【数据结构】超详解栈和队列
栈和队列
- 一、栈的定义
-
- 栈的存储结构及实现
- 二.顺序栈
-
- 1.顺序栈的初始化
- 2.入栈
- 3.出栈
- 4.获取栈顶元素
- 5.获取栈中有效数据个数
- 6.栈的销毁
- 三、链栈
-
- 1.链栈的定义
- 2.链栈的初始化
- 3.压栈
- 4.出栈
- 5.链栈的长度
- 6.链栈的销毁
- 小结
- 栈的作用
- 四、队列的定义
-
- 队列的存储结构及实现
- 五、循环队列
-
- 1.队列的假溢出
- 2.循环队列的定义
- 3.循环队列的长度
- 4.循环队列的初始化
- 5.判空和判满
- 6.入队
- 7.出队
- 8.取队头和队尾元素
- 9.循环队列的销毁
- 小结
- 六、链队列
-
- 1.链队列的定义及初始化
- 2.入队
- 3.出队
- 4.队列的长度和判空
- 5.取得队头和队尾元素
- 6.队列的销毁
- 小结
- 总结
一、栈的定义
栈是一种可以实现数据后进先出的数据结构,就像一把手枪,先压入弹夹的子弹是最后发射出去的,而最后压入的子弹是第一颗发射出去的,而在我们许多的软件应用当中,栈的应用是非常普遍的。
栈是限定仅在表尾进行插入和删除操作的线性表
我们把允许插入和删除的一段称为栈顶top,另外一段称为栈底bottom,而不含有任何数据元素的栈称为空栈。栈有称为后进先出(Last In First Out)的线性表,简称LIFO结构。
栈的存储结构及实现
既然栈是一种线性表,那么线性表的存储结构可以分为两种:
- 顺式存储结构:顺序栈
- 链式存储结构:链栈
我们可以分别用这两种存储方式来实现栈,顺序栈是用数组来实现的,而链栈则是用链表来实现。
二.顺序栈
对于栈这种只能一头插入删除的数据来说,如果我们用数组来实现,考虑到数组的尾插尾删效率很高的情况下,那么我们可以用数组的尾来当栈的栈顶top,数组下标为0的一段作为栈底bottom。由此,我们可以定义出一个动态增长的栈。
代码如下:
typedef int STDataType;//将int作为栈存储的数据类型
typedef struct Stack
{
STDataType* a;//存放数据的数组
int top; // 栈顶
int capacity; // 容量
}Stack;
1.顺序栈的初始化
当栈的结构体被我们定义好了之后,我们还需要对这个栈进行初始化,包括了开辟可以动态增长的数组a,设置栈顶top的位置以及存储空间的起始容量capacity的大小。
void StackInit(Stack* st)
{
//起始空间设置为可以存储10个int数据的数组
st->a = (STDataType*)malloc(10*sizeof(STDataType));
st->capacity = 10;//数组的容量为10
st->top = 0;//top起始位置是数组下标为0的位置
//注意:如果st->top=0,那么栈顶的数据是数组下标为st->top-1的元素
// 如果st->top=-1,那么栈顶数据就是数组下标为st->top的元素
}
2.入栈
完成以上步骤,一个栈就创建好了,接下来,我们就要进行进栈操作,即往栈里面插入数据,其实就是进行如下图的处理。
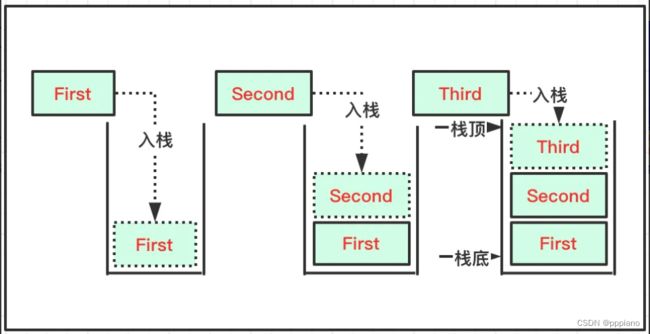
我们用代码来实现入栈的操作的时候,需要注意的是,我们是用的数组来实现的顺序栈,如果插入的数据太多,数组的空间不够,我们就要及时对数组进行扩容。
代码如下:
void StackPush(Stack* st, STDataType data)
{
if (st->capacity == st->top)//当top和capacity相等说明数组放满了,要对数组进行扩容
{
int newcapacity = 2 * st->capacity;//新的容量是原来的2倍
//对原数组进行扩容并防止扩容失败
STDataType* ret = (STDataType*)realloc(st->a, newcapacity * sizeof(STDataType));
if (ret == NULL)
{
printf("realloc fail\n");
exit(-1);
}
//将扩容好的数组返回给原数组
st->a = ret;
//数组的容量变成新的容量大小
st->capacity = newcapacity;
}
st->a[st->top] = data;//将数据压入栈中
st->top++;//栈顶的位置+1
}
3.出栈
出栈操作很简单,就是将栈顶top的数据删除即可,但出栈要考虑到,如果栈本身就不存储任何数据,那么此时没有数据可以出,不能进行出栈操作。
代码如下:
void StackPop(Stack* st)
{
assert(st);//防止传入空指针
if(st->top==0)//如果是空栈,直接返回
return;
st->top--;//将栈顶位置-1,即可看作将栈顶元素删去
}
因为栈每次push和pop操作针对的对象都是栈顶数据,并且我们将栈的top的值初始化为0,所以只有数组下标小于top的元素才是栈里面的有效数据。
如果栈的top的值初始化为-1,那么数组下标小于等于top的元素都是栈的有效数据。
4.获取栈顶元素
//判断栈是否为空的函数
int StackEmpty(Stack* st)
{
assert(st);
return st->top == 0;//如果top等于0,就是空栈
}
//返回栈顶数据的函数
STDataType StackTop(Stack* st)
{
assert(st);//防止传入空指针
assert(!StackEmpty(st));//断言栈不为空
return st->a[st->top-1];//返回的是top-1位置的数据
}
同出栈一样,如果是空栈,没有任何有效数据,此时得不到栈顶的数据。
5.获取栈中有效数据个数
int StackSize(Stack* st)
{
assert(st);//防止传入空指针
return st->top;//top的大小就是有效数据个数的大小
}
如果是空栈的话,不用进行单独处理,该函数会直接返回0,表示栈中的有效数据个数是0个。
6.栈的销毁
由于本文是用C语言实现的栈,存储数据的数组是动态开辟的,需要手动释放,如果不手动释放,会造成内存泄漏的问题。
void StackDestroy(Stack* st)
{
assert(st);
free(st->a);//将动态开辟的数组空间释放
st->a = NULL;//st->a要设置为NULL,防止其成为野指针
st->top = 0;//top的位置归0
st->capacity = 0;//容量也归0
}
三、链栈
实现了栈的顺序存储结构,我们再接着实现栈的链式存储结构,简称为链栈
对比顺序栈的实现,我们可以用单链表来实现链栈,而根据单链表的头插头删的效率很高,并且单链表自带头指针,而刚好栈顶指针也是必需的,我们可以让这两者合二为一。即让单链表的表头作为栈顶,进行入栈和出栈等操作。
