java 异构类型
几乎所有计算系统中都存在异构硬件:我们的智能手机包含中央处理器(CPU)和具有多个内核的图形处理单元(GPU); 我们的笔记本电脑很可能包含带有集成GPU和专用GPU的多核CPU; 数据中心正在向其系统添加附加的现场可编程门阵列(FPGA),以加快专业化的任务,同时降低能耗。 而且,公司正在实施自己的硬件以加速专业程序。 例如,谷歌开发了一种处理器,用于更快地处理TensorFlow计算,称为Tensor处理单元(TPU)。 这种硬件专业化和硬件加速器的最近流行是由于摩尔定律的终结。在摩尔定律中,由于物理限制,每个新一代的CPU不再使每处理器的晶体管数量每两年增加一倍。 因此,获得更快的硬件以加速应用程序的方法是通过硬件专业化。
硬件专业化的主要挑战是可编程性 。 每个异构硬件很可能都有自己的编程模型和自己的并行编程语言。 诸如OpenCL , SYCL和map-reduce框架之类的标准有助于对新硬件和/或并行硬件进行编程。 但是,许多并行编程框架都是为低级编程语言(例如Fortran,C和C ++)创建的。
尽管这些编程语言仍被广泛使用,但现实是工业界和学术界倾向于使用更高级的编程语言,例如Java,Python,Ruby,R和Javascript。 因此,现在的问题是, 如何使用那些高级编程语言中的新异构硬件 ?
当前,该问题有两种主要解决方案:a)通过外部库,其中用户可能仅限于一组众所周知的功能; b)通过将低层并行硬件细节公开给高层程序的包装器(例如,JOCL是从Java编程OpenCL的包装器,开发人员需要在其中了解OpenCL编程模型,数据管理,线程调度等) )。 但是,这些新的并行和异构硬件的许多潜在用户不一定是并行计算的专家,也许需要更简单的解决方案。
在本文中,我们讨论TornadoVM,它是OpenJDK的插件,它使开发人员能够在异构硬件上自动透明地运行Java程序,而无需任何有关并行计算或异构编程模型的知识。 TornadoVM当前支持多核CPU,GPU和FPGA上的硬件加速,并且能够通过在以下位置在多个设备之间执行代码迁移(例如,从多核系统到GPU)来动态地使其执行适应最佳目标设备。运行。 TornadoVM是由曼彻斯特大学(英国)开发的研究项目,它是完全开源的,可在Github上使用 。 在本文中,我们概述了TornadoVM,以及程序员如何在多核CPU和GPU上自动加速摄影过滤器。
TornadoVM如何工作?
TornadoVM的总体思想是编写或修改尽可能少的代码行,并在加速器(例如GPU)上自动执行该代码。 TornadoVM透明地管理执行,内存管理和同步,而无需指定有关要运行的实际硬件的任何详细信息。
TornadoVM的体系结构由传统的分层体系结构与微内核体系结构组成,其中核心组件是其运行时系统。 下图显示了所有TornadoVM组件以及它们之间如何交互的高层概述。

在最高级别,TornadoVM向Java开发人员公开API。 该API允许用户通过在异构硬件上运行它们来确定要加速的方法。 该编程框架的一个重要方面是它不会自动检测并行性。 相反,它在任务级别利用并行性,其中每个任务对应于一个现有的Java方法。
TornadoVM-API还可以创建一组任务,称为任务计划。 相同任务时间表(与任务时间表关联的所有Java方法)内的所有任务都在同一设备(例如,在同一GPU上)上编译和执行。 通过将多个任务(方法)作为任务计划的一部分,TornadoVM可以进一步优化主主机(CPU)和目标设备(例如GPU)之间的数据移动。 这是由于主机和目标设备之间未共享内存。 因此,我们需要将数据从CPU的主内存复制到加速器的内存(通常通过PCIe总线)。 这些数据传输确实非常昂贵,并且可能损害我们应用程序的端到端性能。 因此,通过创建一组任务,如果TornadoVM检测到某些数据可以保留在目标设备上,而无需与所执行的每个内核(Java方法)与主机端同步,则可以进一步优化数据移动。
还请参见:您是哪种Java开发人员? 参加我们的Java测验找出答案!
