数据库主从复制-mysql
MySQL主从复制
1.介绍
通过二进制日志方式,达到2台以上MySQL实例数据“同步”(异步同步)。
2.主从复制前提 (搭建)
2.1两台以上数据库实例,版本一致
[root@db01 ~]# systemctl start mysqld3307
[root@db01 ~]# systemctl start mysqld3308
[root@db01 ~]# systemctl start mysqld3309
2.2 区分不同角色
[root@db01 ~]# mysql -S /data/3307/mysql.sock -e "select @@server_id"
@@server_id: 7
[root@db01 ~]# mysql -S /data/3308/mysql.sock -e "select @@server_id"
@@server_id: 8
[root@db01 ~]# mysql -S /data/3309/mysql.sock -e "select @@server_id"
@@server_id: 9
2.3 主库开启二进制日志(3307)
[root@db01 ~]# mysql -S /data/3307/mysql.sock -e "select @@log_bin"
@@log_bin: 1
[root@db01 ~]# mysql -S /data/3307/mysql.sock -e "select @@log_bin_basename"
@@log_bin_basename: /data/3307/mysql-bin
2.4 主库创建专用复制用户
[root@db01 ~]# mysql -S /data/3307/mysql.sock -e "grant replication slave on *.* to repl@'10.0.0.%' identified by '123'"
注意:8.0版本创建用户授权命令
1. create user repl@'10.0.0.%' identified with mysql_native_password by '123';
2. grant replication slave on *.* to repl@'10.0.0.%';
2.5 备份主库数据,恢复从库
[root@db01 data]# mysqldump -S /data/3307/mysql.sock -A --master-data=2 >/tmp/full.sql
[root@db01 data]# mysql -S /data/3308/mysql.sock </tmp/full.sql
[root@db01 data]# mysql -S /data/3309/mysql.sock </tmp/full.sql
2.6 开启从库复制功能(连接信息,复制起点)
[root@db01 ~]# grep "\-- CHANGE MASTER TO" /tmp/full.sql
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000004', MASTER_LOG_POS=674;
#告知两个从库关键复制信息
mysql> CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000004',
MASTER_LOG_POS=674,
MASTER_CONNECT_RETRY=10;
#开启主从专用线程
mysql> start slave;
2.7 检查主从状态
[root@db01 ~]# mysql -S /data/3309/mysql.sock -e "show slave status \G"|grep "Running"
[root@db01 ~]# mysql -S /data/3308/mysql.sock -e "show slave status \G"|grep "Running"
3.主从复制原理
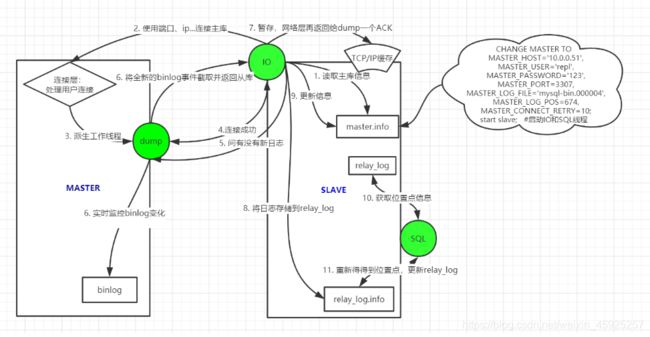
3.1 涉及到的文件
主库:binlog(二进制日志)
从库:relay-log(中继日志):存储请求过来的binlog
master.info:保存主库信息(IP,PORT, USER, PASSWORD, 复制binlog的位置点)
relay-log.info:记录的是从库回放relaylog的位置点信息。
3.2 涉及到的线程
主库:dump: 日志投递线程
从库:IO : 连接主库,请求日志
SQL: 回放日志
3.3 主从复制原理(文字说明)
1. 从库执行change master to 语句:IP、PORT、USER、PASSWD、binlog起点,信息记录到master.info
2. 从库执行start slave 。开启IO、SQL复制线程
3. 从库IO开始工作,读取master.info: IP、 PORT 、USER、PASSWD,连接主库。
4. 主库连接层接收到请求,验证通过后,生成 DUMP线程和IO线程交互。
5. 从库IO 通过master.info : binlog起点,找主库DUMP请求新的binlog
6. 主库DUMP监控着binlog变化,接收到从库IO请求,截取最新的Binlog,传输给IO
7. 从库IO接收到binlog,临时存储再TCP/IP缓存。主库工作到此为止。
8. 从库IO将接收到的日志存储到relay-log中,并更新master.info。IO线程工作结束
9. 从库SQL线程读取relay.info中,获取到上次回放到的relay-log的位置点
10.从库SQL回放新的relaylog,再次更新relay.info。SQL线程工作结束。
彩蛋:
11. relay_log_purge线程,对relay-log有自动清理的功能。
12. 主库dump线程实时监控binlog的变化,自动通知给从库IO。
4.主从复制监控
4.1主库监控
mysql> show processlist;
mysql> show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 9 | | 3309 | 7 | d1492ae9-6728-11ea-ad4b-000c29248f69 |
| 8 | | 3308 | 7 | ced6749c-6728-11ea-ab51-000c29248f69 |
+-----------+------+------+-----------+--------------------------------------+
4.2 从库监控
mysql> show slave status \G
主库信息汇总:master.info
Master_Host: 10.0.0.51
Master_User: repl