1.链栈的定义
因为链栈是用单链表实现,用链表来存储数据,我们只需要创建一个个节点来存储数据,然后将这些节点链接起来,而进行pop和push等操作的位置都是表头,故需要链表的头指针top。
代码如下:
//将int作为链栈存储的数据类型
typedef struct int STDataType;
//链栈节点的结构体定义
typedef struct StackNode
{
STDataType data;//存储的数据
struct StackNode* next;//下一个节点的地址
}SNode;
//链栈的结构体定义:包含链表头指针和链表的长度
typedef struct Stack
{
SNode* top;//头指针
int size;//链表长度
}Stack;
2.链栈的初始化
对于链栈,我们需要的是链表的头指针,有了头指针,才能进行链栈的压栈和出栈等操作。
//链栈的初始化函数
void InitStack(Stack* st)
{
st->top = NULL;//空栈:头指针也应该为空,NULL
st->size = 0;//空栈:长度为0
}
3.压栈
对链栈进行压栈,其实进行的就是单链表的头插,注意不能用尾插,因为我们只定义了头指针,能够操作的位置只有表头,如果是尾插,数据会在表尾插入,此时进行出栈操作,弹出的是表头的数据。
void PushStack(Stack* st, STDataType x)
{
assert(st);//防止传入空指针
//开辟新节点并将数据存放进去
SNode* newnode = (SNode*)malloc(sizeof(SNode));
newnode->data = x;
newnode->next = NULL;
//第一次压栈时,头指针为NULL,要将新节点的地址赋给头指针
if (st->top == NULL)
{
st->top = newnode;
st->size++;//链表的长度+1
}
else//如果头指针不为空,将新节点头插到表头,更新头指针
{
newnode->next = st->top;
st->top = newnode;
st->size++;//链表长度+1
}
}
链栈的push操作需要注意是,如果是第一次插入数据到空链表,那么要将新开辟的节点的地址赋给头指针,避免空指针解引用的问题发生。
4.出栈
链栈的出栈是直接将链表队头的数据删去,即链表的头删。
//链栈的出栈函数
void PopStack(Stack* st)
{
assert(st);//防止传入空指针
assert(st->top);//空链表不能进行pop操作
SNode* next = st->top->next;//记录头结点的下一个节点
free(st->top);//释放头结点
st->top = next;//更新头指针
st->size--;//链表长度-1
}
注意:空链表不能进行出栈操作
5.链栈的长度
链栈的长度有可以由两种方法得到,一种是遍历链表,最后得到链表的长度,一种就是在链栈的结构体定义中就设置一个长度size变量,每次进行push操作size++,每次进行push操作size--,前者的时间复杂度为O(N),后者时间复杂度是O(1),此处我们使用的是第二种方法,代码更加简洁高效。
//返回链表长度
int StackSize(Stack* st)
{
assert(st);//防止传入空指针
return st->size;//返回链栈长度
}
//判断链表时候为空
