四川大学软件学院操作系统笔记
关于作者
操作系统分数:96/100
个人主页:https://tzq0301.cn
GitHub:https://github.com/tzq0301
这篇博客的使用方式
此博客笔记结合《操作系统——精髓与设计原理(第九版)》英文版和 PPT 制作而成,没有英文教材的同学可以使用这篇博客进行一定的辅助:
- 若需要找题目答案/相关信息时,按 Ctrl + F 进行关键字搜索即可
- 下划线的内容为遇到的题目的内容
- 加粗的内容为重点
- 有不会的就上外网
一篇很好的文章
https://medium.com/cracking-the-data-science-interview/the-10-operating-system-concepts-software-developers-need-to-remember-480d0734d710
四川大学操作系统选择题
OS操作系统_Solar的专栏-CSDN博客
文章目录
-
- 关于作者
- 这篇博客的使用方式
- 一篇很好的文章
- 四川大学操作系统选择题
- Chapter 1 - Computer System Overview
-
- Basic Elements
- Register
-
- User-Visible Register
- Control and Status Register
-
- Program Counter(PC,程序计数器)
- Instruction Register(IR,指令寄存器)
- Program Status Word(PSW,程序状态字)
- Data Register
- Address Register
- Instruction Execution
- Interrupt
-
- Interrupt Introduction
- Interrupts and the Instruction Cycle
- Interrupt Processing
- Multiple Interrupts
- The Memory Hicrarchy
- Cache Memory
- I/O Communication Techniques
- Multiprogramming and Multicore Organization
-
- Symmetric Multiprocessors (对称多处理机)
- Multicore Computer
- Chapter 2 - Operating System Overview
-
- OS Objectives and Function (操作系统的目标和功能)
-
- The OS as a User/Computer Interface
- The OS as Resource Manager
- Ease of Evolution of an OS
- The Evolution of OS
-
- Serial Processing: No OS
- Simple Batch Systems
- Multiprogrammed Batch Systems
- Time-Sharing Systems
- Major Archievements
-
- The Process
- Memory Management
- Infomation Protection and Security
- Scheduling and Resource Management
- Linux
- Chapter 3 - Process
-
- What is a process
-
- Processes and Process Control Block (PCB,进程控制块)
- Process States
-
- Trace of Process
- Two-State Process Model
- The Creation and Termination of Processes
-
- Process Creation
- Process Termination
- A Five-State Model
- Suspended Processes
- Process Description
-
- Operating System Control Structures (操作系统的控制结构)
- Process Control Structures
-
- Process Location
- Process Attributes
- Process Control
-
- Modes of Execution
- Process Creation
- Process Switching
-
- When to Switch a Process
- Change of Process State
- Execution of The Operating System
-
- Non-process Kernel(无进程内核)
- Execution within User Processes(在用户进程中执行)
- Process-Based Operating System(基于进程的 OS)
- UNIX SVR4 Process Management
- Chapter 4 — Threads
-
- Processes and Threads
-
- Multithreading
- Thread Functionality
-
- Thread Starts
- Thread Synchronization
- Types of Threads
-
- User-Level Threads
- Kernel-Level Threads
- Advantages of ULT to KLT
- Disadvantages of ULT to KLT
- Advantages of KLT to ULT
- Disadvantages of KLT to ULT
- Combined Approaches
- Other Arrangements
- Multicore and Multithreading
- Symmetric Multiprocessing
-
- SMP Architecture
-
- Categories of Computer Systems
- Symmetric Multiprocessing
- Multiprocessor OS Design Considerations
- Microkernel
-
- Microkernel Architecture
- Benefits of a Microkernel Organization
- Microkernel Performance
- Microkernel Design
- Windows Process
- Solaris Thread
- Linux Process
- Chapter 5 - Concurrency
-
- Mutual Exlusion: Software Approaches
-
- Dekker's Algorithm
- Peterson's Algorithm
- Principles of Concurrency
-
- Race Condition
- OS Concerns
- Process Interaction
- Competition among Processes for Resources
- Requirements for Mutual Exclusion
- Mutual Exlusion: Hardware Approaches (互斥:硬件支持)
-
- Interrupt Disabling (中断禁用)
- Special Machine Instructions (专有机器指令)
-
- Compare&Swap Instruction
- Exchange Instruction
- Properties of the Machine-Instruction Approach
- Semaphores (信号量)
-
- Mutual Exclusion
- The Producer/Consumer Problem
- Implement of Semaphores
- Monitors (管程)
-
- Monitor with Signal
- Alternate Model of Monitors with Notify and Broadcast
- Message Passing
-
- Synchronization
- Addressing
- Message Format
- Queueing Discipline
- Mutual Exclusion
- Readers/Writers Problem
-
- Readers Have Priority
- Writers Have Priority
- Chapter 6 — Concurrency: Deadlock and Starvation
-
- Principles of Deadlock
-
- Reusable Resources
- Consumable Resources
- Resource Allocation Graphs (资源分配图)
- The Conditions for Deadlock
- Deadlock Prevention
-
-
- Mutual Exclusion
- Hold and wait
- No Preemption
- Circular Wait
-
- Deadlock Avoidance
-
- Process Initiation Denial (进程启动拒绝)
- Resource Allocation Denial (资源分配拒绝)
- Deadlock Detection
-
- Deadlock Detection Algorithm
- Recovery
- An Intergrated Deadlock Strategy
- Dining Philosophers Problem
-
- Solution Using Semaphores
- Solution Using a Monitor
- Chapter 7 - Memory Management
-
- Memory Management Requirements
-
- Relocation
- Protection
- Sharing
- Logical Organization
- Physical Organization
- Memory Partitioning
-
- Fixed Partitioning
-
- Partition Sizes
- Placement Algorithm
-
- Equal-size partitions
- Unequal-size partitions
- Dynamic Partitioning
-
- Placement Algorithm
- Replacement Algorithm
- Buddy System
- Relocation
- Paging
- Segmentation
- Chapter 8 - Virtual Memory
-
- Hardware and Control Structures
-
- Locality and Virtual Memory
- Paging
-
- Page Table Structure
- Invented Page Table (倒排页表)
- Translation Lookaside Buffer
- Page Size
- Segmentation
-
- Virtual Memory Implications
- Orgazization
- Combined Paging and Segmentation
- Protection and Sharing
- OS Software
-
- Fetch Policy
- Placement Policy
- Replacement Policy
-
- Frame Locking
- Basic Algorithm
- Page Buffering
- Resident Set Management
-
- Resident Set Management
- Replacement Scope
- Fixed Allocation, Global Scope
- Variable Allocation, Global Scope
- Variable Allocation, Local Scope
- Cleaning Policy
- Load Control
-
- Multiprogramming Level
- Process Suspension
- Chapter 9 - Uniprocessor Scheduling
-
- Types of Processor scheduling
-
- Long-term Scheduling
- Medium-term Scheduling
- Short-term Scheduling
- Scheduling Algorithms
-
- Short-term Scheduling Criteria
- The Use of Priorities
- Alternative Scheduling Policies
-
- First-Come-First-Served
- Round-Robin
- Shortest Process Next
- Shorest Remaining Time
- Highest Response Ratio Next
- Feedback
- Performance Comparison
- Fair-Share Scheduling
- Chapter 11 - I/O Management & Disk Scheduling
-
- I/O Devices
- Organization of the I/O Function
-
- Evolution of the I/O Function
- DMA
- OS Design Issues
-
- Design Objectives
- I/O Buffering
-
- Single Buffer (单缓冲)
-
- Block-oriented single buffering
- Stream-oriented single buffer
- Double Buffer
- Circular Buffer
- Disk Scheduling
-
- Disk Performance Parameters
- Disk Scheduling Policies
-
- FIFO
- Priority
- LIFO
- Shortest Service Time First (SSTF)
- SCAN
- C-SCAN (circular SCAN)
- N-step-SCAN
- FSCAN
- RAID
- Disk Cache
-
- Design Considerations
-
- LRU
- LFU
- Chapter 12 - File Management
-
- Overview
-
- File and File Systems
-
- File Management
- File System Properties
- File Operations
- File Structure
- File Management Systems
-
- File System Architecture
- File Management Functions
- File Organization and Access
-
- The Pile
- The Sequential File
- The Indexed Sequential File
- The Indexed File
- The Direct or Hashed File
- File Directories
-
- Contents
- Structure
-
- Simple Structure for a Directory
- Two-level Scheme for a Directory
- Hierarchical, or Tree-Structure Directory
- Naming
- File Sharing
-
- Access Rights
- Simultaneous Access
- Record Blocking (记录组块)
- Secondary Storage Management
-
- File Allocation
-
- Preallocation vs Dynamic Allocation
- File Allocation Methods
-
- Contiguous Allocation
- Chained Allcation
- Indexed Allocation
- Free Space Management
- Reliability
Chapter 1 - Computer System Overview
The OS acts as an interface between the computer hardware and the human user.
The general role of an operating system is to provide a set of services to system users.
An operating system exploits the hardware resources of one or more processors to provide a set of services to system users.
Basic Elements
The four main structural elements of a computer system are Processor, Main Memory, I/O Modules & System Bus.
- Processor: Controls the operation of the computer and performs its data processing functions. When there is only one processor, it is often referred to as the central processing unit (CPU).
- One of the processor’s main functions is to exchange data with memory.
- Main memory: Stores data and programs. This memory is typically volatile (易失性) ; that is, when the computer is shut down, the contents of the memory are lost. In contrast, the contents of disk memory are retained even when the computer system is shut down. Main memory is also referred to as real memory or primary memory.
- Each location in Main Memory contains a binary number value that can be interpreted as either an instruction or data.
- I/O modules: Move data between the computer and its external environment. The external environment consists of a variety of devices, including secondary memory devices (e.g., disks), communications equipment, and terminals.
- System bus: Provides for communication among processors, main memory, and I/O modules. (作用:处理器、内存和I/O模块之间的通信)
Register
What is Registers:Memory inside CPU(处理内部的存储单元)
Why Registers:Enable CPU to minimize main-memory references(减少 CPU 读取内存的次数)
Can be classified into:
- User-Visible Register(用户程序可见寄存器)
- Control and Status Register(控制和状态寄存器)
The two basic types of processor registers are User-visible & Control/Status registers.
User-Visible Register
How to use: May be referenced (访问/存取) by machine/assemble language (机器或汇编指令).
User-visible registers are typically accessible to system programs but are not typically available to all programs.
Registers that are used by system programs to minimize main memory references by optimizing register use are called user-visible registers.
Control and Status Register
Function: are used to control the operation of the processor.
Some may be accessibly by machine instruction in control or system mode.
A Control/Status register that contains the address of the next instruction to be fetched is called the Program Counter (PC).
Program Counter(PC,程序计数器)
Contains the address of an instruction to be fetched. (包含要获取的指令的地址)
Instruction Register(IR,指令寄存器)
Contains the instruction most recently fetched. (包含最近获取的指令)
A fetched instruction is normally loaded into the Instruction Register (IR).
The Instruction Register (IR) contains the most recently fetched instruction.
A fetched instruction is normally loaded into the instruction register (IR).
Program Status Word(PSW,程序状态字)
Condition codes [more detail next]
The Program Status Word contains status information in the form of condition codes, which are bits typically set by the processor hardware as a result of program operation.
Data Register
Data registers are general purpose (通用) in nature, but may be restricted to specific tasks such as performing floating-point operations.
Address Register
Address registers may contain Memory addresses of data, Memory addresses of instructions, Partial memory addresses.
A special type of address register, required by a system that implements user-visible stack addressing, is called a stack pointer.
Instruction Execution
A program to be executed by a processor consists of a set of instructions stored in memory.
PC of CPU holds address of the instruction to be fetched next.
The fetched instruction is loaded into the instruction register.
Two stages of each Instruction Execution: Processor reads/loads/fetches instructions from memory (处理器从内存读取或加载或获取指令); Processor Execute each instruction (处理器执行每条指令).
The processing required for a single instruction on a typical computer system is called the Instruction Cycle.
Instruction Cycle:
- At the beginning of each instruction cycle, the processor fetches an instruction from memory.
- The program counter (PC) holds the address of the next instruction to be fetched.
- Unless instructed otherwise, the processor always increments the PC after each instruction fetch so it will fetch the next instruction in sequence.
The two basic steps used by the processor in instruction processing are Fetch and Execute cycles.
A fetched instruction is normally loaded into the Instruction Register (IR).
The processing required for a single instruction is called a(n) instruction cycle.
Interrupt
Classes of Interrupts: Program, Timer, I/O, Hardware failure.
An arithmetic overflow condition resulting from some instructional execution will generate a(n) program interrupt.
The address of the next instruction is part of the information that must be saved prior to the processor transferring control to the interrupt handler routine, and it tells the processor where to return control to the previously interrupted program.
Interrupt-driven I/O, although more efficient than simple Programmed I/O, still requires the use of the processor to transfer data between memory and an I/O module.
Interrupt Introduction
Why Interrupt in computer system?
- Most I/O devices are slower than the processor, so interrupt can improve CPU’s utilization. (提高CPU利用率)
- Count. (计数)
- Avoid some program to monopolize CPU. (避免CPU被独占)
Introduction Interrupt Definition:
- A mechanism by which other modules (I/O, clock) may interrupt the normal sequencing of the processor.
- Interrupt and Restore/Resume
Interrupts and the Instruction Cycle
When an external device becomes ready to be serviced by the processor, the device sends Interrupt signal to the processor.
An interrupt is a mechanism used by system modules to signal the processor that normal processing should be temporarily suspended.
To accommodate interrupts, a(n) interrupt stage (cycle) is added to the basic instruction cycle.
Interrupt Processing
Suspends the normal sequence of execution.
Information that must be saved prior to the processor transferring control to the interrupt handler routine includes: Processor Status Word (PSW) & Location of next instruction.
Multiple Interrupts
One approach to dealing with multiple interrupts is to disable all interrupts while an interrupt is being processed.
One accepted method of dealing with multiple interrupts is to define priorities for the interrupts.
Methods:
- Disable interrupts while an interrupt is being processed.
- Drawback:It does not take into account relative priority or time-critucal needs.
- Define priorities for interrupts and allow an innterrupt of higher priority to cause a lower-priority interrupt handler to be interrupted.
The Memory Hicrarchy
In a two-level memory hierarchy, the Hit Ratio is defined as the fraction of all memory accesses found in the faster memory.
The memory design dilemma (regarding cost vs. capacity vs. access time) is solved by employing a(n) memory hierarchy.
Speed, Price, Capacity’s confict:
- Faster access time, greater cost per bit.
- Greater capacity, smaller cost per bit.
- Greater capacity, slower access speed.
Three Levels:
- Level 1: Inboard memory ---- Registers, Cache, Main memory
- Level 2: Outboard storage ---- Magnetic disk, CD-ROM, CD-RW, DVD-RW, DVD-RAM, Blu-Ray
- Level 3: Off-line storage ---- Magnetic tape
As one goes down the Hierarchy, the following occur:
- Increasing capacity.
- Increasing access time (that is slow speed).
- Decreasing cost per bit.
- Decreasing frequency of access of the memory by the processor.
Thus, smaller, more expensive, faster memories are supplemented by larger, cheaper, slower memories. The key to the success of this organization is the decreasing frequency of access at lower levels.
Cache Memory
Cache memory exploits the principle of locality by providing a small, fast memory between the processor and main memory.
Memory caching exploits the principle of locality by providing a small, fast memory between the processor and main memory.
In cache memory design, block size refers to the unit of data exchanged between cache and main memory.
Exploit the principle of locality, add something cache between fast and slow memory.
Cache Principles:
Cache memory is intended to provide memory access time approaching that of the fastest memories available, and at the same time support a large memory size that has the price of less expensive types of semiconductor memories.
- Contains a copy of a portion of main memory. (保存主内存部分数据的拷贝)
- Processor first checks cache.
- (Hit) If found, just use it. The byte or word is delivered to the processor. (命中:如果找到,就读入寄存器,不会在访问内存)
- (Miss) If not found in cache, the block of memory containing the needed information is moved to the cache and delivered to the processor. (如果没找到,那把包含需要的数据块,从内存读入到缓存中,然后该数据传递给处理器)
When a new block of data is written into cache memory, the following determines which cache location the block will occupy: mapping function.
Two constraints affect the design of the mapping function:
- When one block is read in, another may have to be repalced.
- The more flexible the mapping function, the more complex is the circuitry required to search the cache to determine if a given block is in the cache.
The replacement algorithm chooses, within the constraints of the mapping function, which block to replace when a new block is to be loaded and all cache slots are already filled.
Replacement algorithm:
- Least-Recently-Used (LRU) algorithm
If the contents of a black in the cache are altered, then it is necessary to write it back to main memory before replacing it.
I/O Communication Techniques
The primary problem with programmed I/O is that the processor must wait for the I/O module to become ready and must repeatedly interrogate (询问) the status of the I/O module while waiting.
Three Methods:
- Programmed I/O(可编程 I/O)
- I/O module performs the action, not the processor. (IO模块执行IO命令,而不是处理器)
- I/O module sets appropriate bits in the I/O status register. (I/O模块在I/O状态寄存器中设置适当的位)
- Processor checks status until operation is complete. (处理器检查状态,直到操作完成)
- Disadvantage: It is a time-consuming process that keeps the processor busy needlessly. (缺点:这是一个耗时的过程,使处理器不必要地忙碌)
- Interrupt-Driven I/O(中断驱动 I/O)
- Processor is interrupted when I/O module ready to exchange data. (当I/O模块准备交换数据时,中断处理器执行)
- Processor saves context of program executing and begins executing interrup-thandler. (处理器保存程序执行的上下文并开始执行中断处理程序)
- The I/O transfer rate is limited by the speed with which the processor can test and service a device.
- The processor is tied up in managing an I/O transfer; a number of instructions must be executed for each I/O transfer.
- Advantage: No needless waiting so more efficient than programmed I/O. (优点:处理器无需等待,比可编程IO更高效)
- Disadvantage: Still consumes a lot of processor time because every word read or written passes through processor. (缺点:仍然会消耗大量处理器时间,因为读写的每个字都要经过处理器)
- Direct Memory Access (DMA,直接内存访问)
- Transfers a block of data directly to or from memory, I/O exchanges occur directly with memory. (直接向内存或从内存中传输数据块,直接与内存进行I/O交换)
- Processor grants DMA module authority to read from or write to memory. (处理器授予DMA模块读写内存的权限)
- Processor continue with other work.
- An interrupt is sent when the transfer is complex. (传输完成时发送中断)
- When the processor wishes to read or write a block of data, it issues a command to the DMA module by sending the following information:
- Whether a read or write is requested
- The address of the I/O device involved
- The starting location in memory to read data from or write data to
- The number of words to be read or written
- Advantage: Relieves the processor responsibility for the exchange.
- Transfers a block of data directly to or from memory, I/O exchanges occur directly with memory. (直接向内存或从内存中传输数据块,直接与内存进行I/O交换)
Multiprogramming and Multicore Organization
Multiprogramming allows the processor to make use of idle time caused by long-wait interrupt handling.
In a uniprocessor system, multiprogramming increases processor efficiency by taking advantage of time wasted by long wait interrupt handling.
The concept of multiple programs taking turns in execution is known as multiprogramming.
If the tima required to complete an I/O operation is much greater than the user code between I/O calls, then the processor will be idle much of the time.
A solution to this problem is to allow multiple user programs to be active at the same time.
Symmetric Multiprocessors (对称多处理机)
Definition: An SMP can be defined as a stand-alone computer system with the following characteristics:
- There are two or more similar processors of comparable capability.
- These processors share the same main memory and I/O facilities and are interconnected by a bus or other internal connection scheme, such that memory access time is approximately the same for each processor.
- All processors share access to I/O devices, either through the same channels or through different channels that provide paths to the same device.
- All processors can perform the same functions (hence the term symmetric).
- The system is controlled by an integrated operating system that provides interaction between processors and their programs at the job, task, file, and data element levels.
Potential Advantages:
- Performance:
- Availability
- Incremental growth
- Scaling
Multicore Computer
A multicore computer, also known as a chip multiprocessor, combines two or more processors (called cores) on a single piece of silicon (called a die).
Chapter 2 - Operating System Overview
The hardware abstraction layer (HAL,硬件抽象层) maps between generic hardware commands/responses and those unique to a specific platform.
The interface to an operating system is often referred to as a shell, because it separates the user from OS details and presents the OS simply as a collection of services.
A distributed operating system provides the illusion of a single main memory space and a single secondary memory space, plus other unified access facilities.
OS Objectives and Function (操作系统的目标和功能)
It can be thought of as having three objectives:
- Convenience: An OS makes a computer more convenient to use.
- Efficiency: An OS allows the computer system resources to be used in an efficient manner.
- Ability to evolve: An OS should be constructed in such a way as to permit the effective development, testing, and introduction of new system functions with out interfering with service.
A primary objective of an operating system is Convenience, Efficiency & Ability to evolve.
The OS as a User/Computer Interface
An operating system controls the execution of applications and acts as an interface between applications and the computer hardware.
The operating system masks the details of the hardware from the application programmer.

Briefly, the OS typically provides services in the following areas:
- Program development (程序开发)
- Program execution (程序运行)
- Access to I/O devices (I/O设备访问)
- Controlled access to files (文件访问控制)
- System access (系统访问)
- Error detection and response (错误检测和响应)
- Accounting (记账)
- Instruction set architecture (ISA)
- Application binary interface (ABI)
- Application programming interface (API)
The operating system provides many types of services to end-users, programmers and system designers, including: Error detection and response.
Definition: A programe that
- controls the execution of application programs
- acts as an interface between applications and hardware
The OS as Resource Manager
The operating system is unusual in it’s role as a control mechanism, in that: It frequently relinquishes control of the system processor and must depend on the processor to regain control of the system.
The kernel or nucleus is the portion of the operating system that remains in main memory during system operation.
Ease of Evolution of an OS
A major OS will evolve over time for a numer of reasons:
- Hardware upgrades plus new types of hardware(硬件升级和新型硬件的出现)
- New services(新的服务/功能)
- Fixes Bug(修复错误)
Operating systems must evolve over time because New hardware is designed and implemented in the computer system.
One of the driving forces in operating system evolution is advancement in the underlying hardware technology.
How to evolve:
- Modularization (模块化)
- OS Architecture (操作系统架构)
An operating system should be modular in construction, allowing it greater flexibility in the evolutionary process.
The operating system maintains information that can be used for billing purposes on multi-user systems.
The operating system’s ability to evolve refers to its inherent flexibility in permitting functional modifications to the system without interruption of services.
The Evolution of OS
In a batch-processing system, the phrase “control is passed to a job” means that the processor is now fetching and executing instructions in a user program.
In a time sharing system, a user’s program is preempted (先占) at regular intervals, but due to relatively slow human reaction time this occurrence is usually transparent to the user.
Which of the following major line of computer system development created problems in timing and synchronization that contributed to the development of the concept of the process? Multiprogramming batch operation systems, Time sharing systems & Real time transaction systems.
Serial Processing: No OS
In the first computers, users interacted directly with the hardware and operating systems did not exist.
Definition: The user have access to the system in series.
Character: The programmer interacted directly with the computer hardware.
Problems:
- Scheduling: Most installations used a hardcopy sign-up sheet to reserve computer time. (大多是都使用一个硬拷贝登记表来预定计算机时间)
- Setup time: Included loading a lots of things. (包括内存加载编译器,源程序,保存编译好的程序,然后加载和链接目标程序)
A major problem with early serial processing systems was: Setup time.
The earliest computers employed serial processing, a name derived by the way the users were forced to access the systems.
Simple Batch Systems
The central idea behind the simple batch-processing scheme is the use of a piece of software known as the monitor.
The Process:
- The monitor reads a job from the batch (监控程序从批处理作业中读入作业)
- Then control is passed to this job(处理器控制交给作业)
- When the job is completed, it returns control to the monitor(当作业完成,返回给监控程序)
- The monitor reads in the next job(监控程序读取下一道作业,然后重复)
Job Control Language (JCL,作业控制语言):
- Special type of programming language(专门的程序语言)
- Provides instruction to the monitor(为监控程序提供指令)
Certain hardware features are as follows:
- Memory protection: While the user program is executing, it must not alter the memory area containing the monitor. (防止更改监视器的内存区域)
- Timer: A timer is used to prevent a single job from monopolizing (垄断) the system. (防止作业独占系统)
- Privileged instructions (特权指令) : Certain machine level instructions are designated as privileged and can be executed only by the monitor. (某些机器级指令只能由监视器执行)
- Interrupts: This feature gives the OS more flexibility in relinquishing control to, and regaining control from, user programs. (此功能使操作系统在放弃对用户程序的控制和重新获得用户程序控制方面具有更大的灵活性)
An example of a hardware feature that is desirable in a batch-processing system is: Privileged instructions.
