CSP-S 模拟赛 2023.7.20
CSP-S 模拟赛 2023.7.20 2023.7.20 2023.7.20
第 1 1 1 题 回文
题目
小 X 有 N N N 个正整数 a 1 , a 2 , . . . , a N a_1,a_2,...,a_N a1,a2,...,aN。
他可以进行任意次操作,每次操作选取相邻的两个数 a x a_x ax 和 a x + 1 a_{x+1} ax+1,将它们替换为一个数 a x + a x + 1 a_x+a_{x+1} ax+ax+1。例如, [ 1 , 1 , 4 , 5 , 1 , 4 ] [1,1,4,5,1,4] [1,1,4,5,1,4] 可以在一次操作中变成 [ 1 , 1 , 9 , 1 , 4 ] [1, 1, 9,1,4] [1,1,9,1,4]。
小 X 想知道最少需要多少次操作,才能使得 a a a 变为回文数组。如: [ 1 , 2 , 3 , 2 , 1 ] [1,2,3,2,1] [1,2,3,2,1] 和 [ 1 , 2 , 2 , 1 ] [1,2,2,1] [1,2,2,1] 是回文数组,而 [ 1 , 1 , 4 ] [1,1,4] [1,1,4] 不是回文数组。
输入格式
第一行一个整数 N N N。
第二行 N N N 个整数,依次表示 a 1... N a_{1...N} a1...N。
数据范围
对于 30 % 30\% 30% 的数据, 1 ⩽ N ⩽ 10 1\leqslant N\leqslant10 1⩽N⩽10。
对于另外 20 % 20\% 20% 的数据, 1 ⩽ N ⩽ 100 1\leqslant N\leqslant100 1⩽N⩽100。
对于 100 % 100\% 100% 的数据, 1 ⩽ N ⩽ 1 0 6 , a 1... N ⩽ 1000 1\leqslant N\leqslant10^6,a_{1...N} \leqslant 1000 1⩽N⩽106,a1...N⩽1000。
输出格式
一行一个整数表示答案。
样例
样例 1 1 1
输入
3
1 2 3
输出
1
解释
对 a 1 a_1 a1 和 a 2 a_2 a2 进行一次操作, a = [ 3 , 3 ] a = [3, 3] a=[3,3],是回文数组。
样例 2 2 2
输入
5
1 2 4 6 1
输出
1
解释
对 a 2 a_2 a2 和 a 3 a_3 a3 进行一次操作, a = [ 1 , 6 , 6 , 1 ] a = [1, 6, 6, 1] a=[1,6,6,1],是回文数组。
样例 3 3 3
输入
4
1 4 3 2
输出
2
解释
对 a 1 a_1 a1 和 a 2 a_2 a2 进行一次操作, a = [ 5 , 3 , 2 ] a = [5, 3, 2] a=[5,3,2];
对 a 2 a_2 a2 和 a 3 a_3 a3 进行一次操作, a = [ 5 , 5 ] a = [5, 5] a=[5,5],是回文数组。
样例 4 4 4、 5 5 5
点击下载
解法
如果 a l = a r a_l = a_r al=ar,可以不考虑它们。
如果 a l < a r a_l < a_r al<ar,合并 a r − 1 a_{r-1} ar−1 和 a r a_r ar 只会让右边更大,不能回文;所以合并 a l a_{l} al 和 a l + 1 a_{l+1} al+1。
如果 a l > a r a_l > a_r al>ar,合并 a l a_{l} al 和 a l + 1 a_l+1 al+1 只会让右边更大,不能回文;所以合并 a r − 1 a_{r-1} ar−1 和 a r a_{r} ar。
一直重复,直到 l ⩾ r l \geqslant r l⩾r 即可。
时间复杂度 Θ ( N ) \Theta(N) Θ(N)。
代码
// 第一题:回文
// Created by 老徐 on 2023/7/21.