int StackEmpty(Stack* st)
{
assert(st);//防止传入空指针
return st->size == 0;//如果链表长度为0,链表为空
}
6.链栈的销毁
由于链表的各个节点都是动态开辟,并且该链栈是用C语言实现,那么我们仍然是要手动释放节点,避免内存泄漏。
//链栈的销毁
void DestroyStack(Stack* st)
{
assert(st);//防止传入空指针
SNode* del = st->top;//用del指针去遍历链表删除每一个节点
while (del)
{
SNode* next = st->top->next;//记录del节点的下一个节点
free(del);//释放del节点
del = next;//del指针指向下一个节点
}
}
小结
对比顺序栈和链栈,它们在时间复杂度上是一样的,没有任何循环操作,时间复杂度均为O(1)。而对于空间性能来说,顺序栈事先需要确定一个固定的长度,数据满了就会扩容,可能会存在频繁扩容和内存空间浪费的问题,但优点就在于可以随机存取。而链栈无需事先确定空间大小,不存在空间浪费,长度没有限制,但每个元素包含指针域,增加了一些内存开销。
如果栈的使用过程中元素变化不可预料,又是很小,有时非常大,那么最好是用链栈,反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些。
栈的作用
引入栈这样的数据结构,是为了让我们直接能够使用栈去实现程序,更少地关注栈的底层是如何实现,更多地关注程序设计的问题,划分了不同关注层次,使得思考范围缩小,更加聚焦于如何通过栈的特性去解决问题。
就像线性表顺序存储结构用到的数组,因为要分散精力去考虑数组的下标增减等问题,反正掩盖了问题本质。
四、队列的定义
队列(queue)是只允许在一段进行插入操作,而在另一端进行删除操作的线性表。
队列是一种先进先出(First In First Out)的线性表,简称FIFO。允许插入的一端称位队尾,允许删除的一端称位队头。
队列的存储结构及实现
线性表具有顺序存储和链式存储两种存储方式,而队列作为一种特殊的线性表,同样存在这两种存储方式。
- 顺序存储结构:循环队列
- 链式存储结构:链队列
五、循环队列
1.队列的假溢出
队列的顺序存储结构就是用数组来实现队列,假设一个队列有n个元素,则顺序存储的队列需要建立一个大于n的数组,并把队列的所有元素存储在数组的前n个单元。数组下标为0的一端是队头。插入数据就是在队尾追加一个元素,不需移动任何元素,时间复杂度为O(1),如下图所示。
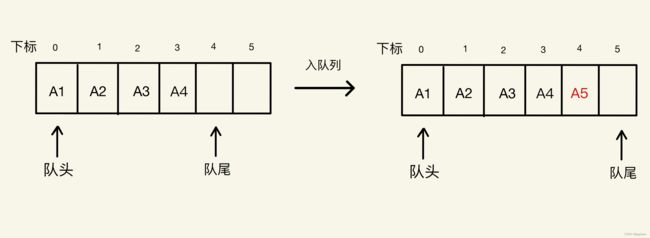
但由于队列先进先出的特性,队列元素的出列是在队头,即下标为0的位置,那么此时就要将数组中的所有元素往前移动,保证队头,下标为0的位置不为空,时间复杂度为O(N),如下图所示。
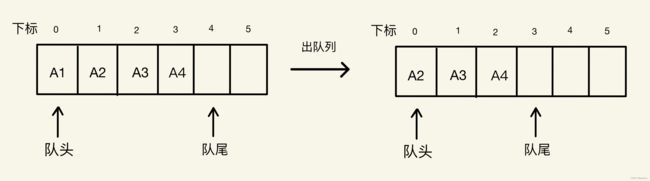
这种方法似乎也能实现队列先进先出的特性,但如果我们改变队头的位置,直接使队头的位置由0变为下标为1的位置,那我们就能避免将所有元素前移一个的操作。如下图所示。

所以我们可以引入两个指针,front指针指向队头元素,rear指针指向队尾元素的下一个位置,这样当front等于rear时,此队列不是只剩一个元素,而是空队列。

此时我们向队列中入队A1、A1、A2、A3、A4四个元素,此时的front指针仍然指向下标为0的位置,而rear指针指向下标为4的位置,即最后一个元素的下一个位置。
