C语言--结构体基本用法
前言:
本章让我们初步认识和使用结构体,但不会深入解读。
为什么要有结构体?
因为在实际问题中,一组数据往往有很多种不同的数据类型。例如,登记学生的信息,可能需要用到 char型的姓名,int型或 char型的学号,int型的年龄,char型的性别,float型的成绩。又例如,对于记录一本书,需要 char型的书名,char型的作者名,float型的价格。在这些情况下,使用简单的基本数据类型甚至是数组都是很困难的。而结构体,则可以有效的解决这个问题。
结构体本质上还是一种数据类型,但它可以包括若干个“成员”,每个成员的类型可以相同也可以不同,也可以是基本数据类型或者又是一个构造类型。
1. 结构体的声明
1.1 结构的基础知识
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
1.2 结构的声明
struct tag//声明结构体,struct+名
{
member-list;//成员变量列表
}variable-list;//变量列表变量列表稍后再做解释。
例如描述一个学生:
#include
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}s3,s4;//分号不能丢
//s3,s4是全局变量
int main()
{
struct stu s1;
struct stu s1;
//struct不能省略
//s1,s2是结构体的变量,是局部变量
return 0;
}
每次定义局部变量都要加上struct,有没有办法省略掉呢?
来看下这种写法:
#include
typedef struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}stu;stu是重命名产生的新的类型
int main()
{
stu s1;
stu s2;
//这里就可以省略struct了
return 0;
}
在上面的写法,我们在声明时加上了typedef,对结构体进行了重命名,这样就能在定义局部变量时省略struct关键字了。
1.3 结构成员的类型
结构的成员可以是标量、数组、指针,甚至是其他结构体。
struct B
{
int a;
char b;
};
struct A
{
char c;
int num;
int arr[10];
double* pd;
struct B sb;
struct B* pd;
};
1.4 结构体变量的定义和初始化
有了结构体类型,那如何定义变量,其实很简单。
struct Point
{
int x;
int y;
}p1; //声明类型的同时定义变量p1
struct Point p2; //定义结构体变量p2(全局)
struct Point p3 = {x, y};//初始化:定义变量的同时赋初值。
struct Stu //类型声明
{
char name[15];//名字
int age; //年龄
};
struct Stu s = {"zhangsan", 20};//初始化
struct Node
{
int data;
int age
struct Point p;
struct Node* next;
}n1 = {10, 20, {4,5}, NULL}; //结构体嵌套初始化(结构体内包含结构体)
int main()
{
//按照顺序初始化
struct Node n2 = {10,20, {5, 6}, NULL};//结构体嵌套初始化
//指定成员初始化
struct Node n3={.data = 1000,.age = 20};
return 0;
}
总结:结构体的初始化可以按照顺序初始化,也可以指定成员初始化。
2. 结构体成员的访问
结构体访问有两种方式:1.结构体变量 . 成员名2.结构体指针->成员名
1.结构体变量 . 成员名方式:
#include
#include
struct stu
{
char name[20];
int age;
};
void set_s(struct stu t)
{
t.age = 18;
//t.name = "zhangsan";//这种写法在这里行不通,因为name是数组名,数组名是常量的地址
strcpy(t.name, "zhangsan");//可以使用字符串拷贝函数解决
}
int main()
{
struct stu s = {0};
//写一个函数给函数s存放数据
set_s(s);
return 0;
} 
从结果看结构体变量s,并未被赋值,这是为什么呢?

所以我们应该要传递过去。
#include
#include
struct stu
{
char name[20];
int age;
};
void set_s(struct stu* ps)
{
(*ps).age = 18;
//t.name = "zhangsan";//这种写法在这里行不通,因为name是数组名,数组名是常量的地址
strcpy((*ps).name, "zhangsan");//可以使用字符串拷贝函数解决
}
int main()
{
struct stu s = {0};
//写一个函数给函数s存放数据
set_s(&s);
return 0;
} 此时s内就有值了
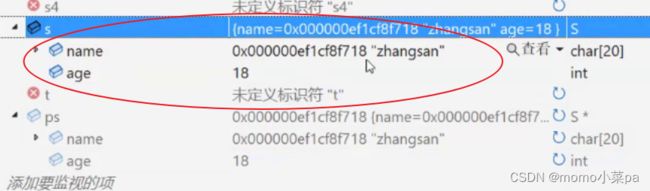
2.结构体指针->成员名方式:
对于上面指针的方式,我们就可以使用->了
#include
#include
struct stu
{
char name[20];
int age;
};
void set_s(struct stu* ps)
{
ps->age = 18;
//t.name = "zhangsan";//这种写法在这里行不通,因为name是数组名,数组名是常量的地址
strcpy(ps->name, "zhangsan");//可以使用字符串拷贝函数解决
}
int main()
{
struct stu s = {0};
//写一个函数给函数s存放数据
set_s(&s);
return 0;
}  结果相同。
结果相同。
但如果只是打印的话就不需要传地址,只需要变量临时拷贝就行了

3. 结构体传参
直接上代码:
struct S {
int data[1000];
int num;
};
struct S s = {{1,2,3,4}, 1000};
//结构体传参
void print1(struct S s)
{
printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{
printf("%d\n", ps->num);
}
int main()
{
print1(s); //传结构体
print2(&s); //传地址
return 0;
}上面的 print1 和 print2 函数哪个好些?
答案是:首选print2函数。
原因:
函数传参的时候,参数是需要压栈的。
如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。
结论:
结构体传参的时候,要传结构体的地址。