数据结构学习之路-链表
链表
- 动态数组的接口设计
- 链表(Linked List)
-
- Java中的接口继承规范(单纯的Java语法,跟数据结构没关系)
- 链表类的设计
- 链表接口的设计
- 链表的练习题
-
- 删除节点
- 反转链表
- 环形链表
- 双向链表(Double Linked List)
-
- 双向链表的接口设计
- 双向链表 VS 单向链表
- 双向链表 VS 动态数组
- 单向循环链表
- 双向循环链表
- 链表总结
学习链表之前,先学习动态数组。数组是一种顺序存储的线性表,所有的元素的内存地址是连续的
动态数组的接口设计
一个动态数组,需要有哪些接口呢?换句话说,有哪些接口之后,才能叫动态数组呢?

这样的话,我们就根据接口去设计动态数组。
成员变量一定要有一个size,也就是记录数组的长度,还要有一个指向数组的指针,也就是类似于数组名。由于我们学习了泛型,这里就将动态数组设置为泛型
public class DynamicArray<Type> {
private int size; // 数组长度
private Type[] ArrayList; //声明一个数组变量,其实本质是一个指针,指向数组首元素的指针
}
然后,我们还要添加构造函数,因为将来创建动态数组对象的时候,大概率会指定数组的长度,因此这个操作要在构造函数里完成。说一下这里构造函数的细节:
-
一个良好的数组类,应该有默认容量,假如我们在创建对象的时候,设置的初始容量非常小,或者误设置成了负数,那么该类应该默认的设置为默认容量,因此有了这句代码
capacity = (capacity < DEFAULT_CAPACITY) ? DEFAULT_CAPACITY : capacity; -
在Java中,常量要设置成static final类型,final就相当于C++中的const,而且变量的名字尽量全部大写,符合规范
-
在获得容量值之后,我们就要在构造函数内部开辟堆空间存储这块空数组,因此需要new一下
-
由于是动态数组,因此,我们还要声明一下当前时刻的容量,随时记录动态的容量。顺其自然,初始化完数组,也得记录当前容
CurrentCapacity = capacity; -
并不是,所有的人创建数组时都为对象传一个参数,也可能没有传参数。那该数组类也应该创建一个数组,所以,还要在声明一个无参的构造函数,里面调用有参的构造函数(通过
this(DEFAULT_CAPACITY)即可,想想跟创建对象的格式一样,对象(参数)),创建一个默认容量的数组。这才完美!!!!
public class DynamicArray<Type> {
private int size; // 数组长度
private Type[] ArrayList; //声明一个数组变量,其实本质是一个指针,指向数组首元素的指针
private static final int DEFAULT_CAPACITY = 5; //数组默认容量-常量,final = const
private int CurrentCapacity; //当前数组的容量
/**
* @param capacity 指定数组容量
* 有参构造函数:创建数组,并且初始化
*/
public DynamicArray(int capacity){
capacity = (capacity < DEFAULT_CAPACITY)?DEFAULT_CAPACITY:capacity;
ArrayList= (Type[]) new Object[capacity]; //所有类都继承Object类,因此java的泛型实现需要在new空间时,new Object[],并且强转类型
CurrentCapacity = capacity;
}
/**
* 无参构造函数,初始化数组,默认容量
*/
public DynamicArray(){
this(DEFAULT_CAPACITY); //构造函数互相调用,使用this指针即可
}
}
接下来,我们该设计接口函数了
- 调用
size()函数,直接返回当前数组里元素的个数,也就是数组的长度。要搞清楚,这个数组长度跟数组容量不是一回事。容量是最多能放多少个元素,size是当前数组有多少个非空元素。
/**
* 调用size方法,返回当前数组的长度(当前数组里数据的个数)
* @return 数组的长度
*/
public int size(){
return size;
}
- 调用
isEmpty()函数,返回数组是否为空,返回的是bool值。即,数组内还有没有元素,因此直接返回size==0,如果size==0了,说明数组为空,正好返回True,反之则返回False
/**
* 检查数组是否为空
* @return bool类型,java里用boolean表示bool类型
*/
public boolean isEmpty(){
return size == 0;
}
- 调用
get(int index)函数,直接返回数组内,索引index处的元素。涉及到数组的索引,一个良好的习惯就是判断索引是否越界,如果越界就抛出异常。Java中索引越界的异常可以用throw new IndexOutOfBoundsException()来设置。然后直接返回数组index处的元素就行了。
/**
* 获得指定索引处的值
* @param index
* @return 数组中的值
*/
public Type get(int index){
if(index<0 || index>=size){
throw new IndexOutOfBoundsException("Index out of range->"+"Index:"+index+", size:"+size);
}
return ArrayList[index];
}
- 调用
set(int index, Type element)函数,就把数组index处的值用新的值element覆盖掉,并返回覆盖掉之前index处的值。一定要先把原来的值取出来,要不然覆盖点之后再取,就不是原来的值了。
/**
* 设置数组index处的值为element,并将原来的值返回
* @param index
* @param element
* @return
*/
public Type set(int index, Type element){
if(index<0 || index>=size){
throw new IndexOutOfBoundsException("Index out of range->"+"Index:"+index+", size:"+size);
}
Type oldElement = ArrayList[index]; //先取出原来的值
ArrayList[index] = element; //再设置
return oldElement;
}
- 调用
int indexOf(Type element)函数,查找给定的元素在数组中的索引位置,如果该元素不在数组中,那就返回-1。没有技巧,就是遍历数组元素,判断数组中的元素是否跟传入的元素相等,相等就直接返回索引i。
/**
* 查看某个元素在数组中的位置,即根据元素返回索引,如果没有找到,那就返回-1
* @param element
* @return int index
*/
public int indexOf(Type element){
for (int i = 0; i < size ; i++) {
if(ArrayList[i] == element) return i;
}
return -1;
}
- 调用
contains(Type element)函数,判断某个元素是否包含在数组中,如果包含那就返回True,如果不包含那就返回False。这里用到了上一个函数indexOf(Type element),因为indexOf函数其实也能判断元素在不在,因为只要返回的不是-1,element就在数组中。所以这个返回indexOf(element) != -1,很是巧妙。
/**
* 查看某个元素是否在数组中,如果存在就返回True,如果不存在就返回False
* @param element
* @return
*/
public boolean contains(Type element){
return indexOf(element) != -1;
}
- 调用
clear()函数,即清空数组所有元素。为什么size=0就办到了呢?有这个疑问是对的。因为size=0,原来数组内的元素还是存在那块内存中,并没有被清空。但是,对于动态数组的使用者来说,他无法get到任何一个元素了,打印size也是0,在他眼里,数组好像就是被清空了。因为,我们是框架的开发者,我们只需要保证调用时的语义正确性。因此,size=0是逻辑清空数组,如果把数组置位null或者释放堆空间内存,这叫物理清空。但是,在保证调用语义一致性的前提下,逻辑清空可以节约资源,减少性能消耗。
/**
* 调用函数,即可清空数组内的所有元素
*/
public void clear(){
size = 0;
}
- 调用
remove(int index)函数,删除index处的元素。后面的元素一次向前移动。
假设删除index为3的元素。因为数组是连续的,因此可以直接删除,只能覆盖。也就是说,不可以直接把index处的内存直接释放。内存是不能动的,因为数组申请完毕之后,内存都是连续的,不可以挖空任何一块内存。
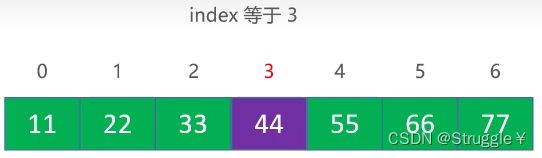
依次,把index处后的元素向前移动,注意是:从index的下一位开始移动,然后下下一位在移动,不能从后向前移动,会导致覆盖错误。

/**
* 删除索引处的元素,后面的向前移动,并返回之前的值(也可以不返回,看自己需求)
* @param index
* @return 返回删除的元素值
*/
@Override
public Type remove(int index) {
if(index<0 || index>=size){
throw new IndexOutOfBoundsException("Index out of range->"+"Index:"+index+", size:"+size);
}
Type oldElement = ArrayList[index];
//i从index +1的位置开始挪动,然后把后面的元素全部向前挪动一位
for (int i = index+1; i < size ; i++) {
ArrayList[i - 1] = ArrayList[i];
}
ArrayList[size - 1] = null; //把最后一位置空,但是也可以不处理,因为只要size-1,最后一个位置就访问不到了
size--; //然后数组数量减少一个
// ArrayList[--size] = null; //这一句代码和上面代码功能相同
return oldElement;
}
- 动态数组的精华:动态扩容技术。调用
ensureCapacity(int capacity),判断当前输入的容量capacity够不够,如果不够,该函数会进行扩容。
动态扩容不允许在原有的数组内存后面拼接一块扩充的内存,没有这种操作。动态扩容的精髓就是申请一个更大的内存空间,然后把之前的数组元素都挪过来,因为是更大的内存空间,所以就相当于扩容了。扩容的具体步骤
- 判断当前的容量
oldCapacity是否满足我所需要的容量capacity。如果满足,就直接return,如果没有return,说明需要扩容,就执行下面的操作- 获得想要扩容后的新容量,比如我想在现有的容量基础上,扩大1.5倍。那就这样写
int newCapacity = oldCapacity + (oldCapacity >> 1);,右移比直接除以2更快。如果我想要扩大2倍,那我就这样写int newCapacity = oldCapacity << 1;,同样,左移比乘2快。- 获得新容量值之后,就要申请对应的存储空间,需要一个新的数组指针
newArrayList指向这块存储空间。- 然后把之前数组里的元素,按照顺序填到新空间里。这里用一个for循环就行了
- 然后让原有的成员变量
ArrayList指向这块存储空间,我们以后访问这块内存,还可以用之前的数组指针ArrayList- 最后将新容量
newCapacity赋值给当前容量CurrentCapacity
/**
* 保证扩容之后的容量要够用
* @param hopeCapacity 想要保证的最小容量
*/
private void ensureCapacity(int hopeCapacity){
int oldCapacity = ArrayList.length; //返回数组的容量,length就是内存中的大小了,而不是真实的元素个数
if (oldCapacity >= hopeCapacity) return; //如果数组的容量大于目前我想要的最小容量,说明不需要扩容
int newCapacity = oldCapacity + (oldCapacity >> 1); //扩充1.5倍,为什么不直接乘1.5?因为浮点数运算更慢,>>1表示一个数除以2,这种效率更高
Type[] newArrayList = (Type[]) new Object[newCapacity]; //新申请一块更大的存储空间,用于存放数组元素
for (int i = 0;i<size;i++){
//把原来数组的元素,放到新的存储空间
newArrayList[i] = ArrayList[i];
}
ArrayList = newArrayList;
CurrentCapacity = newCapacity;
System.out.println("扩容:"+"oldCapacity:"+oldCapacity+" -> newCapacity:"+newCapacity);
}
我们以后在添加元素到数组的时候,先判断当前容量够不够,如果不够,再去扩容
- 调用
append(Type elements)函数,添加元素到数组尾部。需要判断是否需要扩容,因为有可能添加元素时,数组已经满了。如果在我append时候,发现size已经大于等于现在的容量了,说明数组已经装满了,这时候就需要扩容。这个函数ensureCapacity(hopeCapacity)的参数,是确保要有这些容量,不一定每次都要扩容。但是如果现在的容量没有我想要的容量大,就得扩容。扩完容,就直接在尾部添加就行了。
/**
* 添加元素到数组的尾部
* @param elements
*/
public void append(Type elements){
if(size >= CurrentCapacity){ //如果当前数组的数据长度大于等于当前容量,就得扩容
ensureCapacity(size+1); //确保最少有size+1的容量
ArrayList[size] = elements;
}else {
ArrayList[size] = elements;
}
size++;//更新数据个数
}
也可以不判断if(size >= CurrentCapacity),因为ensureCapacity(int hopeCapacity)里已经有判断需不需要扩容了。
- 调用
add(int index, Type element)函数,向指定的index处插入元素,然后index及其后面的元素,向后移动。向后移动,就要从后面开始向右移动了,所以for循环里必须这样写for(int i = size -1; i >= index; i--)。原则就是:合理,不会出错的移动。
/**
* 向index处添加元素,后面的元素需要依次向后移动
* @param index
* @param element
*/
public void add(int index, Type element){
if(index<0 || index>=size){
throw new IndexOutOfBoundsException("Index out of range->"+"Index:"+index+", size:"+size);
}
//至少保证容量要有size+1个大小
ensureCapacity(size + 1);
for(int i = size -1; i >= index; i--){
ArrayList[i + 1] = ArrayList[i];
}
ArrayList[index] = element;
size++;
}
链表(Linked List)
动态数组有一个明显的缺点:可能会造成内存空间的大量浪费!!!
因为,动态数组每次扩容的空间可能会用不到。
那能否办到用多少就申请多少内存呢?
答案是:链表可以办到这一点!!!链表是一种链式存储的线性表,所有元素的内存地址不一定连续。
下图是一个链表的示意图:具有头结点、尾结点,每一个节点内部存储两个变量(该节点的值,指向下一个节点的指针),对于单向链表来说,尾结点指向null。

Java中的接口继承规范(单纯的Java语法,跟数据结构没关系)
我们知道,继承的作用是子类继承父类的成员函数,进而达到少写函数的目的。这里有一个前提:那就是子类想要省略写的函数必须是跟父类一模一样的(函数名,函数体,函数功能)。
这里举一个例子:猫类和狗类继承动物类,猫可以叫,狗也可以叫,但是这两个动物的叫法不一样,也就是说同一个函数名但是函数体不一样。因此,猫类和狗类继承动物类就没有意义,因为动物类没法写一个函数,可以让猫类和狗类同时复用。但是,动物类可以定义一个接口(只有函数名,没有函数体),这样猫类和狗类就可以自己自定义地实现动物类的接口。
讲这个故事的目的是什么呢?多个子类如果想实现同样的功能,但是不同的内部实现,那只需要继承一个接口类即可,在C++中使用抽象类(Abstract Class)来定义接口规范。
接口类只声明接口,不实现,类似于这种:Java中定义接口,用的是interface 关键字。
public interface List<Type> {
void clear();
int size();
boolean isEmpty();
void append(Type element);
void add(int index,Type element);
boolean contains(Type element);
Type get(int index);
Type remove(int index);
int indexOf(Type element);
Type set(int index, Type element);
}
如果子类要实现接口类,那就意味着该子类必须将接口类里的所有接口全部实现,少实现一个都会报错。Java中,实现接口用implements关键字。
public class subClass<Type> implements List<Type> {
//必须全部实现,少实现一个,都会报错
}
如果想要不实现接口类的全部接口还不报错,那就需要将该类设置为抽象类,然后需要有该抽象类的子类去替抽象类实现没有全部实现的接口。 这样的功能有什么应用场景吗?
public abstract class AbstractClass<Type> implements List<Type> {
//可以部分实现
}
public class subClass<Type> extends AbstractClass<Type> {
//但是要实现抽象类没有实现的剩余全部接口,少实现一个,也会报错
}
结合本例说明场景:动态数组和链表接口是完全一样的,也就是说函数名完全一样。但是,部分接口的实现是不同的,比如get()函数,动态数组和链表的内部实现明显不一样。然后呢,也有一部分是相同的,比如size()函数,都是返回size,显然动态数组和链表不仅接口相同,内部实现也相同。
在这种情况下,声明一个接口类List将所有的接口都声明出来,然后声明一个抽象类去实现这个接口类(只实现动态数组和链表完全一样的函数,把接口相同但是函数体不同的,分别交给动态数组和链表自己去实现)
- 接口类,只声明函数,不实现,Java用
public interface 类名来定义接口类。
/**
* 接口类:interface
* 接口只定义函数本身,不需要实现,且不用public修饰
* @param
*/
public interface List<Type> {
static final int ELEMENT_NOT_FOUND = -1; //将ELEMENT_NOT_FOUND放在这里,为的就是供外界访问
/**
* 清除所有元素
*/
void clear();
/**
* 查看list元素的数量
* @return
*/
int size();
/**
* 判断list是否为空
* @return
*/
boolean isEmpty();
/**
* 添加元素到list尾部
* @param element
*/
void append(Type element);
/**
* 向指定索引处插入元素
* @param index
* @param element
*/
void add(int index,Type element);
/**
* 查看元素是否在list中
* @param element
* @return
*/
boolean contains(Type element);
/**
* 获得list某索引处的元素
* @param index
* @return
*/
Type get(int index);
/**
* 删除索引处的元素,后面的元素向前移
* @param index
*/
Type remove(int index);
/**
* 给定元素,返回在list中的位置
* @param element
* @return
*/
int indexOf(Type element);
/**
* 设置某index处的节点元素值
* @param index
* @param element
* @return
*/
Type set(int index, Type element);
}
- 抽象类,实现部分接口(这部分接口,对于动态数组和链表来说,函数名和函数体都一模一样),由于是
public abstract class 类名,所以可以不全部实现接口类List。但是,没有被实现的,需要在继承抽象类的子类里全部实现。 - 如下函数,判断越界函数
rangeCheck(int index),返回size函数size(),判断是否为空isEmpty()函数等,显然动态数组和链表的实现可以相同,因此放在抽象父类里,当做公共的可复用的代码,节省了两个子类都书写的繁琐。
/**
* 抽象类,用来存放子类公共的函数代码,然后实现子类都要重写的接口类List
* 两个子类,所实现的接口相同,但是接口里的实现不同,同时还有一些接口的实现是相同的。
* 设计是:两个子类继承一个抽象类,抽象类实现接口,抽象类里存放实现相同的接口,可以避免两个子类中重复书写相同实现的接口
* 如果不设置为抽象类,就必须全部实现接口。反之,可以只实现部分接口,即子类中相同实现的接口;那些没有在抽象类中实现的接口(即非公共部分),子类则必须实现
* 因为该抽象类就是为了派生子类的,所以多数都要protected
* @param
*/
public abstract class AbstractList<Type> implements List<Type> {
protected int size; //链表/动态数组 元素的个数
/**
* 当索引越界时,抛出异常。因为只用在此类中,所以设置为private
* @param index
*/
private void outOfBounds(int index){
throw new IndexOutOfBoundsException("Index"+index+", Size:"+size);
}
/**
* 索引边界检查,当index<0或者index >= size,表明传入的索引不正确,就会调用outOfBounds函数抛出异常。
* @param index
*/
protected void rangeCheck(int index){
if (index < 0 || index >= size){
outOfBounds(index);
}
}
/**
* append函数的索引越界检查,与普通的访问index不同,这里的index可以等于size
* @param index
*/
protected void rangeCheckForAppend(int index){
if (index < 0 || index > size){
outOfBounds(index);
}
}
/**
* 返回当前链表的长度
* @return
*/
@Override
public int size() {
return size;
}
/**
* 用来判断链表是否为空
* @return bool值,size如果等于0,说明链表为空,那就返回true,否则返回false
*/
@Override
public boolean isEmpty() {
return size == 0;
}
/**
* 向链表的最后面插入一个节点
* @param element
*/
@Override
public void append(Type element) {
add(size,element);//调用与之重载的函数,实现向List最后一处添加元素
}
/**
* 判断某个元素是否在链表当中
* @param element
* @return bool值,
*/
@Override
public boolean contains(Type element) {
return indexOf(element) != ELEMENT_NOT_FOUND; //通过查找元素的索引,判断该元素在不在链表中
}
}
- 链表子类
LinkedList,需要继承抽象类,既可以复用抽象类里的代码,还可以实现父类实现的接口类里的接口。Java里继承用extends关键字。
/**
* 链表的设计,继承AbstractList
* 以后使用链表时,一定多进行边界测试
*/
public class LinkedList<Type> extends AbstractList<Type> {
private Node<Type> HeadNode; //链表第一个节点,首节点
/**
* 清空链表,即将指向链表的指针清空,后面的链表会一一断开
*/
@Override
public void clear() {
size = 0;
HeadNode = null;
}
/**
* 向指定index处插入一个节点,比如向1处插入一个节点,原来的1就变成了2,原来的0还是0
* Node.next指向的是整个节点,而不是指向的节点里的element或者next
* @param index
* @param element
*/
@Override
public void add(int index, Type element) {
if(index==0) {
HeadNode = new Node<>(element,HeadNode);//新节点首先指向原来的HeadNode,然后将HeadNode指向此时的首节点(也就是新创建的节点)
}
else {
Node<Type> prevNode = node(index-1); //获取index-1处的节点
Node<Type> newNode = new Node<>(element,prevNode.next);//新节点先指向index处的节点,prevNode.next是index处节点
prevNode.next = newNode; //然后让prevNode指向newNode,然后就自动断开了和原本index处的连接
}
size++;//链表长度++
}
/**
* 获取index处节点的元素值
* @param index
* @return
*/
@Override
public Type get(int index) {
return node(index).element;
}
/**
* 设置某index处的值,并返回以前的值
* @param index 要设置节点的index
* @param element 要设置的值
* @return 原先节点的element
*/
@Override
public Type set(int index, Type element) {
Type oldElement = node(index).element;
node(index).element = element;//覆盖点以前的element
return oldElement;
}
/**
* 删除指定index处的节点
* @param index
*/
@Override
public Type remove(int index) {
Node<Type> oldNode = node(index);
if(index==0){
HeadNode = node(index+1);
}
else{
if(index==size-1){
Node<Type> prevNode = node(index-1); //取出前一个节点
prevNode.next = null;
}else {
Node<Type> prevNode = node(index-1); //取出前一个节点
prevNode.next = node(index+1); //前一个节点指向下一个节点,即前一个节点不指向当前index节点,那么当前节点就自动销毁了
}
}
size--;
return oldNode.element;
}
/**
* 返回链表中某个元素的链表索引
* @param element
* @return
*/
@Override
public int indexOf(Type element) {
if(element==null){
for (int i = 0; i < size ; i++) {
if(node(i).element == null) return i;
}
}else {
for (int i = 0; i < size ; i++) {
if(node(i).element == element) return i;
}
}
return ELEMENT_NOT_FOUND;
}
@Override
public String toString() {
StringBuilder string = new StringBuilder(); //字符串拼接建议使用StringBuilder,效率会很高
string.append("size = ").append(size).append(", [");
for (int i = 0; i < size; i++) {
string.append(node(i).element);
if(i != size-1){
string.append(", ");
}
}
string.append("]");
return string.toString(); //因为StringBuilder不是String,而这里需要返回的是String
}
/**
* 返回index处的节点
* @param index 传进去的索引
* @return 返回一个Node对象
*/
private Node<Type> node(int index){
rangeCheck(index);
Node<Type> node = HeadNode; //将node定义为链表的头节点
for (int i = 0; i < index; i++) {
node = node.next;//循环index次,直到node是index处的节点
}
return node;
}
/**
* 链表的内部类(要定义成static类型,既然是内部类那就是private),Type是泛型
* @param
*/
private static class Node<Type>{
Type element; //节点中的元素
Node<Type> next; //指向下一节点的“指针”,但是java没有指针的概念
/**
* 节点构造函数
* @param element 元素
* @param next 指向下一个节点的指针
*/
public Node(Type element, Node<Type> next) {
this.element = element;
this.next = next;
}
}
}
- 动态数组子类
DynamicArray(不是本节考察重点),需要继承抽象类,既可以复用抽象类里的代码,还可以实现接口类里的接口。可以看出,对于没有被在抽象类里实现的接口,动态数组和链表的内部实现是不同的。
/**
* 动态数组,继承自AbstractList
* @param
*/
public class DynamicArray<Type> extends AbstractList<Type> {
private Type[] ArrayPointer; //指向int数组的指针
private static final int DEFAULT_CAPACITY = 5; //数组默认容量,final = const
private int CurrentCapacity; //当前数组的容量
/**
* @param capacity 指定数组容量
* 有参构造函数:创建数组,并且初始化
*/
public DynamicArray(int capacity){
capacity = (capacity < DEFAULT_CAPACITY)?DEFAULT_CAPACITY:capacity;
ArrayPointer = (Type[]) new Object[capacity]; //所有类都继承Object类,因此java的泛型实现需要在new空间时,new Object[],并且强转类型
CurrentCapacity = capacity;
}
/**
* 无参构造函数,初始化数组,默认容量
*/
public DynamicArray(){
this(DEFAULT_CAPACITY); //构造函数互相调用,使用this指针即可
}
@Override
public void clear() {
size=0;
}
@Override
public void add(int index, Type element) {
rangeCheckForAppend(index);
if(size >= CurrentCapacity){ //如果当前数组的数据长度大于等于当前容量,就得扩容
ensureCapacity(size+1); //确保最少有size+1的容量,扩容
for (int i = size; i > index ; i--) { //从最后面开始挪动,然后把index的位置空出来
ArrayPointer[i] = ArrayPointer[i-1]; //前一个覆盖到后一个,就是由前向后挪动的feel
}
ArrayPointer[index] = element;//将元素放在空出来的index处
}
else {
for (int i = size; i > index ; i--) {
ArrayPointer[i] = ArrayPointer[i-1];
}
ArrayPointer[index] = element;
}
size++;//更新数据个数
}
@Override
public boolean contains(Type element) {
return indexOf(element) != ELEMENT_NOT_FOUND;
}
/**
* 打印字符串需要重写的toString方法
* @return
*/
@Override
public String toString() {
StringBuilder string = new StringBuilder(); //字符串拼接建议使用StringBuilder,效率会很高
string.append("size = ").append(size).append(", [");
for (int i = 0; i < size; i++) {
string.append(ArrayPointer[i]);
if(i != size-1){
string.append(", ");
}
}
string.append("]");
return string.toString(); //因为StringBuilder不是String,而这里需要返回的是String
}
/**
* 获得指定索引处的值
* @param index
* @return 数组中的值
*/
public Type get(int index){
if(index<0 || index>=size){
throw new IndexOutOfBoundsException("Index out of range->"+"Index:"+index+", size:"+size);
}
return ArrayPointer[index];
}
/**
* 删除索引处的元素,后面的向前移动
* @param index
* @return 返回删除的元素值
*/
@Override
public Type remove(int index) {
rangeCheck(index);
Type oldElement = ArrayPointer[index];
for (int i = index+1; i < size ; i++) {
ArrayPointer[i - 1] = ArrayPointer[i];
}
ArrayPointer[size - 1] = null; //把最后一位置空
size--; //然后数组数量减少一个
// ArrayPointer[--size] = null; //这一句代码和上面代码功能相同
cutCapacity(); //每次remove元素的时候,就要进行动态缩容操作
return oldElement;
}
@Override
public int indexOf(Type element) {
return 0;
}
@Override
public Type set(int index, Type element) {
return null;
}
/**
* 保证扩容之后的容量要够用
* @param capacity 想要保证的最小容量
*/
private void ensureCapacity(int capacity){
int oldCapacity = ArrayPointer.length;
if (oldCapacity >= capacity) return; //如果数组的容量大于目前我想要的最小容量,说明不需要扩容
int newCapacity = oldCapacity + (oldCapacity >> 1); //扩充1.5倍,为什么不直接乘1.5?因为浮点数运算更慢,>>1表示一个数除以2,这种效率更高
Type[] newArrayPointer = (Type[]) new Object[newCapacity]; //新申请一块更大的存储空间,用于存放数组元素
for (int i = 0;i<size;i++){
//把原来数组的元素,放到新的存储空间
newArrayPointer[i] = ArrayPointer[i];
}
ArrayPointer = newArrayPointer;
CurrentCapacity = newCapacity;
System.out.println("扩容:"+"oldCapacity:"+oldCapacity+" -> newCapacity:"+newCapacity);
}
/**
* 动态数组的动态缩容技术
* 应用场景:当数组被扩容后,又remove了一些,但是原本的容量就闲置了下来,如果此时项目的内存比较紧张,那就要考虑将闲置的内存缩掉
* 技术实施:创建一个更小的内存空间,将原本大空间里面的少量元素移动到更小的内存空间完成索缩容
*/
private void cutCapacity(){
int oldCapacity = ArrayPointer.length; //现在数组的容量,即数组指针ArrayPointer指向的内存空间大小
int newCapacity = oldCapacity >> 1; //期待缩容后的数组容量
// 如果当前数组内的元素个数大于我期待缩容后的容量,就说明不能缩容,因为缩容后的内存空间装不下原本的数据
// 或者,现在的数组容量就是原本默认的容量,也没必要缩,即使存在浪费。因为缩的太狠,将来再需要扩容的时候,是很有开销的
**加粗样式** if(size > newCapacity || oldCapacity <= DEFAULT_CAPACITY) return;
//具体缩容细节(程序执行到这,说明剩余空间还有很多)
Type[] newArrayPointer = (Type[]) new Object[newCapacity]; // 申请一块新的存储空间,容量为newCapacity
for (int i = 0; i < size ; i++) {
// 将原本存储空间的元素移动到新的存储空间
newArrayPointer[i] = ArrayPointer[i];
}
ArrayPointer = newArrayPointer; //将新的数组指针赋值给ArrayPointer,即指向新内存的仍是我们的成员变量ArrayPointer
System.out.println("缩容:"+"oldCapacity:"+oldCapacity+" -> newCapacity:"+newCapacity);
}
}
这一节,仅仅介绍编码规范的问题。链表的具体实现,将在下一节讲解。
链表类的设计
链表类内部的设计要考虑链表的特性。比如,链表需要有size,即几个元素在链表中;还要有指向链表的指针,就类似于数组名,数组本身,但本质上是一个地址。因为要指向头结点,这里就需要声明一个指针HeadNode指向头结点。

- 链表类首先是以节点类作为基础的,因此,在链表类的内部要创建一个内部类:
Node类。Java创建内部类,直接写在外部类的里面,并用static修饰。 - Node类里面的成员变量有两个:节点内存储的元素本身
element,以及指向下一个节点的地址next。 - 因为创建节点,就是创建Node对象,那么就会调用Node的构造函数。因此,还要声明Node类的构造函数。
Node构造函数的参数是element和next,即我要创建节点时,需要指定节点内部存储什么元素,以及指向下一个节点。(C/C++中用结构体struct做这个事最简便)
/**
* 链表的设计,继承AbstractList
* 以后使用链表时,一定多进行边界测试
*/
public class LinkedList<Type> {
private int size;
private Node<Type> HeadNode; //链表第一个节点,首节点
/**
* 链表的内部类(要定义成static类型,既然是内部类那就是private),Type是泛型
* @param
*/
private static class Node<Type>{
Type element; //节点中的元素
Node<Type> next; //指向下一节点的“指针”,但是java没有指针的概念
/**
* 节点构造函数
* @param element 元素
* @param next 指向下一个节点的指针
*/
public Node(Type element, Node<Type> next) {
this.element = element;
this.next = next;
}
}
}
这样的话,一个链表类的空壳子就设计完整了,所需要的属性也都完备了。至于链表可以有什么功能,那就是接口设计的事了。
链表接口的设计
既然我们要学习数据结构的本质,那就需要自己设计链表的接口,进而实现与官方链表功能一样的链表类。接下来,我们要设计链表的核心接口了
- 调用
clear()函数,清空链表内的所有节点。清空所有节点即释放所有节点的内存空间。首先size=0无需质疑,但是只处理size=0貌似不合理。因为链表是随创建节点随开辟内存,因此清空的话必须要把内存空间也清空,逻辑清空适用于数组但是不适用于链表。那怎么能物理清空呢?答案很简单,只需要把指向头结点的指针清空,即链表指针指向null即可

把链表类中指向头结点的指针清空,也就意味着没有指针指向0号节点,那么0-Node就会消失,那么又0-Node指向1-Node的指针就会断掉,紧接着1-Node也会消失,以此类推,全部消失(即每个Node里的next不需要设置为null,没必要)。达到了物理清空的目的。

/**
* 清空链表,即将指向链表的指针清空,后面的链表会一一断开
*/
@Override
public void clear() {
size = 0;
HeadNode = null;
}
- 调用
add(int index, Type element)函数,向指定索引处插入节点。也就意味着,索引处的节点变成新节点,而原来的索引及其以后的节点都要向后移动一位。具体做法就是:先让新节点指向原来索引处的节点,然后再让index-1处的节点断开原来的指向,指向新的节点。就是实现了插入的操作。(注意:必须是新节点先指向index处的节点,然后index-1处的节点再指向新节点)
例如:想在index = 1处插入,就要先找到0处的节点

让新节点指向index = 1处的节点

index - 1 = 0处的节点再指向新的节点
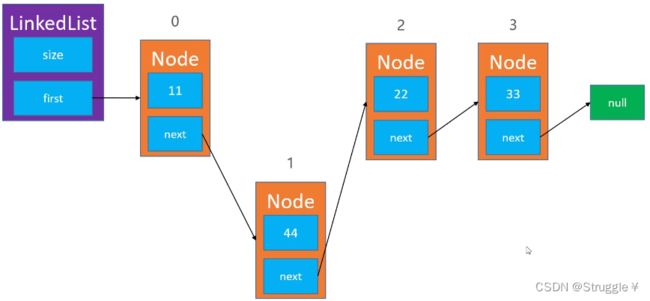
但是要注意一种边界情况:向index=0处添加节点,也就是新节点要充当头结点。思路就是:新节点先指向原来的头结点(这一步可以在创建新节点时完成:new Node<>(element,HeadNode)),然后头节点指针再指向新节点即可HeadNode = new Node<>(element,HeadNode)。要理解头结点HeadNode这个变量,可以当做真实链表中的成员,也可以是链表类的成员,可以充当两种角色。就跟数组名一样,既可以代表整个数组,也可以代表数组首元素。
为什么要额外处理index=0时候的添加?因为,我们在向index处添加元素的时候,需要用到index-1处的节点。假如index=0,那么index-1就等于-1,这显然是越界行为,这是不被允许的。
/**
* 向指定index处插入一个节点,比如向1处插入一个节点,原来的1就变成了2,原来的0还是0
* Node.next指向的是整个节点,而不是指向的节点里的element或者next
* @param index
* @param element
*/
@Override
public void add(int index, Type element) {
if(index==0) {
HeadNode = new Node<>(element,HeadNode);//新节点首先指向原来的HeadNode,然后将HeadNode指向此时的首节点(也就是新创建的节点)
//下面两行代码跟上面一行代码效果一样
Node<Type> newnode = new Node<>(element,HeadNode);
newnode = HeadNode;
}
else {
Node<Type> prevNode = node(index-1); //获取index-1处的节点
Node<Type> newNode = new Node<>(element,prevNode.next);//新节点先指向index处的节点,prevNode.next是index处节点
prevNode.next = newNode; //然后让prevNode指向newNode,然后就自动断开了和原本index处的连接
}
size++;//链表长度++
}
获得某一个index处的节点,必须要从头开始遍历,直到遍历到index处,把节点取出来。就是这么暴力。传index进函数,遍历的范围从0到index-1,所以循环是这样for (int i = 0; i < index; i++),最后到index-1时,直接返回node.next,其实就是index处的节点。
/**
* 返回index处的节点
* @param index 传进去的索引
* @return 返回一个Node对象
*/
private Node<Type> node(int index){
rangeCheck(index);
Node<Type> node = HeadNode; //将node定义为链表的头节点
for (int i = 0; i < index; i++) {
node = node.next;//循环index次,直到node是index处的节点
}
return node;
}
- 调用
get(int index)函数,获取节点内的元素值(对于链表来说,节点的值默认就是节点内的元素值)。因为我们已经可以根据索引获得相应的节点对象了,所以取值易如反掌。
/**
* 获取index处节点的元素值
* @param index
* @return
*/
@Override
public Type get(int index) {
return node(index).element;
}
- 调用
set(int index, Type element)函数,设置某一index处的节点的元素值,即把原来的元素值改为我设置的值。顺便返回原先的值(根据需求自行添加)。
/**
* 设置某index处的值,并返回以前的值
* @param index 要设置节点的index
* @param element 要设置的值
* @return 原先节点的element
*/
@Override
public Type set(int index, Type element) {
Type oldElement = node(index).element;
node(index).element = element;//覆盖点以前的element
return oldElement;
}
- 调用
remove(int index)函数,删除指定索引处的节点。只需要让index-1处的节点指向index+1处的节点即可,这样index处的节点就自动销毁了。别忘了,链表的成员变量size需要减一
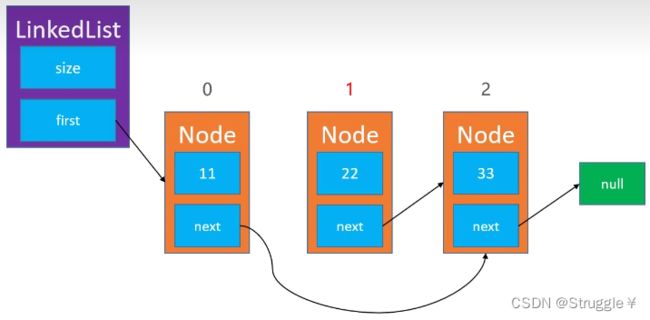
这里有需要注意的两点:
1、删除的元素是头结点怎么办?答:那就让头结点指针指向index+1处的节点即可
2、删除的元素是尾结点怎么办?答:那就让index-1处的节点指向null即可
想想为什么要单独处理头结点和尾结点啊?因为我们在删除index处的节点是,要用到index-1处的节点和index+1的节点。如果是头结点,说明index=0,那么index-1就等于-1了;如何是尾结点,说明index=size-1,那么index+1就等于size了。这都是属于越界行为,因此要单独拿出来处理。
总结:什么时候需要考虑链表的边界处理呢?那就看我们在进行链表操作的时候,是否用到前一个节点和后一个节点。如果用到前一个节点,就需要额外考虑链表的头结点情况;如果要用到后一个节点,那就需要额外考虑链表的尾结点情况了。
/**
* 删除指定index处的节点,返回原有的值(需求自己定)
* @param index
*/
@Override
public Type remove(int index) {
Node<Type> oldNode = node(index);
if(index==0){
HeadNode = oldNode.next;//如果用node(index+1),是有BUG的,当链表只剩一个元素时,node(index+1)访问不到。
}
else{
if(index==size-1){
Node<Type> prevNode = node(index-1); //取出前一个节点
prevNode.next = null;
}else {
Node<Type> prevNode = node(index-1); //取出前一个节点
prevNode.next = node(index+1); //前一个节点指向下一个节点,即前一个节点不指向当前index节点,那么当前节点就自动销毁了
}
}
size--;
return oldNode.element;
}
- 调用
indexOf(Type element)函数,返回某元素在链表中的节点索引,如果没找到,就返回-1。为什么要有if(element==null)呢?因为,我们希望链表某个节点可以存储null值。
/**
* 返回链表中某个元素的链表索引
* @param element
* @return
*/
@Override
public int indexOf(Type element) {
if(element==null){
for (int i = 0; i < size ; i++) {
if(node(i).element == null) return i;
}
}else {
for (int i = 0; i < size ; i++) {
if(node(i).element == element) return i;
}
}
return ELEMENT_NOT_FOUND;
}
- 实现
String toString()方法,可以使用println打印链表。下面是实现过程:
1、打印链表和打印数组一样,本质都是字符串的拼接操作,因此要使用Java中的StringBuilder()声明一个字符串拼接对象
2、拼接某个字符串,只需要调用StringBuilder()的append方法
3、然后就是有策略地循环append(node(i).element)
4、为了呈现size = 4, [10, 20, 30, 40]这样的效果,需要拼接一个数的后面拼接一个逗号‘,’,但是在最后一个数的后面不用拼接,最后的最后别忘了中括号‘]’回来
@Override
public String toString() {
StringBuilder string = new StringBuilder(); //字符串拼接建议使用StringBuilder,效率会很高
string.append("size = ").append(size).append(", [");
for (int i = 0; i < size; i++) {
string.append(node(i).element);
if(i != size-1){
string.append(", ");
}
}
string.append("]");
return string.toString(); //因为StringBuilder不是String,而这里需要返回的是String
}
- 测试链表demo
public class Main {
public static void main(String[] args) {
// List是java中的接口,类似于C++中的接口父类,可以指向子类对象
List<Integer> list2 = new LinkedList<>();
list2.append(20); //向尾部添加20
list2.add(0,10);//向index = 0处添加10
list2.append(30);//向尾部添加30
list2.add(list2.size(),40); //向尾部添加40
System.out.println(list2); //打印当前的链表
System.out.println(list2.indexOf(30)); //查看30在链表中的节点索引
list2.set(2,300); //设置index=2处的是为300
System.out.println(list2); //再次打印
System.out.println(list2.get(2));//打印index=2的值
list2.remove(1); //删除index=1处的值
System.out.println(list2);//再次打印
}
}
控制台输出结果:
 可以看到,我们实现了添加元素到末尾,添加元素在链表的任何一个位置,查看某个元素在链表中的索引,移除某个节点等关键功能。至此链表的设计全部完成!接下来我们将学习链表的进阶知识。
可以看到,我们实现了添加元素到末尾,添加元素在链表的任何一个位置,查看某个元素在链表中的索引,移除某个节点等关键功能。至此链表的设计全部完成!接下来我们将学习链表的进阶知识。
链表的练习题
删除节点
学习完链表之后,我们删除某个index处的节点很简单,只需要让index-1处的节点指向index+1处的节点,index处的节点就会自动消失,但这依赖于给定index的前提下。
但是,这个题目的要求是:无法访问头结点,同时只给出待删除的节点,并没有给索引。因此,无法根据index删除,因为无法访问头结点,因此indexOf也无法使用。总之,这个题无法根据index删除。需要尝试别的方法
因此,这里需要技巧了。既然是删除某个节点(删除节点就是删除对于的值,链表的本质还是存储数据线性表),那我们只需要让那个值不存在链表中就好了。

所以,我们先用这个节点下一个节点的值覆盖掉该节点的值(因为我们可以使用node.next访问下一个节点)

覆盖掉之后,让该节点指向下一个的下一个节点(可能为NULL,不需要额外处理,因为节点是可以指向NULL的)
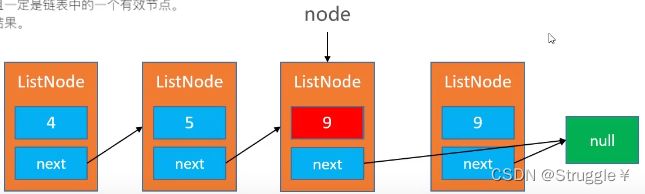
那么该节点的下一个节点就消失了。从逻辑上,好像是把原来的节点删除了一样。
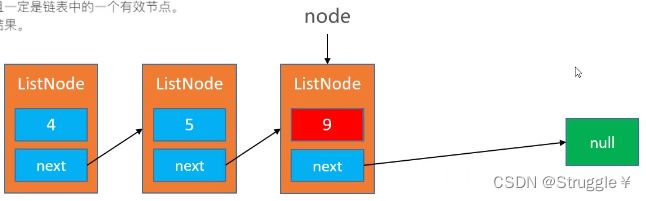
力扣链接
public class _237_删除链表中的节点 {
public static class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
}
}
public void deleteNode(ListNode node) {
node.val = node.next.val; //把该节点的值用后面的一个节点值覆盖掉
node.next = node.next.next; //然后再让该节点指向后面节点的后面节点,就会把后面的节点删除,因为后的值已经覆盖到本节点了,所以结果就像删除了该节点一样
}
}
这道小练习给我们的启示是:要充分利用node可以访问的东西,不要固化思维(因为有的时候,不让你用链表的头结点指针)。
反转链表
这道题的要求是:只给定头结点,将链表翻转回来。即这个函数ListNode reverseList(ListNode head)的功能如下图所示:
 既然知道了函数的功能(输入是头结点所指向的链表,输出是新的头结点指向的翻转链表(一直指向翻转前的头结点,然后再指向
既然知道了函数的功能(输入是头结点所指向的链表,输出是新的头结点指向的翻转链表(一直指向翻转前的头结点,然后再指向null))
那我们输入的如果是head.next,输出的新节点指向的是一个怎样的链表呢?应该是下图所示的链表:(因为,reverseList(ListNode head) 函数的功能就是把输入参数到末尾翻转一下,然后让newHead指向头结点)
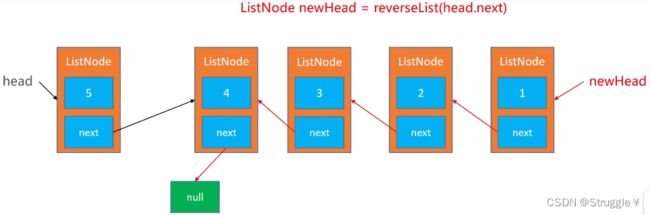
既然我们得到了这一一个链表,那我们只需要把4和5节点额外处理一下就行了,剩下的就交给递归去做。
所以,我们只需要让4节点(head.next)指向5节点,然后让5节点(head)指向null,就完成了翻转)。
但是,递归是需要边界条件的,要不然就陷入死循环了。那这道题的边界条件怎么确定呢?
递归边界条件确定的原则:不断地缩小问题规模,直至遇到边界
对应此题:我们不断地head.next去缩小问题规模,但是head不可能一直next。如果head.next=NULL了,说明就剩一个节点了,那直接返回这个节点就行了。如果链表本身就是NULL的,那也无需翻转,直接返回NULL即可。
力扣链接
这里给出了Java和C++两种版本的解题答案
public class _206_反转链表 {
public class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
/**
* 递归的思想:首先搞清楚这个函数的功能,即输入的啥,输出的又是啥。然后把输入+1或者-1,输出又是啥,直到输入不能-1或者不能+1了,就是递归的结束条件
* 递归的诀窍:考虑清楚函数的功能
* 设计递归的步骤:
* 1、递归函数定义;要知道函数的功能是什么,输入参数是什么,返回的是什么
* 2、基础情况处理;即结束条件的确定,要考虑判断当前数据规模足够小时,且答案显而易见时,直接将返回值写死
* 3、递归调用阶段;我们每次让数据规模减少一点,并且调用递归函数,这样便可以获得较小问题规模的答案,虽然不是显而易见,但是我们知道这就是较小规模的答案就足够了
* 4、递推到当前层;我们通过将上一层的答案简单递推,将最终结果地推出来,虽然不是显而易见的答案,但是我们知道这就是最终答案,并作为该函数的最终返回值
* @param head
* @return
*/
public ListNode reverseList(ListNode head) {
// 这是递归结束条件,也就是该问题最基础的情况处理
if(head == null || head.next == null){
return head;
}
//递归调用阶段,将数据规模减少
ListNode newNode = reverseList(head.next);
// 递推到当前层,将输入参数为head.next时的最终结果表示出来
head.next.next = head; //head.next是节点,节点.next是让节点指向。。。
head.next = null;//用head指向null,这个head可不一定是最开始的,可能head已经变成了1了
return newNode;
}
}
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if(head == nullptr) return nullptr;
if(head->next == nullptr) return head;
ListNode *newHead = reverseList(head->next);
head->next->next = head;
head->next = nullptr;
return newHead;
}
};
如果不用递归,只允许用迭代,能否实现呢?
这题唯一的输入就是head,因此,我们只能且必须用head去一个一个翻转节点。具体步骤就是:
1、先把head.next节点保住,因此要一个临时节点指针tmp指向这里
2、把head指针指向原来的head.next节点的那条线断开,去指向null,也就是newHead节点
3、然后让newHead指针指向这个新来的,即当前的head节点
4、然后当前的head指针指向原来的head.next(这里已经是tmp了)充当新的head节点
(注意,我一会是head指针,一会是head节点,要理解。A指向B,A就是指针,B就是节点)
1、临时节点指针指向head.next,保住

2、head节点指针newHead节点,newHead指针指向head
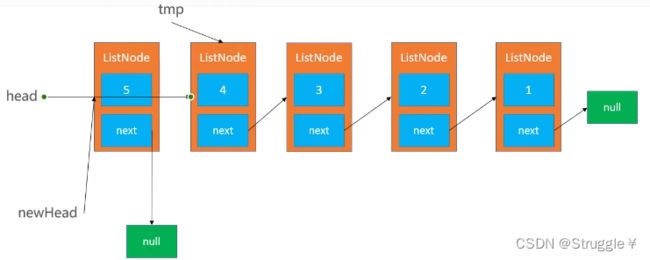
3、新一轮,tmp继续指向head.next,然后重复操作

4、直到jhead=null了,那么tmp也就没法继续指向head.next,循环就得结束
这里仍然给出两种语言的答案。注意:背题解没有,重要的是解决问题的角度:只能用head,那就只能不断地从head处翻转。以及程序的理解:链表题中赋值语句等号的左右两边要理解其物理意义,一个是指针,一个是节点。虽然,本质都是地址指针,但是不要这么想。
/**
* 迭代法翻转链表
* 思路的前提,我们只能利用head这一个节点
* @param head
* @return
*/
public ListNode reverseList2(ListNode head) {
//一个节点或者没有节点,就直接返回,无需翻转
if(head == null || head.next == null){
return head;
}
ListNode newNode = null; //声明一个newNode指向null
//首先明确我们只能利用head这一个节点做事
while (head != null){
ListNode tempNode = head.next; //备份head.next,因为下面head.next换节点了
head.next = newNode; //首先head的next指向newNode
newNode = head; //然后,newNode作为新链表的head
head = tempNode; //然后将原链表的head向后移动一位
}
//直到head指向了null,说明5 4 3 2 1都翻转完了,因为之前newNode就是null,所以,整个翻转过程也就结束了
return newNode;
}
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if(head == nullptr) return nullptr;
if(head->next == nullptr) return head;
ListNode *newHead = nullptr;
ListNode *tempNode = nullptr;
while(head != nullptr){
//没翻转之前就要先用一个临时指针指向head.next,要不然这个节点该消失了
tempNode = head->next; //临时节点指向head-next,避免下一步消失
head->next = newHead;
newHead = head;
head = tempNode;
}
return newHead;
}
};
PS:当赋值语句的左边是指针时,表示的是这个指针指向右边的东西,不要理解成普通的赋值操作。最重要的来了:对于链表的题来说,等式右边的统统都要想象成节点本身。
环形链表
判断一个链表是不是环形链表。如下图所示,就叫环形链表。


思路就是:定义一对快慢指针。让快指针每次移动两步,慢指针每次移动一步。如果有环,快慢指针一定会相遇在某一时刻。如果没环,快指针一定会指向NULL。

解释一下关键程序:
1、if(head == NULL || head->next == NULL) return false;意味着,如果没有节点或者只有一个节点,那一定没有环。
2、ListNode *fast_er = head->next开始先定义快指针领先慢指针一步,要不然下面判断快慢指针相遇就没法判断了。如果快指针和慢指针开始都指向head,那就直接算相遇了。
3、while(fast_er != NULL && fast_er->next != NULL)判断快指针是否指向NULL不就行了?为什么还要判断fast_er->next 是否指向NULL呢?因为快指针每次移动两步,所以走一步就要判断一下是否指向了NULL。(可能链表中就两个节点且没环,快指针初始就在最后一个,如果不判断fast_er->next != NULL,那就会进入循环里,当fast_er->next->next时就会发生链表越界的行为,会指向一个既不是节点也不是null的地方,程序也会报错。)
class Solution {
public:
bool hasCycle(ListNode *head) {
if(head == NULL || head->next == NULL) return false;
ListNode *slow_er = head;
ListNode *fast_er = head->next;
while(fast_er != NULL && fast_er->next != NULL){
if(slow_er == fast_er){
return true;
}
slow_er = slow_er->next;
fast_er = fast_er->next->next;
}
return false;
}
};
Java版本的
/**
* 判断一个链表里是否有环,即是否存在环形链表
* 通过一个快慢指针来实现这件事。什么叫快慢指针呢?即有两个指针,分布指向链表的第一个节点和第二个节点。指向第一个节点的是慢指针,一次只向后移动1位;指向第二个节点的是
* 快指针,一次向后移动两位。如果链表中节点大于等于2个,且存在环,快慢指针在移动的过程中一定会相遇,即指向同一个节点;如果不存在环,那么快指针一定先指向null
* @param head
* @return
*/
public boolean hasCycle(ListNode head) {
if(head == null || head.next == null){
// 如果链表为空,或者只有一个节点,那指定没有环
return false;
}
ListNode slowNodePointer = head; //慢指针,指向第一个节点
ListNode fasterNodePointer = head.next; //快指针,指向第二个节点
while (fasterNodePointer != null && fasterNodePointer.next != null){
// 因为快指针一次移动两步,所以要考虑两种情况,一个是直接能移动到链表的最后一位,那说明下一次就是null,但快指针却要移动两次,这明显指向了一段不被初始化的空间,会报错的
// 所以当快指针移动到最后一个节点的时候,就判断next是不是null,如果是,那说明没有环,如果不是那才说明有环
slowNodePointer = slowNodePointer.next; //慢指针移动一位
fasterNodePointer = fasterNodePointer.next.next; //快指针移动两位
if (slowNodePointer == fasterNodePointer){
//相遇就说明有环
return true;
}
}
//能到这,说明不满足 fasterNodePointer != null, fasterNodePointer.next != null的其中一个,就说明无环
return false;
}
双向链表(Double Linked List)
上面说的链表,都是最普通的链表,也就是单向链表。也就是说,每一个Node只能指向同一方向,即指向next Node。
接下来介绍的是双向链表,即每一个Node既可以指向next Node,也可以指向prev Node。
对比单向链表,双向链表每个节点Node的内部多了一个prev指针,用来指向上一个Node。

为什么要设计一个双向链表呢?
因为我们之前想要获得链表中任何一个节点的值,都需要从头结点开始一个一个的往后找。一旦有了双向链表,我们就可以从两个方向去找。(例子:如果找的是比较靠近后面的元素,那就可以从尾部开始找;如果找的是比较靠前的元素,那就从头部开始找;这样做会大大提高链表的查找效率)