// 2023.7.20 测试
#include 第 2 2 2 题 配对
题目
小 X 有一个质数 P P P 和一个非负整数 K K K。
小 Y 有 N N N 个互不相同的非负整数 a 1 , a 2 , . . . , a N a_1, a_2, ..., a_N a1,a2,...,aN。
小 X 和 小 Y 想贴贴,所以他们想知道有多少数对 ( i , j ) (i, j) (i,j) 满足以下条件
1 ⩽ i < j ⩽ N , ( a i + a j ) ( a i 2 + a j 2 ) ≡ K ( m o d P ) 1 \leqslant i < j \leqslant N, (a_i + a_j)({a_i}^2+{a_j}^2) \equiv K (\bmod \enspace P) 1⩽i<j⩽N,(ai+aj)(ai2+aj2)≡K(modP)
输入格式
第一行三个整数 N , P , K N,P,K N,P,K。
第二行 N N N 个整数,依次表示 a 1... N a_{1...N} a1...N。
数据范围
对于 30 % 30\% 30% 的数据: 1 ⩽ N ⩽ 3000 , 2 ⩽ P ⩽ 3 × 1 0 5 , 0 ⩽ K , a i < P 1 \leqslant N \leqslant 3000, 2 \leqslant P \leqslant 3 \times 10^5, 0 \leqslant K, a_i< P 1⩽N⩽3000,2⩽P⩽3×105,0⩽K,ai<P。
对于 另外 20 % 20\% 20% 的数据: 1 ⩽ N ⩽ 3 × 1 0 5 , 2 ⩽ P ⩽ 1 0 9 , K = 0 , 0 ⩽ a i < P 1 \leqslant N \leqslant 3 \times 10^5, 2 \leqslant P \leqslant 10^9, K = 0, 0 \leqslant a_i< P 1⩽N⩽3×105,2⩽P⩽109,K=0,0⩽ai<P。
对于 另外 10 % 10\% 10% 的数据: 1 ⩽ N ⩽ 3 × 1 0 5 , 2 ⩽ P ⩽ 1 0 9 , K = 1 , 0 ⩽ a i < P 1 \leqslant N \leqslant 3 \times 10^5, 2 \leqslant P \leqslant 10^9, K = 1,0 \leqslant a_i< P 1⩽N⩽3×105,2⩽P⩽109,K=1,0⩽ai<P。
对于 100 % 100\% 100% 的数据: 1 ⩽ N ⩽ 3 × 1 0 5 , 2 ⩽ P ⩽ 1 0 9 , 0 ⩽ K , a i < P 1 \leqslant N \leqslant 3 \times 10^5, 2 \leqslant P \leqslant 10^9, 0 \leqslant K, a_i< P 1⩽N⩽3×105,2⩽P⩽109,0⩽K,ai<P。
样例
样例 1 1 1
输入
3 3 0
0 1 2
输出
1
解释
( 2 , 3 ) (2, 3) (2,3)
样例 2 2 2
输入
6 7 2
1 2 3 4 5 6
输出
3
解释
( 1 , 5 ) , ( 2 , 3 ) , ( 4 , 6 ) (1, 5),(2,3),(4,6) (1,5),(2,3),(4,6)
样例 3 3 3、 4 4 4、 5 5 5、 6 6 6
点击下载
解法
平方差公式: a 2 − b 2 = ( a + b ) ( a − b ) a^2-b^2=(a+b)(a-b) a2−b2=(a+b)(a−b)
观察式子,考虑左右同时 × ( a i − a j ) \times (a_i - a_j) ×(ai−aj),则根据平方差公式可得
≡ \equiv ≡ 左边 = ( a i − a j ) ( a i + a j ) ( a i 2 + a j 2 ) = ( a i 2 + a j 2 ) ( a i 2 + a j 2 ) = a i 4 − a j 4 = (a_i-a_j)(a_i+a_j)({a_i}^2+{a_j}^2) = ({a_i}^2+{a_j}^2)({a_i}^2+{a_j}^2)={a_i}^4-{a_j}^4 =(ai−aj)(ai+aj)(ai2+aj2)=(ai2+aj2)(ai2+aj2)=ai4−aj4