The special type of programming language used to provide instructions to a monitor in a batch-processing scheme is called Job Control Language (JCL).
CPU mode
- User program executes in user mode
- Certain instructions may not be executed
- Some memory can not be accessed
- Monitor executes in system mode
- Kernel mode
- Privileged instructions are executed
- Protected areas of memory may be accessed
Shortcoming: Processor must wait for I/O instruction to complete before preceding.
Multiprogrammed Batch Systems
Multiprogramming/Multitasking: When one job needs to wait for I/O, the processor can switch to the other job, which is likely not waiting for I/O.
A computer hardware feature that is vital to the effective operation of a multiprogramming operating system is: I/O interrupts and DMA.
The central theme of modern operating systems, based on the concept of switching among multiple programs in memory, is called multiprogramming or multitasking.
Time-Sharing Systems
Requirement: handle multiple interactive users/jobs.
| Batch Multiprogtamming | Time Sharing | |
|---|---|---|
| Principal objective | Maximize processor use | Minimize response time |
| Source of directives to operating system |
Job control language commands provided with the job |
Commands entered at the terminal |
In a time-sharing, multiprogramming system, users interact with the system through terminals.
Major Archievements
A common problem with full-featured operating systems, due to their size and difficulty of the tasks they address, is: Chronically late in delivery, Latent bugs that show up in the field, Sub-par performance.
A technique in which a process, executing an application, is divided into threads that can run concurrently is called Multithreading.
The Process
Implementing priority levels is a common strategy for short-term scheduling, which involves assigning each process in the queue to the processor according to its level of importance.
A process consists of three elements: an executable program, associated data, and a(n) execution context or process state, which includes all information needed by the operating system and processor to manage and execute the process.
Central to the design of operating systems is the concept of process.
Four main causes of such errors:
- Improper synchronization
- Failed mutual exclusion
- Nondeterminate program operation
- Deadlocks
Processes consists of 3 components:
- An executable program/code
- Associated data needed by the program
- Execution context of the program (the core)
The process is realized/implemented as a data structure.
Memory Management
A process can be defined as a unit of activity characterized by a single sequential thread of execution, a current state, and an associated set of system resources.
OS has 5 storage management responsibilities:
- Process isolation(进程隔离)
- Automatic allocation and management(自动分配和管理)
- Support of modular programming(模块化程序设计)
- Protection and access control(保护与存取控制)
- Long-term storage(长期存储)
Virtual Memory / VM:
- Allows programmers to address memory from a logical point of view, without regard to the amount of main memory physically available.
- No hiatus (脱节) between the execution of successive processes while one process was written out to secondary store and the successor process was read in.
Page:
- Allows process to be comprised of a number of fixed-size blocks, called pages(允许进程由许多固定大小的块组成,称为页)
- Each page may be located any where in main memory(可以不连续)
Virtual Memory Addressing: Storage system consists of main memory and auxiliay memory.
A virtual memory address typically consists of a page number and an offset within the page.
The paging system in a memory management system provides for dynamic mapping between a virtual address used in a program and A real address in main memory.
Infomation Protection and Security
Relative to information protection and security in computer systems, access control typically refers to Regulating user and process access to various aspects of the system.
- Availability(可用性)
- Confidentiality(保密性)
- Data integrity(数据完整性)
- Authenticity(认证)
Scheduling and Resource Management
- Manage the resources
- Schedule these resources to various active processes
The factors that should be considered:
- Fairness
- Differential responsiveness
- Efficiency
The short-term queue in the operating system scheduling system consists of processes that are in main memory.
Linux
Linux is one example of a modern UNIX system that implements a modular architecture.
Key to the success of Linux has been it’s character as a free software package available under the auspices of the Free Software Foundation.
Chapter 3 - Process
What is a process
Several definitions of the term process, including:
- A program in execution.
- An instance of a program running on a computer.
- The entity that can be assigned to and executed on a processor.
- A unit of activity characterized by the execution of a sequence of instructions, a current state, and an associated set of system resources.
The principal function of the processor is to execute machine instructions residing in main memory.
The principal responsibility of the OS is to control the execution of processes.
When one process spawns another, the spawning process is referred to as the parent process and the spawned process is referred to as the child process.
Processes and Process Control Block (PCB,进程控制块)
PCB: The information in the preceding list is stored in a data structure.
- Contains the process elements(由一组元素组成)
- Created and manage by the operating system(由操作系统创建和管理)
The Process Image element that contains the collection of attributes needed by the O/S to control a particular process is called the PCB.
The Process Identification, Processor State Information and the Process Control Information are the general categories that collectively make up what is referred to as the process control block.
Process Elements:
- Identifier(标识符,唯一,区别其他进程)
- State(状态,比如正在执行,执行/阻塞状态)
- Priority(优先级,相对其他进程优先顺序)
- Program counter (PC)(程序计数器,下一条指令地址)
- Memory pointers(内存指针,程序和数据)
- Context data(上下文数据,寄存器内容)
- I/O status information(输入/输出状态信息)
- Accounting information(记账信息)
The information in the preceding list is stored in a data structure, typically called a process control block.
When a process is interrupted, the current values of the program counter and the processor registers (context data) are saved in the appropriate fields of the corresponding process control block, and the state of the process is changed to some other value, such as blocked or ready.
Process States
Trace of Process
The behavior of an individual process can be characterized by examining a single process trace.
The behavior of a processor can be characterized by examining the interleaving of the process traces.
The behavior of a processor can be characterized by examining the interleaving of the process traces for the processes currently running on the system.
The listing of a sequence of instructions that execute for a particular process is called a trace.
The sequence of instructions that execute for the process.(进程执行的一列指令)
Dispatcher (调度器) switches the processor from one process to another.(通过进程轨迹来描述操作系统的调度器如何交替切换进程)
The portion of the operating system that selects the next process to run is called the dispatcher.
Two-State Process Model
Process may be in one of two states:
- Running
- Not-Running
The Creation and Termination of Processes
Process Creation
When a new process is to be added to those currently being managed, the OS builds the data structures used to manage the process, and allocates address space in main memory to the process.
Reasons for Process Creation:
- New batch job: The OS is provided with a batch job control stream, usually on tape or disk. When the OS is prepared to take on new work, it will read the next sequence of job control commands.
- Interactive log-on: A user at a terminal logs on to the system.
- Created by OS to provide a service: The OS can create a process to perform a function on behalf of a user program, without the user having to wait.
- Spawned by existing process: For purposes of modularity or to exploit parallelism, a user program can dictate the creation of a number of processes.
When the OS creates a process at the explict request of another process, the action is referred to as process spawning. (当操作系统为另一个进程显式请求创建一个新的进程时,这个动作称为进程派生)
One step in the procedure for creating a new process involves initializing the process control block, allocating space for the process, assigning a unique identifier.
When the OS creates a process at the explicit request of an existing process, the action is referred to as process spawning.
Process Termination
There are a number of conditions that can lead to process termination, including: normal completion, bounds violation, parent termination.
Reasons for Process Termination:
- Normal completion: The process executes an OS service call to indicate that ie has completed running.
- Time limit exceeded: The process has run longer than the specified total time limit.
- Memory unavailable: The process requires more memory than the system can provide.
- Bounds violation (越界) : The process tries to access a memory location that it is not allowed to access.
- **Protection error (保护错误) **: The process attempts to use a resource such as a file that it is not allowed to user, or it tries to use it in an improper fashion, such as writing to a read-only file.
- Arithmetic error: The process tries a prohibited computation (such as division by zero) or tries to store numbers larger than the hardware can accommodate.
- Time overrun: The process has waited longer than a specified maximum for a certain event to occur.
- I/O failure: An error occurs during input or output, such as inability to find a file, failure to read or write after a specified maximum number of tries, or invalid operation.
- Invalid instruction: The process attempts to execute a nonexistent instruction.
- Privileged instruction: The process attempts to use an instruction reserved for the operating system.
- Data misuse: A piece of data is of the wrong type or is not initialized.
- Operator or OS intervention (操作员或操作系统干涉) : For some reason, the operator or the operating system has terminated the process.
- Parent termination: For some reason, the operator or the operating system has terminated the process.
- Parent request: A parent process typically has the authority to terminate any of its offspring.
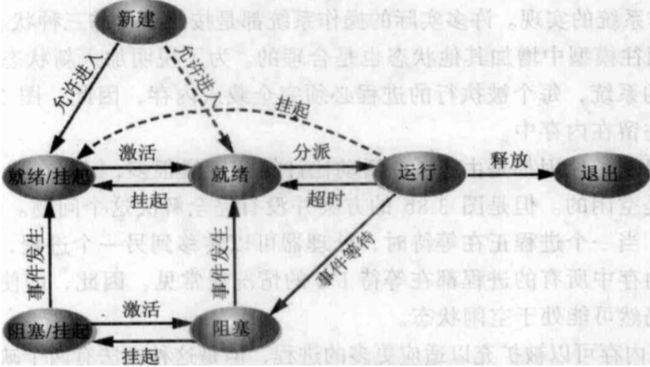
A Five-State Model

Round-Robin processing doesn’t refer to a method of thread prioritization for scheduling. (The queue is a first-in-first-out list and the processor operates in round-robin fashion on the available processes.)
The primary difference between the Two-State Process Model and the Five-State Process Model is that the latter splits the Not Running state into two new states: Ready and Blocked.
A process that cannot execute until some event occurs is said to be in the blocked state.
The scheduling strategy where each process in the queue is given a certain amount of time, in turn, to execute and then returned to the queue, unless blocked is referred to as round-robin (each process in the queue is given a certain amount of time, in trurn, to execute and then returned to the queue, unless blocked).
- Runnning
- Ready
- Blocked / Waiting
- New
- Exit
Passible transitions:
- Null -> New
- New -> Ready
- Ready -> Running
- Running -> Exit
- Running -> Ready
- Running -> Blocked
Suspended Processes
The solution is swapping, which involves moving part or all of a process from main memory to disk.
- When none of the processes in main memory is in the Ready state, the OS swaps one of the blocked processes out on to disk into a suspend queue.
- This is a queue of existing processes that have been temporarily kicked out of main memory, or suspended.
- The OS then brings in another process from the suspend queue or it honors a new-process request.
- Execution then continues with the newly arrived process.
- Processor is faster than I/O so all processes could be waiting for I/O
- Swap these processes to disk to free up more memory
- Blocked state becomes suspend state when swapped to disk
- Two new states
- Blocked/Suspend ( 阻塞 / 挂起 )
- Ready/Suspend ( 就绪 / 挂起 )
New Transitions:
- Blocked -> Blocked/Suspend
- Blocked/Suspend -> Ready/Suspend
- Ready/Suspend -> Ready
- Ready -> Ready/Suspend
In a system that implements two suspend states, a process that has been swapped out of main memory and into secondary memory and that is also awaiting an event is in the Blocked/Suspend state.
Process Description
In order to define the control structures (e.g., tables) that the O/S needs to manage processes and resources, it must have access to configuration data during initialization.
Operating System Control Structures (操作系统的控制结构)
The O/S control structure that the O/S uses to manage system processes is called the process table.
- Information about the current status of each process and resouce. (每个进程和资源的当前状态)
- Tables are constructed for each entity the operating system manages. (操作系统构造并维护他所管理的所有实体的信息表)
Structrue of OS Control Tables:
- Memory table
- Allocation of main memory to processes (分配给进程的主存)
- Allocation of secondary memory to processes (分配给进程的辅存)
- Any protection attributes of blocks of main or virtual memory, such as which processes may access certain shared memory regions (共享内存区域的保护属性)
- Any information needed to manage virtual memory (虚拟内存的管理信息)
- I/O table
- I/O device is available or assigned (分配状态)
- Status of I/O operation (操作状态)
- Location in main memory being used as the source or destination of the I/O transfer (数据传送的源和目的地址)
- File table
- Existence of files (文件是否存在)
- Location on secondary memory (外存的位置)
- Current Status (当前状态)
- Attributes (其他属性信息)
- Process table
- Every entry is a description of a process image (每个进程表项描述了一个进程映像)
Usages of 4 structures:
- Memory tables are used to keep track of both main (real) and secondary (virtual) memory.