以下代码段显示了如何使用TornadoVM编程典型的map-reduce计算的示例。 Sample类包含三种方法:一种执行矢量加法(映射)的方法;另一种执行矢量加法(映射)。 另一种计算约简(减少)的方法,最后一种创建任务计划并执行(计划)的方法。 要加速的方法是方法图和归约方法。 请注意,用户使用诸如@Parallel和@Reduce之类的注释扩充了序列代码,这些注释用作TornadoVM编译器并行化代码的提示。 最后一个方法(计算)创建任务计划Java类的实例,并指定要加速的方法。 在下一部分中,我们将通过完整的示例详细介绍API。
public class Sample {
public static void map(float[] a, float[] b, float[] c) {
for (@Parallel int i = 0; i < c.length; i++) {
c[i] = a[i] + b[i];
}
}
public static void reduce(float[] input, @Reduce float[] out) {
for (@Parallel int i = 0; i < input.length; i++) {
out[0] += input[i];
}
}
public void compute(float[] a, float[] b, float[] c, float[] output) {
TaskSchedule ts = new TaskSchedule("s0")
.task("map", Sample::map, a, b, c)
.task("reduce", Sample::reduce, c, output)
.streamOut(output)
.execute();
}
}TornadoVM运行时层分为两个子组件:任务优化器和字节码生成器。 任务优化器采用任务计划中的所有任务,并分析其中的数据依赖关系(数据流运行时分析)。 正如我们前面提到的,此操作的目的是优化跨任务的数据移动。
一旦TornadoVM运行时系统优化了数据传输,它就会生成内部特定于TornadoVM的字节码。 这些字节码对开发人员不可见,它们的作用是协调异构设备上的执行。 在下一个块中,我们将显示内部TornadoVM字节码的示例。
生成TornadoVM字节码后,执行引擎将在字节码解释器中执行它们。 字节码是简单的指令,可以在内部对其进行重新排序以执行优化-例如,将计算与通信重叠。
以下代码段显示了为先前代码段中所示的map-reduce示例生成的字节码的列表。 每个任务计划都包含在BEGIN-END字节码之间。 每个字节码后面的数字是任务计划中所有任务将在其上执行的设备。 但是,可以在运行期间随时更改设备。 回想一下,我们正在此特定的任务计划中运行两个任务(映射方法和简化方法)。 对于每种方法(或任务),TornadoVM需要预分配数据并执行相应的数据传输。 因此,TornadoVM执行COPY_IN,它将为只读数据(例如示例中的数组a和b )分配和复制数据,并通过调用以下命令为输出(仅写)变量分配设备缓冲区上的空间。 ALLOC字节码。 所有字节码都有其他字节码可以引用的字节码索引(bi)。 例如,由于许多字节码的执行是非阻塞的,因此TornadoVM通过运行ADD_DEP字节码和要等待的字节码索引列表来增加障碍。
还请参见: Java 13 –为什么文本块值得等待
然后,为了运行内核(Java方法),TornadoVM执行字节码LAUNCH。 第一次执行此字节码时,TornadoVM将从Java字节码编译引用的方法(在我们的示例中为map和reduce的方法)到OpenCLC。由于编译器实际上是源到源(从Java字节码到OpenCL) C),需要另一个编译器。 后者的编译器是每个目标设备驱动程序(例如,用于NVIDIA的GPU驱动程序,或用于Intel FPGA的英特尔驱动程序)的驱动程序的一部分,它将OpenCL C编译为二进制文件。 然后,TornadoVM将最终的二进制文件存储在其代码缓存中。 如果任务计划被重用并再次执行,TornadoVM将从代码缓存中获取优化的二进制文件,从而节省了重新编译的时间。 一旦所有任务执行完毕,TornadoVM通过运行COPY_OUT_BLOCK字节码将最终结果复制到主机存储器中。
BEGIN <0>
COPY_IN <0, bi1, a>
COPY_IN <0, bi2, b>
ALLOC <0, bi3, c>
