深入理解MVCC与bufferPool缓存机制
Mysql在读已提交和可重复读隔离级别下都实现了MVCC机制。
MVCC(Muti-Version Concurrency Controller)多版本并发控制机制
undo日志版本链与read view机制详解:undo日志表示的是回滚日志
通过事务id和回滚指针来判断比对的。
在可重复读隔离级别,当事务开启,执行任何查询sql时会生成当前事务的一致性视图read-view,该视图在事务结束 之前都不会变化(如果是读已提交隔离级别在每次执行查询sql时都会重新生成),这个视图由执行查询时所有未提交事务id数组(数组里最小的id为min_id)和已创建的最大事务id(max_id)组成,事务里的任何sql查询结果需要从对应 版本链里的最新数据开始逐条跟read-view做比对从而得到最终的快照结果。
如果是开启的是读已提交机制,则在每次查询的时候都会查询获取一组最新事务id,然后再进行比对.
版本链比对规则:
1. 如果 row 的 trx_id 落在绿色部分( trx_id
2. 如果 row 的 trx_id 落在红色部分( trx_id>max_id ),表示这个版本是由将来启动的事务生成的,是不可见的(若row 的 trx_id 就是当前自己的事务是可见的;
3. 如果 row 的 trx_id 落在黄色部分(min_id <=trx_id<= max_id),那就包括两种情况
a. 若 row 的 trx_id 在视图数组中,表示这个版本是由还没提交的事务生成的,不可见(若 row 的 trx_id 就是当前自己的事务是可见的);
b. 若 row 的 trx_id 不在视图数组中,表示这个版本是已经提交了的事务生成的,可见。
对于删除的情况可以认为是update的特殊情况,会将版本链上最新的数据复制一份,然后将trx_id修改成删除操作的trx_id,同时在该条记录的头信息(record header)里的(deleted_flag)标记位写上true,来表示当前记录已经被删除,在查询时按照上面的规则查到对应的记录如果delete_flag标记位为true,意味着记录已被删除,则不返回数据。
注意:
begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个修改操作InnoDB表的语句,事务才真正启动,才会向mysql申请事务id,mysql内部是严格按照事务的启动顺序来分配事务id的。
undo log版本链:
每条数据都有俩个隐藏的字段,一个是trx_id,另一个是roll_pointer,trx_id是最近一次更新这条数据的事务id,roll_pointer就是指向了你更新这个事务之前生成的undo log。
Read View:
你执行一个事务的时候,就给你生成一个readView,里面由四个部分组成:
m_ids:这个就是说此时有哪些事务在mysql里执行还没提交
min_trx_id:就是m_ids中最小的值
max_trx_id:这是mysql下一个要生成的事务id,就是最大的事务id
current_trx_id:当前事务的id
eg:
1.如数据库有一行数据(原始值),事务id=7; 此后有并发请求过来,事务A(id=10),事务B(id=12),事务A想进行查询操作,事务B想进行更新操作。此时事务A开启Read View,这时的Read View里的m_ids包含有事务A和事务B的id ,即10和12;则此时已知min_trx_id=10,max_trx_id=13,current_trx_id=10,这时事务A第一次查询这一行数据,会先进行判断当前的行数据trx_id是否小于Read View中min_trx_id(10),而行数据的trx_id=7,确实小。说明在事务A开启之前,该行数据事务早已提交,所以事务A可以查到该行数据。
2.接着事务B,事务B也查询到改行数据(原始值),并将该行数据(原始值)修改为b,最新一次更新的事务id设置成12(即trx_id=12),同时roll_pointer指向之前修改行数据的undo log,事务B提交。
3.当事务A再次去查询行数据时,发现trx_id=12,这个trx_id比Read View中min_trx_id=10大,比max_trx_id=13小,说明该行数据不能查询,则需要查询最近那个undo log里的值,基于undo log多版本链条快照链条可以读到之前的快照值。
4.接着事务A自己更新了这行数据(原数据),并将改行数据(原始值)修改为a,trx_id设置为10,同时保存事务B修改值的快照。则当事务A再来查询这行数据时,发现这个trx_id=10,与自己的Read View中的current_trx_id=10 是一样的,说明这行数据是自己修改的,自己就可以读到!
5.接着又开启了一个事务C(id=20),事务C更新了行数据值为c,并提交了。
6.当事务A再次去查询时,发现trx_id=20,比自己Read View中max_trx_id=13还要大,说明事务A开启后,又有一个新事务修改了数据,则自己看不到!就会顺着undo log多版本链条往下找,找到自己之前修改过的那个undo log版本链,那个trx_id=10跟自己的Read View中的current_trx_id=10 是一样的,则读取到自己修改的那版本数据。

总结:
MVCC机制的实现就是通过read-view机制与undo版本链比对机制,使得不同的事务会根据数据版本链对比规则读取同一条数据在版本链上的不同版本数据。
当开启事务后,某一事务第一次开启事务时就会生成read view。
规则:将所有为提交的事务id存放在一个数组中,找到最大的事务id.
Eg:[100,200],300
事务id小于100的,都是已提交的事务,可见
在100和300之间的,是未提交或者已提交的事务,不可见
事务id大于300的,是事务未开启的。不可见
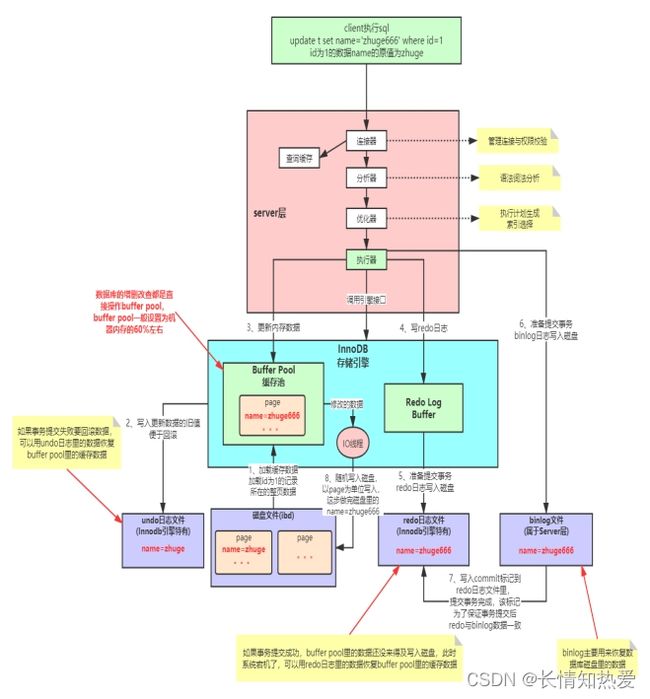
Innodb引擎SQL执行的BufferPool缓存机制:
undo日志主要用来回滚数据来恢复buffer pool里的缓存数据.
Redo日志主要是用来,当mysql数据库宕机后,重连接之后.将redo日志的数据同步到buffer pool中.
Binlog日志文件,主要用于被删库后,用来恢复数据库磁盘里的数据
如下图: