《Java开发手册(泰山版)》内容摘取,个人笔记
背景:
这几天挤时间看了阿里的《Java开发手册(泰山版)》,记录了部分常见或可作为参考的地方,也是一个自我梳理的过程。
一、编程规约
(一) 命名风格
1.【强制】包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用
单数形式,但是类名如果有复数含义,类名可以使用复数形式。
正例:应用工具类包名为 com.alibaba.ei.kunlun.aap.util、类名为 MessageUtils(此规则参考 spring 的
框架结构)
2.【强制】避免在子父类的成员变量之间、或者不同代码块的局部变量之间采用完全相同的命名,
使可读性降低。
3.【推荐】为了达到代码自解释的目标,任何自定义编程元素在命名时,使用尽量完整的单词组
合来表达。
4.【推荐】在常量与变量的命名时,表示类型的名词放在词尾,以提升辨识度。
正例:startTime / workQueue / nameList / TERMINATED_THREAD_COUNT
5.【强制】POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架(如GSON)解析会引起序列
化错误。
6.【参考】各层命名规约:
A) Service/DAO 层方法命名规约
1) 获取单个对象的方法用 get 做前缀。
2) 获取多个对象的方法用 list 做前缀,复数结尾,如:listObjects。
3) 获取统计值的方法用 count 做前缀。
4) 插入的方法用 save/insert 做前缀。
5) 删除的方法用 remove/delete 做前缀。
6) 修改的方法用 update 做前缀。
B) 领域模型命名规约
1) 数据对象:xxxDO,xxx 即为数据表名。
2) 数据传输对象:xxxDTO,xxx 为业务领域相关的名称。
3) 展示对象:xxxVO,xxx 一般为网页名称。
4) POJO 是 DO/DTO/BO/VO 的统称,禁止命名成 xxxPOJO。
(二) 代码格式
1.【强制】if/for/while/switch/do 等保留字与括号之间都必须加空格。
2.【强制】任何二目、三目运算符的左右两边都需要加一个空格。
说明:包括赋值运算符=、逻辑运算符&&、加减乘除符号等。
3.【强制】采用 4 个空格缩进,禁止使用 tab 字符。
说明:如果使用 tab 缩进,必须设置 1 个 tab 为 4 个空格。IDEA 设置 tab 为 4 个空格时,请勿勾选 Use tab
character;
4.【强制】注释的双斜线与注释内容之间有且仅有一个空格。
5.【强制】单行字符数限制不超过 120 个,超出需要换行,换行时遵循如下原则:
1)第二行相对第一行缩进 4 个空格,从第三行开始,不再继续缩进,参考示例。
2)运算符与下文一起换行。
3)方法调用的点符号与下文一起换行。
4)方法调用中的多个参数需要换行时,在逗号后进行。
5)在括号前不要换行,见反例。
正例:
StringBuilder sb = new StringBuilder();
// 超过 120 个字符的情况下,换行缩进 4 个空格,并且方法前的点号一起换行
sb.append(“zi”).append(“xin”)…
.append(“huang”)…
.append(“huang”)…
.append(“huang”);
6.【强制】方法参数在定义和传入时,多个参数逗号后边必须加空格。
正例:下例中实参的 args1,后边必须要有一个空格。
method(args1, args2, args3);
7.【强制】IDE 的 text file encoding 设置为 UTF-8; IDE 中文件的换行符使用 Unix 格式,不要
使用 Windows 格式。
8.【推荐】单个方法的总行数不超过 80 行。
9.【推荐】不同逻辑、不同语义、不同业务的代码之间插入一个空行分隔开来以提升可读性。
说明:任何情形,没有必要插入多个空行进行隔开。
(三) OOP 规约
1.【强制】所有整型包装类对象之间值的比较,全部使用 equals 方法比较。
说明:对于 Integer var = ? 在-128 至 127 之间的赋值,Integer 对象是在 IntegerCache.cache 产生,
会复用已有对象,这个区间内的 Integer 值可以直接使用==进行判断,但是这个区间之外的所有数据,都
会在堆上产生,并不会复用已有对象,这是一个大坑,推荐使用 equals 方法进行判断。
2.【强制】浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用 equals