≡ \equiv ≡ 右边 = K ( a i − a j ) = K a i − K a j =K(a_i-a_j)=Ka_i-Ka_j =K(ai−aj)=Kai−Kaj
将所有关于 i i i 的项移到左边,所有关于 j j j 的项移到右边得到 K a i − a i 4 ≡ K a j − a j 4 ( m o d P ) Ka_i-{a_i}^4 \equiv Ka_j-{a_j}^4(\bmod \enspace P) Kai−ai4≡Kaj−aj4(modP)
问题就变成 K × a i − a i 4 K \times a_i - {a_i}^4 K×ai−ai4 相等的对数,开个 map存一下就解决了。
时间复杂度 Θ ( N log N ) \Theta (N \log N) Θ(NlogN),一重 for循环执行 N N N 次,map内部复杂度 Θ ( log N ) \Theta (\log N) Θ(logN)。
代码
#include 第 3 3 3 题 地震恢复
题目
小 X 所在地区不幸地发生了地震,幸运的是人没事,但是他需要你帮助他规划地震后的修复工作。
形式化地说,小 X X X 所在地区原本是一张 N N N 个点 M M M 条边的无向连通图,每个点 N o d e Node Node 有点权 N o d e W e i g h t N o d e NodeWeight_{Node} NodeWeightNode,第 i i i 条边有一个权值 E d g e W e i g h t i EdgeWeight_{i} EdgeWeighti。由于地震影响,这 M M M 条边都需要修复,未修复的边是无法连通的,这意味着这 N N N 个点初始时互不连通。
第 i i i 条边 ( N o d e 1 , N o d e 2 , W e i g h t ) (Node1, Node2, Weight) (Node1,Node2,Weight) 能被修复当且仅当 点 N o d e 1 Node1 Node1 所在的连通块的权值和 + + + 点 N o d e 2 Node2 Node2 所在的连通块的权值和 ⩾ \geqslant ⩾ W e i g h t Weight Weight。
地震后的修复十分重要,所有你需要尽可能多地修复道路,但是为了效率,你不能修复一条无用的道路,即道路 ( N o d e 1 , N o d e 2 , W e i g h t ) (Node1, Node2, Weight) (Node1,Node2,Weight) 若被修复必须保证修复前 N o d e 1 Node1 Node1 和 N o d e 2 Node2 Node2 不连通。
请你在保证修复边尽可能长的情况下,构建出字典序最小的修复方案。一个修复方案指一个修复边的序列。
输入格式
第一行两个整数 N , E N, E N,E,分别表示点数和边数。
接下来一行 N N N 个整数,第 i 个整数表示点 i 的权值 N o d e W e i g h t NodeWeight NodeWeight。
接下来 E E E 行,每行三个整数 N o d e 1 , N o d e 2 , W e i g h t Node1,Node2,Weight Node1,Node2,Weight,表示一条边 ( N o d e 1 , N o d e 2 , W e i g h t ) (Node1,Node2,Weight) (Node1,Node2,Weight)。
数据范围
本题共 25 25 25 个测试点。
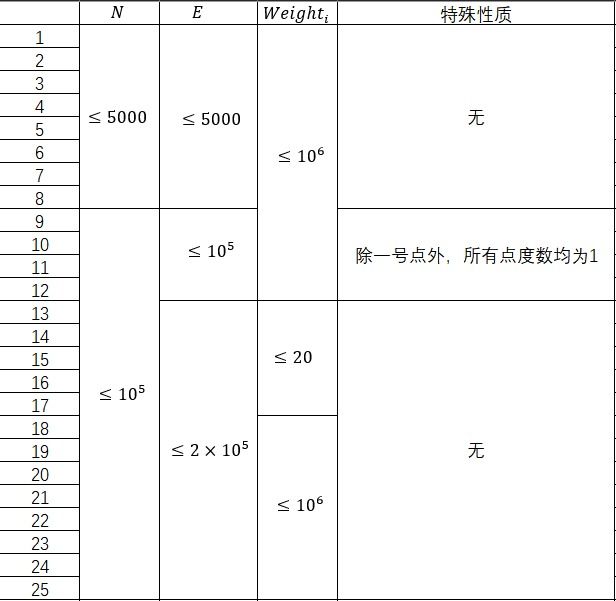
对于所有数据,保证给定的图连通且无自环, 0 ⩽ N o d e W e i g h t [ i ] ⩽ 1 0 6 , 1 ⩽ N o d e 1 , N o d e 2 ⩽ N 0 \leqslant NodeWeight[i] \leqslant 10^6,1 \leqslant Node1,Node2 \leqslant N 0⩽NodeWeight[i]⩽106,1⩽Node1,Node2⩽N。
输出格式
第一行一个整数 K K K,表示最多能修复的边数。
接下来一行 K K K 个整数,表示一次修复的边的编号。
样例
样例 1 1 1