Master_Port: 3307
Connect_Retry: 10
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 674
从库relaylog回放到的位置点:relay-log.info
Relay_Log_File: db01-relay-bin.000004
Relay_Log_Pos: 320
从库的线程状态:log_error
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
过滤复制相关信息:
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
监控主从延时:
Seconds_Behind_Master: 0
延时从库的状态:
SQL_Delay: 0
SQL_Remaining_Delay: NULL
GTID复制状态:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
5. 主从复制故障原因分析
5.0 监控方法
show slave status \G
从库的线程状态:log_error
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
5.1 IO
5.1.1 连接主库:connecting
可能原因:
连接信息有误。
网络故障。
防火墙。
最大连接数上线。
排查方法:
[root@db01 data]# mysql -urepl -p123 -h10.0.0.51 -P 3307
处理方法:
mysql -S /data/3308/mysql.sock -e "stop slave;reset slave all;"
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000004',
MASTER_LOG_POS=674,
MASTER_CONNECT_RETRY=10;
start slave;
5.1.2 请求日志: NO
主库日志损坏。
日志起点写错。
server_id重复
排查方法:
mysql> show slave status \G
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 674
Last_IO_Error: xxxx
5.2 SQL 线程故障: 回放中继日志
5.2.1 中继日志损坏
环境准备:
1. 从库停SQL线程
stop slave sql_thread ;
2. 主库发生新的操作
create database test1;
3. 从库删除relaylog
rm -rf /data/3308/data/db01-relay-bin.00000*
4. 启动SQL线程
start slave sql_thread ;
修复:
1)cat /data/3308/data/relay-log.info ----> binlog 位置点
7
./db01-relay-bin.000002
320
mysql-bin.000001
154
0
0
1
2)重构
stop slave;
reset slave all;
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=154,
MASTER_CONNECT_RETRY=10;
start slave;
5.2.2 日志回放失败(执行不了SQL)
1)修改的对象不存在
2)创建的对象已存在
3)约束冲突
4)主从配置不同
5)SQL_MODE不兼容
6)主从版本差异
方法0:从库逆反操作
mysql> drop 已有的
mysql> stop slave;
mysql> start slave;
方法一:
stop slave;
set global sql_slave_skip_counter = 1;
#将同步指针向下移动一个,如果多次不同步,可以重复操作。
start slave;
方法二
/etc/my.cnf
slave-skip-errors = 1032,1062,1007
常见错误代码:
1007:对象已存在
1032:无法执行DML
1062:主键冲突,或约束冲突
但是,以上操作有时是有风险的,最安全的做法就是重新构建主从。把握一个原则,一切以主库为主.
方法三: PT工具
pt-table-checksum
pt-table-sync
方法四:从库只读
mysql> select @@read_only;
mysql> select @@super_read_only;
6. 主从复制延时
主库做了操作,从库很久才回放
6.1 主库方面
6.1.1 提供binlog
binlog日志文件落地(写入磁盘)不及时,sync_binlog=1(控制实时将日志写入磁盘)
6.1.2传输binlog
传统claassic 模式(无GTID),dump线程传输日志是串行的。主库可以并行多个事务。
产生问题:大事务、并发事务量大。都会导致较高延时。
5.6 版本加入了GTID功能,在传输时就可以并行传输日志了。
5.7 版本即使没开GTID,会自动生成Anonymous_Gtid。
6.2 从库方面
6.2.1 relay 落地
无其他影响因素,唯一因素就是从库所在的磁盘性能
6.2.2 SQL回访
单一SQL线程(默认一个),只能串行回放relaylog。主库可以并发事务,并行传输日志,回放时是串行的。
产生问题:如果大事务,并发事务量大。都会导致较高回放延时。
5.6 版本GTID模式下,可以开启多个SQL线程。但是,5.6多SQL回放时,只能针对不同database并行回放。
5.7 版本GTID模式下,可以开启多个SQL线程,真正实现了并性回放(MTS)
6.3 外部因素
网络慢
主从配置相差大 (例如主库固态盘,从库机械盘)
7.过滤复制
7.1 介绍
部分数据复制

7.2 配置方法
主库:
binlog_do_db=world
binlog_ignore_db
从库:
库级别
replicate_do_db=world
replicate_do_db=test
replicate_ignore_db=
表级别:
replicate_do_table=world.city
replicate_ignore_table=
模糊:
replicate_wild_do_table=world.t*
replicate_wild_ignore_table=
7.3 模拟(只同步oldguo和olddoy库)
[root@db01 3309]# cat /data/3309/my.cnf
[mysqld]
basedir=/data/app/mysql
datadir=/data/3309/data
socket=/data/3309/mysql.sock
log_error=/data/3309/mysql.log