来判断。
说明:浮点数采用“尾数+阶码”的编码方式,类似于科学计数法的“有效数字+指数”的表示方式。二进
制无法精确表示大部分的十进制小数。
正例:
(1) 指定一个误差范围,两个浮点数的差值在此范围之内,则认为是相等的。
float a = 1.0f - 0.9f;
float b = 0.9f - 0.8f;
float diff = 1e-6f;
if (Math.abs(a - b) < diff) {
System.out.println(“true”);
}
(2) 使用 BigDecimal 来定义值,再进行浮点数的运算操作。
BigDecimal a = new BigDecimal(“1.0”);
BigDecimal b = new BigDecimal(“0.9”);
BigDecimal c = new BigDecimal(“0.8”);
BigDecimal x = a.subtract(b);
BigDecimal y = b.subtract©;
if (x.equals(y)) {
System.out.println(“true”);
}
3.【强制】序列化类新增属性时,请不要修改 serialVersionUID 字段,避免反序列失败;如果
完全不兼容升级,避免反序列化混乱,那么请修改 serialVersionUID 值。
说明:注意 serialVersionUID 不一致会抛出序列化运行时异常。
4.【强制】POJO 类必须写 toString 方法。使用 IDE 中的工具:source> generate toString
时,如果继承了另一个 POJO 类,注意在前面加一下 super.toString。
说明:在方法执行抛出异常时,可以直接调用 POJO 的 toString()方法打印其属性值,便于排查问题。
5.【推荐】循环体内,字符串的连接方式,使用 StringBuilder 的 append 方法进行扩展。
说明:下例中,反编译出的字节码文件显示每次循环都会 new 出一个 StringBuilder 对象,然后进行 append
操作,最后通过 toString 方法返回 String 对象,造成内存资源浪费。
反例:
String str = “start”;
for (int i = 0; i < 100; i++) {
str = str + “hello”;
}
(四) 集合处理
1.【强制】判断所有集合内部的元素是否为空,使用 isEmpty()方法,而不是 size()==0 的方式。
说明:前者的时间复杂度为 O(1),而且可读性更好。
2.【强制】使用 Map 的方法 keySet()/values()/entrySet()返回集合对象时,不可以对其进行添
加元素操作,否则会抛出 UnsupportedOperationException 异常。
3.【强制】使用工具类 Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法,
它的 add/remove/clear 方法会抛出 UnsupportedOperationException 异常。
说明:asList 的返回对象是一个 Arrays 内部类,并没有实现集合的修改方法。Arrays.asList 体现的是适配
器模式,只是转换接口,后台的数据仍是数组。
String[] str = new String[] { “yang”, “hao” };
List list = Arrays.asList(str);
第一种情况:list.add(“garden”); 运行时异常。
第二种情况:str[0] = “changed”; 也会随之修改,反之亦然。
4…【推荐】使用 entrySet 遍历 Map 类集合 KV,而不是 keySet 方式进行遍历。
说明:keySet 其实是遍历了 2 次,一次是转为 Iterator 对象,另一次是从 hashMap 中取出 key 所对应的
value。而 entrySet 只是遍历了一次就把 key 和 value 都放到了 entry 中,效率更高。如果是 JDK8,使用
Map.forEach 方法。
正例:values()返回的是 V 值集合,是一个 list 集合对象;keySet()返回的是 K 值集合,是一个 Set 集合对
象;entrySet()返回的是 K-V 值组合集合。
5.【推荐】高度注意 Map 类集合 K/V 能不能存储 null 值的情况,如下表格:
| 集合类 | Key | Value | Super | 说明 |
