渗透测试-最全Web 渗透测试信息搜集-CheckList
干货 | 最全Web 渗透测试信息搜集-CheckList
文章目录
- 干货 | 最全Web 渗透测试信息搜集-CheckList
- 前言
- 1.获取真实IP
- 2.如何判断是否是CDN
-
-
- 使用ping域名判断是否有CDN
- 使用不同主机ping域名判断是否有CDN
- 使用nslookup域名解析判断是否有CDN
-
- 3.如何绕过CDN获取真实IP
-
- 使用国外主机请求域名
- 网站信息泄露漏洞
- 邮件信息
- 目标网站APP应用
- 4.旁站查询(IP反查)
-
- Nmap扫描获取旁站信息
- 第三方服务获取旁站信息
- 5.C段主机查询
-
- Nmap扫描C段
- 搜索引擎语法收集C段信息
- 在线C段扫描工具
- 本地C段扫描工具(其中某些工具不只是C段扫描)
- 6.子域名查询
-
- 枚举发现子域名
- 搜索引擎发现子域名
- 第三方聚合服务发现子域名
- 证书透明性信息发现子域名
- DNS域传送发现子域名
-
- 利用nmap漏洞检测脚本dns-zone-transfer进行检测
- Linux dig命令进行测试
- 7.端口扫描
-
- 常见端口及对应服务表:
- 8.目录探测
- 9.指纹识别
-
- 服务器信息搜集
- CMS识别
- 特定关键字识别
- 特定文件及路径识别
- 响应头信息识别
- 指纹识别工具
- 10.Google hacking
- 11.社工信息收集
-
- whois信息
-
- 在线工具
- 12.社会工程学
-
- 最后
前言
这篇文章是21年中旬记录的,平安夜p牛的直播中也谈到,对于渗透测试来说最好有一个checklist,为了避免忘记测试某一部分的内容而错过一些重要信息,同时有了checklist也容易利用自己喜欢的语言实现自动化,突然想起了这篇信息搜集相关的文章所以就分享出来。
1.获取真实IP
为了保证网络的稳定和快速传输,网站服务商会在网络的不同位置设置节点服务器,通过CDN(Content Delivery Network,内容分发网络)技术,将网络请求分发到最优的节点服务器上面。如果网站开启了CDN加速,就无法通过网站的域名信息获取真实的IP,要对目标的IP资源进行收集,就要绕过CDN查询到其真实的IP信息。
2.如何判断是否是CDN
在对目标IP信息收集之前,首先要判断目标网站是否开启了CDN,一般通过不同地方的主机ping域名和nslookup域名解析两种方法,通过查看返回的IP是否是多个的方式来判断网站是否开启了CDN,如果返回的IP信息是多个不同的IP,那就有可能使用了CDN技术。
使用ping域名判断是否有CDN
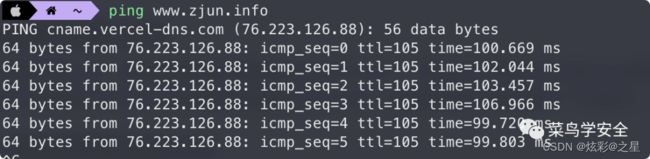
直接使用ping域名查看回显地址来进行判断,如下回显cname.vercel-dns.com,很明显使用了cdn技术。
使用不同主机ping域名判断是否有CDN
如果自己在多地都有主机可以ping域名,就可以根据返回的IP信息进行判断。互联网有很多公开的服务可以进行多地ping来判断是否开启了CDN,比如以下几个:
全球Ping测试:https://www.wepcc.com/
站长工具Ping检测:http://ping.chinaz.com/
爱站网Ping检测:https://ping.aizhan.com/
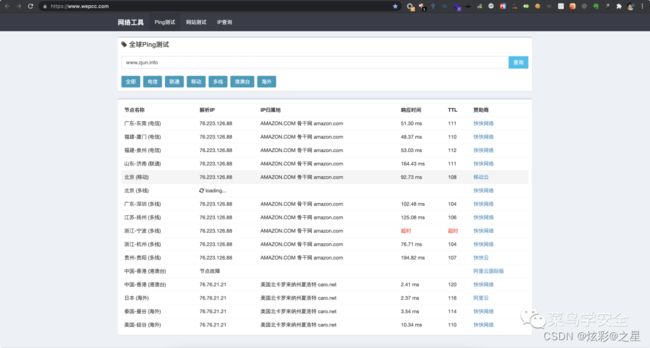
可以发现对www.zjun.info的全球ping测试,有76.223.126、76.76.21.21这两个不同的解析IP,说明www.zjun.info可能使用了CDN。
使用nslookup域名解析判断是否有CDN
通过系统自带的nslookup命令对域名解析,发现其中的Name字段直接指向cname.vercel-dns.com,毫无疑问使用了CDN技术。

又比如www.baidu.com,其中Address字段也是指向两个不同IP,即www.baidu.com可能使用了CDN。

3.如何绕过CDN获取真实IP
查询子域名
由于CDN加速需要支付一定的费用,很多网站只对主站做了CDN加速,子域名没有做CDN加速,子域名可能跟主站在同一个服务器或者同一个C段网络中,可以通过子域名探测的方式,收集目标的子域名信息,通过查询子域名的IP信息来辅助判断主站的真实IP信息。
查询历史DNS记录
通过查询DNS与IP绑定的历史记录就有可能发现之前的真实IP信息,常用的第三方服务网站有:
dnsdb:https://dnsdb.io/zh-cn/
viewdns:https://viewdns.info/iphistory/
微步在线:https://x.threatbook.cn/
使用国外主机请求域名
部分国内的CDN加速服务商只对国内的线路做了CDN加速,但是国外的线路没有做加速,这样就可以通过国外的主机来探测真实的IP信息。
探测的方式也有两种,可以利用已有的国外主机直接进行探测;如果没有国外主机,可以利用公开的多地ping服务(多地ping服务有国外的探测节点),可以利用国外的探测节点返回的信息来判断真实的IP信息。
网站信息泄露漏洞
