C/C++结构体内存对齐
昨天在一个群里看到一个小伙伴提到一道面试题,说:如果一个结构体,第一个成员是char类型,第二个成员是sizeof为1M的资源,那这个结构体有多大。
先说结论:
对于该面试题,应该根据不同操作系统或者编译器的默认对齐数,以及这1MB资源的数据类型来综合考虑。该结构体在windows中最大情况是8 + 1024字节,在Linux中就最大是4 + 1024字节,而最小情况就是该1MB资源全是char型,那就是1 + 1024字节。
下面开始详解C/C++内存对齐知识!
一.为什么要内存对齐
因为CPU从内存中取数据并不是一字节一字节的取,而是以2,4,8,16这些字节为单位进行存取。因为在CPU眼中,内存是一块一块的,块的大小是2,4,8,16字节大小,因此CPU读取内存时就是一块一块的读取,这些存取单位也就是块的大小称为内存存取粒度。
要知道,每次内存存取都是一个固定的开销,减少内存的读取次数将提升程序的性能。
假设一个CPU的存取粒度是4字节,那么在某结构体中取int型数据将有以下这些情况出现:
说明:我们当然不用管结构体旁边存了什么数据,是什么逻辑地址,CPU从结构体中取数据时,肯定是只看偏移量的,结构体起始位置就是偏移量为0的位置。4字节存取粒度的话,就是从0处每四个字节取一次,跟滑动窗口一样。
1. 有内存对齐时
A结构体内依次存了1个char字符和1个int型整数
struct A{
char m;
int n;
};
那么结构体的内存占用形式如下图所示,一个格子代表1个字节,红色框为CPU每次读取的范围——4字节
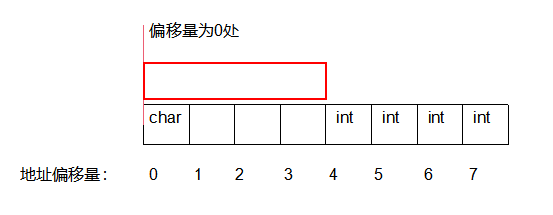
这个时候肯定读到char数据了,然后放入寄存器,接着继续往右滑:
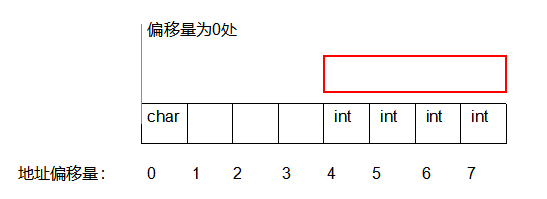
这样就取到了完整的int数据n。
当然,为了节省内存我们尽量让m和n换一下存储顺序,所以结构体应该改成如下形式更好些:
struct A{ int n; char m; };这样就只需占用5字节空间
勘误:
其实上面先int n,再char m会占用8字节,这个和CSAPP说的不一样,因为CSAPP里面是编译器不自动对齐的情况下,现在编译器优化之后,对于后面那1个char,也会被分配1个int的空间,因为32位系统里内存访问粒度就是4字节。如果后面是2个char,那么也是分配1个int的空间,也就是int a; char b; char c;这种也是8字节大小。
2023.04.11
2. 没有内存对齐时
如果最初的那个结构体没有内存对齐会怎么样,比如如下方式存储在内存中:
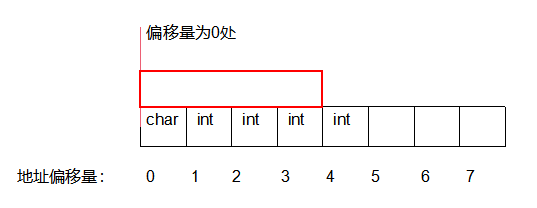

这样下来,如果我们只想要读取int型的数据n就不能再像前面那样一次就能读到,而是需要分两次,每次只读到其一部分,然后拼接在一块
当然这个例子中要读取结构体A的所有数据无论如何都需要两次,好像内存对不对齐也一样的,但是在很多时候并不是这么理想化,比如下面某结构体,其int型数据的地址存在4的整数倍(内存对齐)和没有在4的整数倍(内存没有对齐)时,后者就会多取一次 

显然,右边这种没有内存对齐的情况,CPU就需要多一次内存读取
结构体的内存对齐是一种用空间换取时间的行为,为了能够一次读取到成员变量,而不惜浪费一些内存来使得结构体内存对齐。
二. 内存对齐规则
有四个规则,这四个规则是计算结构体大下的规则,至于结构体内成员变量的排列顺序应该根据这些规则和实际情况自行优化:
1.第一个成员在与结构体变量偏移量为0的地址处;
2.其它成员变量要对齐到对齐数的整数倍地址处。这个对齐数并不是待对齐成员变量的大小,而是编译器默认对齐数和该成员大小两者中的较小值。
比如VS中默认的对齐数是8,Linux默认对齐数是4。
所以在Linux中,如果某结构体内有8字节的long long型数据,那么该变量应该对齐到4的整数倍地址处,而不是8的整数
在64位Linux和Windows下只有long的大小是不同的,64位Linux下long的大小为8字节,和long long一样,Windows下long为4字节和int一样。但是在32位Linux下long的大小也仅有4字节
为啥对齐数是取编译器默认值和成员变量大小的较小值呢,我猜测这个默认值跟CPU存取粒度有关,为了跨平台,比如能一次取8字节的CPU肯定也能取4字节,反过来就不行了。所以比如在Linux中,比如遇到long long这种8字节的数,它超了默认对齐数,但是我CPU可能本来也不能一次取8字节,粒度没那么大,即使按照8字节对齐了我也得不能因此读取完它,那干脆我就分两次取,内存对齐就按4字节去对齐。
3.结构体整体大小是最大对齐数的整数倍。这个最大对齐数是这样理解的,就是一个结构体里面有多个不同数据类型的成员变量,按照规则2,它们都有一个对齐数,这些对齐数里最大的就是最大对齐数——显然在windows里不会超过8,linux里不会超过4
4.对于结构体里嵌套了结构体的情况,首先里面那个结构体就按照前面三个规则对齐,该内置结构体的首地址就在自己里面最大对齐数的整数倍处,比如4的倍数处,对于外面这个结构体,也就是所要求的整个结构体的大小,它就是自己的普通成员变量和嵌套结构体内成员变量中取 最大对齐数 的整数倍。
比如结构体A里有一个long long,该成员变量对齐数是8,A里面嵌套了结构体B,其中B里面最大的是个int型的,那最大对齐数就是4字节,对于整个A来说,它的大小就是8的整数倍
三. 结构体内存对齐的例子
在windows平台下测试,此时默认对齐数是8,当然这个值可以被修改——#pragma pack(n)//n是2的整数次方如4, 16,太小了不太好,比如某CPU存取粒度是4,要是按2字节来对齐,那就降低程序性能了。
例1:
struct test{
double a;
char b;
int c;
};
该结构体各成员变量的存储形式如下:

即该结构体大小为16字节,当然,我们把b和c换一下就是8 + 4 + 1 = 13了
例2:
有一道面试题说,如果一个结构体,第一个成员是char类型,第二个成员是sizeof为1M的资源,那这个结构体有多大。
我认为除了考虑不同操作系统,编译器的默认对齐数之外,还得考虑这个1MB的资源是由什么构成的,因为根据结构体内存对齐规则2,对齐数是编译器默认对齐数和成员变量大小两者中的较小值。
注意:千万不要想当然以为是2MB,注意规则3是最大对齐数大小的整数倍,而有些帖子写的是最大成员变量大小的整数倍,后者会认为这道题是2MB!
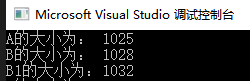
(1)假如这1MB资源是数组:
且数组成员类型分别为char、int和double,这些类型的大小在windows中分别为1、4、8. 见如下结构体:
struct A {
char m;
char n[1024];//1MB
};
struct B {
char a;
int b[256];//1MB
};
struct B1 {
char a;
long long b[128];//1MB
};
显然,根据规则2,他们的对齐数分别为1, 4,8,而根据规则3,结构体总大小还得是最大对齐数的整数倍,那么它们的大小就分别是1024 + 1、1024 + 4、1024 + 8,测试结果也符号我们的计算:
(2)假如这1MB资源是结构体:
而且我们让这1MB的嵌套结构体里面的成员也分为不同数据类型,这里就测4字节的int型和8字节的long long型
//考虑嵌套结构体情况,先写三个1MB大小的结构体C、C1和C2
struct C {
int c[256];//1MB
};
struct C1 {
long long c1[128];//1MB
};
struct C2 {
long long c1[64];//512
int c[128];//512
};
//分别嵌套了C、C1和C2的结构体D、D1、D2
struct D {
char d;
struct C c;//1MB
};
struct D1 {
char d1;
struct C1 c1;//1MB
};
struct D2 {
char d1;
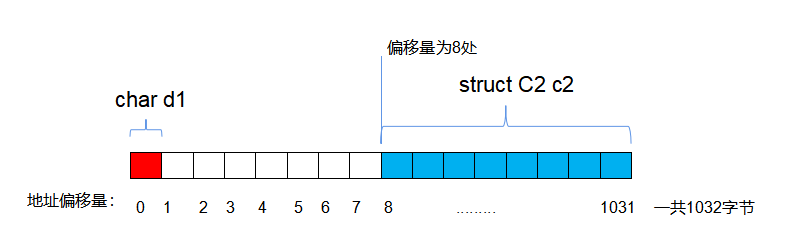
struct C2 c2;//1MB
};
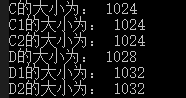
结构体D中,内置结构体c的对齐数是4字节,所以结构体类型的c这一成员应该放在结构体D的偏移量为4的位置,即4 + 1024,算下来再看是否符合规则4,也符合,所以结构体D的大小是1028;
结构体D1中,内置结构体c1的对齐数是8字节,所以结构体类型的c1这一成员应该放在结构体D的偏移量为8的位置,即 8 + 1024,算下来也符合规则4,是8的整数倍,所以结构体D1的大小是1032;
结构体D2中,我们先看结构体C2是不是1MB,数组c1的对齐数根据规则2是8字节,数组c的对齐数根据规则2是4字节,c1刚好放置在0511这512字节处,而512是4的整数倍,所以数组c从512开始,放置到1023处,从01023一共1024字节,1024也是最大对齐数8的整数倍,所以也符合规则3,所以结构体C2的大小确实为1MB。而且c2放在结构体D2中,也得从c2的最大对齐数8的整数倍地址处开始放,所以结构体D2的前8个字节就只有第一个字节放了个char,有七个字节空着,然后从8开始放置结构体c2 ,所以D2大小是8 + 1024,和D1一样也符合规则4,其在内存中的存储模型如下:
测试结果也符合我们的计算:
例2总结:
所以对于该面试题,应该根据不同操作系统或者编译器的默认对齐数,以及这1MB资源的数据类型来综合考虑。因为对齐规则2的存在,所以最大对齐数也不会超过默认对齐数的大小,那么VS中默认对齐数为8,所以该结构体在windows中最大情况是8 + 1024,在Linux中就最大是4 + 1024,而最小情况就是该1MB资源全是char型,那就是1 + 1024。
本文测试代码如下:
#include运行结果:
