大模型应用开发框架 LangChain 学习笔记
一场关于大模型的战役正在全世界激烈地上演着,国内外的各大科技巨头和研究机构纷纷投入到这场战役中,光是写名字就能罗列出一大串,比如国外的有 OpenAI 的 GPT-4,Meta 的 LLaMa,Stanford University 的 Alpaca,Google 的 LaMDA 和 PaLM 2,Anthropic 的 Claude,Databricks 的 Dolly,国内的有百度的 文心,阿里的 通义,科大讯飞的 星火,华为的 盘古,复旦大学的 MOSS,智谱 AI 的 ChatGLM 等等等等。
一时间大模型如百花齐放,百鸟争鸣,并在向各个行业领域渗透,让人感觉通用人工智能仿佛就在眼前。基于大模型开发的应用和产品也如雨后春笋,让人目不暇接,每天都有很多新奇的应用和产品问世,有的可以充当你的朋友配你聊天解闷,有的可以充当你的老师帮你学习答疑,有的可以帮你写文章编故事,有的可以帮你写代码改 BUG,大模型的崛起正影响着我们生活中的方方面面。
正是在这样的背景下,为了方便和统一基于大模型的应用开发,一批大模型应用开发框架横空出世,LangChain 就是其中最流行的一个。
快速开始
正如前文所述,LangChain 是一个基于大语言模型(LLM)的应用程序开发框架,它提供了一整套工具、组件和接口,简化了创建大模型应用程序的过程,方便开发者使用语言模型实现各种复杂的任务,比如聊天机器人、文档问答、各种基于 Prompt 的助手等。根据 官网的介绍,它可以让你的应用变得 Data-aware 和 Agentic:
- Data-aware:也就是数据感知,可以将语言模型和其他来源的数据进行连接,比如让语言模型针对指定文档回答问题;
- Agentic:可以让语言模型和它所处的环境进行交互,实现类似代理机器人的功能,帮助用户完成指定任务;
LangChain 在 GitHub 上有着异乎寻常的热度,截止目前为止,星星数高达 55k,而且它的更新非常频繁,隔几天就会发一个新版本,有时甚至一天发好几个版本,所以学习的时候最好以官方文档为准,网络上有很多资料都过时了(包括我的这篇笔记)。
LangChain 提供了 Python 和 JavaScript 两个版本的 SDK,这里我主要使用 Python 版本的,在我写这篇笔记的时候,最新的版本为 0.0.238,使用下面的命令安装:
| 1 |
|
注意:Python 版本需要在 3.8.1 及以上,如果低于这个版本,只能安装 langchain==0.0.27。
另外要注意的是,这个命令只会安装 LangChain 的基础包,这或许并没有什么用,因为 LangChain 最有价值的地方在于它能和各种各样的语言模型、数据存储、外部工具等进行交互,比如如果我们需要使用 OpenAI,则需要手动安装:
| 1 |
|
也可以在安装 LangChain 时指定安装可选依赖包:
| 1 |
|
或者使用下面的命令一次性安装所有的可选依赖包(不过很多依赖可能会用不上):
| 1 |
|
LangChain 支持的可选依赖包有:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
可以在项目的 pyproject.toml 文件中查看依赖包详情。
入门示例:LLMs vs. ChatModels
我们首先从一个简单的例子开始:
| 1 2 3 4 5 6 7 |
|
LangChain 集成了许多流行的语言模型,并提供了一套统一的接口方便开发者直接使用,比如在上面的例子中,我们引入了 OpenAI 这个 LLM,然后调用 llm.predict() 方法让语言模型完成后续内容的生成。如果用户想使用其他语言模型,只需要将上面的 OpenAI 换成其他的即可,比如流行的 Anthropic 的 Claude 2,或者 Google 的 PaLM 2 等,这里 可以找到 LangChain 目前支持的所有语言模型接口。
回到上面的例子,llm.predict() 方法实际上调用的是 OpenAI 的 Completions 接口,这个接口的作用是给定一个提示语,让 AI 生成后续内容;我们知道,除了 Completions,OpenAI 还提供了一个 Chat 接口,也可以用于生成后续内容,而且比 Completions 更强大,可以给定一系列对话内容,让 AI 生成后续的回复,从而实现类似 ChatGPT 的聊天功能。
官方推荐使用 Chat 替换 Completions 接口,在后续的 OpenAI 版本中,Completions 接口可能会被弃用。
因此,LangChain 也提供 Chat 接口:
| 1 2 3 4 5 6 7 8 9 10 |
|
和上面的 llm.predict() 方法比起来,chat.predict_messages() 方法可以接受一个数组,这也意味着 Chat 接口可以带上下文信息,实现聊天的效果:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
另外,Chat 接口也提供了一个 chat.predict() 方法,可以实现和 llm.predict() 一样的效果:
| 1 2 3 4 5 6 7 |
|
实现翻译助手:PromptTemplate
在 基于 ChatGPT 实现一个划词翻译 Chrome 插件 这篇笔记中,我们通过提示语技术实现了一个非常简单的划词翻译 Chrome 插件,其中的翻译功能我们也可以使用 LangChain 来完成,当然,使用 LLMs 和 ChatModels 都可以。
使用 LLMs 实现翻译助手:
| 1 2 3 4 5 6 7 |
|
使用 ChatModels 实现翻译助手:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
观察上面的代码可以发现,输入参数都具备一个固定的模式,为此,LangChain 提供了一个 PromptTemplate 类来方便我们构造提示语模板:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
其实
PromptTemplate默认实现就是 Python 的 f-strings,只不过它提供了一种抽象,还可以支持其他的模板实现,比如 jinja2 模板引擎。
对于 ChatModels,LangChain 也提供了相应的 ChatPromptTemplate,只不过使用起来要稍微繁琐一点:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
实现知识库助手:Data connection
在 使用 Embedding 技术打造本地知识库助手 这篇笔记中,我们通过 OpenAI 的 Embedding 接口和开源向量数据库 Qdrant 实现了一个非常简单的知识库助手。在上面的介绍中我们提到,LangChain 的一大特点就是数据感知,可以将语言模型和其他来源的数据进行连接,所以知识库助手正是 LangChain 最常见的用例之一,这一节我们就使用 LangChain 来重新实现它。
LangChain 将实现知识库助手的过程拆分成了几个模块,可以自由组合使用,这几个模块是:
- Document loaders - 用于从不同的来源加载文档;
- Document transformers - 对文档进行处理,比如转换为不同的格式,对大文档分片,去除冗余文档,等等;
- Text embedding models - 通过 Embedding 模型将文本转换为向量;
- Vector stores - 将文档保存到向量数据库,或从向量数据库中检索文档;
- Retrievers - 用于检索文档,这是比向量数据库更高一级的抽象,不仅仅限于从向量数据库中检索,可以扩充更多的检索来源;
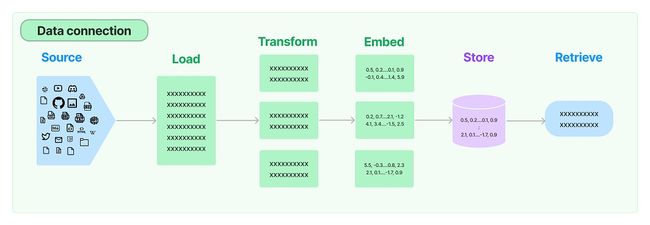
读取文档
TextLoader 是最简单的读取文档的方法,它可以处理大多数的纯文本,比如 txt 或 md 文件:
| 1 2 3 4 5 |
|
LangChain 还提供了一些其他格式的文档读取方法,比如 JSON、HTML、CSV、Word、PPT、PDF 等,也可以加载其他来源的文档,比如通过 URLLoader 抓取网页内容,通过 WikipediaLoader 获取维基百科的内容等,还可以使用 DirectoryLoader 同时读取整个目录的文档。
文档分割
使用 TextLoader 加载得到的是原始文档,有时候我们还需要对原始文档进行处理,最常见的一种处理方式是文档分割。由于大模型的输入存在上下文窗口的限制,所以我们不能直接将一个几百兆的文档丢给大模型,而是将大文档分割成一个个小分片,然后通过 Embedding 技术查询与用户问题最相关的几个分片丢给大模型。
最简单的文档分割器是 CharacterTextSplitter,它默认使用分隔符 \n\n 来分割文档,我们也可以修改为使用 \n 来分割:
| 1 2 3 4 5 6 7 8 9 |
|
CharacterTextSplitter 可以通过 chunk_size 参数控制每个分片的大小,默认情况下分片大小为 4000,这也意味着如果有长度不足 4000 的分片会递归地和其他分片合并成一个分片;由于我这里的测试文档比较小,总共都没有 4000,所以按 \n 分割完,每个分片又会被合并成一个大分片了,所以我这里将 chunk_size 设置为 0,这样就不会自动合并。
另一个需要注意的是,这里的分片大小是根据 length_function 来计算的,默认使用的是 len() 函数,也就是根据字符的长度来分割;但是大模型的上下文窗口限制一般是通过 token 来计算的,这和长度有一些细微的区别,所以如果要确保分割后的分片能准确的适配大模型,我们就需要 通过 token 来分割文档,比如 OpenAI 的 tiktoken,Hugging Face 的 GPT2TokenizerFast 等。OpenAI 的这篇文档 介绍了什么是 token 以及如何计算它,感兴趣的同学可以参考之。
不过在一般情况下,如果对上下文窗口的控制不需要那么严格,按长度分割也就足够了。
Embedding 与向量库
有了分割后的文档分片,接下来,我们就可以对每个分片计算 Embedding 了:
| 1 2 3 4 5 |
|
这里我们使用的是 OpenAI 的 Embedding 接口,除此之外,LangChain 还集成了很多 其他的 Embedding 接口,比如 Cohere、SentenceTransformer 等。不过一般情况下我们不会像上面这样单独计算 Embedding,而是和向量数据库结合使用:
| 1 2 3 4 5 6 7 8 9 10 |
|
这里我们仍然使用 Qdrant 来做向量数据库,Qdrant.from_documents() 方法会自动根据文档列表计算 Embedding 并存储到 Qdrant 中。除了 Qdrant,LangChain 也集成了很多 其他的向量数据库,比如 Chroma、FAISS、Milvus、PGVector 等。
再接下来,我们通过 qdrant.similarity_search() 方法从向量数据库中搜索出和用户问题最接近的文本片段:
| 1 2 3 |
|
后面的步骤就和 使用 Embedding 技术打造本地知识库助手 这篇笔记中一样,准备一段提示词模板,向 ChatGPT 提问就可以了。
LangChain 的精髓:Chain
通过上面的快速开始,我们学习了 LangChain 的基本用法,从几个例子下来,或许有人觉得 LangChain 也没什么特别的,只是一个集成了大量的 LLM、Embedding、向量库的 SDK 而已,我一开始也是这样的感觉,直到学习 Chain 这个概念的时候,才明白这时才算是真正地进入 LangChain 的大门。
从 LLMChain 开始
LLMChain 是 LangChain 中最基础的 Chain,它接受两个参数:一个是 LLM,另一个是提供给 LLM 的 Prompt 模板:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
其中,LLM 参数同时支持 LLMs 和 ChatModels,运行效果和上面的入门示例是一样的。
在 LangChain 中,Chain 的特别之处在于,它的每一个参数都被称为 Component,Chain 由一系列的 Component 组合在一起以完成特定任务,Component 也可以是另一个 Chain,通过封装和组合,形成一个更复杂的调用链,从而创建出更强大的应用程序。
上面的例子中,有一点值得注意的是,我们在 Prompt 中定义了一个占位符 {sentence},但是在调用 Chain 的时候并没有明确指定该占位符的值,LangChain 是怎么知道要将我们的输入替换掉这个占位符的呢?实际上,每个 Chain 里都包含了两个很重要的属性:input_keys 和 output_keys,用于表示这个 Chain 的输入和输出,我们查看 LLMChain 的源码,它的 input_keys 实现如下:
| 1 2 3 |
|
所以 LLMChain 的入参就是 Prompt 的 input_variables,而 PromptTemplate.from_template() 其实是 PromptTemplate 的简写,下面这行代码:
| 1 |
|
等价于下面这行代码:
| 1 2 3 4 |
|
所以 LLMChain 的入参也就是 sentence 参数。
而下面这行代码:
| 1 |
|
是下面这行代码的简写:
| 1 |
|
当参数比较简单时,LangChain 会自动将传入的参数转换成它需要的 Dict 形式,一旦我们在 Prompt 中定义了多个参数,那么这种简写就不行了,就得在调用的时候明确指定参数:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
我们从 LangChain 的源码中可以更深入的看下 Chain 的类定义,如下:
| 1 2 3 4 5 6 7 8 9 10 |
|
这说明 Chain 的本质其实就是根据一个 Dict 输入,得到一个 Dict 输出而已。只不过 Chain 为我们还提供了三个特性:
- Stateful: 内置 Memory 记忆功能,使得每个 Chain 都是有状态的;
- Composable: 具备高度的可组合性,我们可以将 Chain 和其他的组件,或者其他的 Chain 进行组合;
- Observable: 支持向 Chain 传入 Callbacks 回调执行额外功能,从而实现可观测性,如日志、监控等;
使用 Memory 实现记忆功能
Chain 的第一个特征就是有状态,也就是说,它能够记住会话的历史,这是通过 Memory 模块来实现的,最简单的 Memory 是 ConversationBufferMemory,它通过一个内存变量保存会话记忆。
在使用 Memory 时,我们的 Prompt 需要做一些调整,我们要在 Prompt 中加上历史会话的内容,比如下面这样:
| 1 2 3 4 5 6 7 8 |
|
其中 {history} 这个占位符的内容就由 Memory 来负责填充,我们只需要将 Memory 设置到 LLMChain 中,这个填充操作将由框架自动完成:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
对于 ChatModels,我们可以使用 ChatPromptTemplate 来构造 Prompt:
| 1 2 3 4 5 6 7 |
|
占位符填充的基本逻辑是一样的,不过在初始化 Memory 的时候记得指定 return_messages=True,让 Memory 使用 Message 列表来填充占位符,而不是默认的字符串:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
为了简化 Prompt 的写法,LangChain 基于 LLMChain 实现了 ConversationChain,使用起来更简单:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
除了 ConversationBufferMemory,LangChain 还提供了很多其他的 Memory 实现:
- ConversationBufferWindowMemory - 基于内存的记忆,只保留最近 K 次会话;
- ConversationTokenBufferMemory - 基于内存的记忆,根据 token 数来限制保留最近的会话;
- ConversationEntityMemory - 从会话中提取实体,并在记忆中构建关于实体的知识;
- ConversationKGMemory - 基于知识图来重建记忆;
- ConversationSummaryMemory - 对历史会话进行总结,减小记忆大小;
- ConversationSummaryBufferMemory - 既保留最近 K 次会话,也对历史会话进行总结;
- VectorStoreRetrieverMemory - 通过向量数据库保存记忆;
这些 Memory 在长对话场景,或需要对记忆进行持久化时非常有用。内置的 Memory 大多数都是基于内存实现的,LangChain 还集成了很多第三方的库,可以实现记忆的持久化,比如 Sqlite、Mongo、Postgre 等。
再聊文档问答:RetrievalQA
在上面的实现知识库助手一节,我们学习了各种加载文档的方式,以及如何对大文档进行分片,并使用 OpenAI 计算文档的 Embedding,最后保存到向量数据库 Qdrant 中。一旦文档库准备就绪,接下来就可以对它进行问答了,LangChain 也贴心地提供了很多关于文档问答的 Chain 方便我们使用,比如下面最常用的 RetrievalQA:
| 1 2 3 4 5 6 7 8 9 |
|
RetrievalQA 充分体现了 Chain 的可组合性,它实际上是一个复合 Chain,真正实现文档问答的 Chain 是它内部封装的 CombineDocumentsChain,RetrievalQA 的作用是通过 Retrievers 获取和用户问题相关的文档,然后丢给内部的 CombineDocumentsChain 来处理,而 CombineDocumentsChain 又是一个复合 Chain,它会将用户问题和相关文档组合成提示语,丢到内部的 LLMChain 处理最终得到输出。
但总的来说,实现文档问答最核心的还是 RetrievalQA 内部使用的 CombineDocumentsChain,实际上除了 文档问答,针对文档的使用场景还有 生成文档摘要,提取文档信息,等等,这些利用大模型处理文档的场景中,最难解决的问题是如何对大文档进行拆分和组合,而解决方案也是多种多样的,LangChain 提供的 CombineDocumentsChain 是一个抽象类,根据不同的解决方案它包含了四个实现类:
- StuffDocumentsChain
- RefineDocumentsChain
- MapReduceDocumentsChain
- MapRerankDocumentsChain
StuffDocumentsChain
StuffDocumentsChain 是最简单的文档处理 Chain,单词 stuff 的意思是 填充,正如它的名字所示,StuffDocumentsChain 将所有的文档内容连同用户的问题一起全部填充进 Prompt,然后丢给大模型。这种 Chain 在处理比较小的文档时非常有用。在上面的例子中,我们通过 RetrievalQA.from_chain_type(chain_type="stuff") 生成了 RetrievalQA,内部就是使用了 StuffDocumentsChain。它的示意图如下所示:
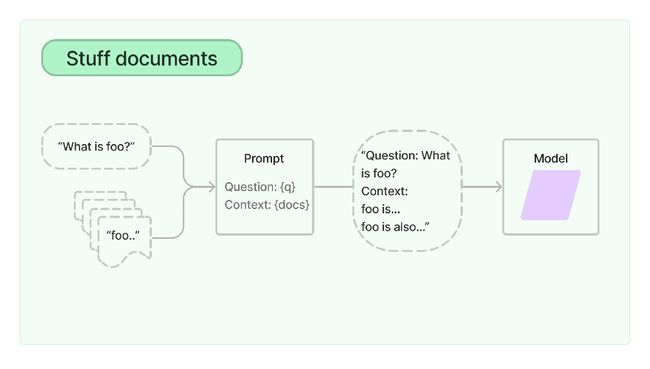
RefineDocumentsChain
refine 的含义是 提炼,RefineDocumentsChain 表示从分片的文档中一步一步的提炼出用户问题的答案,这个 Chain 在处理大文档时非常有用,可以保证每一步的提炼都不超出大模型的上下文限制。比如我们有一个很大的 PDF 文件,我们要生成它的文档摘要,我们可以先生成第一个分片的摘要,然后将第一个分片的摘要和第二个分片丢给大模型生成前两个分片的摘要,再将前两个分片的摘要和第三个分片丢给大模型生成前三个分片的摘要,依次类推,通过不断地对大模型的答案进行更新,最终生成全部分片的摘要。整个提炼的过程如下:
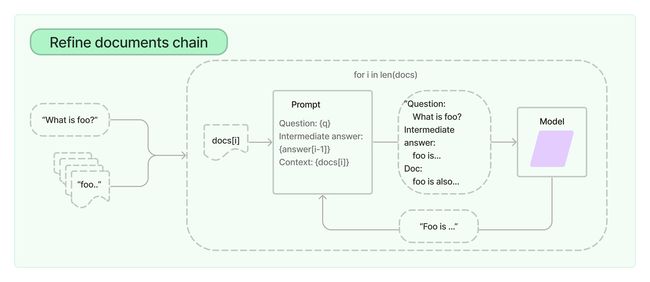
RefineDocumentsChain 相比于 StuffDocumentsChain,会产生更多的大模型调用,而且对于有些场景,它的效果可能很差,比如当文档中经常出现相互交叉的引用时,或者需要从多个文档中获取非常详细的信息时。
MapReduceDocumentsChain
MapReduceDocumentsChain 和 RefineDocumentsChain 一样,都适合处理一些大文档,它的处理过程可以分为两步:Map 和 Reduce。比如我们有一个很大的 PDF 文件,我们要生成它的文档摘要,我们可以先将文档分成小的分片,让大模型挨个生成每个分片的摘要,这一步称为 Map;然后再将每个分片的摘要合起来生成汇总的摘要,这一步称为 Reduce;如果所有分片的摘要合起来超过了大模型的限制,那么我们需要对合起来的摘要再次分片,然后再次递归地执行 Map 和 Reduce 这个过程:
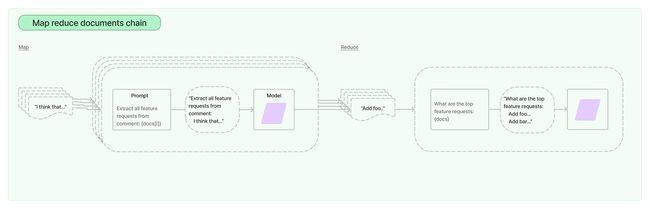
MapRerankDocumentsChain
MapRerankDocumentsChain 一般适合于大文档的问答场景,它的第一步和 MapReduceDocumentsChain 类似,都是遍历所有的文档分片,挨个向大模型提问,只不过它的 Prompt 有一点特殊,它不仅要求大模型针对用户的问题给出一个答案,而且还要求大模型为其答案的确定性给出一个分数;得到每个答案的分数后,MapRerankDocumentsChain 的第二步就可以按分数排序,给出分数最高的答案:

对 Chain 进行调试
当 LangChain 的输出结果有问题时,开发者就需要 对 Chain 进行调试,特别是当组合的 Chain 非常多时,LangChain 的输出结果往往非常不可控。最简单的方法是在 Chain 上加上 verbose=True 参数,这时 LangChain 会将执行的中间步骤打印出来,比如上面的 使用 Memory 实现记忆功能 一节中的例子,加上调试信息后,第一次输出结果如下:
| 1 2 3 4 5 6 7 |
|
第二次的输出结果如下:
| 1 2 3 4 5 6 7 8 9 |
|
可以很方便的看出 Memory 模块确实起作用了,它将历史会话自动拼接在 Prompt 中了。
当一个 Chain 组合了其他 Chain 的时候,比如上面的 RetrievalQA,这时我们不仅要给 Chain 加上 verbose=True 参数,注意还要通过 chain_type_kwargs 为内部的 Chain 也加上该参数:
| 1 2 3 4 5 6 |
|
输出来的结果类似下面这样:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
从输出的结果我们不仅可以看到各个 Chain 的调用链路,而且还可以看到 StuffDocumentsChain 所使用的提示语,以及 retriever 检索出来的内容,这对我们调试 Chain 非常有帮助。
另外,Callbacks 是 LangChain 提供的另一种调试机制,它提供了比 verbose=True 更好的扩展性,用户可以基于这个机制实现自定义的监控或日志功能。LangChain 内置了很多的 Callbacks,这些 Callbacks 都实现自 CallbackHandler 接口,比如最常用的 StdOutCallbackHandler,它将日志打印到控制台,参数 verbose=True 就是通过它实现的;或者 FileCallbackHandler 可以将日志记录到文件中;LangChain 还 集成了很多第三方工具,比如 StreamlitCallbackHandler 可以将日志以交互形式输出到 Streamlit 应用中。
用户如果要实现自己的 Callbacks,可以直接继承基类 BaseCallbackHandler 即可,下面是一个简单的例子:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
在这个例子中,我们对 LLM 和 Chain 进行了监控,我们需要将这个 Callback 分别传递到 LLM 和 Chain 中:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
LangChain 会在调用 LLM 和 Chain 开始和结束的时候回调我们的 Callback,输出结果大致如下:
| 1 2 3 4 5 6 |
|
从 Chain 到 Agent
通过上一节的学习,我们掌握了 Chain 的基本概念和用法,对 Chain 的三大特性也有了一个大概的认识,关于 Chain 还有很多高级主题等着我们去探索,比如 Chain 的异步调用,实现自定义的 Chain,Chain 的序列化和反序列化,从 LangChainHub 加载 Chain,等等。
此外,除了上一节学习的 LLMChain、ConversationChain、RetrievalQA 以及各种 CombineDocumentsChain,LangChain 还提供了很多其他的 Chain 供用户使用,其中有四个是最基础的:
- LLMChain - 这个 Chain 在前面已经学习过,它主要是围绕着大模型添加一些额外的功能,比如
ConversationChain和CombineDocumentsChain都是基于LLMChain实现的; - TransformChain - 这个 Chain 主要用于参数转换,这在对多个 Chain 进行组合时会很有用,我们可以使用
TransformChain将上一个 Chain 的输出参数转换为下一个 Chain 的输入参数; - SequentialChain - 可以将多个 Chain 组合起来并按照顺序分别执行;
