MSQL系列(四) Mysql实战-索引分析Explain命令详解
Mysql实战-索引分析Explain命令详解
前面我们讲解了索引的存储结构,我们知道了B+Tree的索引结构,也了解了索引最左侧匹配原则,到底最左侧匹配原则在我们的项目中有什么用?或者说有什么影响?今天我们来实战操作一下,讲解下如何进行SQL分析及优化
1.联合索引
比如我搜身份证号,查某个人的姓名
- 首先想到的是我新建一个cardId的唯一索引
- 然后我先搜cardId的索引树,找到该cardId对应的主键id
- 然后根据主键id,然后再去主键索引上搜索这个人的姓名
这种查询方式代价是昂贵的,因为他检索了两个B+树,第一个是cardId的索引树,第二个是主键id的索引树,如果树的高度是3,那么两次就是6,去除两次根节点,需要IO检索的就是4次,这就是回表
为了解决主键索引回表查询的问题,尽量不用某个要搜索的列作为索引,这就引出了我们要使用的联合索引
联合索引
就是一个表中,使用多个列来作为索引的方式,也就是说联合索引可以让我们在查询时根据多个列的值来进行筛选
针对上面的搜身份证号,查名字的场景,我们可以创建一个 cardId + name的联合索引, 在查到cardId的同时,就能够取出name的信息,避免回表查询
联合索引有一个最左侧匹配原则
最左匹配原则指的是,当使用联合索引进行查询时,MySQL会优先使用最左边的列进行匹配,然后再依次向右匹配。
假设我们有一个表,包含三个列:A、B、C
- 我们使用(A,B,C)这个联合索引进行查询时,MySQL会先根据列A进行匹配
- 再根据列B进行匹配,最后再根据列C进行匹配。
- 如果我们只查询了(A,B)这两个列,而没有查询列C,那么MySQL只会使用(A,B)这个前缀来进行索引匹配,而不会使用到列C
- 如果我们要查询 了(B,C)这两个列,而没有查询列A,那么MySQL索引就会失效,导致找不到索引,因为最左侧匹配原理
- 所以 我们应该尽量把最常用的列放在联合索引的最左边,这样可以提高查询效率
2.实战
新建表结构 user, user_info
#新建表结构 user
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`id_card` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '身份证ID',
`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户名字',
`age` int NOT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'
#创建另一个测试表,用于连表结构
CREATE TABLE `user_info` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_id` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户ID',
`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户ID',
`age` int NOT NULL COMMENT '年龄',
`address` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '地址',
`order_ids` json DEFAULT NULL COMMENT '用户id的json数组',
`goods` json DEFAULT NULL COMMENT '用户商品信息 商品对象',
`sort_order` int DEFAULT '0' COMMENT '排序字段',
`is_del` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否删除',
`is_del2` tinyint NOT NULL COMMENT '测试',
`addtime` bigint NOT NULL DEFAULT '0' COMMENT '创建时间',
`modtime` bigint NOT NULL DEFAULT '0' COMMENT '修改时间',
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=24 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'
- id 主键id列
- id_card 身份证id
- user_name 用户姓名
- age 年龄
先插入测试数据, 插入 5条测试数据
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (1, '11', 'aa', 10);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (2, '22', 'bb', 20);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (3, '33', 'cc', 30);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (4, '44', 'dd', 40);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (5, '55', 'ee', 50);
