Hadoop3教程(二十六):(生产调优篇)NameNode核心参数配置与回收站的启用
文章目录
- (143)NameNode内存配置
- (144)NN心跳并发配置
- (145)开启回收站
- 参考文献
(143)NameNode内存配置
每个文件块(的元数据等)在内存中大概 占用150byte,一台服务器128G内存的话,大概能存储9.1亿个文件块。
在Hadoop2.x里,如何配置NameNode内存?
NameNode默认内存2000M。如果你的服务器内存是4G,那一般可以把NN内存设置成3G,留1G给服务器维持基本运行(如系统运行需要、DataNode运行需要等)所需就行。
在hadoop-env.sh文件中设置:
HADOOP_NAMENODE_OPTS=-Xmx3072m
Hadoop3.x系列,如何配置NameNode内存?
答案是动态分配的。hadoop-env.sh有描述:
# The maximum amount of heap to use (Java -Xmx). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xmx setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MAX=
# The minimum amount of heap to use (Java -Xms). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xms setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MIN=
HADOOP_NAMENODE_OPTS=-Xmx102400m
如何查看NN所占用内存?
[atguigu@hadoop102 ~]$ jps
3088 NodeManager
2611 NameNode
3271 JobHistoryServer
2744 DataNode
3579 Jps
[atguigu@hadoop102 ~]$ jmap -heap 2611
Heap Configuration:
MaxHeapSize = 1031798784 (984.0MB)
如何查看DataNode所占内存?
[atguigu@hadoop102 ~]$ jmap -heap 2744
Heap Configuration:
MaxHeapSize = 1031798784 (984.0MB)
DN和NN的内存在默认情况下都是自动分配的,且NN和DN相等。这个就不太合理了,万一两个加起来超过了节点总内存怎么办,可能会崩掉。
经验参考:
https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_hardware_requirements.html#concept_fzz_dq4_gbb


NameNode是每增加100万个文件块,就增加1G内存;
DataNode是每增加100万个副本,就增加1G内存。
本质上都是管理元数据,可以理解成,各自管理的数据单位量在上100w之后,就增加1G内存。
具体修改:hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"
(144)NN心跳并发配置

在实际生产运行时,每台DataNode会跟NameNode通信,客户端也会并发向NameNode发出申请,那么NameNode准备多少个线程是合适的呢,即NameNode的并发线程数设置成多少合适呢?
一般在hdfs-sit.xml文件中配置:
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大该参数。默认值是10。
<property>
<name>dfs.namenode.handler.countname>
<value>21value>
property>
企业经验:dfs.namenode.handler.count=![]()
,比如集群规模(DataNode台数)为3台时,此参数设置为21。
可通过简单的python代码计算该值,代码如下:
[atguigu@hadoop102 ~]$ sudo yum install -y python
[atguigu@hadoop102 ~]$ python
Python 2.7.5 (default, Apr 11 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import math
>>> print int(20*math.log(3))
21
>>> quit()
(145)开启回收站
开启回收站之后,删除的文件会送进回收站,等待超时后再彻底删除,这样子方便恢复原数据,起到防止误删除、备份等作用。本质上是将文件放在特定目录存储,跟windows的回收站功能一样。
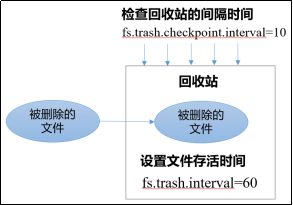
单位是min
参数说明:
- 默认值
fs.trash.interval = 0,0表示禁用回收站;其他值表示设置文件的存活时间; - 默认值
fs.trash.checkpoint.interval = 0,检查回收站的间隔时间,意思是多长时间去检查一次,准备删除文件。如果该值为0,则该值设置和fs.trash.interval的参数值相等; - 要求
fs.trash.checkpoint.interval <= fs.trash.interval
具体启用的话,是修改core-site.xml,配置垃圾回收时间是1分钟:
<property>
<name>fs.trash.intervalname>
<value>1value>
property>
那回收站文件的路径在哪儿呢?
回收站目录在HDFS集群中的路径:/user/atguigu/.Trash/….
需要注意,通过网页上HDFS目录管理里删除的文件并不会走回收站。
通过程序删除的文件同样也不会走回收站,除非你在代码里显式调用了moveToTrash()
Trash trash = New Trash(conf);
trash.moveToTrash(path);
所以只有命令行里,通过hadoop fs -rm指令删除的文件,才会走回收站。且当你执行这个指令的时候,会有以下提示:
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /user/atguigu/input
2021-07-14 16:13:42,643 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop102:9820/user/atguigu/input' to trash at: hdfs://hadoop102:9820/user/atguigu/.Trash/Current/user/atguigu/input
那如何恢复回收站数据呢?
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv
/user/atguigu/.Trash/Current/user/atguigu/input /user/atguigu/input
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】