Python PySpark 大数据的瑞士军刀
本篇文章主要涉及的知识点有:
- Hadoop及其生态系统:了解Hadoop的由来以及Hadoop生态系统。
- Spark的核心概念:掌握Spark的基本概念和架构。
- Spark基本操作:了解Spark的几种常见操作。
- SQL in Spark概述:了解Spark相关数据统计可以用SQL来操作。
- Spark与机器学习:了解Spark MLlib库种的几种机器学习算法。
Part 1 Hadoop与生态系统
Hadoop不是一个简单的工具,它有自己的生态体系。
Part 1.1 Hadoop概述
Hadoop是一个开源的大数据软件框架,主要用于分布式数据存储和大数据集处理。Hadoop在大数据领域使用广泛,其中一个重要的原因是开源,这就意味着使用Hadoop的成本很低,软件本身是免费的。另一方面,还可以研究其内部的实现原理,并根据自身的业务需求,进行代码层面的定制。
Hadoop可以在具有数千个节点的分布式系统上稳定运行。它的分布式文件系统不但提供了节点间进行数据快速传输的能力,还允许系统在个别节点出现故障时,保证整个系统可以继续运行。
注意:一般来说,在非高可用架构下,如果Hadoop集群种的NameNode节点出现故障,那么整个Hadoop系统将无法提供服务。
一般来说,Hadoop的定义有侠义和广义之分。从狭义上来说,Hadoop就是单独指代Hadoop这个软件。而从广义上来说,Hadoop指代大数据的一个生态圈,包括很多其他的大数据软件,比如HBase、Hive、Spark、Sqoop和Flumn等。
我们一般所说的Hadoop,指的是Hadoop这个软件,即狭义的概念。当提到Hadoop生态系统或者生态圈的时候,往往指的是广义的Hadoop概念。
注意:目前而言,Hadoop主要有三个发行版本:Apache Hadoop、Cloudera版本(简称CDH)和Hortonworks版本(简称HDP)。
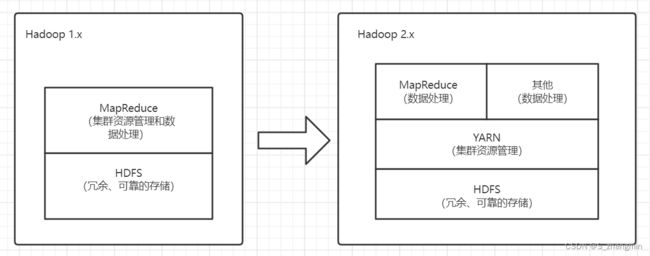
Hadoop1.x主要由HDFS(Hadoop Distributed File System)和MapReduce两个组件组成,其中MapReduce组件除了负责数据处理外,还负责集群的资源管理。而Hadoop2.x由HDFS、MapReduce和YARN三个组件组成,MapReduce只负责数据处理,且运行在YARN之上,YARN负责集群资源调度。这样单独分离出来的YARN组件还可以作为其他数据处理框架的集群资源管理。
Hadoop2.x的主要组件说明如下:
- HDFS:分布式文件系统,提供对应用程序数据的高吞吐量、高伸缩性、高容错性的访问。它是Hadoop体系中数据存储管理的基础,也是一个高度容错的系统,能检测和应对硬件故障,可在低配置的硬件上运行。
- YARN:用于任务调度和集群资源管理
- MapReduce:基于YARN的大型数据集并行处理系统,是一种分布式计算模型,用于进行大数据量的分布式计算。
相对于之前的主要发布版本Hadoop2.x,Apache Hadoop3.x整合许多重要的增强功能。Hadoop3.x是一个可用版本,提供了稳定性和高质量的API,可以用于实际的产品开发。
- 最低Java版本变为JDK1.8:所有Hadoop的jar都是基于JDK1.8进行编译的。
- HDFS支持纠删码(erasure coding)是一种比副本存储更节省存储空间的数据持久化存储方法。
- YARN时间线服务增强:提高时间线服务的可扩展性、可靠性。
- 重写Shell脚本:修补了许多长期存在的bug,并增加了一些新的特性。
- 覆盖客户端的jar:将Hadoop的依赖隔离在单一jar包中,从而达到避免依赖渗透到应用程序的类路径中的问题,避免包冲突。
- MapReduce任务级本地优化:添加了映射输出收集器的本地化实现的支持、可以带来30%的性能提升。
- 支持2个以上的NameNode:通过多个NameNode来提供更高的容错性。
- 数据节点内置平衡器。
- YARN增强:YARN资源模型已经被一般化,可以支持用户自定义的可计算资源类型而不仅仅是CPU和内存。
前面对Hadoop进行了简要的介绍,再介绍学习Hadoop解决了大数据什么问题。
Part 1.1.1 大数据存储
首先,大数据要解决的问题是如何方便地存取海量的数据,而Hadoop的HDFS组件可以解决这个问题。HDFS以分布式方式存储数据,并将每个文件存储为块(block)。块是文件系统中最小的数据单元。