利用网站存在的漏洞和信息泄露的敏感信息、文件(如:phpinfo文件、网站源码文件、Github泄露的信息等)获取真实的IP信息。
phpinfo页面中有一个SERVER_ADDR字段会显示该主机真实IP。
邮件信息
一般的邮件系统都在内部,没有经过CDN的解析,通过利用目标网站的邮箱注册、找回密码或者RSS订阅等功能,接收到发来的邮件后,查看邮件源码就可以获得目标的真实IP。

目标网站APP应用
如果目标网站有自己的App,可以尝试利用Burp Suite等流量抓包工具抓取App的请求,从里面可能会找到目标的真实IP。
4.旁站查询(IP反查)
旁站是与攻击目标在同一服务器上的不同网站,获取到目标真实IP的情况下,在攻击目标没有可利用漏洞的情况下,可以通过查找旁站的漏洞攻击旁站,然后再通过提权拿到服务器的最高权限,拿到服务器的最高权限后攻击目标也就拿下了。
旁站信息收集也称为IP反查,主要有以下方式:
Nmap扫描获取旁站信息
使用命令
nmap -sV -p 1-65535 x.x.x.x
对目标IP进行全端口扫描,确保每个可能开放的端口服务都能识别到。
第三方服务获取旁站信息
旁站信息可以通过第三方服务进行收集,比如在线网站与搜索引擎等。以下是几个在线搜集网站:
站长工具同IP网站查询:http://s.tool.chinaz.com/same
webscan:https://www.webscan.cc/
云悉:https://www.yunsee.cn/
微步在线:https://x.threatbook.cn/
在线旁站查询|C段查询|必应接口C段查询:http://www.bug8.me/bing/bing.php
也可以利用搜索引擎语法来实现查询
bing
https://cn.bing.com/search?q=ip:x.x.x.x
fofa
ip=“x.x.x.x”
5.C段主机查询
C段主机是指与目标服务器在同一C段网络的服务器。攻击目标的C段存活主机是信息收集的重要步骤,很多企业的内部服务器可能都会在一个C段网络中。在很难找到攻击目标服务器互联网漏洞的情况下,可以通过攻击C段主机,获取对C段主机的控制权,进入企业内网,在企业的内网安全隔离及安全防护不如互联网防护健全的情况下,可以通过C段的主机进行内网渗透,这样就可以绕过互联网的防护,对目标进行攻击。但是这种攻击方式容易打偏。
Nmap扫描C段
使用命令nmap -sn x.x.x.x/24,对目标IP的C段主机进行存活扫描,根据扫描的结果可以判断目标IP的C段还有哪些主机存活。
nmap -Pn这个命令在实际工作中的使用很多,该命令不通过ICMP协议进行主机存活判断,会直接对端口进行扫描。这样在开启了防火墙禁Ping的情况下,也可以利用这个命令正常扫描目标是否存活及对外开启的相关服务。
搜索引擎语法收集C段信息
site:x.x.x.*
Fofa
ip=“x.x.x.x/24”
在线C段扫描工具
在线旁站查询|C段查询|必应接口C段查询:http://www.bug8.me/bing/bing.php
查旁站:https://chapangzhan.com/
云悉:https://www.yunsee.cn/
本地C段扫描工具(其中某些工具不只是C段扫描)
httpscan:https://github.com/zer0h/httpscan
小米范web查找器
Goby:https://gobies.org/
bufferfly:https://github.com/dr0op/bufferfly
cscan:https://github.com/z1un/cscan
6.子域名查询
子域名是父域名的下一级,比如blog.zjun.info和tools.zjun.info这两个域名是zjun.info的子域名。一般企业对于主站域名的应用的防护措施比较健全,不管是应用本身的漏洞发现、漏洞修复,还是安全设备相关的防护都做得更加及时和到位,而企业可能有多个、几十个甚至更多的子域名应用,因为子域名数量多,企业子域名应用的防护可能会没有主站及时。攻击者在主站域名找不到突破口时,就可以进行子域名的信息收集,然后通过子域名的漏洞进行迂回攻击。子域名信息收集主要包含枚举发现子域名、搜索引擎发现子域名、第三方聚合服务发现子域名、证书透明性信息发现子域名、DNS域传送发现子域名等方式。
枚举发现子域名
子域名收集可以通过枚举的方式对子域名进行收集,枚举需要一个好的字典,制作字典时会将常见子域名的名字放到字段里面,增加枚举的成功率。子域名暴力破解常用的工具以下:
在线子域名查询:https://phpinfo.me/domain/
OneForAll:https://github.com/shmilylty/OneForAll
knock:https://github.com/guelfoweb/knock
subDomainsBrute:https://github.com/lijiejie/subDomainsBrute
Layer子域名挖掘机:https://github.com/euphrat1ca/LayerDomainFinder
搜索引擎发现子域名
使用搜索引擎语法,如
Google或者百度等
site:xxx.com
Fofa
domain=“xxx.com”
第三方聚合服务发现子域名