- RouterChain - 这是一种很特别的 Chain,当你有多个 Chain 且不知道该使用哪个 Chain 处理用户请求时,可以使用它;首先,你给每个 Chain 取一个名字,然后给它们分别写一段描述,然后让大模型来决定该使用哪个 Chain 处理用户请求,这就被称之为 路由(route);
在这四个基础 Chain 中,RouterChain 是最复杂的一个,而且它一般不单独使用,而是和 MultiPromptChain 或 MultiRetrievalQAChain 一起使用,类似于下面这样:
| 1 2 3 4 5 6 |
|
在 MultiPromptChain 中,我们给定了多个目标 Chains,然后使用 RouterChain 来选取一个最适合处理用户请求的 Chain,如果不存在,则使用一个默认的 Chain,这种思路为我们打开了一扇解决问题的新大门,如果我们让大模型选择的不是 Chain,而是一个函数,或是一个外部接口,那么我们就可以通过大模型做出更多的动作,完成更多的任务,这不就是 OpenAI 的 Function Calling 功能吗?
实际上,LangChain 也提供了 create_structured_output_chain() 和 create_openai_fn_chain() 等方法来创建 OpenAI Functions Chain,只不过 OpenAI 的 Function Calling 归根结底仍然只是一个 LLMChain,它只能返回要使用的函数和参数,并没有真正地调用它,如果要将大模型的输出和函数执行真正联系起来,这就得 Agents 出马了。
Agents 是 LangChain 里一个非常重要的主题,我们将在下一篇笔记中继续学习它。
本文所有的源码可以 参考这里。
参考
- LangChain 完整指南:使用大语言模型构建强大的应用程序
- LangChain 中文入门教程
- LangChain初学者入门指南
- LangChain:Model as a Service粘合剂,被ChatGPT插件干掉了吗?
LangChain 官方资料
- LangChain GitHub
- LangChain 官方博客
- LangChain 官方文档
- LangChain Python 文档
- LangChain JS/TS 文档
LangChain 项目
- hwchase17/chat-langchain - 基于文档的 QA 问答
- hwchase17/notion-qa - 基于 Notion 的 QA 问答
- hwchase17/chat-your-data
- imClumsyPanda/langchain-ChatGLM - 基于本地知识库的 ChatGLM 等大语言模型应用实现
LangChain 教程
- gkamradt/langchain-tutorials
- A Comprehensive Guide to LangChain
- Build a GitHub Support Bot with GPT3, LangChain, and Python
- LangChain and LlamaIndex Projects Lab Book: Hooking Large Language Models Up to the Real World
- Re-implementing LangChain in 100 lines of code
- LangChain + Vectara: better together
LangChain 可视化
- FlowiseAI/Flowise - Drag & drop UI to build your customized LLM flow using LangchainJS
- logspace-ai/langflow - LangFlow is a UI for LangChain, designed with react-flow to provide an effortless way to experiment and prototype flows.
- 向量脉络 VectorVein
- ChatFlow
LlamaIndex 参考资料
- LlamaIndex
- 面向QA系统的全新文档摘要索引
- LlamaIndex:轻松构建索引查询本地文档的神器
- 后chatgpt时代的对话式文档问答解决方案
其他
- Prem - Self Sovereign AI Infrastructure
- 生成式AI的应用路线图