ADD_DEP <0, b1, b2, b3>
LAUNCH <0, bi4, @map, a, b, c>
ALLOC <0, bi5, output>
ADD_DEP <0, b4, b5>
LAUNCH <0, bi7, @reduce, c, output>
COPY_OUT_BLOCK <0, bi8, output>
END <0>下图显示了TornadoVM如何执行和编译从Java到OpenCL的代码的高级表示。 JIT编译器是曼彻斯特大学开发的OpenCL的Graal JIT编译器的扩展。 在内部,JIT编译器为输入程序构建控制流程图(CFG)和数据流程图(DFG),这些流程图在不同的编译层中进行了优化。 在TornadoVM JIT编译器中,当前存在三层优化:a)与体系结构无关的优化(HIR),例如循环展开,恒定传播,并行循环探索或并行模式检测。 b)内存优化,例如MIR中的对齐,以及c)依赖于体系结构的优化。 优化代码后,TornadoVM将遍历优化的图形并生成OpenCL C代码,如下图右侧所示。
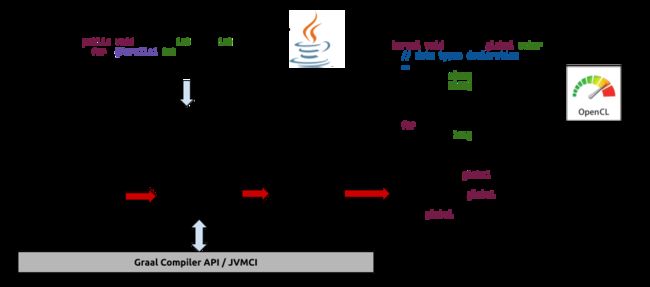
此外,执行引擎会自动处理内存,并保持设备缓冲区(分配给目标设备)和主机缓冲区(分配给Java堆)之间的一致性。 由于编译和执行由TornadoVM自动管理,因此TornadoVM的最终用户不必担心内部细节。
测试TornadoVM
本节显示了一些如何编程和运行TornadoVM的示例。 作为示例,我们展示了一个简单的程序,该程序如何将输入的彩色JPEG图像转换为灰度图像。 然后,我们展示如何在不同的设备上运行它并评估其性能。 本文提供的所有示例均可在Github上在线获得 。
灰度转换Java代码
将彩色JPEG图像转换为灰度的Java方法如下:
class Image {
private static void grayScale(int[] image, final int w, final int s) {
for (int i = 0; i < w; i++) {
for (int j = 0; j < s; j++) { int rgb = image[i * s + j]; // get the pixel int alpha = (rgb >> 24) & 0xff;
int red = (rgb >> 16) & 0xFF;
int green = (rgb >> 8) & 0xFF;
int blue = (rgb & 0xFF);
int grayLevel = (red + green + blue) / 3;
int gray = (alpha << 24) | (grayLevel << 16) | (grayLevel << 8) | grayLevel;
image[i * s + j] = gray;
}
}
}
}对于图像中的每个像素,都会获得alpha,红色,绿色和蓝色通道。 然后将它们全部组合为一个值,以显示相应的灰色像素,该像素最终再次存储到像素的图像阵列中。
由于该算法可以并行执行,因此它是使用TorandoVM进行硬件加速的理想选择。 要使用TornadoVM编程相同的算法,我们首先使用@Parallel批注来注释可能并行运行的循环。 TornadoVM将检查循环并分析两次迭代之间是否没有数据依赖性。 在这种情况下,TornadoVM将使代码专用于在OpenCL中使用2D索引。 对于此示例,代码如下所示:
class Image {
private static void grayScale(int[] image, final int w, final int s) {
for (@Parallel int i = 0; i < w; i++) {
for (@Parallel int j = 0; j < s; j++) { int rgb = image[i * s + j]; // get the pixel int alpha = (rgb >> 24) & 0xff;
int red = (rgb >> 16) & 0xFF;
int green = (rgb >> 8) & 0xFF;
int blue = (rgb & 0xFF);
int grayLevel = (red + green + blue) / 3;
int gray = (alpha << 24) | (grayLevel << 16) | (grayLevel << 8) | grayLevel;