第三方聚合平台 Netcraft、Virustotal、ThreatCrowd、DNSdumpster 和 ReverseDNS 等获取子域信息。
Sublist3r:https://github.com/aboul3la/Sublist3r
OneForAll:https://github.com/shmilylty/OneForAll
证书透明性信息发现子域名
证书透明性(Certificate Transparency,CT)是Google的公开项目,通过让域所有者、CA和域用户对SSL证书的发行和存在进行审查,来纠正这些基于证书的威胁。具体而言,证书透明性具有三个主要目标:
使CA无法(或至少非常困难)为域颁发SSL证书,而该域的所有者看不到该证书;
提供一个开放的审核和监视系统,该系统可以让任何域所有者或CA确定证书是错误的还是恶意颁发的;
尽可能防止用户被错误或恶意颁发的证书所欺骗。
证书透明性项目有利有弊。通过证书透明性,可以检测由证书颁发机构错误颁发的SSL证书,可以识别恶意颁发证书的证书颁发机构。因为它是一个开放的公共框架,所以任何人都可以构建或访问驱动证书透明性的基本组件,CA证书中包含了域名、子域名、邮箱等敏感信息,存在一定的安全风险。
利用证书透明性进行域名信息收集,一般使用CT日志搜索引擎进行域名信息收集,如在线网站:
https://crt.sh/
https://transparencyreport.google.com/https/certificates
https://developers.facebook.com/tools/ct/
本地工具:
ctfr:https://github.com/UnaPibaGeek/ctfr
OneForAll:https://github.com/shmilylty/OneForAll
DNS域传送发现子域名
DNS服务器分为:主服务器、备份服务器和缓存服务器。在主备服务器之间同步数据库,需要使用“DNS域传送”。域传送是指备份服务器从主服务器拷贝数据,并用得到的数据更新自身数据库。
若DNS服务器配置不当,可能导致攻击者获取某个域的所有记录。造成整个网络的拓扑结构泄露给潜在的攻击者,包括一些安全性较低的内部主机,如测试服务器。同时,黑客可以快速的判定出某个特定zone的所有主机,收集域信息,选择攻击目标,找出未使用的IP地址,绕过基于网络的访问控制。目前来看"DNS域传送漏洞"已经很少了。
利用nmap漏洞检测脚本dns-zone-transfer进行检测
nmap --script dns-zone-transfer --script-args dns-zone-transfer.domain=xxx.edu.cn
Linux dig命令进行测试
dig xxx.com ns
dig axfr @dns xxx.com
7.端口扫描
最常用的就是nmap
-sS (TCP SYN扫描)
-sT (TCP connect()扫描)
-sU (UDP扫描)
-sN; -sF; -sX (TCP Null,FIN,and Xmas扫描)
-Pn (不通过ICMP探测)
详细文档:
https://nmap.org/man/zh/
其次可能还会用到masscan:
https://github.com/robertdavidgraham/masscan
常见端口及对应服务表:

8.目录探测
在信息搜集中,目录扫描是一个很重要的步骤,可以帮助我们获得如网站的测试页面、后台地址、常见第三方高危组件路径等。但是目前多数网站都有云waf、主机防护等,对于频繁访问的IP会封禁处理。对于云waf,找到网站真实IP是很关键的,其余的情况基本都可以修改开源工具代码利用IP代理池或控制访问频率的方式进行探测。
常用目录扫描工具如下:
dirsearch:https://github.com/maurosoria/dirsearch
dirmap:https://github.com/H4ckForJob/dirmap
御剑目录扫描:https://github.com/foryujian/yjdirscan
dirb:https://tools.kali.org/web-applications/dirb
IP代理池推荐:
ProxyPool:https://github.com/Python3WebSpider/ProxyPool
9.指纹识别
常见的指纹识别内容有CMS识别、框架识别、中间件识别、WAF识别。CMS识别一般利用不同的CMS特征来识别,常见的识别方式包括特定关键字识别、特定文件及路径识别、CMS网站返回的响应头信息识别等。
服务器信息搜集
服务版本识别、操作系统信息识别都可以利用nmap实现识别
nmap -sV -p 1-65535 x.x.x.x
nmap -O x.x.x.x
CMS识别
识别CMS的目的在于,方便利用已公开漏洞进行渗透测试,甚至可以到对应CMS的官网下载对应版本的CMS进行本地白盒代码审计。
特定关键字识别
CMS的首页文件、特定文件可能包含了CMS类型及版本信息,通过访问这些文件,将返回的网页信息(如Powered by XXCMS)与扫描工具数据库存储的指纹信息进行正则匹配,判断CMS的类型。