2.1 创建 id_card,user_name,age的索引列
alter table user add index idx_card_name_age(id_card,user_name,age);
创建索引成功
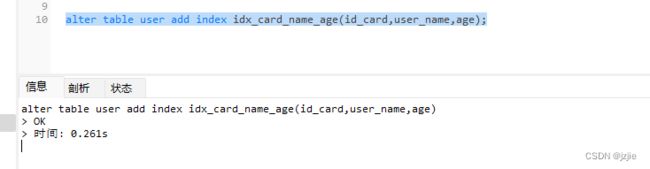
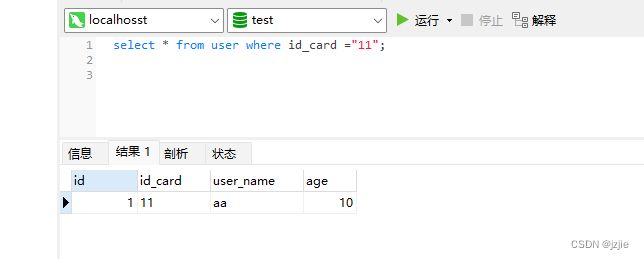
执行语句 ,可以看到 数据存在于表中,我们查询的是id_card,现在我们来分析下这条查询语句
select * from user where id_card ="11";
3 explain 分析SQL语句
分析上面的查询语句
EXPLAIN SELECT * FROM `user` where id_card = "11";
可以看到执行结果
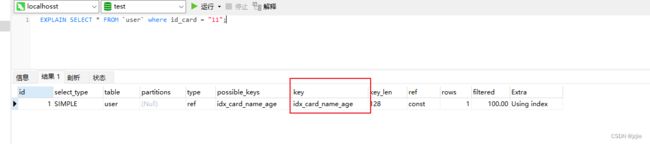
下面我们一 一讲解下这部分结果代表的含义
我先来介绍下图3中sql在expalin执行计划后得一些参数
| 列名 | 含义 |
|---|---|
| id | 选择标识符 |
| select_type | 表示查询的类型,SIMPLE表示简单的select,没有union和子查询。 还有一些 比如 UNION 表示第二个SELECT语句 或者PRIMARY 表示最外层 select 等等 |
| table | 查询sql的表名 |
| partitions | 匹配的分区 |
| type | 连接类型, 重点,重点,重点 如果要有优化sql,一般都是看这个标识 |
| key | 实际选择的索引 |
| key_len | 所选密钥的长度 |
| ref | 显示哪些列或常量与key列中命名的索引进行比较,以便从表中选择行。 |
| rows | 扫描行 表示MySQL认为必须检查才能执行查询的行数 |
| filtered | 过滤的百分比,越高说明过滤的越多,命中率越高 |
| extra | 其他信息,重要,重要,重要,告诉你是否使用了临时表?是否使用内存排序等等,都是优化点 |
我们来着重讲下Explain的用法及如何优化SQL
3.1 select_type 查询类型
select_type表示查询类型,主要分为一下几种
- SIMPLE 简单的select查询
- 查询中不包含子查询或者UNION,上面我们查询的EXPLAIN SELECT * FROM
userwhere id_card = “11”; 不包含任何子查询就是简单类型查询
- 查询中不包含子查询或者UNION,上面我们查询的EXPLAIN SELECT * FROM
- PRIMARY 查询中若包含任何复杂的子查询,最外层查询标记为该标识
- 比如我们查询 explain SELECT * FROM user WHERE user_name IN (SELECT user_name FROM user_info) or user_name=“1”; 外层是 复杂查询,嵌套子查询, 外层查询就是PRIMARY,内层子查询就是SUBQUERY
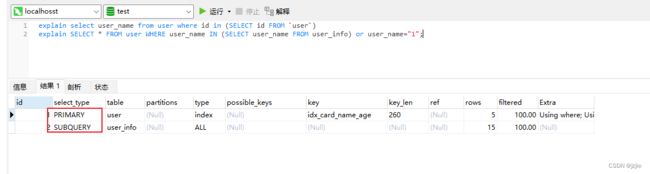
- 比如我们查询 explain SELECT * FROM user WHERE user_name IN (SELECT user_name FROM user_info) or user_name=“1”; 外层是 复杂查询,嵌套子查询, 外层查询就是PRIMARY,内层子查询就是SUBQUERY
- SUBQUERY 在SELECT 或 WHERE 列表中包含了子查询
- 这个SUBQUERY我们在PRIMARY中已经将结果,就是内层的子查询
- DERIVED 在FROM 列表中包含的子查询
- UNION 若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED
- UNION RESULT 从UNION表获取结果的SELECT
- UNION,UNION RESULT都是联合查询才会出现的,比如 EXPLAIN SELECT user_name FROM user UNION SELECT user_name FROM user_info; 就出现了这两种类型 -
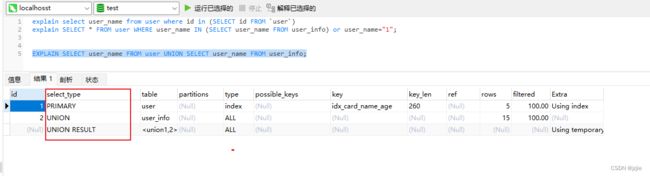
- UNION,UNION RESULT都是联合查询才会出现的,比如 EXPLAIN SELECT user_name FROM user UNION SELECT user_name FROM user_info; 就出现了这两种类型 -
3.2 type 表示连接类型
type 又称访问类型 或者连接类型,即这里的type
比如,type是ref,表名mysql将使用ref方法对改行记录的表进行查询。type字段有着完整的效率高低关系,如下:
null> system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > all,越靠前代表效率越高
我们来看下这几种分别代表什么
- null 表示当前的查询语句不需要访问表,我们直接从索引中就可以取出数据,效率最高
- 比如 explain select id from user where id is null; 我们要查id, where 语句 id is null, 所以他不用查询mysql表,直接通过语句就可以执行处结果,这种type就是null

- 比如 explain select id from user where id is null; 我们要查id, where 语句 id is null, 所以他不用查询mysql表,直接通过语句就可以执行处结果,这种type就是null
- system/const 当表中只有1条记录匹配时,那么时 system/const,效率很高
- 比如 explain select * from user where id =1;根据主键id只能找到1条记录, type就是const

- 比如 explain select * from user where id =1;根据主键id只能找到1条记录, type就是const
- eq_ref 表示唯一索引,对于连接的表结构,如果是主表和附表通过唯一索引进行联合匹配,那么附表的访问方式就是 eq_ref
- 比如访问2个表结构, user表 存在唯一索引 user_name, 附表 user_info 只有主键id索引,没有其他索引字段,现在 连接两个表进行访问
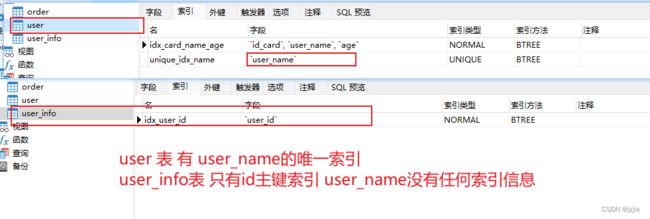
- 我们来看下访问结果, user表,有唯一索引字段user_name的走的就是eq_ref连接索引,但是user_info附表,没有索引字段,走的时全表扫描ALL
- EXPLAIN SELECT * from user INNER JOIN user_info WHERE user.user_name = user_info.user_name;
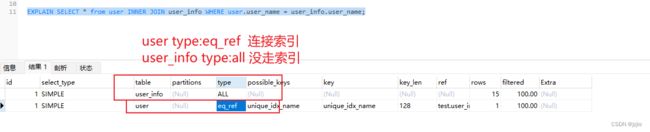
- 比如访问2个表结构, user表 存在唯一索引 user_name, 附表 user_info 只有主键id索引,没有其他索引字段,现在 连接两个表进行访问
- ref 就是非唯一性索引扫描,很实用的正常索引,也就是我们平时用到的最多的
- 我们的user表中有个age的Normal索引,现在对age进行查询搜索,返回匹配age的行,就是最普通的查询请求

- explain select * from user where age=10;

- 我们的user表中有个age的Normal索引,现在对age进行查询搜索,返回匹配age的行,就是最普通的查询请求
- range 表示使用了范围查找 ,where 之后出现 between , < , > , in 等操作。
- index 表示遍历了整个索引树,比ALL强一丢丢,但是也是不行的
- ALL别说了,扫描全表,来匹配需要的数据
从 ref后面的,我们就不详细介绍了,因为一旦出现这些就是你的SQL有问题,就需要优化SQL
3.3 possible_key 和 key
possible_key : 表示这次查询中可能会用到的索引,一般有些字段会创建多个索引,但是本次查询如果涉及到了该字段,那么possible_key中就会出现,只表示 本次可能会用到这个索引,但是真正用到的是不是它,不一定
key: 表示经过查询优化器计算使用不同索引的查询成本之后,最终确定使用的索引
比如 explain select * from user where age=10;
user 表中存在联合索引 idx_card_name_age,又存在唯一索引 indx_age,当查询age=xx的时候,都会涉及到该字段的索引,所以 possible_key :idx_card_name_age,idx_age
真正使用索引key: idx_age

3.4 key_len 表示索引长度
key_ken 表示 实际使用到的索引的长度(即字节数),用来查看是否充分利用了索引,key_len的值越大越好,因为主要是针对的联合索引,因为利用联合索引的长度越大,查询需要读入的数据页就越少,效率也就越高
我们上面 执行 explain select * from user where user_name=“aa”;, 可以看到 key_len长度到达128
3.5 rows 表示扫描行,filtered表示过滤后剩余记录的百分比
rows表示这次SQL查询 扫描的行数,值越小越好,值越小,说明扫描很少行,就找到了数据,效率越高
我们上面 执行 explain select * from user where user_name=“aa”;, rows=1,表示一行就找到了要查询的数据
filtered 表示某个表经过条件过滤之后,剩余记录条数的百分比,值越大越好, 100%表示过滤后100%全都是符合要求的
3.6 extra 表示其他信息,很重要
extra表示 其他的额外的执行计划信息,这里面如果出现了 using filesort和 using temporary表示SQL使用了内存排序及使用了临时表,效率一般都不太行,需要优化
- using filesort
这条语句执行会对数据使用外部的索引排序,而不是按照表内的索引顺序进行读取,表示该SQL无法利用索引完成的排序操作, 称为 “文件排序”, 效率低下,需要优化 - using temporary
这条语句执行会使用了临时表保存中间结果,常见于使用 order by 和 group by;效率低下,需要优化
- using index
表示相应的select操作使用了覆盖索引, 直接从索引中过滤掉不需要的结果,无需回表, 效率不错。
- using index condition
查找使用了索引,但是需要回表查询数据,因为索引列的字段不全,没有完全包含查询列,需要回表操作查询其他字段,效率不错
至此,我们从最左侧匹配引入了Explain的SQL分析,并且指明了如何分析SQL,如何对SQL进行优化,下一篇,我们主要来实践一下 最左侧匹配原则