输入
5 5
1 1 1 1 1
1 2 3
2 3 2
3 4 1
4 5 1
5 1 1
输出
4
2 1 3 4
样例 2 2 2、 3 3 3
点击下载
解法
1 1 1 到 8 8 8 测评点
贪心。
每次找到编号最小的能够修复的边并修复,时间复杂度 Θ ( N E ) \Theta(NE) Θ(NE),正确性不难证明。
得分:32分
9 9 9 到 12 12 12 测评点
只有一号点度数不为 1 1 1,则这是一个菊花图,开个堆维护还没选的边即可。时间复杂度 Θ ( N log N ) \Theta(N \log N) Θ(NlogN)
得分:16分
13 13 13 到 17 17 17 测评点
启发正确算法
每次合并两个连通块时,暴力合并还不能修复的出边,并将能修复的出边加入一个优先队列里,每次取出编号最小的修复并合并两个连通块即可。由于 W e i g h t i ⩽ 20 Weight_i \leqslant 20 Weighti⩽20, 每条边最多被访问 20 20 20 次就会变成可修复的边,所以时间复杂度为 Θ ( N log N + N × W e i g h t i ) \Theta(N \log N + N \times Weight_i) Θ(NlogN+N×Weighti)。
得分:20分
18 18 18 到 25 25 25 测评点
可以发现合并时,我们没有必要访问所有还不能修复的出边。具体来说,如果边 i i i 还差权值 k k k (还差指的是限制权值 − - − 两端连通块目前的权值和),那么如果边两端的连通块权值增加都小于 k 2 \frac{k}{2} 2k,那么这条边一定仍然无法修复。
那么我们就用一个优先队列维护连通块的所有出边,给每条边设置一个触发点 k 2 \frac{k}{2} 2k。
每次合并两个连通块的出边,并对所有达到出发点的边进行一次 C h e c k Check Check。
合并方法
出边少的连通块弹出所有出边,插入到出边较多的那个连通块。
如果一条边被 C h e c k Check Check 但是仍然不合法,那么就更新它的 k k k,并重新设置触发点。
可以发现,每条边只会被触发 Θ ( log W e i g h t i ) \Theta(\log Weight_i) Θ(logWeighti) 次,故总时间复杂度 Θ ( N log N + N log 2 W e i g h t i ) \Theta(N \log N + N \log^2 Weight_i) Θ(NlogN+Nlog2Weighti)
代码
#include 第 4 4 4 题 好奇宝宝
题目
小 X 有 N N N 个数 a 1 , a 2 , . . . , a N a_1, a_2, ..., a_N a1,a2,...,aN。
好奇宝宝小 Y 不仅对小 X X X 感兴趣,他也对这 N N N 个数感兴趣。所以,他会进行 M M M 次以下三种类型的操作之一
1. 1. 1. 1 L R X 1\enspace L\enspace R\enspace X 1LRX 将 a [ L . . . R ] a_{[L...R]} a[L...R] 中每个元素二进制与一个数 X X X。
2. 2. 2. 2 L R X 2\enspace L\enspace R\enspace X 2LRX 将 a [ L . . . R ] a_{[L...R]} a[L...R] 中每个元素二进制或一个数 X X X。
3. 3. 3. 3 L R 3\enspace L\enspace R 3LR 查询 a [ L . . . R ] a_{[L...R]} a[L...R] 中的最小值。
输入格式
第一行两个整数 N , M N,M N,M
接下来一行 N N N 个整数,表示 a [ 1... N ] a_{[1...N]} a[1...N]。
接下来 M M M 题,每行表示一个操作。
数据范围
本题共 25 25 25 个测试点。
1 1 1 到 5 5 5: 1 ⩽ N , M ⩽ 1000 1 \leqslant N, M \leqslant 1000 1⩽N,M⩽1000
6 6 6 到 12 12 12: 1 ⩽ N , M ⩽ 10000 1 \leqslant N, M \leqslant 10000 1⩽N,M⩽10000