也可能前端源码中或meta标签中的content字段存在一些CMS特征信息,下图很明显能得知是WordPress框架。

特定文件及路径识别
不同的CMS会有不同的网站结构及文件名称,可以通过特定文件及路径识别CMS。如WordPress会有特定的文件路径/wp-admin、/wp-includes等,有些CMS的robots.txt文件也可能包含了CMS特定的文件路径,与扫描工具数据库存储的指纹信息进行正则匹配,判断CMS的类型。
CMS会有一些JS、CSS、图片等静态文件,这些文件一般不会变化,可以利用这些特定文件的MD5值作为指纹信息来判断CMS的类型。
响应头信息识别
应用程序会在响应头Server、X-Powered-By、Set-Cookie等字段中返回Banner信息或者自定义的数据字段,通过响应头返回的信息,可以对应用进行识别,有些WAF设备也可以通过响应头信息进行识别判断。当然Banner信息并不一定是完全准确的,应用程序可以自定义自己的Banner信息。
例如Shiro的响应头信息中包含rememberMe字段:

指纹识别工具
指纹识别常用的工具如下:
whatweb:https://github.com/urbanadventurer/WhatWeb
wappalyzer:https://github.com/AliasIO/wappalyzer
Glass:https://github.com/s7ckTeam/Glass
还有两款只支持如WordPress, Joomla, Drupal的工具
CMSScan:https://github.com/ajinabraham/CMSScan
CMSmap:https://github.com/Dionach/CMSmap
云悉:https://www.yunsee.cn/
bugscaner在线cms识别:http://whatweb.bugscaner.com/look/
10.Google hacking
目录遍历: site:$site intitle:index.of
配置文件泄露: site:$site ext:xml | ext:conf | ext:cnf | ext:reg | ext:inf | ext:rdp | ext:cfg | ext:txt | ext:ora | ext:ini
数据库文件泄露: site:$site ext:sql | ext:dbf | ext:mdb
日志文件泄露: site:$site ext:log
备份和历史文件: site:$site ext:bkf | ext:bkp | ext:bak | ext:old | ext:backup
登录页面: site:$site inurl:login
SQL错误: site:$site intext:“sql syntax near” | intext:“syntax error has occurred” | intext:“incorrect syntax near” | intext:“unexpected end of SQL command” | intext:“Warning: mysql_connect()” | intext:“Warning: mysql_query()” | intext:“Warning: pg_connect()”
公开文件信息: site:$site ext:doc | ext:docx | ext:odt | ext:pdf | ext:rtf | ext:sxw | ext:psw | ext:ppt | ext:pptx | ext:pps | ext:csv
phpinfo(): site:$site ext:php intitle:phpinfo “published by the PHP Group”
搜索粘贴站点: site:pastebin.com | site:paste2.org | site:pastehtml.com | site:slexy.org | site:snipplr.com | site:snipt.net | site:textsnip.com | site:bitpaste.app | site:justpaste.it | site:heypasteit.com | site:hastebin.com | site:dpaste.org | site:dpaste.com | site:codepad.org | site:jsitor.com | site:codepen.io | site:jsfiddle.net | site:dotnetfiddle.net | site:phpfiddle.org | site:ide.geeksforgeeks.org | site:repl.it | site:ideone.com | site:paste.debian.net | site:paste.org | site:paste.org.ru | site:codebeautify.org | site:codeshare.io | site:trello.com $site
搜索Github、Gitlab: site:github.com | site:gitlab.com $site.
