TYWZOJ 外星猫 题解
题目描述
VHOS 养了一只从外星来的猫,这只猫的基因由三种字符组成:'![]() ','
','![]() ','
','![]() '。
'。
但这只猫会疯狂进化,每过一个单位时间,这只猫的基因都会复制一遍,并在原基因和复制出来的基因中加入 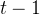 个 '
个 '![]() ' ,组成新基因。
' ,组成新基因。
当  时,它的基因为 "
时,它的基因为 "![]() "。
"。
当  时,它的基因为 "
时,它的基因为 "![]() "。
"。
当 ![]() 时,它的基因为 "
时,它的基因为 "![]() "。
"。
VHOS 想知道在这只猫的第  位的基因是什么,什么时候出现了这位基因。
位的基因是什么,什么时候出现了这位基因。
输入格式
第一行一个数 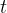 ,表示问题个数;第
,表示问题个数;第 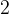 到
到  行,每行一个整数 。
行,每行一个整数 。
输出格式
行,每行第一个为字符,表示这只猫的第 位的基因;第二个为一个整数,表示出现这位基因的时间。
思路及部分实现
为了方便叙述,我们首先思考第二个问题:出现第 位基因的时间是什么?
最简单的思路是,假设基因的长度变化是有规律性的,那么当按照这个规律往后枚举出每一个单位时间基因的长度,如果这个长度已经大于等于 ,显然第 位基因就是在这个单位时间里出现的。注意一定是第一个大于等于 的长度!
有了大体思路,接下来就是找规律了,根据题目描述中已经给出的基因变化规律(即每一个单位时间的基因就是复制出两份上一个单位时间的基因,然后在中间插入 个 '![]() ')可以发现此时的基因长度就等于上一个单位时间的基因长度乘二再加 (的含义见题目描述),举个例子来帮助理解:
')可以发现此时的基因长度就等于上一个单位时间的基因长度乘二再加 (的含义见题目描述),举个例子来帮助理解:
t=1: cat
len=3
t=2: cat a cat
len=3*2+1=7
t=3: catacat aa catacat
len=7*2+1=15
t=4: catacataacatacat aaa catacataacatacat
len=15*2+1=31
t=5: catacataacatacataaacatacataacatacat aaaa catacataacatacataaacatacataacatacat
len=31*2+1=63下面是代码实现:
int len=3,pos=0;
//第一个时间单位的基因长度要直接赋值
//pos记录循环结束时枚举到的单位时间
for(int i=2;i;i++){
if(len>=x){
pos=i;
break;
}
len=len+len+i-1;
} 接着解决第一个问题: 这只猫的第 位的基因是什么?
很容易想到,可以在刚才求解第二个问题时所用的循环中用一个 ![]() 类型的字符串储存每一个单位时间的基因。代码实现如下:
类型的字符串储存每一个单位时间的基因。代码实现如下:
int len=3,pos=0;
string cat="cat",k="a";
for(int i=2;i;i++){
if(len>=x){
pos=i;
break;
}
len=len+len+i-1;
cat=cat+k+cat,k+="a";
}
printf("%c %d",cat[x-1],pos-1);
//由于字符串从0开始计数,所以输出时下标要-1 但仔细看看题目给出的数据范围 ![]() 且
且 ![]() ,那么字符串里最多会存
,那么字符串里最多会存 ![]() 个字符,显然出题人很容易把这种方法卡掉。(亲测只能拿
个字符,显然出题人很容易把这种方法卡掉。(亲测只能拿 ![]() 分,后面五个测试点全部超内存)储存的方法不行,也就意味着这一问依然要找规律解决。
分,后面五个测试点全部超内存)储存的方法不行,也就意味着这一问依然要找规律解决。
我们还是看前面发现的规律:每一个单位时间的基因就是复制出两份上一个单位时间的基因,然后在中间插入 个 '![]() '。也就是说 个时间单位后的基因是由两份 个时间单位后的基因与 个 '
'。也就是说 个时间单位后的基因是由两份 个时间单位后的基因与 个 '![]() ' 组成的,而 个时间单位后的基因是由两份
' 组成的,而 个时间单位后的基因是由两份 ![]() 个时间单位后的基因与
个时间单位后的基因与 ![]() 个 '
个 '![]() ' 组成的
' 组成的 ![]() 以此类推,直到 时,只需判断题目所问的是三个字符中的哪一个就好了。所以我们考虑每次操作时将基因长度分为左右两部分,如果此时枚举到的部分长度只剩