假设有一个512MB大小的文件需要存储,由于HDFS默认创建数据块大小是128MB,因此HDFS将文件数据分为4个块(512/128=4),并将其存储在不同的数据节点上。同时为了保证可靠性,还会复制块数据到不同数据节点上。因此,Hadoop拆分数据的模式,可以胜任大数据的分布式存储。
Part 1.1.2 可扩展性
其次,大数据需要解决的问题就是需要进行资源扩展,比如通过增强服务器节点来提升存储空间和计算资源。Hadoop采取主从架构,支持横向扩展的方式来扩展资源,当存储空间或者计算资源不够的情况下,用户可以向HDFS集群中添加额外的数据节点(服务器)来解决。
Part 1.1.3 存储各种数据
再次,大数据需要解决存储克重数据的问题,大数据系统中很大一部分都是非结构化数据,结构化的数据可能只占很少的比例。HDFS可以存储所有类型的数据,包括结构化、半结构化和非结构化数据。Hadoop适合一次写入、多次读取的业务场景。
Part 1.1.4 数据处理问题
大数据还有一个重要的问题就是如何对数据进行分布式计算。一般来说,传统的应用程序都是拉取数据,应用程序是固定的,将需要处理的数据从存储的地方移动到计算程序所在的计算机上,即移动数据。
大数据计算往往需要处理的数据量非常大,而程序一般一般比较小,因此在这种情况下,更好的解决方法是移动程序到各个数据节点上。Hadoop就是将计算移到数据节点上,而不是将数据移到计算程序所在的节点上。
Hadoop的主要优势如下:
- 可扩展性:通过添加数据节点,可以扩展系统以处理更多数据。
- 灵活性:可以存储任意多的数据,且数据支持各种类型。
- 低成本:开源免费,且可以运行在低廉的硬件上。
- 容错机制:如果某个数据节点宕机,则作业将自动重定向到其他节点。
- 计算能力:数据节点越多,处理数据的能力就越强。
Hadoop的缺点如下:
- 安全问题:Hadoop数据没有加密,因此如果数据需要在互联网上传播,则存在数据泄露的风险。
- 小文件问题:Hadoop缺乏有效支持随机读取小文件的能力,因此不适合小文件的存储。
注意:在生产环境中,Hadoop在选择版本时,应该优先选择最新的稳定版本。
Part 1.2 HDFS体系结构
HDFS支持跨多台服务器进行数据存储,且数据会自动复制到不同的数据节点上,以防止数据丢失。HDFS采用主从(Master/Slave)架构。
一般来说,一个HDFS集群是由一个NameNode节点(主节点)和多个DataNode节点(从节点)组成。其中,NameNode是一个中心服务器,负责管理文件系统的各种元数据(Metadata)和客户端对文件的访问。DataNode在集群中一般负责管理节点上的数据读取和计算。
- NameNode:存储文件系统的原数据,即文件名、文件块信息、块位置、权限等,也管理数据节点。
- DataNode:存储实际业务数据(文件块)的从节点,根据NameNode指令为客户端读/写请求提供服务。
NameNode负责管理block的复制,它周期性地接收HDFS集群中所有DataNode的心跳数据包(heartbeats)和block报告。心跳包表示DataNode正常工作,block报告描述了该DataNode上所有的block组成的列表 ,并根据需要更新NameNode上的状态信息。
当文件读取时,客户端向NameNode节点发起文件读取的请求。NameNode返回文件存储的block块信息及其block块所在DataNode的信息。客户端根据这些信息,即可到具体的DataNode上进行文件读取。
由于数据流分散在HDFS集群中的所有DataNode节点上,且NameNode只响应块位置的请求(存储在内存中,速度很快),而无须响应数据请求,所以这种设计能适应大量的并发访问。
当文件写入时,客户端向NameNode节点发起文件写入的请求。NameNode根据文件大小和文件块配置的情况,返回给客户端它所管理部分DataNode的信息。客户端将文件划分多个block块,并根据DataNode的地址信息,按顺序写入到每一个DataNode块中。HDFS的文件默认规则是一次写,多次读,并且严格要求在任何时候只有一个写操作(writer)。
注意:除了最后一个block,所有的block大小都是一样的(128MB)。当一个1MB的文件存储在一个128MB的block中时,文件只使用1MB的磁盘空间,而不是128MB。
备份数据的存放是HDFS可靠性和性能的关键。HDFS采用一种称为Rack-Aware的策略来决定备份数据的存放。通过Rack Awareness过程,NameNode给每个DataNode分配RackID。比如,DataNode1属于Rack1,DataNode4属于Rack2.