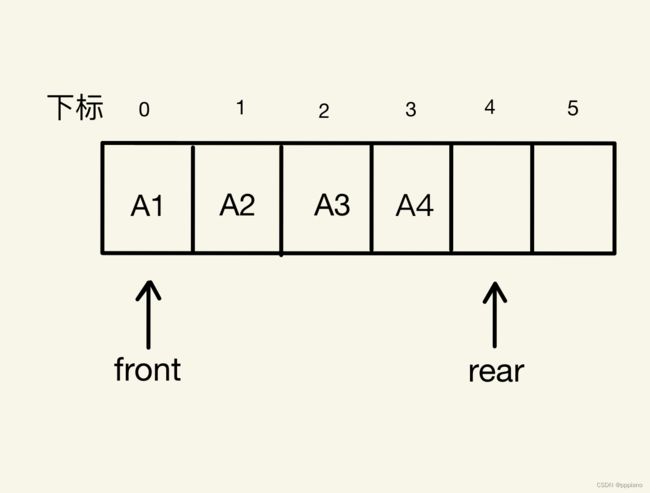
出队A1、A2,front指针指向下标为2的位置,rear指针不变,如下图所示。
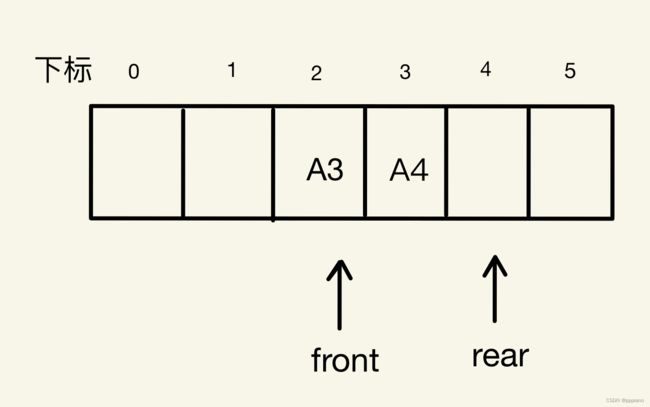
此时,我们如果继续插入A5、A6元素,就会发现问题来了。
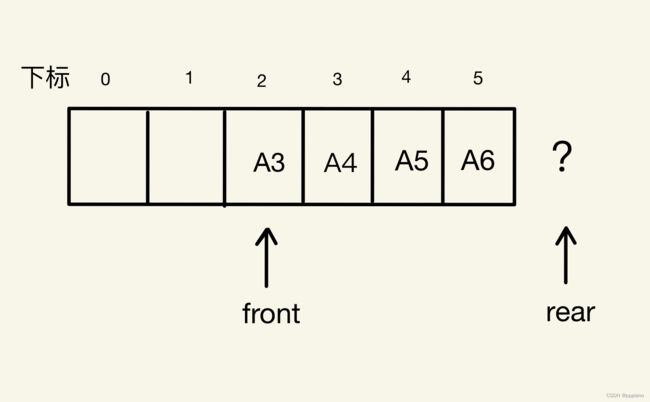
我们会发现如果rear指针继续往后走的话,就会越界,而数组之外存放的数据是什么,我们也不知道,也许存放了很重要的数据,如果我们通过rear对其进行修改,也许会造成不可预知的后果。
但我们此时还是想要入队列怎么办呢?我们会发现下标为0和1的位置还是空闲的,我们可以把数据插入到这两个位置呀,我们把这种现象称为“假溢出”。
2.循环队列的定义
解决假溢出的办法就是后面满了,就从头开始,把数据插入空闲的地方,这就形成了头尾相接的循环。我们把队列的这种头尾相接的顺序存储结构称为循环队列。
所以接着之前的例子,我们只需要将rear指针指向下标为0的位置,这样就不会发生越界,还能在数组前面空闲的地方插入数据。
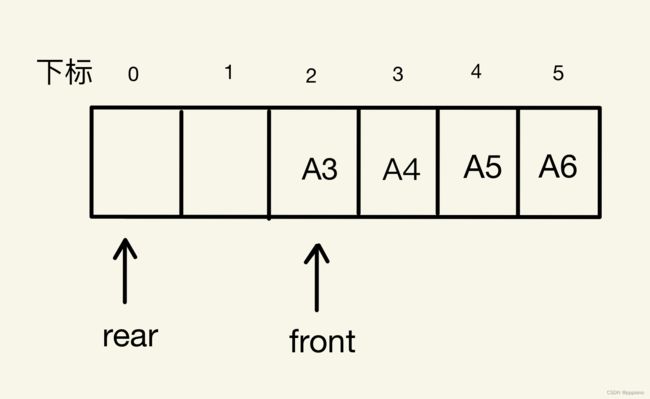
接着,我们就可以继续进行入队操作,比如我们将A7、A8也入队,那么此时rear和front指针就会重合。如下图所示。
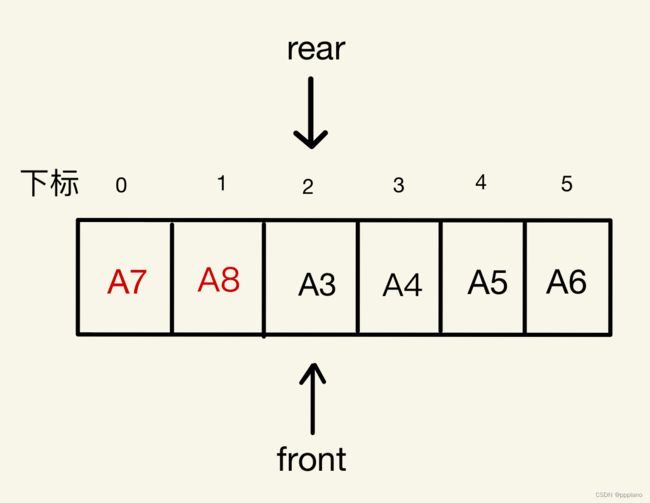
- 此时问题又出来了,对比一下空队列,我们发现空队列的
front和rear是相等的,此时队列满了,front和rear也是相等的,那么我们该如何判断队列为空还是为满呢? - 方法一:设置一个标志变量
flag,当front=rear,且flag=0时是空队列,当front=rear,且flag=1时队列已满。 - 方法二:我们空出一个元素空间,不存放任何数据,
当front=rear时,队列为空,当front=(rear+1)%QueueSize(队列的长度)时,队列为满。
我们重点来看一下第二种方法,因为我们空出一个元素空间,那么当队列满了的时候,应该是如下图所示的情况。
情况一:
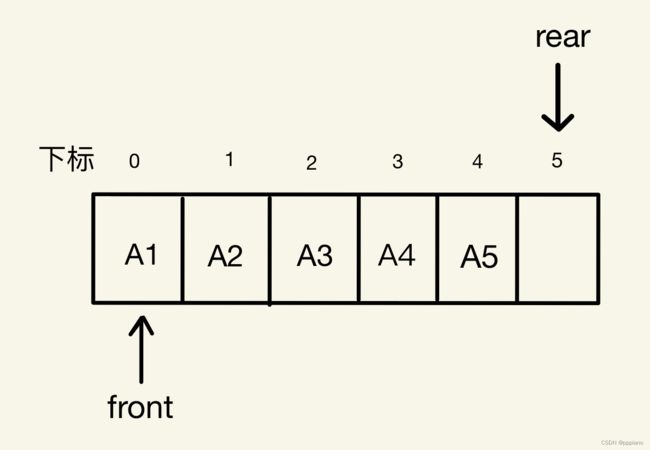
此时,下标为5的元素空间就是我们空余出来的,不存放任何有效数据,代表队列已满,此时我们会发现其实rear位置的下一个元素就是front指向的元素,但在上图所示的情况中,他们虽然只差了一个元素,但由于是循环队列,他们相差的其实是一圈,所以判断队列是否已满的条件要在(rear+1)的基础上模(%)上队列的长度QueueSize,将那一圈的差距忽略掉,如果相等,那么队列已满,如果不相等,那就说明队列还没满。
情况二:
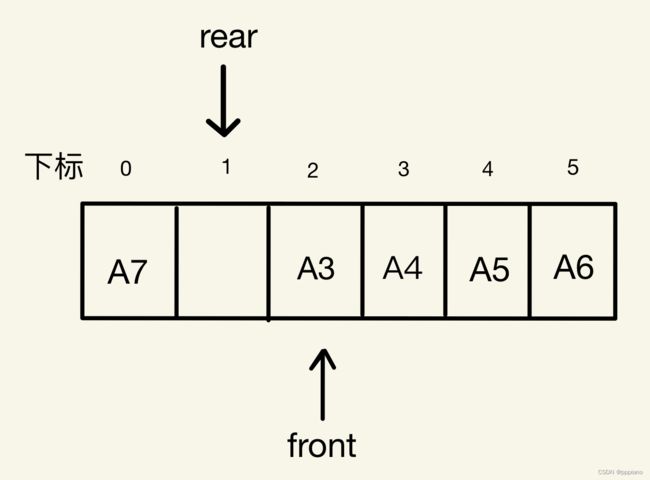
在情况二中,rear和front由于都处在队列的中间,相差的距离就是1,此时如果rear+1=front,那么队列就满了,反之就没满。而为了避免情况一这种比较特殊的情况,我们还是应该对(rear+1)进行模上队列的长度QueueSize的操作,因为取模对情况二的最终结果并无影响。
3.循环队列的长度
要求循环队列的长度也分两种情况,两种情况对应的队列长度的计算都可以用一个通用公式来计算出。
情况一:rear>front
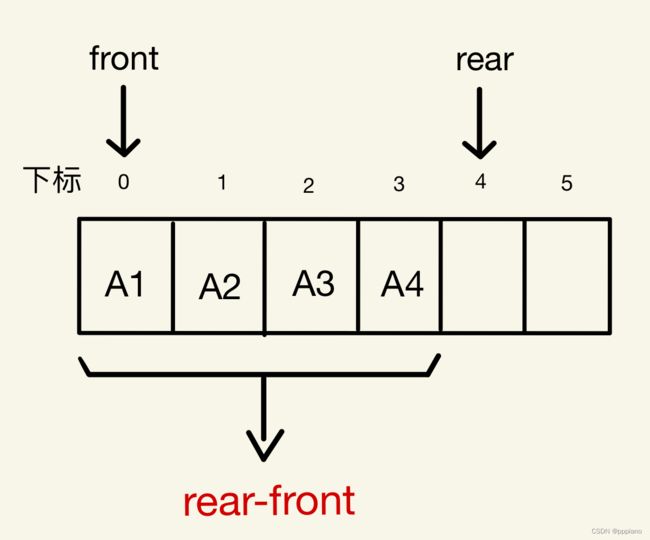
对于这种情况,队列长度就等于rear-front.