在线Google Hacking利用:https://tools.zjun.info/googlehacking/
11.社工信息收集
主要是对目标企业单位的关键员工、供应商和合作伙伴等相关信息进行收集。通过社工可以了解目标企业的人员组织结构,通过分析人员组织结构,能够判断关键人员并对其实施社会工程学鱼叉钓鱼攻击。收集到的相关信息还可以进行社工库查询或字典的制作,用于相关应用系统的暴力破解。
whois信息
whois是用来查询域名的IP及所有人等信息的传输协议。whois的本质就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商),可以通过whois来实现对域名信息的查询。whois查询可以通过命令行或网页在线查询工具。
11.社工信息收集
主要是对目标企业单位的关键员工、供应商和合作伙伴等相关信息进行收集。通过社工可以了解目标企业的人员组织结构,通过分析人员组织结构,能够判断关键人员并对其实施社会工程学鱼叉钓鱼攻击。收集到的相关信息还可以进行社工库查询或字典的制作,用于相关应用系统的暴力破解。
whois命令
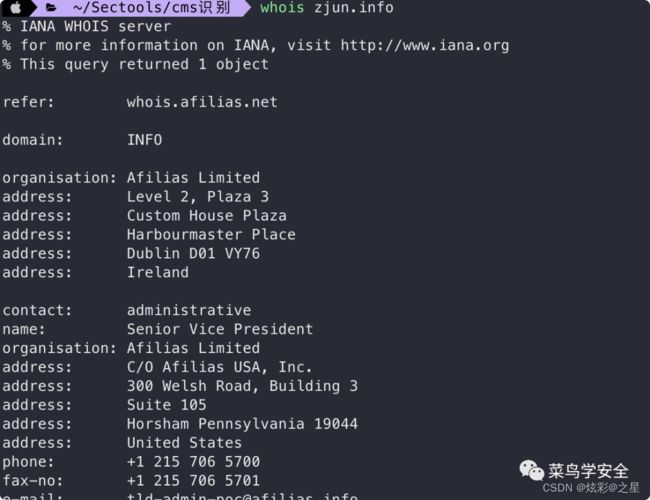
whois xxx.com
后面的具体信息就没截出来了,可以查询域名的所有人、注册商等相关信息:
在线工具
站长工具whois查询:http://tool.chinaz.com/ipwhois
爱站网whois查询:https://whois.aizhan.com/
12.社会工程学
社会工程学收集的信息有很多,包含网络ID(现用和曾用)、真实姓名、手机号、电子邮箱、出生日期、身份证号、银行卡、支付宝账号、QQ号、微信号、家庭地址、注册网站(贴吧、微博、人人网等)等信息。
在目标相关网页中可能会存在招聘信息、客服联系等,可以利用招聘或客服聊天的方式进行钓鱼、木马植入等。
搜集到相关的人员信息后可以制作社工字典,有如下在线或本地工具:
bugku密码攻击器:https://www.bugku.com/mima/
白鹿社工字典生成器:https://github.com/z3r023/BaiLu-SED-Tool
除了制作社工字典进行暴破外,还可以用已知信息进行社工库查询,涉及敏感信息了,所以不给出链接,在Telegram软件中充斥着大量免费或付费的社工查询。
最后
补充一个网址:https://gitbook.se7ensec.cn/
信息收集在线工具集合网站