HDFS默认情况下,一个block会有3个备份,一个在NameNode指定的DataNode上(假如是Rack1下的DataNode1),一个在指定DataNode非同一个Rack的DataNode上(假如是Rack2下的DataNode4)。这种策略综合考虑了同一个Rack失效,以及不同Rack之间数据复制的性能问题。
在读取副本数据时,为了降低带宽消耗和读取延时,HDFS会尽量读取最近的副本。如果在同一个Rack上有一个副本,那么就读该副本。
注意:Hadoop服务器启动后先进入安全模式,此时系统中的内容不允许修改和删除,直到安全模式结束。
Part 1.3 Hadoop生态系统
Hadoop可以说是奠定了大数据开源方案的基础,因此,不少大数据工具都被纳入Hadoop生态系统。随着Hadoop与各种各样的Apache开源大数据项目的融合,Hadoop生态系统也在不断地变化 。
Hadoop正在不断地将其核心组件HDFS和YARN扩展为一个更为复杂的开源大数据系统,也就是Hadoop生态系统。

Hadoop生态系统图
- Hadoop HDFS
HDFS是一个容错、分布式、水平可扩展的存储系统,可跨多个服务器工作。它可以用作Hadoop集群的一个部分,也可以用作独立的通用文件系统,它是很多大数据工具的默认数据存储系统起到非常重要的作用。
另外,Hadoop是开源的,这意味着一个组织可以运行这个文件系统来处理PB级别的数据,而无须支付软件成本。
- Hadoop MapReduce
MapReduce是一个分布式编程框架,它可以并行方式处理TB级别的数据。因此非常适合处理离线的数据,而且非常稳定。
- Flume
Flume是一个分布式的海量日志采集、聚合和传输的系统,它支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume提供对数据进行简单处理,并具有写入各种数据存储系统的能力。
- Sqoop
Sqoop支持HDFS、Hive、HBase与关系型数据库之间的批量数据双向传输(导入/导出)。与Flume不同,Sqoop在结构化数据的传输上操作更加方便。
- Pig
Pig是一个基于Hadoop的大数据分析平台,它提供的SQL-like语言叫Pig Latin(其实并不好用),该语言的编译器会把类SQL的数据分析请求,转换为一系列经过优化处理的MapReduce运算。Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口。
- Mahout
Mahout是在MapReduce之上实现的一套可扩展的机器学习库。不过当前随着Spark和Flink等软件的流行,Mahout逐步被其他机器学习库所替代。
- Hive
Hive是一个SQL翻译器,可以基于类似SQL语言的HiveQL来编写查询。Hive可以将HDFS和HBase中的数据集映射到表上。虽然Hive对于一些复杂SQL还不能很好地支持,但是常用的数据查询任务基本都可以用SQL来解决,这让开发人员只需要用SQL就可以完成MapReduce作业。
- HBase
HBase是一个NoSQL分布式的面向列的数据库,它运行在HDFS之上,可以对HDFS执行随机读/写操作,它是Google Big Table的开源实现。HBase能够近实时地存储和检索随机数据。这就很好地弥补了Hadoop在实时应用上的不足。
- ZooKeeper
ZooKeeper是一个开源的分布式应用程序协调服务,是Google Chubby的一个开源实现。它是一个分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步和组服务等。
- Spark
Spark是专为大规模数据处理而设计的、快速的通用计算引擎。他目前已经可以对大数据中的批处理和流处理进行处理,且Spark计算速度比Hadoop MapReduce要更快。
- Drill
