Mysql5.7表分区技术
目录
一、快速开始demo
二、查看某表分区情况
2.1 使用SHOW CREATE TABLE语句
2.2 使用INFORMATION_SCHEMA.PARTITIONS表
三、查看某分区详细情况
3.1 快速查询所有分区
3.2 查询某一分区的所有行数据
四、操作分区
4.1 新增分区
4.1.1 建表时创建分区
4.1.2 已有表创建分区
4.2 删除分区
4.3 合并分区
五、概念
5.1 MySQL表分区释义
5.2 MySQL表分区的分区类型
5.2.1 范围分区(Range Partitioning)
5.2.2 列表分区(List Partitioning)
5.2.3 哈希分区(Hash Partitioning)
5.2.4 键分区(Key Partitioning)
六、架构角度看表横向扩展和Mysql表分区
一、快速开始demo
1、创建表:使用CREATE TABLE语句创建主表结构,指定分区类型、分区键、分区定义。例如:
CREATE TABLE my_partitioned_table ( id INT, -- INT类型长度不写默认为11,VARCHAR类型长度必须写 name VARCHAR(50), created_date DATE ) ENGINE = INNODB CHARSET = utf8 -- 建表时要指定引擎和字符集,否则表默认引擎可能是MyISAM,导致分区的引擎也是MyISAM PARTITION BY RANGE (YEAR(created_date)) ( PARTITION p0 VALUES LESS THAN (2010), PARTITION p1 VALUES LESS THAN (2020), PARTITION p2 VALUES LESS THAN (2030) );在上述示例中,使用了RANGE分区类型,并按照
created_date字段的年份进行分区。2、插入数据:向分区表中插入数据,MySQL会自动将数据分散到不同的分区中。例如:
INSERT INTO my_partitioned_table ( id, NAME, created_date ) VALUES ( 1, 'John', '2009-03-15' ), ( 2, 'lucy', '2020-03-15' ), ( 3, 'jack', '2021-03-15' );3、查询数据:可以像查询普通表一样查询分区表。MySQL会自动确定应该在哪个分区中查找数据,以提高查询性能。
4、管理分区:可以根据需求对分区进行管理,例如添加、删除或合并分区。例如,可以使用ALTER TABLE语句添加一个新的分区:
ALTER TABLE my_partitioned_table ADD PARTITION ( PARTITION p3 VALUES LESS THAN (2040) );注意上述中的YEAR(created_date),是分区键,用YEAR函数求created_date列的年份值。
SELECT DAY( '2022-11-24' );-- 结果: 24
SELECT YEAR( '2022-11-24' );-- 结果: 2022
SELECT YEAR_MONTH( '2022-11-24' );-- 结果: 报错,Mysql5.7版本不支持该函数
二、查看某表分区情况
2.1 使用SHOW CREATE TABLE语句
将
your_table_name替换为要查看的表名:SHOW CREATE TABLE your_table_name;执行后,获得一个结果集,其中包含表的创建语句。在创建语句中,可以找到有关分区的信息,包括分区类型、分区键、分区定义。
展开如下:
CREATE TABLE `my_partitioned_table` ( `id` int(11) DEFAULT NULL, `name` varchar(50) DEFAULT NULL, `created_date` date DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 /*!50100 PARTITION BY RANGE (YEAR(created_date)) (PARTITION p0 VALUES LESS THAN (2010) ENGINE = InnoDB, PARTITION p1 VALUES LESS THAN (2020) ENGINE = InnoDB, PARTITION p2 VALUES LESS THAN (2030) ENGINE = InnoDB, PARTITION p3 VALUES LESS THAN (2040) ENGINE = InnoDB) */上述创建语句中可以看出,INT类型长度默认是11,表分区的引擎就是表的引擎InnoDB。
分区类型是范围分区(Range Partitioning),使用
PARTITION BY RANGE语句指定了范围分区方式。分区键是
created_date列,即根据created_date列的值进行分区。分区定义如下:
PARTITION p0 VALUES LESS THAN (2010) ENGINE = InnoDB:定义了名为p0的分区,该分区包含所有created_date小于2010年的数据。PARTITION p1 VALUES LESS THAN (2020) ENGINE = InnoDB:定义了名为p1的分区,该分区包含所有created_date小于2020年的数据。PARTITION p2 VALUES LESS THAN (2030) ENGINE = InnoDB:定义了名为p2的分区,该分区包含所有created_date小于2030年的数据。PARTITION p3 VALUES LESS THAN (2040) ENGINE = InnoDB:定义了名为p3的分区,该分区包含所有created_date小于2040年的数据。每个分区都使用了
VALUES LESS THAN子句来定义分区的范围条件,指定了每个分区所包含的数据范围。分区定义中的
ENGINE = InnoDB指定了每个分区使用的存储引擎为InnoDB。注意,这里的存储引擎是针对每个分区而言的,而不是整个表的存储引擎。总之,上述创建语句,创建了一个名为
my_partitioned_table的表,使用了范围分区方式,根据created_date列的值将数据分为四个分区:p0、p1、p2和p3。每个分区根据VALUES LESS THAN子句定义了分区的范围条件,并使用InnoDB作为分区的存储引擎。

2.2 使用INFORMATION_SCHEMA.PARTITIONS表
将
your_table_name替换为要查看的表名:SELECT * FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'your_table_name';

三、查看某分区详细情况
3.1 快速查询所有分区
EXPLAIN SELECT * FROM my_partitioned_table;

3.2 查询某一分区的所有行数据
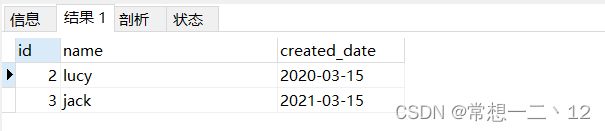
SELECT * FROM my_partitioned_table PARTITION (p2);
四、操作分区
4.1 新增分区
4.1.1 建表时创建分区
CREATE TABLE orders1 ( id BIGINT, creator VARCHAR(100), tenant_code BIGINT ) ENGINE = INNODB CHARSET = utf8 PARTITION BY LIST (tenant_code) ( PARTITION p1001 VALUES IN (1001), PARTITION p1002 VALUES IN (1002), PARTITION p1003 VALUES IN (1003), PARTITION pOther VALUES IN (1004, 1005) );ALTER TABLE orders1 ADD PARTITION ( PARTITION p1006 VALUES IN (1006) );
4.1.2 已有表创建分区
在MySQL中,没有直接在现有表上进行分区的操作。需要创建一个新的表,并将数据从旧表复制到新表中。
1、创建一个新的具有分区的表 "orders2",并定义所需的分区结构。
2、将数据从旧表 "orders1" 插入到新表 "orders2" 中。
3、删除旧表 "orders1"。
4、将新表 "orders2" 重命名为 "orders1"。
-- 创建新表 "orders2",带有分区结构 CREATE TABLE orders2 ( id BIGINT, creator VARCHAR(100), tenant_code BIGINT ) ENGINE = INNODB CHARSET = utf8 PARTITION BY LIST (tenant_code) ( PARTITION p1001 VALUES IN (1001), PARTITION p1002 VALUES IN (1002), PARTITION p1003 VALUES IN (1003), PARTITION pOther VALUES IN (1004, 1005) ); -- 将数据从旧表 "orders1" 插入到新表 "orders2" 中 INSERT INTO orders2 SELECT * FROM orders1; -- 重命名旧表 "orders1" 为 "orders1_old" RENAME TABLE orders1 TO orders1_old; -- 重命名新表 "orders2" 为 "orders1" RENAME TABLE orders2 TO orders1;在执行这些操作之前,必须备份数据,以防发生意外情况。
4.2 删除分区
使用
ALTER TABLE语句,并使用DROP PARTITION子句来指定要删除的分区。ALTER TABLE my_partitioned_table DROP PARTITION p2;执行上述语句后,分区
p2将从表my_partitioned_table中删除。删除分区将永久删除该分区中的数据。在执行删除操作之前,请确保已经备份了需要保留的数据,以防止数据丢失。另外,删除分区可能会影响表的索引和性能。如果删除了分区,您可能需要重新建立索引或重新优化表的结构,以确保表的性能仍然良好。在删除分区之前,请考虑可能的影响并进行适当的测试和规划。
4.3 合并分区
使用
ALTER TABLE语句,并使用REORGANIZE PARTITION子句来指定要合并的分区。ALTER TABLE my_partitioned_table REORGANIZE PARTITION p1,p2 INTO ( PARTITION pp);在 MySQL 中,范围分区无法直接合并两个分区。然而,可以通过以下步骤来模拟合并两个范围分区的效果:
1、创建一个新的目标表,与原始表具有相同的结构,但不包含分区定义。
2、将要合并的两个分区的数据插入到新的目标表中。
3、删除原始表。
4、重命名新的目标表为原始表的名称。
以下是一个示例,演示如何合并名为
p1和p2的范围分区:-- 创建新的目标表 CREATE TABLE my_partitioned_table_new ( `id` int(11) DEFAULT NULL, `name` varchar(50) DEFAULT NULL, `created_date` date DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- 将分区 p1 的数据插入到新表 INSERT INTO my_partitioned_table_new SELECT * FROM my_partitioned_table PARTITION (p1); -- 将分区 p2 的数据插入到新表 INSERT INTO my_partitioned_table_new SELECT * FROM my_partitioned_table PARTITION (p2); -- 删除原始表 DROP TABLE my_partitioned_table; -- 重命名新的目标表为原始表的名称 ALTER TABLE my_partitioned_table_new RENAME TO my_partitioned_table;请注意,上述示例中的表结构和分区定义应根据实际情况进行调整。在执行任何涉及数据操作的步骤之前,请确保对数据进行备份,并在生产环境中进行适当的测试。
此方法模拟了合并两个分区的效果,但实际上并没有合并原始表的分区。相反,它创建了一个新的表,并将两个分区的数据合并到新表中。因此,您需要根据实际情况来评估是否适合使用此方法,并确保在进行任何更改之前进行适当的测试和备份。
五、概念
5.1 MySQL表分区释义
MySQL表分区技术是一种将表数据划分为更小、更可管理的逻辑部分的方法。它可以提高查询性能、简化数据维护和管理,并允许更灵活地处理大量数据。
5.2 MySQL表分区的分区类型
MySQL提供了几种分区类型,包括范围分区(Range Partitioning)、列表分区(List Partitioning)、哈希分区(Hash Partitioning)和键分区(Key Partitioning)。下面对每种分区类型进行简要介绍:
5.2.1 范围分区(Range Partitioning)
根据指定的范围条件将数据分配到不同的分区中。例如,可以按照日期范围将数据分区,每个分区包含一段时间内的数据。
5.2.2 列表分区(List Partitioning)
根据列值的列表将数据分配到不同的分区中。例如,可以根据地区或部门名称将数据分区,每个分区包含特定地区或部门的数据。
5.2.3 哈希分区(Hash Partitioning)
根据列值的哈希函数结果将数据均匀地分配到不同的分区中。哈希分区可以确保数据在各个分区中分布均匀,适用于负载平衡和分布式查询。
5.2.4 键分区(Key Partitioning)
根据列值的哈希函数或者直接的键值将数据分配到不同的分区中。键分区类似于哈希分区,但可以自定义哈希函数或者直接指定键值进行分区。
六、架构角度看表横向扩展和Mysql表分区
当涉及到表的横向扩展和表分区时,以下是从可维护性、性能、数据一致性和应用程序复杂性的角度来比较它们:
1、可维护性
- 表横向扩展:当需要增加更多的数据节点时,需要修改应用程序的逻辑和配置,以确保数据在新节点上正确分布。这可能需要更多的开发和运维工作。
- 表分区:通过使用数据库的内置分区功能,管理和维护表分区相对较为简单。您可以使用ALTER TABLE语句添加、删除或修改分区,而不需要修改应用程序的逻辑。
2、性能
- 表横向扩展:横向扩展允许将负载分布在多个节点上,从而提高系统的整体吞吐量。每个节点可以处理更少的数据,减轻了单一节点的负载压力。
- 表分区:分区可以提高查询性能,因为可以只针对特定分区的数据执行查询,而不需要扫描整个表。分区还可以利用并行查询的优势,从而加快查询速度。
3、数据一致性
- 表横向扩展:横向扩展通常涉及到将数据分布在不同的节点上,因此在处理跨节点事务或数据更新时,需要考虑数据一致性的问题。这可能需要实现分布式事务或采用其他一致性机制。
- 表分区:表分区通常在单个数据库实例内进行,因此事务和数据更新的一致性相对较容易维护。数据位于同一数据库中,可以使用常规的事务机制来确保数据的一致性。
4、应用程序复杂性
- 表横向扩展:横向扩展可能需要更复杂的应用程序架构和逻辑,以处理分布式数据的查询和操作。开发和维护这样的应用程序可能需要更高的技术要求和开发成本。
- 表分区:分区可以相对较容易地集成到应用程序中,因为大多数数据库提供了对分区的内置支持。应用程序可以在不知道分区细节的情况下进行正常操作,从而减少了复杂性
其实他们往往可以联合使用,当表的数据特别特别多的时候,以横向扩展为主,表分区为辅,表数据不是很多,推荐表分区。请注意,表分区的设计和使用需要根据实际情况和需求进行权衡和规划。它可能对数据的存储、查询和维护产生一些限制和约束。在使用分区技术之前,请确保对MySQL的分区功能有足够的了解,并在设计和使用分区表时谨慎考虑各种因素。