- I/O tables are used by the OS to manage the I/O devices and channels of the computer system.
- File tables are used to provide information about the existence of files, their location on secondary memory, their current status, and other attributes.
- Process tables are used to manage processes.
Process Image: Collection of program, data, stack, attributes.
Process Control Structures
Process Location
Typically, the collection of attributes is referred to as a process control block.
We can refer this collection of program, data, stack & attributes as the process image.
The Process Image consists of:
- Program code (or text, and It is not necessary for the processor to read the totality of a process into physical memory when a program is run)
- Program data
- Stack (A process will commonly have at least two LIFO stacks, including a user stack for user mode and a kernel stack for kernel mode)
- Process Control Block (PCB)
The location of a process image will depend on the memory management scheme being used.
To execute the process, the entire process image must be loaded into main memory, or at least virtual memory. Thus, the OS needs to know the location of each process on disk and, for each such process that is in main memory, the location of that process in main memory.
The User Data, User Program, System Stack and Process Control Block elements collectively make up what is referred to as the process image.
Process Attributes
We can group the process control block information into three general categories:
- Process Identification(进程标识 ID)
- Processor State Information(进程状态信息)
- User-Visible Registers(用户可见寄存器)
- Control and Status Registers(控制状态寄存器)
- Stack Pointers(栈指针)
- Process Control Information(进程控制信息)
- Scheduling and State Information
- Data Structing (link information)
- Interprocess Communication
- Process Privileges
- Memory Management
- Resource Ownership and Utilization
The portion of the Process Control Block that consists of the contents of the processor registers is called the Process State Information.
Process Control
Modes of Execution
- User mode
- Less-privileged mode
- User programs typically execute in this mode
- System mode, Control mode or Kernel mode
- Mode-privileged mode
- Kernel of the operating system
- Translation between the two mode
- Processor Status Register (PSR) and Current Pricileged Level (CPL)
The less-privileged processor execution mode is often referred to as user mode.
The processor typically maintains the current operating mode (i.e., user or kernel) in the program status word (PSW).
Process Creation
- Assign a unique process identifier
- Allocate space for the process
- Initialize process control block
- Set up appropriate linkages
- Create or expand other data structures
The first step in creating a new process is to assign a unique process identifier to the new process.
Process Switching
When to Switch a Process
- Interrupt
- Clock interrupt: process has executed for the maximum allowable time slice.
- I/O interrupt
- Memory fault: referenced virtual address is not in main memory, so it must be brought in.
- Trap(陷阱)
- Error or exception occurred.
- May cause process to be moved to Exit state.
- Supervisor call (System Call)
- Such as file open.
One kind of system interrupt, the trap, relates to an error or exception condition in the currently running process.
A process switch may occur when the system encounters an interrupt condition, such as that generated by memory fault, Supervisor call, Trap.
The execution of a user process may be interrupted by a supervisor call, which might be generated by the process requesting an I/O operation.
Change of Process State
- Save the context of the processor, including program counter and other registers.
- Update the process control block of the process that is currently in the Running state.
- Move the process control block of this process to the appropriate queue.
- Select another process for execution; this topic will be explored in Part Four.
- Update the process control block of the process selected.
- Update memory management data structures.
- Restore the context of the processor to that which existed at the time the selected process was last switched out of the Running state, by loading in the previous values of the program counter and other registers.
Execution of The Operating System
Non-process Kernel(无进程内核)
- Execute kernel outside of any process.
- Operating system code is executed as a separated entity that operates in privileged mode.
In the Nonprocess Kernel approach to defining the relationship between the O/S and the User Process, the O/S code is executed as a separate entity that operates in privileged mode.
Execution within User Processes(在用户进程中执行)
- Operating system software within context of a user process.
- Process executes in privileged mode when executing operating system code.
In the separate kernel model for illustrating the relationship between the O/S and User Processes, the O/S has its own region of memory to use and its own system stack for controlling procedure calls and returns.
In the short-term model for illustrating the relationship between the O/S and User Processes, the O/S has its own region of memory to use and its own system stack for controlling procedure calls and returns.
Process-Based Operating System(基于进程的 OS)
- Implement operating system as a collection of system processes.(操作系统大部分功能以进程实现)
- Useful in multi-processor or multi-computer environment.(适用于多处理器、分布式多机环境下)
In the Process Based OS, major kernel functions are organized as separate functions.(主要的内核函数被组织成独立的进程)
UNIX SVR4 Process Management
In a typical UNIX system, the element of the process image that contains the processor status information is the Register context.
Chapter 4 — Threads
Processes and Threads
In an operating system, the unit of dispatching is usually referred to as a thread or lightweight process, while the unit of resource ownership is usually referred to as a process or task.
The concept of a process in an operating system embodies two primary characteristics:
- Resource ownership (资源所有权)
- Scheduling/execution (调度/执行)
Dispatching is referred to as a thread or lightweight process. (调度的单位称为线程或轻量进程)
Resource of ownership is referred to as a process or task. (资源所有权的单位称为进程或者任务)
Multithreading
The basic unit of dispatching in an operating system is usually referred to as a thread or lightweight process.
The concept of thread synchronization is required in multithreaded systems because they share the same address space.
Multithreading refers to the ability of an OS to support multiple, concurrent paths of execution within a single process.
- An example of an operating system that supports a single user process and a single thread is MS-DOS.
- Some UNIX supports multiple user processes but only supports one thread per process.
- An example of a system that implements a single process with multiple threads is Java.
- An example of an operating system that supports multiple user processes and multiple threads is WIN2K/Solaris/Linux/Mach/OS2.
In a multithreaded environment, a process is defined as the unit of resource allocation and a unit of protection (资源分配和保护的单位) .
Within a process, there may be one or more threads, each with the following:
- A thread execution state (Running, Ready, etc.)
- A saved thread context when not running; one way to view a thread is as an independent program counter operating within a process
- An execution stack
- Some per-thread static storage for local variables
- Access to the memory and resources of its process, shared with all other threads in that process
Thread —— Unit of Scheduling/Execution (调度执行的单位)
Each thread has:
- An execution state (running, ready, etc.)
- Saved thread context when not running
- Has an execution stack
- Some per-thread static storage for local variables(一些局部变量的静态存储空间)
- Access to the memory and resources of its process
- all threads of a process share this
All of the threads of a process share the state and resouces of that process.
The key benefits of threads derive from the performance implications:
- It takes far less time to create a new thread in an existing process, than to create a brand-new process.
- It takes less time to terminate a thread than a process.
- It takes less time to switch between two threads within the same process than to switch between processes.
- Threads enhance efficiency in communication between different executing programs.
Threads are affected by many process action:
- Suspending a process involves suspending all threads of the process since all threads share the same address space (挂起进程会挂起该进程的所有线程)
- Termination of a process, terminates all threads within the process (终止进程会终止该进程的所有线程)
Thread Functionality
Thread Starts
There are 4 basic operations associated with a change in thread state:
- Spawn (派生)
- Block (阻塞)
- Unblock (解除阻塞)
- Finish
- Deallocate register context and stacks
On a uniprocessor, multiprogramming enables the interleaving (交叉;交错) of multiple threads within multiple processes.
Thread Synchronization
All of the threads of a process share the same address space and other resources.
It is necessary to synchronize the activities of the various threads so that they do not interfere with each other or corrupt data structures.
Types of Threads
User-Level Threads
In a pure User-Level Thread (ULT) facility, all of the work of thread management is done by the application, and the kernel is not aware of the existence of threads.
Any application can be programmed to be multithreaded by using a threads library, which is a package of routines for ULT management. The threads library contains code for creating and destroying threads, for passing messages and for saving and restoring thread contexts.
- Multithread implemented by a threads library(线程的机制由线程库实现)
- All thread management is done by the application(线程由应用程序管理)
- The kernel is not aware of the existence of threads & scheduling is done on a process basis(内核透明,调度基于进程)
Kernel-Level Threads
In a pure KLT facility, all of the work of thread management is done by the kernel.
- The kernel maintains context information for the process as a whole and for the individual threads within the process.
- Scheduling by the kernel is done on a thread basis.
Advantages of ULT to KLT
- Less overhead of thread switches (mode switches do not required) (线程切换的开销小)
- Scheduling can be application specific (调度可以是特定于应用程序的)
- ULTs can run on any OS (用户级线程可以运行在任何操作系统)
Disadvantages of ULT to KLT
One of the disadvantages of User-Level Threads (ULTs) compared to Kernel-Level Threads (KLTs) is: when a ULT executes a system call, all threads in the process are blocked.
- In a typival OS, many system calls are blocking. One thread is blocked, all other threads of the process are blocked.
- A multithreaded application cannot take advantage of multiprocessing (不能有效的利用多处理器的优势)
Ways (解决方案) to work around these drawbacks:
- Multiple processes (多线程变成多进程)
- Jacketing (把阻塞式系统调用改造成非阻塞式系统调用)
Advantages of KLT to ULT
- Multiple threads in one process can simultaneously run on multiple processors (线程能同时在多处理器上运行)
- One threads blocked cannot make the other threads within the same process blocked (一个线程阻塞不会引起在同一进程里的线程阻塞)
- Kernel routines themselves can be multithreaded (内核本身就可以多线程,提高效率)
Disadvantages of KLT to ULT
- The principal disadvantage is that thread switch requires mode switchs to kernel.
Combined Approaches
- Thread creation done in the user space (在用户空间创建线程)
- The multiple ULTs from a single application are mapped onto some sumber of KLTs (用户级线程映射到内核级,一般内核级数量小于或等于用户级线程)
- Bulk of scheduling and synchronization of threads with application (应用程序中的线程分组进行调度和同步)
Other Arrangements
In the field of distributed operating system design, the One-to-Many (Thread-to-Process) relationship is particularly interesting because it involves the concept of thread migration.
The Clouds O/S implements the concept of a thread as primarily an entity that can move among address spaces which represents the One-to-Many Thread-to-Process relationship.
Multicore and Multithreading
One disadvantage to the master/slave shared-memory multiprocessor architecture is that the failure of the master brings down the whole system.
Symmetric Multiprocessing
Symmetric Multiprocessing (对称多处理)
In a symmetric multiprocessing (SMP) system, each processor has access not only to a private main memory area but also to a shared main memory.
An SMP OS manages processor and other resources so that the user may view the system in the same fashion as a multiprogramming uniprocessor system.
In a SMP system, each processor maintains a local cache and must alert all other processors that a change to cache update has taken place. This is referred to as the Cache coherency problem.
In most modern computer systems, processors generally have at least one level of cache memory that is private to the processor.
With multiple active processes in an SMP system having potential access to shared address space or shared I/O resources, care must be taken to provide effective synchronization.
SMP Architecture
Categories of Computer Systems
- Single Instruction Single Data (SISD, 单指令单数据流)
- Single processor executes a single instruction stream to operate on data stored in a single memory.
- Single Instruction Multiple Data (SIMD, 单指令多数据流)
- A single instruction controls the simultaneous execution of a number of processing elements on a lockstep basis. (一个机器指令控制许多处理部件步伐一致的同时执行)
- Each instruction is executed on a different set of data by the different processors(每个指令由不同的处理器在不同的数据集上执行)
- E.g. vector and array processors(向量和阵列处理器)
- Multiple Instruction Multiple Data (MIMD, 多指令多数据流)
- A set of processors simultaneously execute different instruction sequences on different data sets.
Symmetric Multiprocessing
In a symmetric multiprocessor system, the kernel can execute on any processor, and typically each processor does self-scheduling from the pool of available processes or threads.
- Kernel can execute on any processor. (内核可以在任何处理器上执行)
- Typically each processor does self-scheduling from the pool of available processes or threads. (通常每个处理器都会自动调度可用进程或线程的池)
Multiprocessor OS Design Considerations
Key issues involved in the design of multiprocessor operating systems include: Scheduling, Synchronization & Reliability and fault tolerance.
- Simultaneous concurrent processes or threads
- Scheduling (调度)
- Synchronization (同步,避免调度冲突)
- Memory management
- Reliablity and fault tolerance (可靠性和容错)
Microkernel
The primary disadvantage of the basic microkernel design over layered kernel designs involves performance.