Drill是一个用于Hadoop和NoSQL数据库的低延迟SQL查询引擎,它支持Parquet、JSON或XML等数据格式。Drill响应速度可达到亚秒级,适合交互式数据分析。
- Apache Superset
Superset是一个开源的可视化工具,可以接入多种数据源。开发人员或者业务人员可以借助它快速构建出美观的管理面板。
Part 2 Spark与Hadoop
在当前的大数据领域,Apache Spark无疑是占有重要位置。在Spark出现之前,想要在一个组织内同时完成多种大数据分析任务,必须部署多套大数据工具,比如离线分析用Hadoop MapReduce,查询数据用Hive,流数据处理用Storm,而机器学习用Mahout。
在这种情况下,一方面增加了大数据系统开发的难度,需要不同技能的人员共同写作才能完成,这也会导致系统的运维变得复杂。另一方面,由于不同大数据工具之间需要互相传递数据,而对于数据的格式可能要求不同,因此需要在多个系统间进行数据格式转换和传输工作,这个过程费时费力。
Spark软件是一个“One Stack to rule them all”的大数据计算框架,它的目标是用一个技术栈完美地解决大数据领域的各种计算任务。Spark官方对Spark的定义是:通用的大数据快速处理引擎。
从某种程度上来说,Spark和Hadoop软件的组合,是未来大数据领域性价比最高的组合,也是最有发展前景的组合。
Part 2.1 Apache Spark概述
2009年,Spark诞生于伯克利大学的AMPLab实验室,AMP是Algorithms、Machines与People的缩写。一开始Spark只是一个学术上的实验性项目,代码量并不多,可以称得上是一个轻量级的框架。
2010年,伯克利大学正式开源了Spark项目。2013年,Spark成为Apache基金会下的项目,进入高速发展期。
2014年,Spark仅一年左右的时间,就以非常快的速度成为Apache的顶级项目。Spark用Spark RDD、Spark SQL、Spark Streaming、Spark MLlib和Spark GraphX成功解决了大数据领域中,离线批处理、交互式查询、实时流计算、机器学习与图计算等最常见的计算问题。
Part 2.2 Spark和Hadoop比较
1. 实现语言不同
Apache Spark框架是用Scala语言编写。Scala是一门多范式(Multi-Paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。Scala运行在Java虚拟机上,并兼容现有的Java程序。Scala源代码被编译成Java字节码,所以它可以运行在JVM之上并可以调用现有的Java类库。
用Hadoop是由Java语言开发的。Java是一门面向对象的编程语言,具有功能强大和简单易用的特征。Java具有简单性、面向对象、分布式、健壮性、安全性、平台独立与可移植性、多线程等特点。可以说,作为一个大数据从业人员,Java语言几乎是必会的一门语言。
2. 数据计算方式不同
Apache Spark最重要的特点是基于内存进行计算,因此计算的速度可以达到Hadoop MapReduce或Hive的数十倍,甚至上百倍。很多应用程序,为了提升程序的响应速度,常用的方法就是将数据在内存中进行缓存。一般来说,Apache Spark对计算机的内存要求比较高。
通常来说,Apache Spark中RDD存放在内存中,如果内存不够存放数据,会同时使用磁盘存储数据。因此,为了提升Spark对数据的计算速度,应该尽可能让计算机的内存足够大,这样可以防止数据缓存到磁盘上。
而Hadoop MapReduce是从HDFS中读取数据的,通过MapReduce将中间结果写HDFS,然后再重新从HDFS读取数据进行MapReduce操作,再回写到HDFS中,这个过程设计多次磁盘IO操作,因此,计算速度相对来说比较慢。
3. 使用场景不同