|---|---|---|---|---|
| Hashtable | 不允许为 null | 不允许为 null | Dictionary | 线程安全 |
| ConcurrentHashMap | 不允许为 null | 不允许为 null | AbstractMap | 锁分段技术(JDK8:CAS) |
| TreeMap | 不允许为 null | 允许为 null | AbstractMap | 线程不安全 |
| HashMap | 允许为 null | 允许为 null | AbstractMap | 线程不安全 |
反例:由于 HashMap 的干扰,很多人认为 ConcurrentHashMap 是可以置入 null 值,而事实上,存储
null 值时会抛出 NPE 异常。
6.【参考】合理利用好集合的有序性(sort)和稳定性(order),避免集合的无序性(unsort)和不稳
定性(unorder)带来的负面影响。
说明:有序性是指遍历的结果是按某种比较规则依次排列的。稳定性指集合每次遍历的元素次序是一定的。
如:ArrayList 是 order/unsort;HashMap 是 unorder/unsort;TreeSet 是 order/sort。
(五) 并发处理
1.【推荐】表达异常的分支时,少用 if-else 方式,这种方式可以改写成:
if (condition) {
…
return obj;
}
// 接着写 else 的业务逻辑代码;
说明:如果非使用 if()…else if()…else…方式表达逻辑,避免后续代码维护困难,请勿超过 3 层。
正例:超过 3 层的 if-else 的逻辑判断代码可以使用卫语句、策略模式、状态模式等来实现,其中卫语句
示例如下:
public void findBoyfriend (Man man){
if (man.isUgly()) {
System.out.println(“本姑娘是外貌协会的资深会员”);
return;
}
if (man.isPoor()) {
System.out.println(“贫贱夫妻百事哀”);
return;
}
if (man.isBadTemper()) {
System.out.println(“银河有多远,你就给我滚多远”);
return;
}
System.out.println(“可以先交往一段时间看看”);
}
2.【推荐】除常用方法(如 getXxx/isXxx)等外,不要在条件判断中执行其它复杂的语句,将复
杂逻辑判断的结果赋值给一个有意义的布尔变量名,以提高可读性。
说明:很多 if 语句内的逻辑表达式相当复杂,与、或、取反混合运算,甚至各种方法纵深调用,理解成本
非常高。如果赋值一个非常好理解的布尔变量名字,则是件令人爽心悦目的事情。
3.【推荐】避免采用取反逻辑运算符。
说明:取反逻辑不利于快速理解,并且取反逻辑写法必然存在对应的正向逻辑写法。
4.【参考】下列情形,需要进行参数校验:
1) 调用频次低的方法。
2) 执行时间开销很大的方法。此情形中,参数校验时间几乎可以忽略不计,但如果因为参数错误导致
中间执行回退,或者错误,那得不偿失。
3) 需要极高稳定性和可用性的方法。
4) 对外提供的开放接口,不管是 RPC/API/HTTP 接口。
5) 敏感权限入口。
(六) 注释规约
1.【强制】类、类属性、类方法的注释必须使用 Javadoc 规范,使用/*内容/格式,不得使用
// xxx 方式。
说明:在 IDE 编辑窗口中,Javadoc 方式会提示相关注释,生成 Javadoc 可以正确输出相应注释;在 IDE
中,工程调用方法时,不进入方法即可悬浮提示方法、参数、返回值的意义,提高阅读效率。
2.【强制】所有的抽象方法(包括接口中的方法)必须要用 Javadoc 注释、除了返回值、参数、
异常说明外,还必须指出该方法做什么事情,实现什么功能。
说明:对子类的实现要求,或者调用注意事项,请一并说明。
3.【强制】所有的类都必须添加创建者和创建日期。
日期的设置统一为 yyyy/MM/dd 的格式。
4.【强制】方法内部单行注释,在被注释语句上方另起一行,使用//注释。方法内部多行注释使
用/* */注释,注意与代码对齐。
5.【强制】所有的枚举类型字段必须要有注释,说明每个数据项的用途。
6.【参考】好的命名、代码结构是自解释的,注释力求精简准确、表达到位。避免出现注释的一
个极端:过多过滥的注释,代码的逻辑一旦修改,修改注释是相当大的负担。
(七) 其它
1.【强制】错误码为字符串类型,共 5 位,分成两个部分:错误产生来源+四位数字编号。
说明:错误产生来源分为 A/B/C,A 表示错误来源于用户,比如参数错误,用户安装版本过低,用户支付