The philosophy underlying the microkernel is that only absolutely essential core operating system functions should be in the kernel.
The basic form of communication between processes or threads in a microkernel OS is messages.
In the layered O/S architecture, functions are organized hierarchically and interaction only takes place between adjacent sections.
Microkernel Architecture
Early operating systems that were designed with little concern about structure are typically referred to as Monolithic operating systems.
- Small operating system core(小型的操作系统核心)
- Contains only essential core operating systems functions(只包含基本的核心操作系统功能)
- Many services traditionally included in the operating system are now external subsystems(许多传统上包含在操作系统中的服务现在都是外部子系统)
- Device drivers(驱动程序)
- File systems(文件系统)
- Virtual memory manager(虚拟内存)
- Windowing system(窗口系统)
- Security services(安全服务)
- 相对的内核称为单体内核 — monolithic kernel
Benefits of a Microkernel Organization
A benefit of the microkernel organization is Extensibility, Portability & Flexibility.
One advantage of the microkernel architecture is extensibility, allowing the addition of new services as well as the provision of multiple services in the same functional area.
- Uniform interface (一致接口) on request made by a process
- Don’t distinguish between kernel-level and user-level services(不区分是内核级还是用户级服务)
- All services are provided by means of message passing(所有服务通过消息传递)
- Extensibility (可扩展性)
- Allows the addition of new services(很容易添加新的服务)
- Flexibility (灵活性)
- New features added
- Existing features can be subtracted (删减)
- Portability (可移植性)
- Changes needed to port the system to a new processor is changed in the microkernel - not in the other services
- Reliability (可靠性)
- Modular design
- Small microkernel can be rigorously tested
- Distributed system support
- Message are sent without knowing what the target machine is (消息的发送不用关心目标是本机还是异机)
- Object-oriented operating system
- Components are objects with clearly defined interfaces that can be interconnected to form software (定义接口明晰的组件,以搭积木方式通过组件互联构造软件)
Microkernel Performance
- A potential disadvantage of microkernels that is often cited is that of performance (消息传递机制是微内核工作的主要机制,消息传递必须通过内核,因此性能较差)
- One response to this problem was to enlarge the microkernel by reintegrating critical servers and drivers back into the OS (把关键服务重新纳入内核,减少消息传递开销)
Microkernel Design
In low-level microkernel memory management, an example of an operation that can support external paging and virtual memory management is the Grant operation, Map operation & Flush operation.
The basic form of communication between processes or threads in a microkernel O/S is messages.
The microkernel must include those functions that depend directly on the hardware. Those functions fall into the following general categories:
- Low level memory management(低级的内存管理)
- Interprocess communication (IPC)(进程间通信)
- I/O and interrupt management(IO和中断管理)
Windows Process
Windows 2000 is an object-oriented OS, and both processes and threads are implemented as objects in the WIN2K OS.
In a W2K system, the state that a thread enters when it has been unblocked and the resource for which it has been blocked is not yet available is called the Transition state.
In a Windows 2000 system, a process that has been selected to run next on a particular process moves from the Ready state to the Standby state.
Solaris Thread
In the Solaris O/S, a User-Level Thread (ULT) in the active state is assigned to a Light-Weight Process (LWP) and executes while the underlying kernel thread executes.
In a Solaris system, a User-Level Thread (ULT) that enters the active state is assigned to a Light-Weight Process (LWP).
In a Solaris system, a User-Level Thread (ULT) in the active state is assigned to a(n) light-weight process (LWP), and executes while the underlying kernel thread executes.
Linux Process
Linux makes no distinction between a process and a thread.
In the Linux O/S, multiple threads may be created and executed within a single process. This is an example of the following Thread-to-Process relationship: M: 1.
In a Linux system, when a new process is cloned, the two processes share the same Virtual memory.
In a Linux system, if the process has been terminated but, for some reason, still must have its task structure in the process table is in the zombie state.
Chapter 5 - Concurrency
Concurrency arises in three different contexts:
- Multiple application (多个应用程序) : Multiprogramming was invented to allow processing time to be dynamically shared among a number of active applications.
- Structured application (结构化应用程序) : As an extension of the principles of modular design and structured programming, some applications can be effectively programmed as a set of concurrent processes.
- OS structure (操作系统结构) : The same structuring advantages apply to systems programs, and we have seen that OSs are themselves often implemented as a set of processes or threads.
Concurrency plays a major part in which of the following specific contexts: Multiple applications & Structured applications & O/S structure.
Some Key Terms Related to Concurrency:
| Key Terms | Introduce |
|---|---|
| Atomic operation (原子操作) |
A function or action implemented as a sequence of one or more instructions that appears to be indivisible; that is, no other process can see an intermediate state or interrupt the operation. |
| Critical section (临界区) |
A section of code (临界区是一段程序) within a process that requires access to shared resources, and that must not be executed while another process is in a corresponding section of code. |
| Deadlock (死锁) |
A situation in which two or more processes are unable to procees because each is waiting for one of the others to do something. |
| Livelock (活锁) |
A situation in which two or more processes continuously change their states in response to changes in the other process(es) without doing any useful work. |
| Mutual exclusion (互斥) |
The requirement that when one process is in a critical section that access shared resources, no other process may be in a critical section that accesses any of those shared resources. |
| Race condition (竞争条件) |
A situation in which multiple threads or processes read and write a shared data item, and the final result depends on the relative timing of their execution. |
| Starvation (饥饿) |
A situation in which a runnable process is overlooked indefinitely by the scheduler; although it is able to procees, it is never chosen. |
Distributed processing can be defined as the management of multiple processes executing on multiple, distributed computer systems.
Both process interleaving and process overlapping are examples of concurrent processes and both present the same basic problems.
Concurrency issues are a concern on multiprocessor systems, and do impact uniprocessor systems.
Starvation refers to the situation where competing processes are denied access to a resource due to scheduling problems.
A basic echo procedure (that echoes a typed character to the screen) running on a multiprocessor system can produce erroneous output if access to the echo procedure is unsynchronized.
In order to implement mutual exclusion on a critical resource for competing processes, only one program at a time should be allowed: In the critical section of the program.
Processes that are designed to be able to pass execution control back and forth between themselves are referred to as: Coroutines.
In order to protect shared variables (and other shared global resources) the system must control the ________________________________.
ANS: code that accesses the variable
The situation where Process 1 (P1) holds Resource 1 (R1), while P2 holds R2, and P1 needs R2 to complete and P2 needs R1 to complete is referred to as _______________.
ANS: deadlock
In multiprocessor configurations, special machine instructions that carry out two actions in a single instruction cycle are said to do so _______________.
ANS: atomically
Mutual Exlusion: Software Approaches
Dekker’s Algorithm
boolean flag[2];
int turn;
void P0() {
while (true) {
flag[0] = true;
while (flag[1]) {
if (turn == 1) {
flag[0] = false;
while (turn == 1) {}
flag[0] = true;
}
}
/* critical section */;
turn = 1;
flag[0] = false;
/* remainder */;
}
}
void P1() {
while (true) {
flag[1] = true;
while (flag[0]) {
if (turn == 0) {
flag[1] = false;
while (turn == 0) {}
flag[1] = true;
}
}
/* critical section */;
turn = 0;
flag[1] = false;
/* remainder */;
}
}
void main() {
flag[0] = false;
flag[1] = false;
turn = 1;
parbegin(P0, P1);
}
Peterson’s Algorithm
Peterson’s Algorithm for solving mutual exclusion is only valid for two processes and can easily be generalized to the case of n processes.
boolean flag[2];
int turn;
void P0() {
while (true) {
flag[0] = true;
turn = 1;
while (flag[1] && turn == 1) {}
/* critical section */;
flag[0] = false;
/* remainder */;
}
}
void P1() {
while (true) {
flag[1] = true;
turn = 0;
while (flag[0] && turn == 0) {}
/* critical section */;
flag[1] = false;
/* remainder */;
}
}
void main() {
flag[0] = false;
flag[1] = false;
parbegin(P0, P1);
}
Principles of Concurrency
In a uniprocessor machine, concurrent processes cannot be overlapped; they can only be interleaved.
Some difficulties:
- The sharing of global resouces is fraught with peril. (充满危险)
- It is difficult for the OS to optimally manage the allocation of resouces.
- It becomes very difficult to locate a programming error because results are typically not deterministic and reproducible.
Race Condition
A race condition occurs when multiple processes or threads read and write data items so that the final result depends on the order of execution of instructions in the multiple processes.
OS Concerns
- Keep track of various processes (through PCB)
- Allocate and deallocate resources
- Processor time
- Memory
- Files
- I/O devices
- Protect data and resources
- Output of process must be independent of the speed of execution of other concurrent processes
Process Interaction
- Processes unaware of each other (进程之间相互不知道对方的存在)
- Process indirectly aware of each other (进程间接知道对方的存在)
- Process directly aware of each other (进程直接知道对方的存在)
Competition among Processes for Resources
Each process is unaware of the existence of other processes. It follows from this each process should leave the state of any resource that it uses unaffected. Examples of resources include I/O devices, memory, processor time, and the clock.
There is no exchange of information between the competing processes. However, the execution of one process may affect the behavior of competing processes.
- Multual Exclusion (互斥)
- Deadlock (死锁)
- Starvation (饥饿)
Requirements for Mutual Exclusion
- Mutual exclusion must be enforced: Only one process at a time is allowed into its critical section, among all processes that have critical sections for the same resource or shared object.
- A process that halts in its noncritical section must do so without interfering with other processes.
- It must not be possible for a process requiring access to a critical section to be delayed indefinitely: no deadlock or starvation.
- When no process is in a critical section, any process that requests entry to its critical section must be permitted to enter without delay.
- No assumptions are made about relative process speeds or number of processors.
- A process remains inside its critical section for a finite time only.
Any facility or capability that is to provide support for mutual exclusion must make certain assumptions about relative process speeds and the number of processors in the system.
ANS: F (no assumptions should be made regarding these parameters)
The following requirement must be met by any facility or capability that is to provide support for mutual exclusion:
- Only one process at a time can be allowed into a critical code section
- A process remains in its critical code section for a finite time only
- No assumptions can be made about relative process speeds
- All of the above
ANS: D
The basic requirement for support of concurrent process is the ability to enforce _______________.
ANS: mutual exclusion
When only one process is allowed in its critical code section at a time, then _______________ is enforced.
ANS: mutual exclusion
Mutual Exlusion: Hardware Approaches (互斥:硬件支持)
Interrupt Disabling (中断禁用)
- A process runs until it invokes an OS service or until it is interrupted. (如果不调用操作系统服务或被中断,进程将一直运行)
- Disabling interrupts guarantees mutual exclusion on uniprocessor system. (禁用中断可以保证单处理器系统上的互斥)
Disadvantage:
- Processor is limited in its ability to interleave programs. (限于交替执行)
- Dissabling interrupts on one processor will not guarantee mutual exclusion in multi-processors environment. (多处理器失效)
In a uniprocessor system, mutual exclusion can be guaranteed by: Disabling interrupts.
Special Machine Instructions (专有机器指令)
Special Machine Instructions
- Performed in a single instruction cycle
- Access to the memory locations is blocked for any other instructions
Compare&Swap Instruction
int compare_and_swap(int* word, int testval, int newval) {
int oldval;
oldVal = *word;
if (oldval == testval) *word = newval;
return oldval;
}
This atomic instruction has two parts: A compare is made between a memory value and a test value; if the values are the same, a swap occurs. The entire compare&swap function is carried out atomically – that is, it is not subject to interrupt.
const int n = /* number of processes */;
int bolt;
void P(int i) {
while (true)
while (compare_and_swap(bolt, 0, 1) == 1)
/* do nothing */
/* critical section */;
bolt = 0;
/* remainder */;
}
void main() {
bolt = 0;
parbegin (P(1), P(2), ... , P(n));
}
The term busy waiting (忙等待), or spin waiting (自旋等待), refers to a technique in which a process can do nothing until it gets permission to enter its critical section.
Examples of solutions to the concurrency problem that do not involve busy waiting are the following:
-
A. Semaphores and monitors
-
B. Message passing and caching
-
C. Producers and consumers
-
D. None of the above
ANS: D (all software solutions involve some form of busy waiting)
Many approaches to achieving mutual exclusion are software solutions that require the use of a technique called ___________________.