那么链表类里,就得再添加一个尾结点指针了。所以,新的链表类,应该这样设计:
public class DoubleLinkedList<Type> extends AbstractList<Type> {
private Node<Type> HeadNode; //链表第一个节点,首节点
private Node<Type> TailNode; //链表最后一个节点,尾节点
/**
* 返回index处的节点
* @param index 传进去的索引
* @return 返回一个Node对象
*/
private Node<Type> node(int index){
rangeCheck(index);
if(index < (size>>1) ){
//如果传进来的index小于链表长度的一半,那就从头开始找
Node<Type> node = HeadNode; //将node定义为链表的头节点
for (int i = 0; i < index; i++) {
node = node.next;//循环index次,直到node是index处的节点
}
return node;
}else {
//如果传进来的index大于链表长度的一半,那就从尾开始找
Node<Type> node = TailNode; //将node定义为链表的尾节点
for (int i = size - 1; i > index; i--) {
node = node.prev;//循环index次,直到node是index处的节点
}
return node;
}
}
/**
* 链表的内部类(要定义成static类型,既然是内部类那就是private),Type是泛型
* @param
*/
private static class Node<Type>{
Type element; //节点中的元素
Node<Type> next; //指向下一节点的“指针”,但是java没有指针的概念
Node<Type> prev; //指向上一节点的“指针”,但是java没有指针的概念,就是引用
/**
* 节点构造函数
* @param element 元素
* @param next 指向下一个节点的指针
* @param prev 指向上一个节点的指针
*/
public Node(Node<Type> prev, Type element, Node<Type> next) {
this.element = element;
this.next = next;
this.prev = prev;
}
}
}
解释这样设计的细节:
1、相比于单向链表,这里多了一个尾结点声明,即该链表是由头结点和尾结点共同确定的。
private Node<Type> HeadNode; //链表第一个节点,首节点
private Node<Type> TailNode; //链表最后一个节点,尾节点
2、节点类,内部多了一个prev指针,因此构造函数也要添加进去
/**
* 链表的内部类(要定义成static类型,既然是内部类那就是private),Type是泛型
* @param
*/
private static class Node<Type>{
Type element; //节点中的元素
Node<Type> next; //指向下一节点的“指针”,但是java没有指针的概念
Node<Type> prev; //指向上一节点的“指针”,但是java没有指针的概念,就是引用
/**
* 节点构造函数
* @param element 元素
* @param next 指向下一个节点的指针
* @param prev 指向上一个节点的指针
*/
public Node(Node<Type> prev, Type element, Node<Type> next) {
this.element = element;
this.next = next;
this.prev = prev;
}
}
3、通过索引index访问链表节点方式的改变,才是双向链表的精髓。(当index在前半区域,就从头结点开始查找;当index在后半部分,就从尾结点开始查找。)
/**
* 返回index处的节点
* @param index 传进去的索引
* @return 返回一个Node对象
*/
private Node<Type> node(int index){
rangeCheck(index);
if(index < (size>>1) ){
//如果传进来的index小于链表长度的一半,那就从头开始找
Node<Type> node = HeadNode; //将node定义为链表的头节点
for (int i = 0; i < index; i++) {
node = node.next;//循环index次,直到node是index处的节点
}
return node;
}else {
//如果传进来的index大于链表长度的一半,那就从尾开始找
Node<Type> node = TailNode; //将node定义为链表的尾节点
for (int i = size - 1; i > index; i--) {
node = node.prev;//循环index次,直到node是index处的节点
}
return node;
}
双向链表的接口设计
- 有些接口跟单向链表一样,比如获取index处节点的元素
get(int index)函数,设置index处节点的元素set(int index, Type element)函数,查看某个元素在链表中的索引indexOf(Type element)函数。想没想过,为什么这些接口可以和单向链表一样呢? - 那是因为这些接口的内部仅仅用到了
node(index)函数,而在node(index)函数里面,我们已经更改了双向链表的查找规则,因此整个函数体看起来跟单向链表一样。
/**
* 获取index处节点的元素值
* @param index
* @return
*/
@Override
public Type get(int index) {
return node(index).element;
}
/**
* 设置某index处的值,并返回以前的值
* @param index 要设置节点的index
* @param element 要设置的值
* @return 原先节点的element
*/
@Override
public Type set(int index, Type element) {
Type oldElement = node(index).element;
node(index).element = element;//覆盖点以前的element
return oldElement;
}
/**
* 返回链表中某个元素的链表索引
* @param element
* @return
*/
@Override
public int indexOf(Type element) {
if(element==null){
for (int i = 0; i < size ; i++) {
if(node(i).element == null) return i;
}
}else {
for (int i = 0; i < size ; i++) {
if(node(i).element == element) return i;
}
}
return ELEMENT_NOT_FOUND;
}
下面介绍,哪些接口跟单向链表不一样。对于双向链表,这些接口的内部实现又该如何呢?
- 清除链表操作
clear():对比于单向链表,这里必须要同时让头结点和尾结点消失。
/**
* 清空链表,即将指向链表的指针清空,后面的链表会一一断开
* 双向链表必须将头部和尾部节点同时清空
*/
@Override
public void clear() {
size = 0;
HeadNode = null;
TailNode = null;
//把指向头部节点和指向尾部节点的指针清空,貌似也不会清空链表里的元素吧?因为每一个节点都被next和prev引用着啊?
//但是,java中的虚拟机会自动识别,这些链表中的节点是不是被gc root对象引用着。只要是没有被gc root对象引用,就会回收
//什么叫gc root对象呢?就好比我们声明出来的东西,栈空间的指针啊,全局区的指针啊,等等。之前链表中的其他节点之所以不会被回收,是因为被gc root对象间接引用了
//而头结点和尾结点是被直接引用的,所以把头结点和尾结点的引用断开,其他节点就失去了间接引用的机会,那就自然都销毁了。当然头尾失去的是直接引用
}
这里注意一个细节:就是当把头结点和尾结点清空,也就是让HeadNode和TailNode都指向NULL了,但是链表似乎还存在啊,因为各个结点都有其他结点指着呀。

这里就要提及一下Java的一些细节知识点了。
Java中有一个gc root的概念。也就是说,当某个对象不被gc root对象直接引用着或者间接引用着的时候,这个对象就会挂掉。那什么对象才能叫gc root对象呢?
比如说:栈空间声明的指针,全局区声明的指针。之前的单向链表非头结点之所以没有被回收,是因为被gc root对象间接引用着,而头结点则是被直接引用着。一旦,gc root对象不再指向头结点了,那么头结点以及其他节点就没有被gc root对象直接或者间接引用,所以就会挂掉。
所以,双向链表中,只要gc root对象不指向头结点或者尾结点,整个链表就会挂掉。就算链表中其他节点互相指,也没用,因为没有一个是gc root对象。
注意注意: 这只是Java的做法,如果是C++那就得挨个把节点释放掉了,因为是new出来的。
- 双向链表向index处添加元素节点
add(int index, Type element):比如向index=1处插入一个节点,原来的index=1就变成了index=2,原来的index=0还是index=0
具体技术细节:
1、先考虑普通情况,即非边界情况;双向链表对比于单向链表还有一个好处就是没必要非得利用node(index-1)去找上一个节点了,直接node(index).prev就行了。首先,插入节点首先要创建节点newNode,在创建的同时就完成了两个操作:新创建的节点的prev指向原来index处节点的前一个节点,也就是节点node.prev,以及新创建的节点的next指向原来的index处的节点node。代码如下:
//不是最后一位添加元素
Node<Type> node = node(index); //获取想要插入的index点
Node<Type> newNode = new Node<>(node.prev,element,node); //新插入的节点的prev要指向index处节点的上一个节点,元素就是element,指向的下一个节点就是index处的节点
接下来就需要让前一个节点的next指向新创建的节点,以及后一个节点的prev也指向新创建的节点。这就完成了一个节点的的插入
node.prev.next = newNode; //原本index处的上一个节点的也要指向新节点(next指向)
node.prev = newNode; //原本index处的节点要指向新节点(prev指向)
示意图如下:

2、这只是普通情况的插入,当我们在头结点处插入,过程会变成什么样呢?如果在头结点处插入,那原来的头结点就变成第二个节点了,新节点就是头结点。头结点什么性质呢?当然是,HeadNode 指向头结点,头结点的prev指向null,next指向第二个节点。于此同时原来头结点的next还要指向新创建的节点。所以,代码如下:
if(index == 0){
Node<Type> node = node(index); //获取想要插入的index点
Node<Type> newNode = new Node<>(null,element,node); //完成了新建接待prev指向null,next指向原来节点的操作
HeadNode = newNode;//头结点指针新节点
node.prev = newNode; //原来头结点的prev指向新节点
}
示意图如下:

3、当我们在尾结点处插入,过程会变成什么样呢?如果在尾结点插入,TailNode 就要指向新节点了,新节点的prev就要指向原来的尾结点了,原来的尾结点的next就要指向新节点了,新节点的next就得指向null了
Node<Type> node = node(size-1); //获取原来链表的最后一个节点
Node<Type> newNode = new Node<>(node,element,null);//创建新节点,同时其prev指向node并且next指向null
TailNode= newNode;//尾结点指针指向新的尾结点
node.next = TailNode;//原来的尾结点的next指向新的尾结点
示意图如下所示:

4、我们首先完成了普通情况下的添加元素,然后又分别完成了在头部或者尾部添加元素的边界情况。基本已经完成了双向链表的add操作。但是还有一种情况没有考虑到,那就是最开始链表为空的时候,add函数怎么操作?
最开始链表为空的时候,新节点的prev和next都应该指向null,所以创建新节点的时候,直接就完成这个操作Node,因为只有一个节点,所以头结点指针和尾结点指针都指向新结点。代码如下:
//说明此时链表没有节点,这是首次添加节点,那么头结点和尾结点都指向同一个节点,那就是相等
Node<Type> newNode = new Node<>(null,element,null);
TailNode = newNode;
HeadNode = newNode;
示意图如下:

考虑到上述所有情况,并充分考虑到代码整洁性,向链表index处添加元素的函数add(int index, Type element)整合为如下实现。最后别忘了size++。
/**
* 向指定index处插入一个节点,比如向1处插入一个节点,原来的1就变成了2,原来的0还是0
* Node.next指向的是整个节点,而不是指向的节点里的element或者next
* @param index
* @param element
*/
@Override
public void add(int index, Type element) {
rangeCheckForAppend(index);
if (index == size){
//往最后面添加元素
if(index == 0){
//说明此时链表没有节点,这是首次添加节点,那么头结点和尾结点都指向同一个节点,那就是相等
TailNode = new Node<>(null,element,null);
HeadNode = TailNode;
}else {
//说明此时链表已经有节点了
Node<Type> node = node(index-1); //获取想要插入的index的点,因为我传入的是size
TailNode = new Node<>(node,element,null);
node.next = TailNode;
}
}else {
//不是最后一位添加元素
Node<Type> node = node(index); //获取想要插入的index点
Node<Type> newNode = new Node<>(node.prev,element,node); //新插入的节点的prev要指向index处节点的上一个节点,元素就是element,指向的下一个节点就是index处的节点
if(node.prev == null){
//如果index处节点的prev是null,那说明该index处的节点是首节点,把节点插入到首节点处,就得直接用HeadNode指向
HeadNode = newNode; //(next指向)
}else {
//如果插入的地方不是头结点,那就用index处的上一个节点指向新节点就可以了
node.prev.next = newNode; //原本index处的上一个节点的也要指向新节点(next指向)
}
node.prev = newNode; //只要不是尾结点,这句话试用。原本index处的节点要指向新节点(prev指向)
}
size++;//链表长度++
}
- 双向链表删除index处的节点:
Type remove(int index),
具体技术细节:
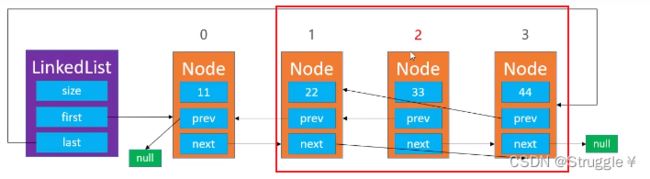
1、先考虑普通情况,删除是非边界结点。那就只需要让index-1处的结点和index+1处的节点互相指就完事了。前一个和后一个互相指以后,就没有结点指向当前index处的节点了,那就会挂掉。
node(index-1).next = node(index+1);//上一个节点指向下一个(next指向)
node(index+1).prev = node(index-1);//下一个节点指向上一个(prev指向)
示意图如下:
2、当删除的是头结点,也就是index=0时。那就让头结点指针HeadNode 指向该节点的下一个节点,然后让该节点的下一个节点的prev指向null即可。因为这样,又没有指针指向该节点了,那就会自动挂掉。
//如果删除的首节点
HeadNode = node(index+1);
node(index+1).prev = null;
示意图如下:
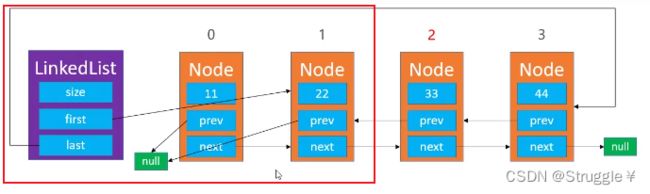
3、当删除的是尾结点,也就是index=size时。那就需要让尾结点指针TailNode指向index-1处的节点,然后再让index-1处结点的next指向null就行了。因为这样的话,也没人指向最后一个节点了,就自动挂掉了。(注意一个特殊情况:当链表只剩下一个元素的时候,再删除,只需要把头尾节点置nulll即可)
if(node(index).next == null){
//如果删除的是尾结点
if(size == 1){
HeadNode = null;
TailNode = null;
size--;
return oldNode.element;
}
TailNode = node(index-1);
node(index-1).next = null;
}
所以整合所有程序,如下:
/**
* 删除指定index处的节点
* @param index
*/
@Override
public Type remove(int index) {
rangeCheck(index);
Node<Type> oldNode = node(index); //获取之前的节点,并返回元素
if(index == 0){
//如果删除的首节点
if(size == 1){
HeadNode = null;
TailNode = null;
size--;
return oldNode.element;
}
HeadNode = node(index+1);
node(index+1).prev = null;
}else {
if(node(index).next == null){
//如果删除的是尾结点
TailNode = node(index-1);
node(index-1).next = null;
}else {
node(index-1).next = node(index+1);//上一个节点指向下一个(next指向)
node(index+1).prev = node(index-1);//下一个节点指向上一个(prev指向)
}
}
size--;
return oldNode.element;
}
但是!!!!!上面程序是有BUG的,假如链表中只有一个节点,node(index-1)和node(index+1)的操作就会发生越界行为。但对于正常的链表来说,只有一个结点也应该可以删除。
因此,在设计remove函数时,node(index-1)统统换成node(index).prev;node(index+1)统统换成node(index).next;
无BUG程序如下:
/**
* 删除指定index处的节点
* @param index
*/
@Override
public Type remove(int index) {
rangeCheck(index);
Node<Type> oldNode = node(index); //获取之前的节点,并返回元素
Node<Type> node = node(index);
if(index == 0){
//如果删除的首节点
if(size == 1){
HeadNode = null;
TailNode = null;
size--;
return oldNode.element;
}
HeadNode = node(index).next;
node(index).next.prev = null;
}else {
if(node(index).next == null){
//如果删除的是尾结点
TailNode = node(index).prev;
node(index).prev.next = null;
}else {
node.prev.next = node.next;//上一个节点指向下一个(next指向)
node.next.prev = node.prev;//下一个节点指向上一个(prev指向)
}
}
size--;
return oldNode.element;
}
至此,双向链表的接口全部设计完毕。下面我们测试一下:其中Asserts.test()函数会判断括号内是否为False,如果是,就断言。
//双向链表的测试
List<Integer> list = new DoubleLinkedList<>();
list.append(11);
list.append(22);
list.append(33);
list.append(44);
System.out.println(list);
Asserts.test(list.indexOf(11) == 0); //检查11是不是在链表的第0位
list.add(0,55);
list.add(2,66);
list.add(list.size(),77);
Asserts.test(list.size() == 7);//检查此时链表的长度是不是7
Asserts.test(list.get(2) == 66);//检查此时链表index==2时,是不是66
System.out.println(list);
list.remove(0);
list.remove(2);
list.remove(list.size()-1);
System.out.println(list);
list.set(2,88); //设置第2位为88
System.out.println(list);
Asserts.test(list.get(2) == 88); //检查是否设置成功
Asserts.test(list.contains(66)); //查看链表里是否包含66这个元素
结果完全正确

至此,双向链表就介绍完了!
双向链表 VS 单向链表
双向链表对比单向链表,总结为一句话就是:操作数据的规模减少一半,因为可以从两个方向检索,但会造成空间的增加,也就是常说的空间换时间。
/**
* 双向链表 vs 单向链表
* 操作数据的规模减少一半,因为可以从两个方向检索
*/
双向链表 VS 动态数组
/**
* 双向链表 vs 动态数组
* 动态数组:开辟,销毁内存空间的次数相对较少,但可能会造成内存空间的浪费(但可以通过缩容技术来解决)
* 双向链表:开辟,销毁内存空间的次数相对较多,但不会造成内存空间的浪费
*
* 注意事项:
* 1、如果频繁地在尾部进行添加,删除操作,动态数组和双向链表没什么区别,因为都是O(1)复杂度
* 2、如果频繁地在头部进行添加,删除操作,建议使用双向链表,因为动态数组是O(n)复杂度
* 3、如果频繁地在任意位置进行添加,删除操作,仍然建议使用双向链表,因为动态数组是有最坏情况的,比如向0处添加,删除元素
* 4、如果有频繁的查询操作(最近访问操作),建议使用动态数组,因为数组的访问是地址偏移量,是瞬间访问的,而链表则需要一个一个定位到index处
*
* 总结:动态数组增删慢,但是查询快;链表查询慢,但是增删快;
*/
单向循环链表
单向循环链表对比于普通的单向链表,唯一的区别就是:尾结点不指向null了,而是指向头结点,因此尾结点的next是头结点。当只有一个结点时,自己要指向自己。如下所示:


那么单向循环链表,对比于普通单向链表,有哪些接口需要额外注意呢?
这里大胆的设想一下:因为单向循环链表的尾结点要指向头结点,因此add或者remove头结点或者尾结点时,需要让循环链表仍然存在。比如:add元素到头部时,新头结点需要让尾结点指向;remove尾结点时,新尾结点就要指向头结点。同理,add元素到尾部,remove头结点也要考虑。
- 调用
add(int index, Type element)函数,向单向循环链表里添加元素。我们需要额外注意什么细节呢?
1、向index=0处添加新的节点:创建新结点时,就完成指向原来头结点的工作。然后,让头结点指针指向新节点,最后把尾结点next指向新节点就完事了。
SingleCircleLinklist.Node<Type> newNode = new SingleCircleLinklist.Node<>(element,HeadNode);//新节点首先指向原来的HeadNode,
HeadNode = newNode;//然后将HeadNode指向此时的首节点(也就是新创建的节点)
TailNode.next = HeadNode; //尾结点指向头结点
但是,单向链表并没有尾结点指针,因此需要自己手动new一个。特别注意:new尾结点,需要node(size-1),如果这句代码不在创建新节点之前new,那么new出来的尾结点就不是原来的尾结点,就是原来倒数第二个结点。因为node(index)函数是从头结点还是找,然后循环从for (int i = 0; i < index; i++),如果传入的index = size -1,那就说明循环了size-1步,因为我头部已经添加了节点,那么节点数就变多了一个,仍然循环size-1步,就到不了尾结点。所以:要在插入新的头节点之前,把原来的尾结点取出来
Node<Type> lastNode = node(size-1);//先取出尾结点(一定要在改变HeadNode节点之前取出来,要不然就乱了)
Node<Type> TailNode = (size == 0) ? HeadNode : lastNode; // 如果此时链表还没有元素呢,那就用刚刚创建的HeadNode也当做尾结点
所以,向index=0处插入节点,完整代码如下:
if(index==0) {
if(size == 0){
//如果是首次添加,那就自己指向自己
HeadNode = new SingleCircleLinklist.Node<>(element,HeadNode);
}else {
//如果不是首次添加
Node<Type> lastNode = node(size-1);//先取出尾结点(一定要在改变HeadNode节点之前取出来,要不然就乱了)
SingleCircleLinklist.Node<Type> newNode = new SingleCircleLinklist.Node<>(element,HeadNode);//新节点首先指向原来的HeadNode,
HeadNode = newNode;//然后将HeadNode指向此时的首节点(也就是新创建的节点)
//循环链表(尾结点指向头结点),需要注意在0处插入元素的情况
Node<Type> TailNode = (size == 0) ? HeadNode : lastNode; // 如果此时链表还没有元素呢,那就用刚刚创建的HeadNode也当做尾结点
TailNode.next = HeadNode; //尾结点指向头结点
}
}
为什么要多一个size == 0的判断呢?因为,下面用到了node(size-1),所以要额外判断一下size == 0。
2、只有不是在index=0处插入新结点,其他情况统统适用,代码如下:
SingleCircleLinklist.Node<Type> prevNode = node(index-1); //获取index-1处的节点
SingleCircleLinklist.Node<Type> newNode = new SingleCircleLinklist.Node<>(element,prevNode.next);//新节点先指向index处的节点,prevNode.next是index处节点
prevNode.next = newNode; //然后让prevNode指向newNode,然后就自动断开了和原本index处的连接
有人就要问了,在尾部插入新结点,这三行代码也适用?答案是:当然!
首先,SingleCircleLinklist.Node其实表示取出原来尾部的结点,因为我在尾部插入,index传入的指定是size;
SingleCircleLinklist.Node;这句代码干了什么事呢?答案是:新创建的结点指向了prevNode.next,也就是原来尾结点的next,也就是头结点!
最终再让原来的尾结点next指向新节点prevNode.next = newNode,就完事了。
OK,整个单向循环链表的add操作整合如下:
/**
* 向指定index处插入一个节点,比如向1处插入一个节点,原来的1就变成了2,原来的0还是0
* Node.next指向的是整个节点,而不是指向的节点里的element或者next
* @param index
* @param element
*/
@Override
public void add(int index, Type element) {
if(index==0) {
if(size == 0){
//如果是首次添加,那就自己指向自己
HeadNode = new SingleCircleLinklist.Node<>(element,HeadNode);
}else {
//如果不是首次添加
Node<Type> lastNode = node(size-1);//先取出尾结点(一定要在改变HeadNode节点之前取出来,要不然就乱了)
HeadNode = new SingleCircleLinklist.Node<>(element,HeadNode);//新节点首先指向原来的HeadNode,然后将HeadNode指向此时的首节点(也就是新创建的节点)
//循环链表(尾结点指向头结点),需要注意在0处插入元素的情况
Node<Type> TailNode = lastNode;
TailNode.next = HeadNode; //尾结点指向头结点
}
}
else {
SingleCircleLinklist.Node<Type> prevNode = node(index-1); //获取index-1处的节点
SingleCircleLinklist.Node<Type> newNode = new SingleCircleLinklist.Node<>(element,prevNode.next);//新节点先指向index处的节点,prevNode.next是index处节点
prevNode.next = newNode; //然后让prevNode指向newNode,然后就自动断开了和原本index处的连接
}
size++;//链表长度++
}
- 调用
remove(int index),删除指定index处的结点,我们需要额外注意什么细节呢?
1、想想删除index=0时的头结点,需要额外处理什么东西吗?答案是:需要尾结点指向新的头结点。时刻注意,单向链表是没有尾结点指针的,需要自己手动指向。为什么要单把size==1拿出来,因为else里有node(index+1),如果链表只剩最后一个节点,node(index+1)是会出现越界行为的。
if(index==0){
if(size ==1){
//如果只剩下一个节点,那就直接清空头结点就好了
HeadNode = null;
}else {
//如果不是只有一个节点的特殊情况
Node<Type> TailNode = node(size-1); //必须写在HeadNode = node(index+1);的前面,因为node是依赖HeadNode查找,如果HeadNode更改了指向,TailNode就会向后移位
HeadNode = node(index+1);//真正的删除头结点操作,让node(index)失去被指
//单向循环链表,删除头结点后,要拿到最后一个节点,然后指向新的头结点
TailNode.next = HeadNode;
}
}
2、当我删除的不是头结点时,还要注意删除的是不是尾结点。因为尾结点删除之后,新的尾结点要把‘环’连上,这一步是需要额外做的。
else{
if(index==size-1){
SingleCircleLinklist.Node<Type> prevNode = node(index-1); //取出前一个节点
prevNode.next = HeadNode; //把环连上
}else {
SingleCircleLinklist.Node<Type> prevNode = node(index-1); //取出前一个节点
prevNode.next = node(index+1); //前一个节点指向下一个节点,即前一个节点不指向当前index节点,那么当前节点就自动销毁了
}
}
单向循环链表需要注意的点:
1、add和remove的时候,需要在index=0的时候做一些特殊处理
2、就是让TailNode指向add新添加的,或者remove掉0处之后的HeadNode
3、要注意size=0时的add,有自己指向自己的操作;和size=1时的remove,头结点清空就行了
双向循环链表
之前的双向链表,头结点的prev指向null,尾结点的next指向null。然而,对于双向循环链表来说,头结点的prev指向尾结点,尾结点的next指向头结点。就如下图所示:

通过单向循环链表的学习,我们大致可以猜到,双向循环链表需要改动的地方应该也是add和remove。接下来看看具体需要注意的细节。
add(int index, Type element)函数。需要考虑的无非是:是否是尾部添加;尾部添加时链表是否是首次添加元素;
1、考虑普通情况下,向尾部添加元素。取出原来的尾结点node(index-1);创建新节点new Node<>(node,element,HeadNode),这一步完成prev指向原来的尾结点,next指向头结点;尾结点指针指向新的尾结点TailNode = new Node<>(node,element,HeadNode);头结点的prev指向新的尾结点HeadNode.prev = TailNode;原来尾结点的next指向新的尾结点node.next = TailNode;
//说明此时链表已经有节点了
Node<Type> node = node(index-1); //获取想要插入的index的点,因为我传入的是size
TailNode = new Node<>(node,element,HeadNode);//让尾结点指向新添加的节点,新添加的节点:prev指向上次的TailNode,next指向HeadNode
HeadNode.prev = TailNode;//HeadNode的prev指向TailNode
node.next = TailNode; //上次的尾结点的下一个是新添加的尾结点
2、考虑初始链表没有结点时,向尾部添加元素。先创建一个新节点new Node<>(HeadNode,element,TailNode),prev指向HeadNode,next指向TailNode。然后让头结点或者尾结点指针先指向这个新节点,然后另一个指针再指向这个节点就行了。
//说明此时链表没有节点,这是首次添加节点,那么头结点和尾结点都指向同一个节点,那就是相等
TailNode = new Node<>(HeadNode,element,TailNode);
HeadNode = TailNode;
3、考虑普通情况下,向中间位置添加元素。跟之前一样,把四根线都指完就行
//不是最后一位添加元素
Node<Type> node = node(index); //获取想要插入的index点
Node<Type> newNode = new Node<>(node.prev,element,node); //新插入的节点的prev要指向index处节点的上一个节点,元素就是element,指向的下一个节点就是index处的节点
//如果插入的地方不是头结点,那就用index处的上一个节点指向新节点就可以了
node.prev.next = newNode; //原本index处的上一个节点的也要指向新节点(next指向)
node.prev = newNode; //原本index处的节点要指向新节点(prev指向)
4、考虑正常情况下,向头部位置添加元素。说明此时index=0,那么node = node(index)其实就是头结点,关键的来了:newNode = new Node<>(node.prev,element,node);这一句代码完成了新节点next指向头结点,同时新节点的prev指向了node.prev,其实就是尾结点!因为插入之前,双向循环就已经成立了。那就把剩下两条线补齐就行了 HeadNode = newNode;和node.prev = newNode;
//不是最后一位添加元素
Node<Type> node = node(index); //获取想要插入的index点
Node<Type> newNode = new Node<>(node.prev,element,node); //新插入的节点的prev要指向index处节点的上一个节点,元素就是element,指向的下一个节点就是index处的节点
if(index == 0){
//把节点插入到首节点处,就得直接用HeadNode指向,也就说明newNode变成了HeadNode
HeadNode = newNode;
}
node.prev = newNode; //原本index处的节点要指向新节点(prev指向)
整合所有情况,双向循环链表的add操作如下:
/**
* 向指定index处插入一个节点,比如向1处插入一个节点,原来的1就变成了2,原来的0还是0
* Node.next指向的是整个节点,而不是指向的节点里的element或者next
* @param index
* @param element
*/
@Override
public void add(int index, Type element) {
rangeCheckForAppend(index);
if (index == size){
//往最后面添加元素
if(index == 0){
//说明此时链表没有节点,这是首次添加节点,那么头结点和尾结点都指向同一个节点,那就是相等
TailNode = new Node<>(HeadNode,element,TailNode);
HeadNode = TailNode;
}else {
//说明此时链表已经有节点了
Node<Type> node = node(index-1); //获取想要插入的index的点,因为我传入的是size
TailNode = new Node<>(node,element,HeadNode);//让尾结点指向新添加的节点,新添加的节点:prev指向上次的TailNode,next指向HeadNode
HeadNode.prev = TailNode;//HeadNode的prev指向TailNode
node.next = TailNode; //上次的尾结点的下一个是新添加的尾结点
}
}else {
//不是最后一位添加元素
Node<Type> node = node(index); //获取想要插入的index点
Node<Type> newNode = new Node<>(node.prev,element,node); //新插入的节点的prev要指向index处节点的上一个节点,元素就是element,指向的下一个节点就是index处的节点
if(index == 0){
//把节点插入到首节点处,就得直接用HeadNode指向,也就说明newNode变成了HeadNode
HeadNode = newNode;
}else {
//如果插入的地方不是头结点,那就用index处的上一个节点指向新节点就可以了
node.prev.next = newNode; //原本index处的上一个节点的也要指向新节点(next指向)
}
node.prev = newNode; //原本index处的节点要指向新节点(prev指向)
}
size++;//链表长度++
}
看到这里,应该明白双向循环链表一个特别之处就是:头结点和尾结点被三根线指向,其余结点被两根线指向。所以在设计双向循环链表时,在头尾结点处不要疏忽丢掉任何一根线。
remove(int index)函数,有哪些细节需要注意呢?
1、删除头结点时,让头节点指针指向下一个node(index+1),然后让node(index+1).prev指向尾结点就行了。但是要考虑删除完头结点,链表为空的情况。也就是当size == 1时,只需要让头结点指针和尾结点指针都指向null就行。
if(index == 0){
//如果删除的首节点
if(size == 1){
//如果删除完,就清空了链表
HeadNode = null;
TailNode = null;
}else {
//如果删除完该节点,链表没有清空
HeadNode = node(index+1);
node(index+1).prev = TailNode;//由于是双向循环,因此头结点的prev要指向尾结点
}
}
2、删除的不是头结点时,假如删除正常节点,那就让index节点的前一个和后一个各自指就行了,index处就会自动消失。如果删除的是尾结点,那就需要让新的尾结点指向头结点node(index-1).next = HeadNode,当然还有尾结点指针指向新的index-1处的节点TailNode = node(index-1);。
else {
if(index == (size-1)){
//如果删除的是尾结点
TailNode = node(index-1);
node(index-1).next = HeadNode; //由于是双向循环,因此尾结点的next要指向头结点
}else {
//如果删除的是中间的节点
node(index-1).next = node(index+1);//上一个节点指向下一个(next指向)
node(index+1).prev = node(index-1);//下一个节点指向上一个(prev指向)
}
}
于是,整合起来,remove整体代码如下:
/**
* 删除指定index处的节点
* @param index
*/
@Override
public Type remove(int index) {
rangeCheck(index);
Node<Type> oldNode = node(index); //获取之前的节点,并返回元素
if(index == 0){
//如果删除的首节点
if(size == 1){
//如果删除完,就清空了链表
HeadNode = null;
TailNode = null;
}else {
//如果删除完该节点,链表没有清空
HeadNode = node(index+1);
node(index+1).prev = TailNode;//由于是双向循环,因此头结点的prev要指向尾结点
}
}else {
if(index == (size-1)){
//如果删除的是尾结点
TailNode = node(index-1);
node(index-1).next = HeadNode; //由于是双向循环,因此尾结点的next要指向头结点
}else {
//如果删除的是中间的节点
node(index-1).next = node(index+1);//上一个节点指向下一个(next指向)
node(index+1).prev = node(index-1);//下一个节点指向上一个(prev指向)
}
}
size--;
return oldNode.element;
}
链表总结
无论是单向链表、单向循环链表、双向链表、双向循环链表,都只是为存储数据所做的额外操作。我们使用者在接口处,只能感觉到‘数组’式的数据,即只有element,根本体会不到next指针,prev指针的存在。
链表在使用者眼里,就是一个高级数组,功能更多的数组,仅此而已!!!!!因为我们是框架的设计者,所以才要考虑整篇文章的事情,但是我们更加清楚细节了不是吗~
还有一些框架设计时,细节之处:
- 用node(index-1)或者node(index+1)时要好好想想边界条件满不满足
- 不被gc root对象指着,就得挂,也就意味着,我们在删除某个节点时,只需要把指向它的线都断掉
- 单向链表任何一个节点都只有一条线指着;单向循环链表头结点被两条线指着;双向链表任何一个节点都被两条线指着;双向循环链表头结点和尾结点被三条线指着
- Java中没有指针的概念,只有引用的概念。
- 等式左右两边的意思是:左边(指针)指向 右边(结点),要充分理解这个感觉