情况二:rear
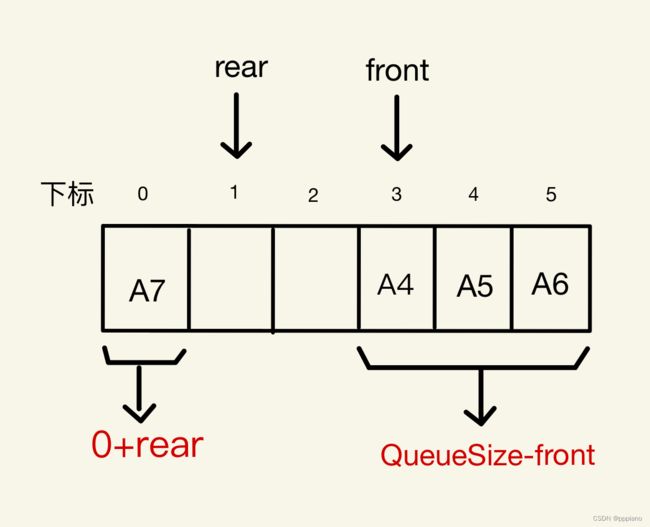
对于这种情况,队列的长度被分为了两段,一段长度为0+rear,一段的长度为QueueSize-front,所以该队列长度为rear-front+QueueSize。
因此通用的计算队列长度的公式为:(rear-front+QueueSzie)%QueueSize
4.循环队列的初始化
有了之前的铺垫,接下来我们用代码来实现循环队列就轻松多了。我们可以创建一个可以存储K个元素的数组来初始化循环队列。
#define K 6 //K即数组大小,我们将其定义为6,可改变大小
typedef int QDatatype;//将int定义为循环队列的存储类型
//循环队列结构体定义
typedef struct CirQueue
{
QDataType* data;//指向该队列的指针
int front;//队头下标
int rear;//队尾下标
}CQueue;
//循环队列的初始化
void InitQueue(CQueue* cq)
{
cq->data=(QDatatype*)malloc(K*sizeof(QDatatype));//开辟存放K个int类型元素的数组当做队列
cq->front = 0;//队头下标为0
cq->rear = 0;//队尾小标为0
}
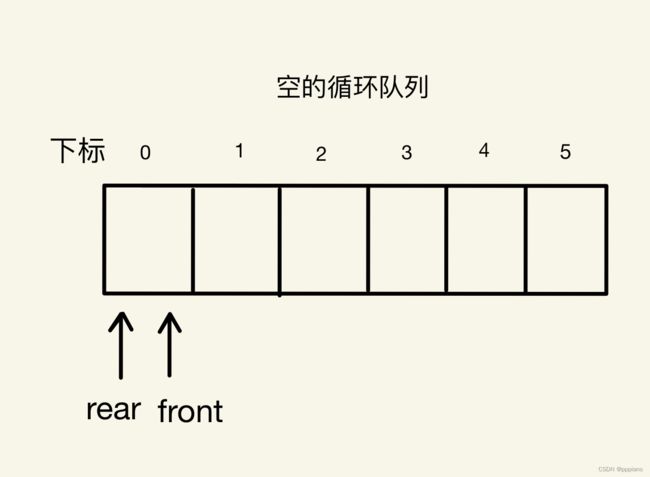
通过对循环队列的初始化,我们就成功地创造了一个循环队列,接下来继续实现入队和出队等操作。
5.判空和判满
在进行出队和入队操作的时候,我们要注意队列是否为空,是否已满,空队列不能进行出队操作,而满队列也不能进行入队操作。
//判断队列是否为空
int IsQueueEmpty(CQueue* cq)
{
assert(cq);//防止传入空指针
return cq->front == cq->rear;//front==rear,则是空队列
}
//判断队列是否已满
int IsQueueFull(CQueue* cq)
{
assert(cq);//防止传入空指针
//如果(cq->rear+1)%k=cq->front,则说明队列满了
return (cq->rear+1)%K==cq->front;
}
6.入队
入队即在下标等于rear的尾插插入数据,注意如果队列已满,则不能进行入队操作,rear的位置如果越界要将其变为下标为0的位置。
//入队
void PushQueue(CQueue* cq, QDataType x)
{
assert(cq);
if ((cq->rear + 1) % K == cq->front)//判断是否是满队列
return;
else//如果不是满队列,在rear位置插入数据,如果rear+1越界,则将其从头开始
cq->data[cq->rear] = x;
rear=(rear+1)%K;
}
7.出队
出队只需要将front往后移动一位即可,同样应该考虑到front往后移动一位可能存在越界的情况,如果越界也是将其从头开始,并且如果是空队列,也不能进行出队操作。
//出队
void PopQueue(CQueue* cq)
{
assert(cq);//防止传入空指针
//如果是空队列直接返回
if(cq->front==cq->rear)
return;
//如果不是空队列,front往后移动一位,如果越界,则从头开始
cq->front = (cq->front + 1) % K;
}
8.取队头和队尾元素
这也是用数组实现循环队列的一大优势,正是因为数组随机存取的特点,循环队列取得队头和队尾元素的效率很高,时间复杂度为O(1).