ANS: busy waiting
The technique in which a process can do nothing until it gets permission to enter its critical section but continues to test the appropriate variable to gain entrance is called _____________.
ANS: busy waiting
Exchange Instruction
void exchange(int* register, int* memory) {
int temp;
temp = *memory;
*memory = *register;
*register = temp;
}
The instruction exchanges the contents of a register with that of a memory location.
const int n = /* number of processes */;
int bolt;
void P(int i) {
while (true) {
int keyi = 1;
do exchange(&keyi, &bolt)
while (keyi != 0);
/* critical section */;
bolt = 0;
/* remainder */;
}
}
void main() {
bolt = 0;
parbegin (P(1), P(2), ... , P(n));
}
Properties of the Machine-Instruction Approach
Advantages:
- It is applicable to any number of processes on either a single processor or multiple processors sharing main memory. (适合共享内存的单/多处理器上任意数目的进程)
- It is simple and therefore easy to verify. (简单易于验证)
- It can be used to support multiple critical sections; each critical section can be defined by its own variable. (可以支持多个临界区)
Disadvantages:
- Busy waiting is employed
- Starvation is possible
- Deadlock is possible
Semaphores (信号量)
| Common Concurrency Mechanism | Introduction |
|---|---|
| Semaphore (信号量) |
An integer value used for signaling among processes. Only three operations may be performed on a semaphore, all of which are atomic: initialize, decrement, and increment. The decrement operation may result in the blocking of a process, and the increment operation may result in the unblocking of a process. |
| Binary semaphore (二元信号量) |
A semaphore that takes on only the values 0 and 1. |
| Mutex (互斥量) |
Similar to a binary semaphore. A key difference between the two is that the process that locks the mutex (set the value to 0) must be the one to unlock it. |
| Condition variable (条件变量) |
A data type that is used to block a process or thread until a particular condition is true. |
| Monitor (管程) |
A programming language construct that encapsulates (封装) variables, access procedures, and initialization code within an abstract data type. The monitor’s variable may only be accessed via its access procedures and only one process may be actively accessing the |
| Event flags (事件标志) |
A memory word used as a synchronization mechanism. Application code may associate a different event with each bit in a flag. A thread can wait for either a single event or a combination of events by checking one or multiple bits in the corresponding flag. The thread is blocked until all of the required bits are set (AND) or until at least one of the bits is set (OR). |
| Mailboxes/messages (信箱/消息) |
A means for two processes to exchange information and that may be used for synchronization. |
| Spinlocks (自旋锁) |
Mutual exclusion mechanism in which a process executes in an infinite loop waiting for the value of a lock variable to indicate availability. |
Fundamental principle: Two or more processes can cooperate by means of simple signals, such that a process can be forced to stop at a specified place until it has received a specific signal. (两个或者多个进程可以通过简单的信号进行合作,一个进程可以被迫在一个位置停止,直到它收到一个信号)
For signaling, special variables called semaphores are used. (一种称为信号量的特殊变量用来传递信号)
If the corresponding signal has not yet been transmitted, the process is suspended until the transmission takes place. (如果一个进程在等待一个信号,它会被挂起,直到它等待的信号被发出)
To achieve the desired effect, we can view the semaphore as a variable that has an integer value upon which only three operations are difined:
- A semaphore may be initialized to a nonnegative integer value.
- The semWait § operation decrements the semaphore value. If the value becomes negative, then the process executing the semWait is blocked. Otherwise, the process continues execution.
- The semSignal (V) operation increments the semaphore value. If the value becomes negative value is less than or equal to zero, then a process blocked by a semWait operation, if any, is unblocked.
A binary semaphore may only take on the values 0 or 1, and can be defined by the following three operations:
- A binary semaphore may be initialized to 0 or 1.
- The semWaitB § operation checks the semaphore value. If the value is zero, then the process executing the semWaitB is blocked. If the value is one, then the value is changed to zero and the process continues execution.
- The semSignalB (V) operation checks to see if any processes are blocked on this semaphore (semaphore value equals 0). If so, then a process blocked by a semWaitB operation is unblocked. If no processes are blocked, then the value of the semaphore is set to one.
In principle, it should be easier to implement the binary semaphore, and it can be shown that it has the same expressive power as the general semaphore. To contrast the two types of semaphores, the nonbinary semaphore is often referred to as either a counting semaphore or a general semaphore.
A concept related to the binary semaphore is the mutual exclusion lock (mutex). A mutual is a programming flag used to grab and release an object. When data are acquired that cannot be shared, or processing is started that cannot be performed simultaneously elsewhere in the system, the mutex is set to lock (typically zero), which blocks other attempts to use it. The mutex is set to unlock when the data are no longer needed or the routine is finished. A key difference between a mutex and a binary semaphore is that the process that locks the mutex (sets the value to 0) must be the one to unlock it (sets the value to 1).
For both counting semaphores and binary semaphores, a queue is used to hold processes waiting on the semaphore. The question arises of the order in which processes are removed from such a queue. A semaphore whose difinition includes FIFO is called a strong semaphore. A semaphore that does not specify the order in which processes are removed from the queue is a weak semaphore.
Weak semaphores do not guarantee freedom from starvation, but strong semaphores do.
The major difficulty with semaphores is that wait and signal operations may be scattered throughout a program and it is difficult to see the overall effect of these operations on the semaphores they affect.
A semaphore that does not specify the order in which processes are removed from the queue is called a: Weak semaphore.
A semaphore whose definition includes the FIFO policy for releasing blocked processes from the queue is called a _________________.
ANS: strong semaphore
The Barbershop Problem uses ________________ to implement concurrency.
ANS: semaphores
Mutual Exclusion
At any time, the value of s.count() can be interpreted as follows:
- s . c o u n t ( ) > = 0 s.count() >= 0 s.count()>=0: s.count() is the number of processes that can execute semWait(s) without suspension (if no semSignal(s) is executed in the meantime). Such situations will allow semaphores to support synchronization as well as mutual exclusion.
- s . c o u n t ( ) < 0 s.count()<0 s.count()<0: The magnitude of s.count() is the number of processes suspended in s.queue.
The Producer/Consumer Problem
One or more producers are generating data and placing these in a buffer. (一个或多个生产者进程/线程生成数据并将其放入缓冲区)
A single consumer is taking items out of the buffer one at time. (有一个消费者进程/线程每次从缓冲区中取出一个数据项)
Only one producer or consumer may access the buffer at any one time. (任何时候只有一个生产者/消费者可以进入缓冲区)
The probleam is to make sure that the producer won’t try to add data into the buffer if it’s full, and that the consumer won’t try to remove data from an empty buffer.
A finite circular buffer and an infinite buffer are two ways to implement a data storage area for the classic Producer/Consumer Problem.
The Producer/Consumer problem is typically considered a special case of the Readers/Writes problem, with only one reader and one writer.
ANS: F (the producer and consumer must both read and write)
The finite circular buffer is used to implement which of the following basic queuing strategies: FIFO.
The classic concurrency problem that involves readers and writers that can both read from and write to a shared data area is the __________________ Problem.
ANS: Producer/Consumer
Infinite:
producer:
while (true) {
/* produce item v */;
b[in] = v;
in++;
}
consumer:
while (true) {
while (in <= out)
/* do nothing */;
w = b[out];
out++;
/* consumer item w */;
}
// A Correct Solution to the Infinite-Buffer Producer/Consumer Problem Using Binary Semaphores
int n; // 缓冲区中的项数
binary_semaphore s = 1; // 控制进入临界区
binary_semaphore delay = 0; // 避免“超前”消息
void producer() {
while (true) {
produce();
semWaitB(s);
append();
n++;
if (n == 1) semSignalB(delay);
semSignalB(s);
}
}
void consumer() {
int m;
semWaitB(delay);
while (true) {
semWaitB(s);
take();
n--;
m = n;
semSignalB(s);
consume();
if (m == 0) semWaitB(delay);
}
}
void main() {
n = 0;
parbegin (producer, consumer);
}
// A Solution to the Infinite-Buffer Producer/Consumer Problem Using Semaphores
semaphore n = 0; // 控制“超前”消息
semaphore s = 1; // 控制进入临界区
void producer() {
while (true) {
produce();
semWait(s);
append();
semSignal(s);
semSignal(n);
}
}
void consumer() {
while (true) {
semWait(n);
semWait(s);
take();
semSignal(s);
consume();
}
}
void main() {
parbegin (producer, consumer);
}
Bounded:
producer:
while (true) {
/* produce item v */;
while ((in + 1) % n == out)
/* do nothing */;
b[in] = v;
in = (in + 1) % n;
}
consumer:
while (true) {
while (in == out)
/* do nothing */;
w = b[out];
out = (out + 1) % n;
/* consumer item w */;
}
// A Solution to the Bounded-Buffer Producer/Consumer Problem Using Semaphores
const int sizeofbuffer = /* buffer size */;
semaphore n = 0; // 控制“超前”消息
semaphore s = 1; // 控制进入临界区
semaphore e = sizeofbuffer; // 控制生产“过剩”
void producer() {
while (true) {
produce();
semWait(e);
semWait(s);
append();
semSignal(s);
semSignal(n);
}
}
void consumer() {
while (true) {
semWait(n);
semWait(s);
take();
semSignal(s);
semSignal(e);
consume();
}
}
void main() {
parbegin (producer, consumer);
}
Implement of Semaphores
- Implement in hardware or fireware (固件)
- Implement in software, e.g. Dekker or Peterson
- Implement by inhibit interrupts (中断禁止) for a single-processor system
Monitors (管程)
The monitor is a programming language construct that provides equivalent functionality to that of semaphores and that is easier to control.
Monitor with Signal
The monitor is a software module consisting of one or more procedures, an initialization sequence, and local data. And the chief characteristics are the following:
- The local data variables are accessible only by the monitor’s procedures and not by any external procedure.
- A process enters the monitor by invoking one of its procedures.
- Only one process may be executing in the monitor at a time; any other processes that have invoked the monitor are blocked, waiting for the monitor to become available.
A chief characteristic of a monitor is: A process enters the monitor by invoking one of its procedures.
A monitor supports synchronization by the use of condition variables that are contained within the monitor and accessible only within the monitor. Condition variables are a special data type in monitors, which are operated on by two functions:
- cwait©: Suspend execution of the calling process on condition c. The monitor is now available for use by another process.
- csignal©: Resume execution of some process blocked after a cwait on the same condition. If there are several such processes, choose one of them; if there is no such process, do nothing.
monitor boundedbuffer; // space for N items
char buffer[N]; // buffer pointers
int nextin, nextout; // number of items in buffer
cond notfull, notempty; // condition variables for synchronization
void append(char x) {
if (count == N) cwait(notfull); // buffer is full; avoid overflow
buffer[nextin] = x;
nextin = (nextin + 1) % N;
count++;
/* one more item in buffer */;
csignal(notempty); // resume any waiting consumer
}
void take(char x) {
if (count == 0) cwait(notempty); // buffer is empty; avoid underflow
x = buffer[nextout];
nextout = (nextout + 1) % N;
count--; // one fewer item in buffer
csignal(notfull); // resume any waiting producer
}
{
nextin = 0;
nextout = 0;
count = 0;
}
void producer() {
char x;
while (true) {
produce(x);
append(x);
}
}
void consumer() {
char x;
while (true) {
take(x);
consume(x);
}
}
void main() {
parbegin (producer, consumer);
}
As with semaphores, it is possible to make mistakes in the synchronization function of monitors.
The advantage that monitors have over semaphores is that all of the synchronization has been done correctly and to detect bugs.
Alternate Model of Monitors with Notify and Broadcast
There are two drawbacks to the approach:
- If the process issuing the csignal has not finished with the monitor, then two additional process switches are required: one to block this process, and another to resume it when the monitor becomes available.
- Process scheduling associated with a signal must be perfectly reliable.
Message Passing
When processes interact with one another, two fundamental requirements must be satisfied: synchronization and communication. Processes need to be synchronized to enforce mutual exclusion; cooperating processes may need to exchange information. One approach to providing both of these functions is message passing.
The actual function of message passing is normally provided in the form of a pair of primitives:
- send(destination, message)
- receive(source, message)
Message passing provides both synchronization and communication, which are fundamental requirements for interacting processes.