image[i * s + j] = gray;
}
}
}
}请注意,我们为两个循环引入了@Parallel 。 此后,我们需要指示TornadoVM加速此方法。 为此,我们创建一个任务计划,如下所示:
TaskSchedule ts = new TaskSchedule("s0")
.streamIn(imageRGB)
.task("t0", Image::grayScale, imageRGB, w, s)
.streamOut(imageRGB);
// Execute the task-schedule (blocking call)
ts.execute();任务计划是描述所有要加速的任务的对象。 首先,我们传递一个名称来标识任务计划(在本例中为“ s0” ,但可以是任何名称)。 然后,我们定义要流式传输到输入任务的Java数组。 此调用向TornadoVM表示,每次调用execute方法时,我们都希望复制数组的内容。 否则,如果在streamIn中未指定任何变量,TornadoVM将为任务执行所需的所有变量创建一个缓存的只读副本。
下一个调用是任务调用。 我们可以在同一任务计划中创建任意数量的任务。 如前一节所述,每个任务都引用一个现有的Java方法。 任务的参数如下:首先,我们传递一个名称(在本例中,我们将其命名为“ t0” ,但也可以是任何其他名称); 然后我们传递lambda表达式或对Java方法的引用。 在我们的例子中,我们从Java类Image中传递了grayScale方法。 最后,我们将所有参数传递给该方法,就像其他任何方法调用一样。
之后,我们需要向TornadoVM指示要与主机(主CPU)再次同步的变量。 在我们的例子中,我们希望用加速的灰度更新同一张输入的JPEG图像。 在内部,此调用将强制OpenCL中的数据从设备移动到主机,并将数据从设备的全局内存复制到驻留在主机内存中的Java堆。 这四行仅声明要使用的任务和变量。 但是,在程序员调用execute方法之前,不会执行任何操作。
创建程序后,我们将使用标准javac对其进行编译。 在TornadoSDK(一旦机器上安装了TornadoVM)中,提供了实用程序命令以使用javac进行编译,并设置了所有类路径和库:
$ javac.py Image.java在运行时,我们使用tornado命令,实际上,它是java的别名,具有通过Java虚拟机(JVM)运行TornadoVM所需的所有类路径和标志。 但是,在使用TornadoVM运行之前,让我们检查一下机器中可用的并行和异构硬件。 我们可以通过使用TornadoVM SDK中的以下命令来查询:
$ tornadoDeviceInfo
Number of Tornado drivers: 1
Total number of devices : 4
Tornado device=0:0
NVIDIA CUDA -- GeForce GTX 1050
Tornado device=0:1
Intel(R) OpenCL -- Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
Tornado device=0:2
AMD Accelerated Parallel Processing -- Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
Tornado device=0:3
Intel(R) OpenCL HD Graphics -- Intel(R) Gen9 HD Graphics NEO在这台笔记本电脑上,我们具有NVIDIA 1050 GPU,Intel CPU和Intel Integrated Graphics(Dell XPS 15'',2018)。 如图所示,所有这些设备均与OpenCL兼容,并且所有驱动程序均已安装。 因此,TornadoVM可以考虑所有可用于执行的设备。 请注意,在这台笔记本电脑上,我们有两台针对Intel CPU的设备,一台使用Intel OpenCL驱动程序,另一台使用AMD OpenCL驱动程序用于CPU。 如果未指定任何设备,TornadoVM将使用默认值一(0:0)。 要使用TornadoVM运行我们的应用程序,我们只需键入:
$ tornado Image
为了发现我们的程序在哪台设备上运行,我们可以使用-debug标志通过TornadoVM查询基本调试信息,如下所示:
$ tornado --debug Image
task info: s0.t0
platform : NVIDIA CUDA
device : GeForce GTX 1050 CL_DEVICE_TYPE_GPU (available)
dims : 2
global work offset: [0, 0]
global work size : [3456, 4608]
local work size : [864, 768]这意味着我们使用了NVIDIA 1050 GPU(笔记本电脑中可用的GPU)来运行此Java程序。 下面发生的是,TornadoVM在运行时将Java方法grayScale编译到OpenCL中,并使用可用的OpenCL支持的设备运行它。 在这种情况下,在NVIDIA GPU上。 调试模式下的其他信息包括运行了多少线程以及它们的块大小(本地工作大小)。 这由TornadoVM运行时自动确定,并且取决于应用程序的输入大小。 在我们的例子中,我们使用了3456×4608像素的输入图像。
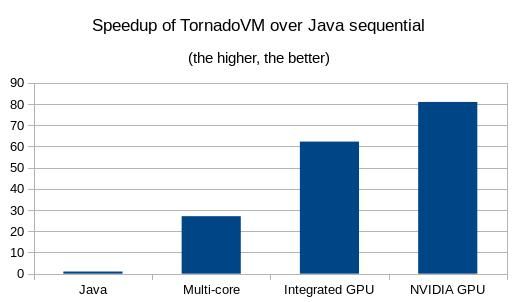
到目前为止,我们设法使Java程序在GPU上自动透明地运行。 这很棒,但是性能呢? 我们在测试台笔记本电脑上使用的是Intel CPU i7-7700HQ。 使用此输入图像运行顺序代码所花费的时间为1.32秒。 在GTX 1050 NVIDIA GPU上,它需要0.017秒。 处理相同图像的速度提高了81倍 。
还请参见: Jakarta EE 8:过去,现在和未来
我们还可以通过传递标志-D
例如,以下代码片段显示了如何运行TornadoVM以使用英特尔集成GPU:
$ tornado --debug -Ds0.t0.device=0:3 Image
task info: s0.t0
platform : Intel(R) OpenCL HD Graphics
device : Intel(R) Gen9 HD Graphics NEO CL_DEVICE_TYPE_GPU (available)
dims : 2
global work offset: [0, 0]
global work size : [3456, 4608]
local work size : [216, 256]通过在所有设备上运行,我们得到以下加速图。 第一栏显示的是在多核(4核)CPU上运行的基准(使用Java顺序代码且无加速运行),而第二栏显示了TornadoVM相对于基准的加速。 最后的条对应于集成GPU和专用GPU上的加速。 通过使用TornadoVM运行此应用程序,我们可以在Java序列上获得多达81倍的性能提升(NVIDIA GPU),并且通过在Intel集成显卡上运行可以达到62倍的性能提升。 请注意,在多核配置中,TornadoVM是超线性的(在4核CPU上是27x)。 这是因为生成的OpenCL C代码可以利用CPU上的矢量指令,例如每个内核可用的AVX和SSE寄存器。
用例
上一节显示了一个简单应用的示例,其中加速了摄影中非常常见的滤镜。 但是,TornadoVM的功能超出了简单程序的范围。 例如,TornadoVM当前可以加速机器学习和深度学习应用程序,计算机视觉,物理模拟和财务应用程序。
TornadoVM已用于在纯Java的 GPU上加速复杂的计算机视觉应用程序( Kinect Fusion ),该GPU包含约7k行Java代码。 该应用程序使用Microsoft Kinect摄像机记录一个房间,目标是实时进行3D空间重建。 为了获得实时性能,必须以至少每秒30帧(fps)的速度渲染房间。 原始Java版本可达到1.7 fps,而运行在GTX 1050 NVIDIA GPU上的TornadoVM版本可达到90 fps。 Kinect Fusion应用程序的TornadoVM版本是开源的,可在Github上使用 。

Exus Ltd.是一家总部位于伦敦的公司,目前正在通过提供患者住院再住院的预测来改善英国NHS系统。 为此,Exus一直在对患者的数据进行关联,这些数据包含其个人资料,特征和医疗状况。 用于预测的算法是一种典型的逻辑回归,具有数百万个元素作为数据集。 到目前为止,Exus已通过TornadoVM将100K患者的算法训练阶段从70秒(纯Java应用程序)缩短到仅7秒(性能提高了10倍)。 此外,他们还证明,通过使用200万患者的数据集,TornadoVM的执行效率提高了14倍。