//取队头元素
int QueueFront(CQueue* cq)
{
assert(cq);//防止传入空指针
assert(!IsQueueEmpty(cq));//断言队列不为空,为空则报错,没有队头元素
return cq->data[cq->front];//队列不为空,直接返回队头元素
}
//取队尾元素
int QueueRear(CQueue* cq)
{
assert(cq);//防止传入空指针
assert(!IsQueueEmpty(cq));//断言队列不为空,空队列无数据,直接报错
//当rear=0时,rear-1会越界,此时rear-1应该回到数组末尾
return cq->data[(cq->rear-1+K)%K];
}
9.循环队列的销毁
由于队列的空间实质是一个动态开辟的数组,当我们不再需要这个队列时,对该循环队列进行销毁,要手动将动态开辟的内存空间释放掉。
void QueueDestroy(CQueue* cq)
{
assert(cq);//防止传入空指针
free(cq->data);//释放动态内存
cq->data=NULL;//将cq->data置为空,避免野指针解引用
cq->front = 0;//front归0
cq->rear = 0;//rear归0
}
小结
我们发现,如果不采用循环队列的方式实现队列的顺序存储方式,算法的时间性能是不高的,因为数组的优势在于尾插尾删,时间复杂度是O(1),但如果是头插头删,又要数组元素从头开始保持原有顺序,则每个元素都需要挪动,时间复杂度是O(N)。
而采用循环队列的方式,又会面临数组“假溢出”的问题,为了解决这个问题又需要我们空出一个元素空间来不存储任何有效数据,并且还需要对front和rear这两个指针的值进行控制,防止其越界,不太便于理解。
所以接下来我们可以研究一下不需要考虑队列长度,也不需要考虑空间是否足够的链式存储结构来实现队列。
六、链队列
队列的链式存储结构,其实就是单链表,但是这个单链表能进行尾进头出,所以简称为链队列。
用单链表实现队列,要达到先进先出的效果,那我们可以对链表进行尾插数据,然后再将表头的数据弹出即可,即入队就是单链表的尾插,出队就是单链表的头删。而由于单链表的尾插效率并不高,因为我们每次尾插都要去寻找尾结点,所以,我们可以给链队列多加一个尾指针方便我们进行尾插。
1.链队列的定义及初始化
给队列定义两个指针,一个头指针head,一个尾指针tail,入队时,开辟一个新节点存放数据,然后将新节点链接在尾结点tail的后面即可,出队时,将头指针head指向下一个节点,再将头结点释放即可。
//将int定义为数据类型
typedef int QDataType;
//节点的结构体定义
typedef struct QueueNode
{
QDataType data;//存放数据
struct QueueNode* next;//存放下一个节点地址
}QNode;
//队列的结构体定义
typedef struct Queue
{
struct QueueNode* head;//队列头指针
struct QueueNode* tail;//队友尾指针
int size;//队列的长度
}Queue;
//队列的初始化
void InitQueue(Queue* q)
{
q->head = NULL;//初始队列为空,此时head也应为空
q->tail = NULL;//初始队列为空,此时tail也应为空
q->size = 0;//空队列长度为0
}
如此,一个队列的定义和初始化都实现了,接下来,就可以进行出队和入队等操作了。
2.入队
入队时,开辟新节点存放数据,然后链接在尾结点的后面即可,但要注意的是,第一次入队时,队列是空,队列的头指针head和尾指针tail都为空,如果直接链接在tail节点的后面,就会造成空指针解引用的问题发生,对这种情况要单独处理。
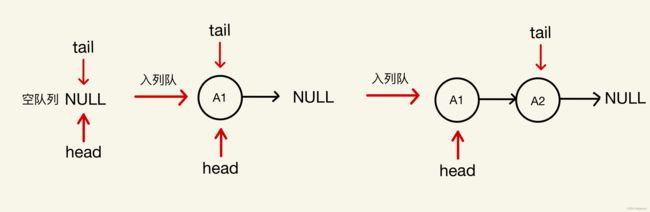
当队列中已经有数据时,直接将新节点插入到尾结点之后即可。
void PushQueue(Queue* q, QDataType x)
{
//开辟新节点
QNode* newnode = (QNode*)malloc(sizeof(QNode));
newnode->data = x;//存放数据
newnode->next = NULL;
//第一次进队列
if (q->head == NULL)
{
//将新节点的地址赋给队列的head和tail指针
q->head = newnode;
q->tail = newnode;
//队列的长度要+1
q->size++;
}
//如果不是空队列,则在尾上插入,并把尾指针赋给新节点
else
{
q->tail->next = newnode;//新节点插入到尾结点之后
q->tail = newnode;//尾指针指向新节点
q->size++;//队列长度+1
}
}
3.出队
出队,即链表的头删,同循环队列一样,空队列无数据可以出,不能进行出队操作,那么问题来了,根据我们之前对队列的结构体定义,如果head为NULL,那么队列是否一定为空?再者说,是不是队列的头指针head为NULL,那么尾指针tail也为NULL呢?