port=3309
server_id=9
log_bin=/data/3309/mysql-bin
replicate_do_db=oldguo
replicate_do_db=oldboy
systemctl restart mysqld3309
7.4 在线修改
stop slave sql_thread;
change replication filter replicate_do_db=(oldguo,oldboy)
start slave sql_thread;
取消:
stop slave sql_thread;
change replication filter replicate_do_db=()
start slave sql_thread;
8. 延时从库
8.1 介绍
人为设置的一种特殊从库,主库变更,在延时时间过后,从库才执行。
8.2 什么是数据损坏
逻辑损坏:DROP delete truncate update
物理损坏:磁盘,文件
8.3 配置
mysql>stop slave;
mysql>CHANGE MASTER TO MASTER_DELAY = 300;
mysql>start slave;
mysql> show slave status \G
SQL_Delay: 300
SQL_Remaining_Delay: NULL
8.4 怎么用
8.4.1 思路
1)场景假设:
主库 drop database oldguo; 9:00
2)监控故障 9:10
发现业务olgduo业务不能正常运行
3)挂维护页
4)停止主从
判断业务是否还有流量,停止主从
5)修复数据
使用relay-log修复数据
起点:relay- log.info ---> sQL线程执行到的位置点
终点:drop之前
6)业务恢复
从库替代主库工作
7)主从修复(后话)
8.4.2模拟故障,使用延时从恢复数据
1.主库模拟基础数据
create database delaydb charset utf8mb4;
use delaydb;
create table t1 (idint);
insert into t1 values(1),(2),(3);
commit;
create table t2 (id int);
insert into t2 values(1),(2),(3);
commit;
create table t3 (id int);
insert into t3 values(1),(2),(3);
commit;
drop database delaydb;
2.从库
1)线程
mysql> stop slave;
2)截取relaylog
起点:
mysql> show slave status\G
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 476
终点:
| db01-relay-bin.000002 | 2039 | Query | 7 | 3284 | drop database delaydb
mysql> show relaylog events in 'db01-relay-bin.000002';
[root@db01 data]# cd /data/3309/data/
[root@db01 data]# mysqlbinlog --start-position=476 --stop-position=2039 db01-relay-bin.000002 >/tmp/relay.sql
3)恢复relaylog 到从库
mysql> stop slave;
mysql> reset slave all;
mysql> reset master;
mysql> set sql_log_bin=0;
mysql> source /tmp/relay.sql
mysql> set sql_log_bin=1;
8.5 主从数据一致: 半同步复制、无损复制、MGR
5.5 版本加入,半同步复制。
1)不能100%保证,主从一致性。
2)性能拉低很多
5.6 gtid 串行传输日志,串行SQL,可以缓解。
5.7 增强半同步复制,无损复制。
https://dev.mysql.com/doc/refman/5.7/en/replication-semisync.html
5.7.17 加入MGR ,8.0以后MGR 。
https://www.jianshu.com/p/8c66e0f65324
9.GTID复制
9.1 优势
1)每个事务都有唯一逻辑编号,并具备幂等性
2)截取binlog时更加灵活、方便(include-gtids --exclude-gtids)
3)主从复制,提高性能:dump传输日志并行,SQL线程并行回放。
4)主从复制搭建、监控延时、数据一-致性保证。
9.2 搭建
9.2.1 准备3台独立虚拟机节点
9.2.2 清理环境(3个节点)
pkill mysqld
rm -rf /data/3306/*
mv /etc/my.cnf /tmp
9.2.3 创建需要的目录
mkdir -p /data/3306/data /data/3306/binlog
chown -R mysql.mysql /data
9.2.4 准备配置文件
db01
cat > /etc/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/data/app/mysql
datadir=/data/3306/data
server_id=6
socket=/tmp/mysql.sock
log_bin=/data/3306/binlog/mysql-bin
gtid_mode=ON
enforce_gtid_consistency
log-slave-updates=1
secure-file-priv=/tmp
innodb_data_file_path=ibdata1:128M;ibdata2:128M:autoextend
innodb_temp_data_file_path=ibtmp1:128M;ibtmp2:128M:autoextend:max:500M
innodb_undo_tablespaces=3
innodb_max_undo_log_size=128M
innodb_undo_log_truncate=ON
innodb_purge_rseg_truncate_frequency=32
autocommit=0
innodb_flush_method=O_DIRECT
slow_query_log=ON
slow_query_log_file=/data/3306/data/db01-slow.log
long_query_time=0.1
log_queries_not_using_indexes
[client]
socket=/tmp/mysql.sock
[mysql]
