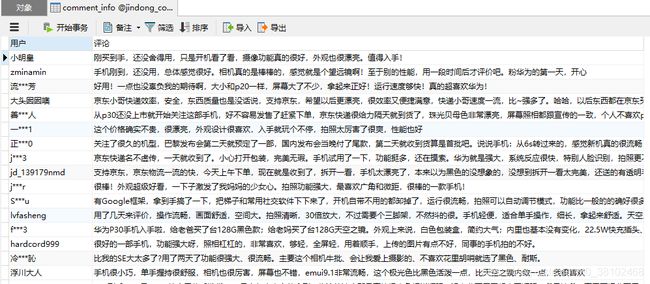
我的爬虫学习之旅 (八) 爬虫实战之京东商品评论爬取
前言:
本次针对待爬取数据是由动态网页技术加载出的情形进行分析,在之前的实战案例中,爬取的数据内容都是随着URL变化来实现页面的跳转,而动态加载的形式使得我们原本可以在页面上看到的内容却在源码中找不到。这时,就需要使用另一种分析页面的方式进行爬虫的编写。
实战案例:爬取京东商品的用户评论
首先打开京东,进入某一指定商品页面,本次选择华为P30的商品信息页面
链接地址:https://item.jd.com/100004404920.html#comment
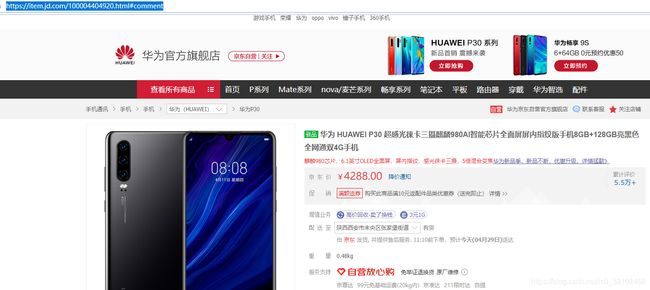
下拉页面,找到评论信息:
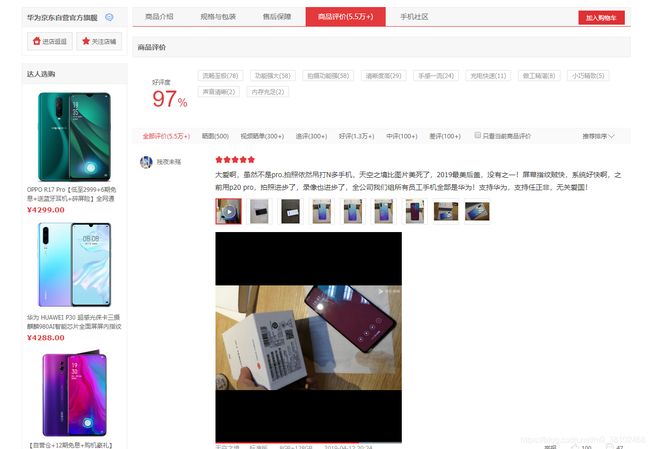
可以看到在这条商品页面中有很多信息元素,于是右键选择查看网页源码,试图寻找用户的评论信息。
然而,在源码信息中,并未找到与评论相关的标签,所以得出结论:评论是由动态页面加载出来的!