Apache Spark只是一个计算分析框架,虽然可以在一套软件栈内完成各种大数据分析任务,但是它并没有提供分布式文件系统,因此必须和其他的分布式文件系统进行继承才能运作。
Spark是专门用来对分布式数据进行计算处理,它本身不能存储数据。可以说,Spark是大数据处理的瑞士军刀,支持多种类型的数据文件,如果HDFS、HBase和各种关系型数据库可以同时支持批处理和流数据处理。
而Hadoop主要由HDFS、MapReduce和YARN构成。其中HDFS作为分布式数据存储,这也是离线数据存储的不二选择。另外,借助MapReduce可以很好地进行离线数据批处理,而且非常稳定,对于实时性要求不高的批处理任务,用MapReduce也是一个不做的选择。
4. 实现原理不同
在Apache Spark中,用户提交的任务称为Application,一个Application对应一个SparkContext。一个Application中存在多个Job,每触发一次Action操作就会产生一个Job。这些Job可以并行或串行执行,每一个Job中有多个Stage,每一个Stage里面有多个Task,由TaskScheduler分发到各个Executor中执行。Executor的生命周期和Application一样,即使没有Job运行也是存在的,所以Task可以快速启动读取内存进行计算。
另外,在Spark中每一个Job可以包含多个RDD转换算子,在调度时可以生成多个Stage,借助Spark狂剑中提供的转换算子和RDD操作算子,可以实现很多复杂的数据计算操作,而这些复杂的操作在Hadoop中原生是不支持的。
在Hadoop中,一个作业称为一个Job,Job里面分为Map Task和Reduce Task,每个Task 都在自己的进程中运行,当Task结束时,进程也会随之结束。
注意: Spark 虽然号称是通用的大数据快速处理引擎,但是目前还不能替换Hadoop,因为Spark并没有提供分布式文件系统。
Part 3 Spark核心概念
Part 3.1 Spark软件栈
Apache Spark是一个快速通用的分布式计算平台,Spark支持更多的计算模式,包括交互式查询和流数据处理。在处理大规模数据集时,Spark的一个核心优势是内存计算,因而处理速度更快。
Spark在统一的框架下,一站式提供批处理、迭代计算、交互式查询、六数据处理、资源调度、机器学习以及图计算。Spark支持多种编程语言,包括Scala、Java、Python和R等。
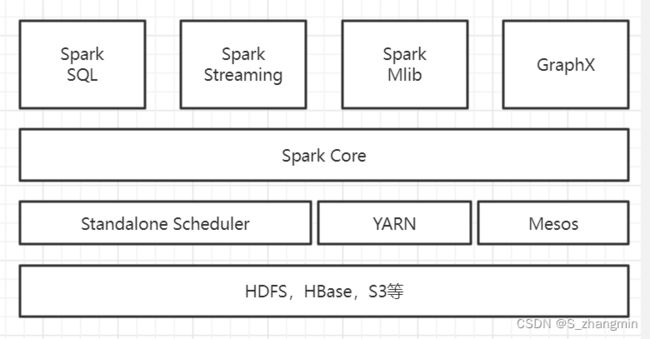
Spark的软件栈架构图
Spark软件栈核心组件如下:
- Spark Core:Spark Core包含Spark的基本功能,包含任务调度、内存管理和容错机制等,内部定义了RDD(弹性分布式数据集),提供了很多API来创建和操作这些RDD,为其他组件提供底层的服务。
- Spark SQL:Spark SQL可以处理结构化数据的查询分析,对于HDFS、HBase等多种数据源中的数据,可以用Spark SQL来进行数据分析。
- Spark Streaming:Spark Streaming是实时数据流处理组件,类似Storm。Spark Streaming提供了API来操作实时流数据。一般需要配合消息队列Kafka,来接收数据做实时统计分析。
- Spark Mllib:Mllib是一个包含通用机器学习功能的包,是Machine Learning Lib的缩写,主要包含分类、聚类和回归等算法,还包括模型评估和数据导入。MLlib提供的机器学习算法库,支持集群上的横向扩展。
- Spark GraphX:GraphX是专门处理图的库,如社交网络图的计算。与Spark Streaming和Spark SQL一样,也提供了RDD API。它提供了各种图的操作和常用的图算法。
Spark提供了一站式的软件栈,因此只要掌握Spark这一个工具,就可以编写不同场景的大数据处理应用程序。
Part 3.2 Spark 运行架构

-- end