Synchronization
Sender and receiver may or may not be blocking. Three communications are common, although any particular system will usually have only one or two combinations implemented:
- Blocking send, blocking receive
- Both sender and receiver are blocked until message is delivered
- Nonblocking send, blocking receive
- Sender continues on
- Receiver is blocked until the requested message arrives
- Nonblocking send, nonblocking receive
- Neither party is required to wait
In the communications mechanism of a message passing system, both sender and receiver can be blocking or non-blocking.
In synchronization involving message passing, the sender of a message can be: Either blocking or non-blocking.
A blocking send, blocking receive message passing scenario is sometimes referred to as a ________________.
ANS: rendezvous
Addressing
Direct addressing (直接寻址):
- Send primitive includes a specific identifier of the destination process.
- Receive primitive could know ahead of time which process a message is expected or receive primitive could use source parameter to return a value when the receive operation has been performed.
In the _____________ addressing implementation of message passing, the “send” primitive includes a specific identifier of the destination process.
ANS: direct
Indirect addressing (间接寻址):
- Messages are sent to a shared data structure consisting of queues.
- Queues are called mailboxed.
- One process sends a message to the appropriate mailbox, and other process picks up the message from the mailbox.
A strength of the use of indirect addressing is that, by decoupling the sender and receiver, it allows for greater flexibility in the use of messages.
The association of processes to mailboxes can be either static or dynamic.
In indirect addressing, as applied to message passing, messages are sent to a temporary shared data structure typically known as a mailbox.
In a system employing message passing, when a message is sent to a shared temporary data structure, this general approach is known as: Indirect addressing.
The shared data structures that temporarily hold messages in a message passing system employing indirect addressing are generally referred to as __________________.
ANS: mailboxes
Message Format
The format of the message depends on the objectives of the messaging facility and whether the facility runs on a single computer or on a distributed system.
In a system employing message passing, the typical message is divided into two primary sections:
-
A. Header and mailbox
-
B. Body and mailbox
-
C. Destination ID and Source ID
-
D. None of the above
ANS: D (header and body)
Queueing Discipline
The simplest queueing discipline is FIFO.
Two alternativs:
- Allow the specifying of message priority, on the basis of message type or by designation by the sender.
- Allow the receiver to inspect the message queue and select which message to receive next.
In a message passing system, one queuing discipline alternative is to allow the receiver to inspect the message queue and select which message to receive next.
Mutual Exclusion
The preceding solution assumes that if more than one process performs the receive operation concurrently, then:
- If there is a message, it is delivered to only one process and the others are blocked, or
- If the message queue is empty, all processes are blocked; when a message is available, only one blocked process is activated and given the message.
Readers/Writers Problem
- Any number of readers may simultaneously read the file.
- Only one writer at a time may write to the file.
- If a writer is writing to the file, no reader may read it.
A reason why the Producer/Consumer problem cannot be considered a special case of the Reader/Writer problem with a single writer (the producer) and a single reader (the consumer) is: The producer and consumer must be both reader and writer.
The classic concurrency problem that involves multiple readers that can read from a shared data area when no single writer is exclusively writing to it is the __________________ Problem.
ANS: Readers/Writers
Readers Have Priority
Once a single reader has begun to access the data area, it is possible for readers to retain control of the data area as long as there is at least one reader in the act of reading. Therefore, writers are subject to starvation.
int readcount;
semaphore x = 1; // 用于readcount修改保护
semaphore wsem = 1; // 用于读/写互斥保护
void reader() {
while (true) {
semWait(x);
readcount++;
if (readcount == 1)
semWait(wsem); // 若“写”进程在临界区,则等待
semSignal(x);
READUNIT();
senWait(x);
readcount--;
if (readcount == 0)
semSignal(wsem); // 若无“读”进程,则通知
semSignal(wsem);
}
}
void writer() {
while (true) {
semWait(wsem); // 若无“读”进程
WRITEUNIT();
semSignal(wsem);
}
}
void main() {
readcount = 0;
parbegin (reader, writer);
}
Writers Have Priority
A solution that guarantees no new readers are allowed access to the data area once at least one writer has declared a desire to write.
int readcount, writecount;
semaphore x = 1; // 用于readcount修改保护
semaphore y= 1; // 用于write修改保护
semaphore z= 1; // 只允许一个“读”进程在rsem上排队,其他“读”进程在z上排队
semaphore wsem = 1; // 用于读/写互斥保护
semaphore rsem = 1; // 当至少有一个“写”请求时,对新的“读”请求进行阻塞
void reader() {
while (true) {
semWait(z);
semWait(rsem);
semWait(x);
readcount++;
if (readcount == 1)
semWait(wsem); // 若“写”进程在临界区,则等待
semSignal(x);
semSignal(rsem);
semSignal(z);
READUNIT();
senWait(x);
readcount--;
if (readcount == 0)
semSignal(wsem); // 若无“读”进程,则通知
semSignal(x);
}
}
void writer() {
while (true) {
semWait(y);
writecount++;
if (writecount == 1)
semWait(rsem);
semSignal(y);
semWait(wsem);
WRITEUNIT();
semWait(y);
writecount--;
if (writecount == 0)
semSignal(rsem);
semSignal(y);
}
}
void main() {
readcount = writecount = 0;
parbegin (reader, writer);
}
Chapter 6 — Concurrency: Deadlock and Starvation
3 common approaches to dealing with deadlock:
- Deadlock prevention (预防) : Disallow one of the three necessary conditions for deadlock occurrence, or prevent circular wait condition from happening.
- Deadlock detection (检测) : Do not grant a resource request if this allocation might lead to deadlock.
- Deadlock avoidance ( 避免 ) : Grant resource requests when possible, but periodically check for the presence of deadlock and take action to recover.
Principles of Deadlock
Deadlock can be defined as the permanent blocking of a set of processes that either compete for system resources or communicate with each other. ( 可以把死锁定义为一组相互竞争系统资源或进行通信的进程间的“永久”阻塞 )
A set of processes is deadlocked when each process in the set in blocked awaiting an event (typically the freeing up of some requested resource) that can only be triggered by another blocked process in the set. ( 当一组进程中的每个进程都在等待某个事件(典型的情况是等待所请求资源的释放),而只有在这组进程中的其他被阻塞的进程才可以触发该事件 )
Deadlock is permanent beacause none of the event is ever triggered.
There is no efficient solution in the general case.
All deadlocks involve conflicting needs for resources by two or more processes. ( 所有死锁都涉及两个或多个进程之间对资源需求的冲突 )
Reusable Resources
Two general categories (类) of resources can be distinguished: reusable & consumable.
A reusable resource is one that can be safely used by only one process at a time and is not depleted by that use.
One strategy for dealing with such a deadlock is to impose system design constraints concerning the order in which resources can be requested. ( 处理竞争独占访问资源的死锁的一个策略是给系统设计施加关于资源请求顺序的约束 )
The best way to deal with this particular problem is, in effect, to eliminate the possibility by using virtual memory. ( 解决内存请求冲突的死锁的最好方法是,通过使用虚拟内存有效地消除这种可能性 )
Consumable Resources
A consumable resource is one that can be created (produced) and destroyed (consumed).
Typically, there is no limit on the number of consumable resources of a particular type. An unblocked producing process may create any number of such resources.
Resource Allocation Graphs (资源分配图)
The resource allocation graph is a directed graph that depicts a state of the system of resources and processes, with each process and each resource represented by a node.
The Conditions for Deadlock
3 conditions of policy must be present for a deadlock to be possible:
- Mutual exclusion (互斥). Only one process may use a resource at a time. No process may access a resource unit that has been allocated to another process.
- Hold and wait (占有且等待). A process may hold allocated resources while awaiting assignment of other resources.
- No preemption (不可抢占). No resource can be forcibly removed from a process holding it.
The first 3 conditions are necessary, but not sufficient, for a deadlock to exist. For deadlock to actually take place, a 4th condition is required:
- Circular wait (循环等待). A closed chain of processes exists, such that each process holds at least one resource needed by the next process in the chain.
Deadlock Prevention
The strategy of deadlock prevention is, simply put, to design a system in such a way that the possibility of deadlock is excluded.
Two methods of deadlock prevention:
- Indirect: prevent the occurrence of one of the three necessary conditions previously listed.
- Direct: prevent the occurrence of a circular wait.
Mutual Exclusion
In general, the 1st of the 4 listed conditions can’t be disallowed.
Hold and wait
The hold-and-wait condition can be prevented by requiring that a process request all of its required resources at one time and blocking the process until all requests can be granted simultaneously. This approach is inefficient.
No Preemption
This condition can be prevented in several ways.
- If a process holding certain resources is denied a further request, that process must release its original resources and, if necessary, request them again together with the additional resource.
- If a process requests a resource that is currently held by another process, the OS may preempt the second process and require it to release its resources. (If no 2 processes possessed the same priority)
Circular Wait
The circular wait condition can be prevented by defining a linear ordering of resource types. (May be efficient)
Deadlock Avoidance
In deadlock prevention, we constrain resource requests to prevent at least 1 of the 4 conditions of deadlocks.
Deadlock avoidance allows the 3 necessary conditions but makes judicious choices to assure that the deadlock point is never reached.
With deadlock avoidance, a decision is made dynamically whether the current resource allocation request will, if granted, potentially lead to a deadlock.
2 approaches to deadlock avoidance:
- Do not start a process if its demands might lead to deadlock.
- Do not grant an incremental resource request to a process if this allocation might lead to deadlock.
Advantage:
- It’s not necessary to preempt and rollback processes, as in deadlock detection, and is less restrictive than deadlock prevention. ( 不需要死锁预防中的抢占和回滚进程,并且限制少 )
Restrictions:
- The maximum resource requirement for each process must be stated in advance. ( 必须事先声明每个进程请求的最大资源 )
- The processes under consideration must be independent; that is, the order in which they execute must be unconstrained by any synchronization requirements. ( 考虑的进程必须是无关的,也就是说,它们执行的顺序必须没有任何同步要求的限制 )
- There must be a fixed number of resources to allocate. ( 分配的资源数目必须是固定的 )
- No process may exit while holding resources. ( 在占用资源时,进程不能退出 )
Process Initiation Denial (进程启动拒绝)
Refuse to start a new process if its resource requirements might lead to deadlock.

Resource Allocation Denial (资源分配拒绝)
A safe state is one in which there is at least one sequence of resource allocations to processes that does not result in a deadlock. An unsafe state is, of course, a state that is not safe.
When a process makes a request for a set of resources, assume the request is granted, update the system state accordingly, then determine if the result is a safe state. If so, grant the request and, if not, block the process until it is sage to grant the request.
The deadlock avoidence strategy does not predict deadlock with certainty; it merely anticipates the possibility of deadlock and assures that there is never such a possibility.
Deadlock Detection
Deadlock detection strategies don’t limit resource access or restrict process actions.
Requested resources are granted to processes whenever possible.
Periodically, the OS performs an algorithm that allows it to detect the circular wait condition described earlier in condition 4.
Deadlock Detection Algorithm
A check for deadlock can be made as frequently as each resource request, or less frequently, depending on how likely it is for a deadlock to occur.
Two advantages: It leads to early detection, and the algorithm is relatively simple because it is based on incremental changes to the state of the system.
Such frequent checks consume considerable processor time.
The strategy in this algorithm is to find a process whose resource requests can be satisfied with the available resources, then assume those resources are granted and the process runs to completion and releases all of its resources. The algorithm then looks for another process to satisfy.
Note this algorithm does not guarantee to prevent deadlock; that will depend on the order in which future requests are granted. All that it does is determine if deadlock currently exists.
Recovery
The following are possible approaches, listed in the order of increasing sophistication:
- Abort all deadlocked processes (取消所有的死锁进程). This is one of the most common solutions adopted in OS.
- Back up each deadlocked process to some previously defined checkpoint, and restart all processes (把每个死锁进程回滚到前面定义的某些检查点,并且重启所有进程). This requires that rollback and restart mechanisms be built into the system. The risk in this approach is that the original deadlock may recur. However, the nondeterminancy of concurrent processing may ensure that this does not happen.
- Successively abort deadlocked processes until deadlock no longer exists (连续取消死锁进程直到不再产生死锁). The order in which processes are selected for abortion should be on the basis of some criterion of minimum cost. After each abortion, the detection algorithm must be reinvoked to see whether deadlock still exists.