以此类推,直到 时,只需判断题目所问的是三个字符中的哪一个就好了。所以我们考虑每次操作时将基因长度分为左右两部分,如果此时枚举到的部分长度只剩  了,就进行上述判断然后输出;否则继续分两半,由于基因的第一部分与第三部分一定相同,所以我们对于左右两部分的下一步分半操作相同,不需要分开处理。
了,就进行上述判断然后输出;否则继续分两半,由于基因的第一部分与第三部分一定相同,所以我们对于左右两部分的下一步分半操作相同,不需要分开处理。
但还有一种情况,那就是题目所问的可能是在中间插入的中间多个 '![]() '中,对于这种情况我们只需在将基因左右分两半时把中间多个 '
'中,对于这种情况我们只需在将基因左右分两半时把中间多个 '![]() ' 的部分划到左半部分或右半部分,然后在进行下一步前判断此时枚举到的部分右边界所在位置是否大于
' 的部分划到左半部分或右半部分,然后在进行下一步前判断此时枚举到的部分右边界所在位置是否大于  就可以解决。
就可以解决。
对于代码实现,笔者首先想到的是二分,毕竟操作都是分为左右两部分,但由于考虑到第二种情况需要把中间多个 '![]() ' 的部分划到左半部分或右半部分,二分实现会变得更为复杂,所以最后笔者决定使用递归实现。代码实现如下:
' 的部分划到左半部分或右半部分,二分实现会变得更为复杂,所以最后笔者决定使用递归实现。代码实现如下:
void search(ll k){
//k是此时搜索到的部分的长度
//用char类型的ans储存最终答案
//如果搜到了答案就将flag标记为true,当开始时如果flag为true,那么就没必要继续搜索了
if(flag==true) return ;
if(k<=3){
if(k==1) ans='c';
else if(k==2) ans='a';
else ans='t';
flag=true;
return ;
}
int l=0;
while(k>a[++l]);l--;
if(a[l]+l>=k){
//对第二种情况的特判
ans='a';
flag=true;
}
else search(k-a[l]-l);
} 可能有人会对  产生疑问,那是对每个单位时间的基因长度做的打表。由于
产生疑问,那是对每个单位时间的基因长度做的打表。由于 ![]() 而
而 ![]() ,所以打表只需写
,所以打表只需写 ![]() 个数。( 数组不开
个数。( 数组不开 ![]()
![]() 会编译错误)
会编译错误)
long long a[28]={0,3,7,16,35,74,153,312,631,1270,2549,5108,10227,
20466,40945,81904,163823,327662,655341,1310700,2621419,5242858,
10485737,20971496,41943015,83886054,167772133,33554429215};完整代码
#include
using namespace std;
typedef long long ll;
char ans;bool flag;
ll a[28]={0,3,7,16,35,74,153,312,631,1270,2549,5108,10227,
20466,40945,81904,163823,327662,655341,1310700,2621419,5242858,
10485737,20971496,41943015,83886054,167772133,33554429215};
void search(ll k){
if(flag==true) return ;
if(k<=3){
if(k==1) ans='c';
else if(k==2) ans='a';
else ans='t';
flag=true;
return ;
}
int l=0;
while(k>a[++l]);
//寻找k处于哪个单位时间
l--;
if(a[l]+l>=k){
//如果此时枚举到的部分右边界所在位置是否大于 x那么就是第二种情况
ans='a';
flag=true;
}else search(k-a[l]-l);
//否则继续搜索右半部分,把左半部分的长度减去
}
int main()
{
int t;scanf("%d",&t);
while(t--){
int l=0;ll x;
scanf("%lld",&x);
//flag不要忘记初始化
flag=false,search(x);
while(a[++l] -------------------------------------------------------请-------------------勿-------------------抄-------------------袭-------------------------------------------------------