13 13 13 到 20 20 20: 1 ⩽ N , M ⩽ 100000 1 \leqslant N, M \leqslant 100000 1⩽N,M⩽100000
21 21 21 到 25 25 25: 1 ⩽ N , M ⩽ 500000 1 \leqslant N, M \leqslant 500000 1⩽N,M⩽500000
对于所有数据, 0 ⩽ a i , X < 2 3 1 0 \leqslant a_i, X < 2^31 0⩽ai,X<231。
输出格式
对于每个操作 3 3 3,输出一行一个答案。
样例
样例 1 1 1
输入
5 4
4 5 1 2 7
3 2 4
1 1 3 3
2 2 5 2
3 2 5
输出
1
2
解释
第一个操作 3 2 4 3 \enspace 2 \enspace 4 324
数组为 [ 4 , 5 , 1 , 2 , 7 ] [4, 5, 1, 2, 7] [4,5,1,2,7]。
查询 [ 5 , 1 , 2 ] [5, 1, 2] [5,1,2] 的最小值,为 1 1 1。
第二个操作 1 1 3 3 1 \enspace 1 \enspace 3 \enspace 3 1133
数组为 [ 0 , 1 , 1 , 2 , 7 ] [0, 1, 1, 2, 7] [0,1,1,2,7]。
第三个操作 2 2 5 2 2 \enspace 2 \enspace 5 \enspace 2 2252
数组为 [ 0 , 3 , 3 , 2 , 7 ] [0, 3, 3, 2, 7] [0,3,3,2,7]。
第四个操作 3 2 5 3 \enspace 2 \enspace 5 325
数组为 [ 0 , 3 , 3 , 2 , 7 ] [0, 3, 3, 2, 7] [0,3,3,2,7]。
查询 [ 3 , 3 , 2 , 7 ] [3, 3, 2, 7] [3,3,2,7] 的最小值,为 2 2 2。
样例 2 2 2、 3 3 3、 4 4 4
点击下载
解法
用线段树维护 A n d , O r , M i n And,Or,Min And,Or,Min 值,对于操作:
1. 1. 1. A n d ( X ) And(X) And(X),设当前点为 T h i s This This,区间值分别为 A n d T h i s , O r T h i s , M i n T h i s And_{This},Or_{This},Min_{This} AndThis,OrThis,MinThis:
如果 X & O r T h i s = O r T h i s X \And Or_{This}=Or_This X&OrThis=OrThis,则该操作对当前区间无效;
如果 O r T h i s & X = A n d T h i s & X Or_{This} \And X = And_{This} \And X OrThis&X=AndThis&X,则该操作对当前区间的每个数影响都是一样的,可以打懒标记维护;
否则直接暴力递归。
2. 2. 2. O r ( X ) Or(X) Or(X),设当前点为 T h i s This This,区间值分别为 A n d T h i s , O r T h i s , M i n T h i s And_{This},Or_{This},Min_{This} AndThis,OrThis,MinThis:
如果 A n d T h i s & X = X And_{This} \And X=X AndThis&X=X,则该操作对当前区间无效;
如果 O r T h i s & X = A n d T h i s & X Or_{This} \And X = And_{This} \And X OrThis&X=AndThis&X,则该操作对当前区间的每个数影响都是一样的,可以打懒标记维护;
否则直接暴力递归。
分析一下时间复杂度:每次暴力递归都会使得当前区间内所有数的某一位相同,每个区间不同位的总数为 Θ ( N log N log \Theta(N \log N \log Θ(NlogNlog 值域 ) ) ),时间复杂度就是 Θ ( N log N log \Theta(N \log N \log Θ(NlogNlog 值域 ) ) )。
代码
#include