超时等问题;B 表示错误来源于当前系统,往往是业务逻辑出错,或程序健壮性差等问题;C 表示错误来源
于第三方服务,比如 CDN 服务出错,消息投递超时等问题;四位数字编号从 0001 到 9999,大类之间的
步长间距预留 100。
2.【强制】应用中不可直接使用日志系统(Log4j、Logback)中的 API,而应依赖使用日志框架
(SLF4J、JCL–Jakarta Commons Logging)中的 API,使用门面模式的日志框架,有利于维护和
各个类的日志处理方式统一。
3.【强制】所有日志文件至少保存 15 天,因为有些异常具备以“周”为频次发生的特点。
4.【强制】异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过
关键字 throws 往上抛出。
正例:logger.error(各类参数或者对象 toString() + “_” + e.getMessage(), e);
5.【推荐】谨慎地记录日志。生产环境禁止输出 debug 日志;有选择地输出 info 日志;如果使用
warn 来记录刚上线时的业务行为信息,一定要注意日志输出量的问题,避免把服务器磁盘撑
爆,并记得及时删除这些观察日志。
说明:大量地输出无效日志,不利于系统性能提升,也不利于快速定位错误点。记录日志时请思考:这些
日志真的有人看吗?看到这条日志你能做什么?能不能给问题排查带来好处?
6.【强制】单元测试应该是全自动执行的,并且非交互式的,元测试用例之间
决不能互相调用,也不能依赖执行的先后次序。测试用例通常是被定期执行的,执
行过程必须完全自动化才有意义。输出结果需要人工检查的测试不是一个好的单元测试。
单元测试中不准使用 System.out 来进行人肉验证,必须使用 assert 来验证。
二、安全公约
1.【强制】隶属于用户个人的页面或者功能必须进行权限控制校验。
说明:防止没有做水平权限校验就可随意访问、修改、删除别人的数据,比如查看他人的私信内容。
2.【强制】用户敏感数据禁止直接展示,必须对展示数据进行脱敏。
说明:中国大陆个人手机号码显示为:137****0969,隐藏中间 4 位,防止隐私泄露。
3.【强制】表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint
(1 表示是,0 表示否)。
说明:任何字段如果为非负数,必须是 unsigned。
注意:POJO 类中的任何布尔类型的变量,都不要加 is 前缀,所以,需要在设置从 is_xxx 到
Xxx 的映射关系[POJO字段用注解@TableField对应tb中的字段]。数据库表示是与否的值,使用 tinyint 类型,
坚持 is_xxx 的命名方式是为了明确其取值含义与取值范围。
正例:表达逻辑删除的字段名 is_deleted,1 表示删除,0 表示未删除。
三、MySQL 数据库
(一) 建表规约
1.【强制】禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字。
2.【强制】小数类型为 decimal,禁止使用 float 和 double。
说明:在存储的时候,float 和 double 都存在精度损失的问题,很可能在比较值的时候,得到不正确的
结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数并分开存储。
3.【强制】表必备三字段:id, gmt_create, gmt_modified。
说明:其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。gmt_create, gmt_modified
的类型均为 datetime 类型,前者现在时表示主动式创建,后者过去分词表示被动式更新。
4.【推荐】表的命名最好是遵循“业务名称_表的作用”。
5.【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索
速度。(eg:年龄,150岁以内,tinyint,1个字节,无符号值:0-255)
(二) 索引规约
1.【强制】业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外,
即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
2.【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
(三) SQL语句