prompt=db01 [\\d]>
socket=/tmp/mysql.sock
EOF
db02
cat > /etc/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/data/app/mysql
datadir=/data/3306/data
server_id=7
socket=/tmp/mysql.sock
log_bin=/data/3306/binlog/mysql-bin
gtid_mode=ON
enforce_gtid_consistency
log-slave-updates=1
secure-file-priv=/tmp
innodb_data_file_path=ibdata1:128M;ibdata2:128M:autoextend
innodb_temp_data_file_path=ibtmp1:128M;ibtmp2:128M:autoextend:max:500M
innodb_undo_tablespaces=3
innodb_max_undo_log_size=128M
innodb_undo_log_truncate=ON
innodb_purge_rseg_truncate_frequency=32
autocommit=0
innodb_flush_method=O_DIRECT
slow_query_log=ON
slow_query_log_file=/data/3306/data/db01-slow.log
long_query_time=0.1
log_queries_not_using_indexes
[client]
socket=/tmp/mysql.sock
[mysql]
prompt=db02 [\\d]>
socket=/tmp/mysql.sock
EOF
db03
cat > /etc/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/data/app/mysql
datadir=/data/3306/data
server_id=8
socket=/tmp/mysql.sock
log_bin=/data/3306/binlog/mysql-bin
gtid_mode=ON
enforce_gtid_consistency
log-slave-updates=1
secure-file-priv=/tmp
innodb_data_file_path=ibdata1:128M;ibdata2:128M:autoextend
innodb_temp_data_file_path=ibtmp1:128M;ibtmp2:128M:autoextend:max:500M
innodb_undo_tablespaces=3
innodb_max_undo_log_size=128M
innodb_undo_log_truncate=ON
innodb_purge_rseg_truncate_frequency=32
autocommit=0
innodb_flush_method=O_DIRECT
slow_query_log=ON
slow_query_log_file=/data/3306/data/db01-slow.log
long_query_time=0.1
log_queries_not_using_indexes
[client]
socket=/tmp/mysql.sock
[mysql]
prompt=db03 [\\d]>
socket=/tmp/mysql.sock
EOF
9.2.5 初始化数据
mysqld --initialize-insecure --user=mysql --basedir=/data/app/mysql --datadir=/data/3306/data
9.2.6 启动数据库
/etc/init.d/mysqld start
9.2.7 构建主从
1)db01创建用户
db01 [(none)]>grant replication slave on *.* to repl@'10.0.0.%' identified by '123';
2)db02、db03构建主从
change master to
master_host='10.0.0.51',
master_user='repl',
master_password='123' ,
MASTER_AUTO_POSITION=1;
start slave;
9.3 gtid 构建时的不同点
MASTER_AUTO_POSITION=1;
参数功能:第一次构建主从时,自动检查最后一个relay的gtid信息,检查没有SET @@GLOBAL.GTID_PURGED='1c35b73a-7321-11ea-8974-000c29248f69:1-10'参数
如果都没有信息。就从主库的第一个GTID事件开始全新复制binlog日志。
注意: 备份主库数据 ,恢复至从库的方式构建GTID主从,不要 --set-gtid-purged=OFF
9.4 查看监控信息
Last_SQL_Error: Error 'Can't create database 'oldboy'; database exists' on query. Default database: 'oldboy'. Query: 'create database oldboy'
Retrieved_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-3
Executed_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-2
解决—注入空事物的方法:
stop slave;
set gtid_next='71bfa52e-4aae-11e9-ab8c-000c293b577e:3';
begin;commit;
set gtid_next='AUTOMATIC';
10.主从复制架演变
10.1基础架构
1主1从
1主多从
多级主从
双主结构
10.2 高级架构
10.2.1 高可用架构
1)故障转移
2)数据一致保证
3)代表产品
MHA(faceback、RDS MySQL(TMHA)、Oracle官方Operator(K8s+MHA))
PXC(Percona)
MGC(mariaDB)
MySQL Cluster
Mycat
InnoDB Cluster(8.0.17 clone plugin) 未来 2-3年
10.2.2高性能架构
1)读写分离:
Atlas
ProxySQL
Maxscale
Mycat
2)分布式架构:
Mycat
DBLE
sharding-jdbc
ProxySQL
10.2.3 NewSQL
PinCAP TiDB
Aliyun PolarDB
Google Spanner