答案是:当head为NULL,队列一定为空,但tail指针不一定为空,在出掉队列中最后一个元素的时候,如果我们不对tail指针进行单独处理,那么tail不为空,tail反而会成为一个野指针。
当队列中不止一个元素时:

在这种情况下,我们只需要改变头指针head即可,而tail仍然指向最后一个节点,不需要做出任何改变。
当队列中只有一个元素时:

当我们将最后一个节点释放之后,发现head为NULL了,队列中的所有节点都被释放掉了,此时,队列的确为空了,但tail仍然指向最后一个节点的位置,因为free只会释放掉最后一个节点所开辟的内存空间,却不会将tail指针也置为NULL,所以,我们要手动将tail置为NULL,避免tail成为野指针,不然,我们下次再进行入队操作时,就会对tail这个野指针进行解引用操作。
代码如下:
void PopQueue(Queue* q)
{
assert(q);//防止传入空指针
assert(q->head != NULL);//断言链表不为空
QNode* next = q->head->next;//记录头结点的下一个节点
free(q->head);//释放头结点
q->head = next;//更新头结点
if (q->head == NULL)//如果此时队列为空
{
q->tail = NULL;//则将tail指针也置为NULL
}
q->size--;//出队,队列长度-1
}
4.队列的长度和判空
由于队列是用链表实现,不存在满队列的情况,理论上,只要空间足够,就可以一直开辟动态内存,建立新节点来存放有效数据,并将其入队,队列的长度可以一直增加下去,所以,我们只需要判断队列是否为空和队列的长度是多少。
//求队列的长度
int QueueSize(Queue* q)
{
assert(q);//防止传入空指针
return q->size;//直接返回队列长度
//本文为了方便求队列的长度,在队列的结构体定义中就定义了一个size变量,来记录队列的长度,时间复杂度是O(1)。
//如果是采用遍历链表,求得队列的长度的方式也可,但时间复杂度是O(N)。
}
//判断队列是否为空
int QueueEmpty(Queue* q)
{
assert(q);//防止传入空指针
return QueueSize(q) == 0;//如果队列长度为0,那么队列为空
}
5.取得队头和队尾元素
由于head和tail指针的存在,使得我们可以直接获取到队头和队尾的数据,十分高效便捷,时间复杂度是O(1)。
//返回队头数据
QDataType QueueFront(Queue* q)
{
assert(q);//防止传入空指针
assert(q->size>0);//断言队列不为空
return q->head->data;//返回队头数据
}
//返回队尾数据
QDataType QueueBack(Queue* q)
{
assert(q);//防止传入空指针
assert(q->size>0);//断言队列不为空
return q->tail->data;//返回队尾数据
}
6.队列的销毁
队列由单链表实现,节点都是动态开辟的,需要手动释放内存空间,避免内存泄漏。
//队列的销毁
void DestroyQueue(Queue* q)
{
assert(q);//防止传入空指针
assert(!QueueEmpty(q));//断言队列不为空
//用del指针从头开始去遍历链表删除每一个节点
QNode* del = q->head;
//循环删除链表中所有的节点
while (del)
{
q->head = q->head->next;
free(del);
del = q->head;
}
q->head = NULL;//头指针置空
q->tail = NULL;//尾指针置空
q->size = 0;//队列长度归0
}
小结
对比一下循环队列与链队列,从时间上,两种队列的入队、出队、取队头队尾元素等操作的时间复杂度都是O(1),但循环队列事先申请好了空间,使用期间也不用释放空间,但链队列每次申请和释放节点会存在一定的时间开销,如果入队出队频繁,则两者在时间上还有有一些细微差别。
从空间上,循环队列必须事先固定队列长度,限制了元素存储的个数,并且存在空间浪费的问题,但链队列不存在这些问题,空间随开随用,即使每个节点都额外存放了一个指针域,产生了一些空间上的开销,但也能接受,所以在空间上,链队列更加灵活。
总的来说,如果能确定队列长度最大值的情况下,建议使用循环队列,如果不能确定,则用链队列。
总结
本文所讲的栈和队列都是一种特殊的线性表,只是对其插入和删除做了一定的限制,如栈要满足其后进先出的特性,而队列要满足其先进先出的特性。
栈(stack)是限定在表尾进行插入和删除操作的线性表队列(Queue)是只允许在一端进行插入操作,在另一端进行删除操作的线性表。- 这两者均可以采用顺序存储结构和链式存储结构来实现,使用不同的存储结构,也会存在一些相应的弊端和优势,所以要选择最合适的结构来分别实现栈和队列。
- 栈的顺序结构存储,即用数组来实现栈,是比较常用的方法,因为数组的尾插尾删效率高,正好与栈后进先出的特性十分契合,好处在于,存取时定位十分方便,实现起来也比较简单,但弊端在于,可能会存在频繁开辟内存空间和内存空间浪费的问题。栈的链式存储结构,虽然不存在空间浪费的问题,但每个节点都存放一个指针域,也会存在一定的内存开销,并且在每次申请和释放节点的过程中也存在一定的时间开销。
- 队列的顺序存储结构,即用数组来实现队列,为了避免数组插入和删除时需要挪动数据,
时间复杂度为O(N),于是引入了循环队列,使得队头和队尾可以在数组中循环变化,解决了移动数据的时间损耗,将原本为O(N)的时间复杂度变为了O(1)。但循环队列也存在空间浪费和限制存储数据个数的问题。队列的链式存储结构,即用链表来实现队列,是比较适合的方法,只需要多定义一个尾指针tail便能很好地解决单链表的尾插效率低的问题,将单链表尾插的时间复杂度由O(N)变为O(1),并且不会限制存储数据的个数,也不存在空间浪费的问题。