依旧进入开发者模式,选择Network,查看加载的全部内容,寻找评论的加载页面。
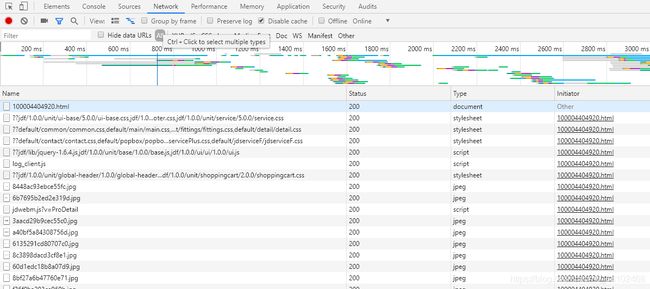
猜测评论应该在属于某个名字带comment有关的页面中,选择Filter进行查找:

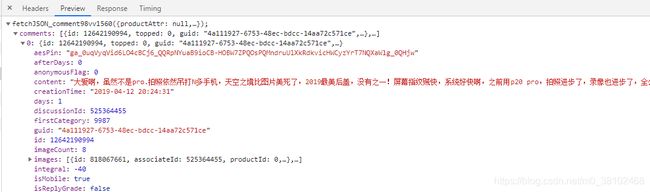
果然找到了真正的评论信息页面!并且可以获得真正的链接地址,存放在Request URL中 。
https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv1560&productId=100004404920&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
接下来进行评论翻页,发现这条URL中的page进行递增变化,则找到了URL随评论页数变化的证据,只需更改page=后的数字便能实现翻页。
查看评论真正页面的源码,发现是JSON的格式。但是在这里有一个小陷阱,这个源码并非严格的JSON格式,所以如果直接request这条URL,返回的response.text是不能够被JSON方法解析的。
经过多次尝试后发现,删除callback=后的这一段内容(fetchJSON_comment98vv1560)后,依然可以正常获取该URL的网页源数据,且为正常的JSON格式。
PS: 用Chrome查看Request Headers时,可能得不到Cookies等信息,经过网上查询后发现这是由Chrome的某些内部设置导致的,只要更换浏览器例如FireFox进入相同页面的开发者模式便能查看到完整请求头信息。
以上分析完毕,对该爬虫程序进行编码:
import requests
import json
import pymysql
import time
import random
from requests.exceptions import RequestException
def get_one_page(url):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
"Referer": "https://item.jd.com/100004404920.html",
"Cookie": "3AB9D23F7A4B3C9B=VCZP7M7YJRJHRR4NROQDRFF3ONPNOOHFBCEKE7ZIEUEEXC55JZMKKTPWVO4SHCLG5MESPVFRKTQIJP2QSZZLPLYA7A; TrackID=1vNcZZ86gqJVNcn0lA8K4G59CKK2xLMVj00TdQGp_qnK7CJUVAFLcRjOf6c-Tdv-qHTCfTItsNsQ0dPvjX8gFdHIxJKyZMEpjpuUgtmG6ups; shshshfp=3f2984513937efb888928303a78596e4; shshshfpa=1cb72623-1e95-9c4e-2289-c706abc21156-1556477337; shshshsID=862bc6bf080fc3ff757e84c12bd2ac4c_2_1556477358058; shshshfpb=vkqdiZw5URKpR4d1GBRYd6g%3D%3D; __jda=122270672.15564773383761543900726.1556477338.1556477338.1556477338.1; __jdb=122270672.2.15564773383761543900726|1.1556477338; __jdc=122270672; __jdv=122270672|direct|-|none|-|1556477338378; __jdu=15564773383761543900726; areaId=27; ipLoc-djd=27-2376-50230-53671; JSESSIONID=1AA5FC953DBCD87E5B49464911847606.s1",
"Host": "sclub.jd.com",
"DNT": "1",
"Accept": "*/*",
"Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept - Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers = headers)
if response.status_code == 200:
print("获取页面成功!")
return response.text
else:
print("获取页面失败,状态码:%d" %response.status_code)
return None
except RequestException:
print("请求失败")
return None
def write_to_DB(user_name, comment):
db = pymysql.connect("localhost", "root", "123456", "jindong_comments")
cursor = db.cursor()
sql="""INSERT INTO comment_P30 VALUES ("%s", "%s")
""" %(user_name, comment)
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
db.close()
def parse_one_page(html):
comments_dict = json.loads(html) # json.loads()使字符串转换为字典形式
comment_list = comments_dict["comments"] # 获取comments标签下的内容,即用户评论信息列表
for item in comment_list:
comment = item["content"]
user_name = item["nickname"]
write_to_DB(user_name, comment)
def main():
# 这次不选择从首评论页进行爬取,而是从随机生成的页数开始爬取评论
rand_num = random.sample(range(100), 100) # 从range(100)中随机获得100个数返回一个列表
for page in rand_num:
url1 = "https://sclub.jd.com/comment/productPageComments.action?callback&productId=100004404920&score=0&sortType=5&page="
url2 = "&pageSize=10&isShadowSku=0&fold=1"
url = url1 + str(page) + url2
html = get_one_page(url)
print("正在爬取第%d页的评论..." %(page+1))
parse_one_page(html)
time.sleep(2)
if __name__ == '__main__':
main()最终在数据库中查看数据,根据这种方法只能爬取到900~1000范围内的评论条数,由于是第一次对动态页面加载内容进行爬取,所以不再深入讨论。如果你有更好的方法,欢迎给我留言讨论。