为我们ck集群是读写分离架构,也就是一个节点写数据,其他节点供读取。
排查思路
从业务得知,数据更新时间点为:11:30。查看clickhouse-server.log日志。
Clickhouse 节点1 被写入日志
2023.10.11 11:30:01.435628 [ 14098 ] {} dws_stock.trade_kline_60_min (ff4239f7-1eb5-40f3-8f18-bdb0d525886d) (MergerMutator): Selected 6 parts from 20231011_0_2_1 to 20231011_7_7_0
2023.10.11 11:30:03.335051 [ 69289 ] {e9e7f8b6-3978-4593-a750-ebc6c5c2e231} executeQuery: (from [::ffff:192.168.122.11]:50788, user: p_realtime_writer) insert into kline_1h (data_date,instr,bar_time,open,high,low,close,vwap,volume,amount,adj_af_open,adj_af_high,adj_af_low,adj_af_close,adj_af_vwap,adj_af_volume,adj_af_amount,up_limit_price,low_limit_price) FORMAT RowBinary (stage: Complete)
2023.10.11 11:30:03.342347 [ 69289 ] {e9e7f8b6-3978-4593-a750-ebc6c5c2e231} dws_stock.kline_1h (0cb13f31-1c20-433a-af76-758a7da5bb65) (Replicated OutputStream): Wrote block with ID ‘20231011_18249948133543406312_10292782376228156948’, 5067 rows
可以看到该节点在2023.10.11 11:30:03.342347的时候写入了5067行数据,对应的分区应该为上述日志所打印的20231011_7_7_0。
我们知道ck数据的更新操作是由zk负责复制日志,其他节点读取日志然后从对应的节点进行更新的。而insert操作并不属于mutation操作,mutation操作主要包括alter、alter update、delete。insert操作将记录在Entry Log内,对应在zk的节点为…/log。具体路径将会在下文中体现。
所以我们查看与该表相关的EntryLog
select name,value from system.zookeeper where path='/clickhouse/tables/{cluster}/库名/表名/1/log/' limit 10;
然后我们发现,和20231011_7_7_0相关的Log为log-0000030818(上图没有)。图上的get操作是数据分区下载。
节点2:2023.10.11 11:35:58才取到数据
2023.10.11 11:30:03.386868 [ 53605 ] {} dws_stock.kline_1h (ReplicatedMergeTreeQueue): Pulling 1 entries to queue: log-0000030818 - log-0000030818
2023.10.11 11:30:03.398940 [ 53605 ] {} dws_stock.kline_1h (ReplicatedMergeTreeQueue): Pulled 1 entries to queue.
2023.10.11 11:30:03.398940 已经把Log拿到了,但是2023.10.11 11:35:58.325150才开始下载数据,也就是Fetch操作,这里注意Ck副本节点会直接去主副本节点下载数据,而不是从zk下载。zk不存储ck任何数据除了日志外。并且数据几十毫秒就下完了。
2023.10.11 11:35:58.325150 [ 53513 ] {} dws_stock.kline_1h (0cb13f31-1c20-433a-af76-758a7da5bb65): Fetching part 20231011_7_7_0 from /clickhouse/tables/ckcluster/dws_stock/kline_1h/1/replicas/192.168.122.29
2023.10.11 11:35:58.336188 [ 53513 ] {} dws_stock.kline_1h (0cb13f31-1c20-433a-af76-758a7da5bb65): Fetched part 20231011_7_7_0 from /clickhouse/tables/ckcluster/dws_stock/kline_1h/1/replicas/192.168.122.29
同样我们看到,节点3:2023.10.11 11:48:00.179239 才取到数据
2023.10.11 11:30:03.392957 [ 38863 ] {} dws_stock.kline_1h (ReplicatedMergeTreeQueue): Pulling 1 entries to queue: log-0000030818 - log-0000030818
2023.10.11 11:30:03.498140 [ 38863 ] {} dws_stock.kline_1h (ReplicatedMergeTreeQueue): Pulled 1 entries to queue.
2023.10.11 11:48:00.179239 [ 38708 ] {} dws_stock.kline_1h (0cb13f31-1c20-433a-af76-758a7da5bb65): Fetched part 20231011_7_7_0 from /clickhouse/tables/ckcluster/dws_stock/kline_1h/1/replicas/192.168.122.29
2023.10.11 11:48:00.163862 [ 38708 ] {} dws_stock.kline_1h (0cb13f31-1c20-433a-af76-758a7da5bb65): Fetching part 20231011_7_7_0 from /clickhouse/tables/ckcluster/dws_stock/kline_1h/1/replicas/192.168.122.29
那么这两个ck节点在拿到Entry Log之后为什么等了几分钟甚至10几分钟才开始获取数据?
这里百思不得其姐,推测和集群负载有关系。查看当时ck集群的负载:
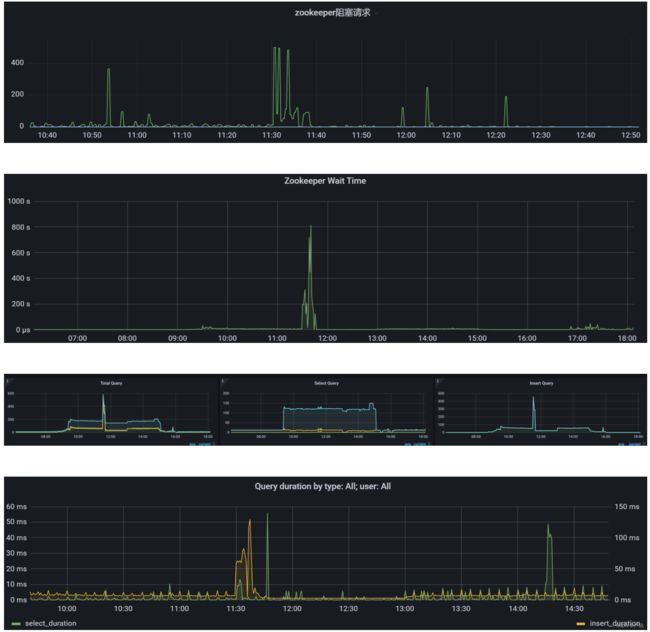
联系了业务得知,但是这段时间内在做一个应用的压力测试。:(
另外,ck的写节点在这段时间内一直有大量的 Too many parts (302) 异常,一直持续了8分钟。
2023.10.11 11:37:23.404245 [ 70328 ] {6df768b2-6ee3-423c-9f3d-ffde4ff37584}
所以,基本可以断定是因为但是ck节点负载太高导致的副本之间的数据同步延迟,因为ck是异步复制,对于实时性要求很高的业务,可选择读写使用同一个节点规避这个问题。