1.【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
外键与级联更新适用于单机低并发,不适合分布式、高并发集群;
级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
2.【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
3.【强制】数据订正(特别是删除或修改记录操作)时,要先 select,避免出现误删除,确认无
误才能执行更新语句。
(四) ORM 映射
1.【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明:1)增加查询分析器解析成本。2)增减字段容易与 resultMap 配置不一致。3)无用字段增加网络
消耗,尤其是 text 类型的字段。
2.【强制】POJO 类的布尔属性不能加 is,而数据库字段必须加 is_,要求在 resultMap 中进行
字段与属性之间的映射。
3.【强制】不允许直接拿 HashMap 与 Hashtable 作为查询结果集的输出。
反例:某同学为避免写一个
是把 bigint 转成 Long 值,而线上由于数据库版本不一样,解析成 BigInteger,导致线上问题。
4.【强制】更新数据表记录时,必须同时更新记录对应的 gmt_modified 字段值为当前时间。
四、工程结构
(一) 工程结构
- 【推荐】图中默认上层依赖于下层,箭头关系表示可直接依赖,如:开放接口层可以依赖于
Web 层,也可以直接依赖于 Service 层,依此类推:
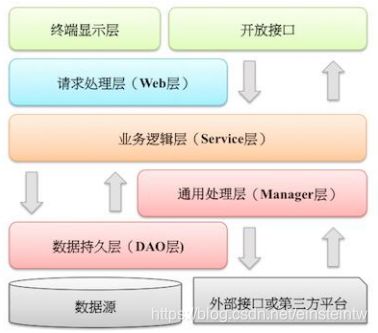
• 开放接口层:可直接封装 Service 方法暴露成 RPC 接口;通过 Web 封装成 http 接口;网关控制层等。
• 终端显示层:各个端的模板渲染并执行显示的层。当前主要是 velocity 渲染,JS 渲染,JSP 渲染,移
动端展示等。
• Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
• Service 层:相对具体的业务逻辑服务层。
• Manager 层:通用业务处理层,它有如下特征:
1) 对第三方平台封装的层,预处理返回结果及转化异常信息。
2) 对 Service 层通用能力的下沉,如缓存方案、中间件通用处理。
3) 与 DAO 层交互,对多个 DAO 的组合复用。
• DAO 层:数据访问层,与底层 MySQL、Oracle、Hbase、OB 等进行数据交互。
• 外部接口或第三方平台:包括其它部门 RPC 开放接口,基础平台,其它公司的 HTTP 接口。
(二) 二方库依赖
-
【强制】定义 GAV 遵从以下规则:
1) GroupID 格式:com.{公司/BU }.业务线 [.子业务线],最多 4 级。
说明:{公司/BU} 例如:alibaba/taobao/tmall/aliexpress 等 BU 一级;子业务线可选。
正例:com.taobao.jstorm 或 com.alibaba.dubbo.register
2) ArtifactID 格式:产品线名-模块名。语义不重复不遗漏,先到中央仓库去查证一下。
正例:dubbo-client / fastjson-api / jstorm-tool
3) Version:详细规定参考下方。 -
【强制】二方库版本号命名方式:主版本号.次版本号.修订号
1)主版本号:产品方向改变,或者大规模 API 不兼容,或者架构不兼容升级。
2) 次版本号:保持相对兼容性,增加主要功能特性,影响范围极小的 API 不兼容修改。
3) 修订号:保持完全兼容性,修复 BUG、新增次要功能特性等。
说明:注意起始版本号必须为:1.0.0,而不是 0.0.1。
反例:仓库内某二方库版本号从 1.0.0.0 开始,一直默默“升级”成 1.0.0.64,完全失去版本的语义信息。
五、设计公约
1.【推荐】需求分析与系统设计在考虑主干功能的同时,需要充分评估异常流程与业务边界。
反例:用户在淘宝付款过程中,银行扣款成功,发送给用户扣款成功短信,但是支付宝入款时由于断网演
练产生异常,淘宝订单页面依然显示未付款,导致用户投诉。
2.【推荐】系统设计阶段,根据依赖倒置原则,尽量依赖抽象类与接口,有利于扩展与维护。
说明:低层次模块依赖于高层次模块的抽象,方便系统间的解耦。
3.【推荐】系统设计阶段,共性业务或公共行为抽取出来公共模块、公共配置、公共类、公共方
法等,在系统中不出现重复代码的情况。
说明:随着代码的重复次数不断增加,维护成本指数级上升。
泰山版《Java开发手册》