我们还尝试了通常用于物理模拟和信号处理的综合基准和计算,例如NBody和DFT 。 在这些情况下,我们使用NVIDIA GP100 GPU(Pascal微体系结构)的速度提高了4500倍,而使用Intel Nallatech 385a FPGA的速度提高了240倍。 这些类型的应用程序需要大量计算,而瓶颈是内核处理时间。 因此,拥有专门用于这些类型的计算的功率并行设备有助于提高整体性能。
TornadoVM的现在和未来
TornadoVM当前是曼彻斯特大学的一项研究项目。 此外,TornadoVM是欧洲Horizon 2020 E2Data项目的一部分,该项目将TornadoVM与Apache Flink(用于批处理和流数据处理的Java框架)集成在一起,以加快异构和分布式内存集群上典型的映射减少操作。
TornadoVM当前支持在多种设备上进行编译和执行,包括Intel和AMD CPU,NVIDIA和AMD GPU以及Intel FPGA。 我们正在进行一项工作,以也支持Xilinx FPGA。 通过此选项,我们旨在涵盖所有当前的云提供商产品。此外,我们正在集成更多的编译器和运行时优化,例如使用设备内存层和使用虚拟共享内存,以减少总执行时间并增加总体性能。
摘要
在本文中,我们讨论了TornadoVM,它是OpenJDK的插件,用于加速异构设备上的Java程序。 首先,我们描述了TornadoVM如何在异构硬件(例如GPU)上编译和执行代码。 然后,我们提供了一个在不同设备上编程和运行TornadoVM的示例,其中包括多核CPU,集成GPU和专用NVIDIA GPU。 最后,我们证明了使用TornadoVM,开发人员可以在保持应用程序完全不依赖硬件的情况下实现高性能。 我们相信,TornadoVM提供了一种有趣的方法,其中要添加的代码易于读取和维护,同时,如果系统中具有并行硬件,则可以提供高性能。
有关TornadoVM技术方面的更多信息,可以在下面找到:
参考资料
Juan Fumero,Michail Papadimitriou,Foivos S.Zakkak,Maria Xekalaki,James Clarkson和Christos Kotselidis。 2019。异构硬件上的动态应用程序重新配置。 在第15届ACM SIGPLAN / SIGOPS虚拟执行环境国际会议论文集 (VEE 2019)中。 美国纽约州ACM,电话:165-178。 DOI: https : //doi.org/10.1145/3313808.3313819
Juan Fumero和Christos Kotselidis。 2018年。使用编译器片段在异构硬件上利用并行性:Java简化案例研究。 在第十届ACM SIGPLAN虚拟机和中间语言国际研讨会 (VMIL 2018)的会议记录中。 美国纽约州纽约市,ACM,16-25。 DOI: https : //doi.org/10.1145/3281287.3281292
詹姆斯·克拉克森(James Clarkson),胡安·富莫罗(Juan Fumero),米歇尔·帕帕第米特里(Michail Papadimitriou),福伊沃斯·S·扎卡克(Foivos S. 2018年。使用Graal为Java程序开发高性能的异构硬件。 在第15届国际托管语言和运行时会议论文集 (ManLang '18)中。 ACM,美国纽约,纽约,第4条,共13页。 DOI: https : //doi.org/10.1145/3237009.3237016
与Juan Fumero的TornadoVM。 https://www.youtube.com/watch?v=nPlacnadR6k
Christos Kotselidis,James Clarkson,Andrey Rodchenko,Andy Nisbet,John Mawer和MikelLuján。 2017。异构托管运行时系统:计算机视觉案例研究。 SIGPLAN不是。 52,7(2017年4月),74-82。 DOI: https : //doi.org/10.1145/3140607.3050764
致谢
这项工作得到了欧盟Horizon 2020 E2Data 780245和ACTiCLOUD 732366资助的部分支持。 特别感谢Exus的Gerald Mema报告了NHS用例。
翻译自: https://jaxenter.com/tornado-vm-java-162460.html
java 异构类型