- Successively preempt resources until deadlock no longer exists (连续抢占资源直到不再存在死锁). As in (3), a cost-based selection should be used, and reinvocation of the detection algorithm is required after each preemption. A process that has a resource preempted from it must be rolled back to a point prior to its acquisition of that resource.
For (3) and (4), the selection criteria could be one of the following. Choose the process with the:
- least amount of processor time consumed so far.
- least amount of output produced so far.
- most estimated time remaining.
- least total resources allocated so far.
- lowest priority.
An Intergrated Deadlock Strategy
[HOWA73] suggests one approach:
- Group resources into a number of different resource classes.
- Use the linear ordering strategy defined previously for the prevention of circular wait to prevent deadlocks between resource classes.
- Within a resource class, use the algorithm that is most appropriate for that class.
As an example of this technique, consider the following classes of resources:
- Swappable space: Blocks of memory on secondary storage for use in swapping processes.
- Process resources: Assignable devices, such as tape drives, and files.
- Main memory: Assignable to processes in pages or segments.
- Internal resources: Such as I/O channels.
The order of the preceding list represents the order in which resources are assigned. The order is a reasonable one, considering the sequence of steps that a process may follow during its lifetime. Within each class, the following strategies could be used:
- Swappable space: Prevention of deadlocks by requiring that all of the required resources that may be used be allocated at one time, as in the hold-and-wait prevention strategy. This strategy is reasonable if the maximum storage requirements are known, which is often the case. Deadlock avoidance is also a possibility.
- Process resources: Avoidance will often be effective in this catagory, because it is reasonable to expect processes to declare ahead of time the resources that they will require in this class. Prevention by means of resource ordering within this class is also possible.
- Main memory: Prevention by preemption appears to be the most appropriate strategy for main memory. When a process is preempted, it is simply swapped to secondary memory, freeing space to resolve the deadlock.
- Internal resources: Prevention by means of resource ordering can be used.
Dining Philosophers Problem
The algorithm must satisfy mutual exclusion while avoiding deadlock and starvation.
Dining philosophers problem is a standard test case for evaluating approaches to synchronization.
Solution Using Semaphores
This solution leads to deadlock.
As an approach, we could consider adding an attendant who only allows 4 philosophers at a time into the dining room. (Assuming there are 5 philosophers)
Solution Using a Monitor
Cool.
Chapter 7 - Memory Management
The task of subdividing memory between the O/S and processes is performed automatically by the O/S and is called: Memory Management.
Memory Management Requirements
Subdividing memory to accommodate multiple processes. (为支持多道程序将内存进行划分)
Memory needs to be allocated to ensure a reasonable supply of ready processes to consume available processor time. (内存管理应确保有适当数目的就绪进程使用处理器时间)
The requirements include the following: Relocation, Protection, Sharing, Logical organization, Physical organization.
Relocation
Programmer does not know where the program will be placed in memory when it is executed.(程序员不知道程序在执行时将被放在内存中的什么位置)
While the program is executing, it may be swapped to disk and returned to main memory at a different location (relocated).(当程序执行时,它可能被交换到磁盘,当换入时,被加载到主内存的不同位置(重新定位))
Memory references must be translated in the code to actual physical memory address. (内存访问必须把代码中的地址转换为实际的物理内存地址)
Somehow, the processor hardware and OS software must be able to translate the memory references found in the code of the program into actual physical memory addresses, reflecting the current location of the program in main memory.
Protection
Programs in other processes should not be able to reference memory locations in a process for reading or writing purposes without permission.
Satisfaction of the relocation requirement increases the difficulty of satisfying the protection requirement.
All memory references generated by a process must be checked at run time to ensure they refer only to the memory space allocated to that process.
Without special arrangement, a program in one process cannot access the data area of another process.
The memory protection requirement must be satisfied by the processor (hardware) rather than the operating system (software). (内存保护要求必须由处理器(硬件)而不是操作系统来满足)This is because the OS cannot anticipate all of the memory references that a program will make.
Normally, processes cannot access any portion of the OS, neither program nor data(通常,进程不能访问操作系统的任何部分,无论是程序还是数据)
Impossible to check absolute addresses at compile time, instead, absolute addresses must be checked at run time.(无法在编译时检查绝对地址,而是必须在运行时检查绝对地址)
Sharing
Any protection mechanism must have the flexibility to allow several processes to access the same portion of main memory.
- Share same copy of the program(共享程序的相同副本)
- Share data structure to cooperate on some task(共享数据结构以协作完成某些任务)
Logical Organization
If the OS and computer hardware can effectively deal with user programs and data in the form of modules of some sort, then a number of advantages can be realized:
- Modules can be written and compiled independently, with all references from one module to another resolved by the system at run time.
- With modest additional overhead, different degrees of protection (read only, execute only) can be given to different models.
- It is possible to introduce mechanisms by which modules can be shared among processes. The advantage of providing sharing on a module level is that this corresponds to the user’s way of viewing the problem, hence it is easy for the user to specify the sharing that is desired.
Segmentation satisfies these requirements(分段技术满足该需求)
Physical Organization
- Memory is organized into at least two levels, referred to as main memory and secondary memory(分为两级:主存和辅存)
- Memory available for a program plus its data may be insufficient (内存对程序和其数据来说可能不足)
- Overlaying (覆盖) allows various modules to be assigned the same region of memory(覆盖技术允许不同的模块分配相同的内存区域)
- Programmer does not know how much space will be available and where his/her program will be loaded in memory (程序员编写代码时不知道可用空间大小和位置)
It is clear, then, that the task of moving information between the two levels of memory should be a system responsibility. This task is the essence of memory management.
Memory Partitioning
Fixed Partitioning
The simplest scheme for managing this available memory is to partition it into regions with fixed boundaries.
Partition Sizes
2 difficulties with the use of equal-size fixed partitions:
- A program may be too big to fit into a partition. The programmer must design the program with overlays(一个程序不能装入一个分区。程序员必须采用覆盖技术来设计程序)
- Main memory utilization is extremely inefficient. (内存使用效率低) This phenomenon, in which there is wasted space internal to a partition due to the fact that the block of data loaded is smaller than the partition, is referred to as internal fragmentation.
Both of these problems can be lesseed, though not solved, by using unequalsize partitions.
The problem of internal fragmentation can be lessened in systems employing a fixed-partition memory management scheme by using: Unequal size partitions.
Placement Algorithm
Equal-size partitions
Because all partitions are of equal size, it does not matter which partition is used(因为所有分区的大小相同,所以使用哪个分区并不重要)
Unequal-size partitions
A preferable approach would be to employ a single queue for all processes. When it is time to load a process into main memory, the smallest available partition that will hold the process is selected. If all partitions are occupied, then a swapping decision must be made. Preference might be given to swapping out of the smallest partition that will hold the incoming process. It is also possible to consider other factors, such as priority, and a preference for swapping out blocked processes versus ready processes.
Disadvantages:
- The use of partitions specified at system generation time limits the number of active (not suspended) processes in the system.
- Because partition sizes are preset at system generation time, small jobs will not utilize partition space efficiently.
Dynamic Partitioning
As time goes on, memory becomes more and more fragmented, and memory utilization declines.
External fragmentation: Indicates the memory that is external to all partitions becomes increasingly fragmented.
One technique for overcoming external fragmentation is compaction (压缩): From time to time, the OS shifts the processes so they are contiguous and all of the free memory is together in one block.
Placement Algorithm
3 placement algorithms:
- Best-fit: Chooses the block that is closest in size to the request.
- First-fit: Begins to scan memory from the beginning and chooses the first available block that is large enough. (从头开始扫描)
- Next-fit: Begins to scan memory from the location of the last placement and chooses the next available block that is large enough. (从上一次放置的位置开始扫描)
The first-fit algorithm is not only the simplest but usually the best and fastest as well. (简单且性能最好) On the other hand, the first-fit algorithm may litter the front end with small free partitions that need to be searched over on each subsequent first-fit pass.
The next-fit algorithm tends to produce slightly worse results than the first-fit. The result is that the largest block of free memory, which usually appears at the end of the memory space, is quickly broken up into small fragments. Thus, compaction may be required more frequently with next-fit.
The best-fit algorithm, despite its name, is usually the worst performer. Because this algorithm looks for the smallest block that will satisfy the requirement, it guarantees that the fragment left behind is as small as possible. Although each memory request always wastes the smallest amount of memory, the result is that main memory is quickly littered by blocks too small to satisfy memory allocation request. Thus, memory compaction must be done more frequently than with the other algorithms.
Replacement Algorithm
To avoid wasting processor time waiting for an active process to become unblocked, the OS will swap one of the processes out of main memory to make room for a new process or for a process in a Ready-Suspend state.
Buddy System
In buddy system, memory blocks are available of size 2 K 2^K 2K words, L ≤ K ≤ U L{\le}K{\le}U L≤K≤U, where:
- $2^L = $ smallest size block that is allocated
- 2 U = 2^U= 2U= largest size block that is allocated; generally 2 U 2^U 2U is the size of the entire memory available for allocation.
To begin, the entire space available for allocation is treated as a single block of size 2 U 2^U 2U. If a request of size s s s such that 2 U − 1 < s ≤ 2 U 2^{U-1}
Relocation
A simple relocating loader: When the process is first loaded, all relative memory references in the code are replaced by absolute main memory addresses, determined by the base address of the loaded process.
A process may occupy different partitions which means different absolute memory locations during execution (from swapping,交换) .
Compaction (压缩) will also cause a program to occupy a different partition which means different absolute memory locations.
A logical address is a reference to a memory location independent of the current assignment of data to memory; a translation must be made to a physical address before the memory access can be achieved.
A relative address is a particular example of logical address, in which the address is expressed as a location relative to some known point, usually a value in a processor register.
A physical address, or absolute address, is an actual location in main memory.
Programs that employ relative addresses in memory are loaded using dynamic run-time loading. Typically, all of the memory references in the loaded process are relative to the origin of the program. Thus, a hardware mechanism is needed for translating relative addresses to physical main memory addresses at the time of execution of the instruction that contains the reference.
- First, the value in the base register is added to the relative address to produce an absolute address.
- Second, the resulting address is compared to the value in the bounds register. If the address is within bounds, then the instruction execution may proceed.
- Otherwise, an interrupt is generated to the OS, which must respond to the error in some fashion.
Paging
Main memory is partitioned into equal fixed-size chunks (块) that are relatively small, and each process is also divided into small fixed-size chunks of the same size. Then the chunks of a process, known as pages, could be assigned to available chunks of memory, known as frams (帧,也可以翻译为页框), or page frames.
Divide each process into small equal fixed-size chunks which are called pages (页). The size of pages are equal to the size of frames(页的大小与页框的大小一一对应)
The page table for each process maintains: The frame location for each page of the process.
A simple base address register will no longer suffice (足够). Rather, the OS maintains a page table for each process. The page table shows the frame location for each page of the process. Within the program, each logical address consists of a page number and an offset within the page. Recall that in the case of simple partition, a processor translates that into a physical address. With paging, the logical-to-physical address translation is still done by processor hardware. Now the processor must know how to access the page table of the current process. Presented with a logical address, the processor uses the page table to produce a physical address.
With paging, the partitions are rather small; a program may occupy more than one partition; and these partitions need not be contiguous (连续的).
To make this paging scheme convenient, let us dictate that the page size, hence the frame size, must be a power of 2. With the use of a page size that is a power of 2, it’s easy to demonstrate that the relative address (which is defined with reference to the origin of the program) and the logical address (expressed as a page number and offset) are the same.
To summarize, with simple paging, main memory is divided into many small equl-size frames. Each process is divided into frame-size pages. Smaller processes require fewer pages; larger processes require more. When a process is brought in, all of its pages are loaded into available frams, and a page table is set up.
Segmentation
It is not required that all segments of all programs be of the same length, although there is a maximum segment length. As with paging, a logical address using segmentation consists of two parts, in this case, a segment number and an offset.
With segmentation a program may occupy more than one partition, and these partitions need not be contiguous.
Segmentation eliminates internal fragmentation but, like dynamic partitioning, it suffers from external fragmentation. However, because a process is broken up into a number of smaller pieces, the external fragmentation should be less.
Whereas paging is invisible to the programmer, segmentation is usually visible and is provided as a convenience for organizing programs and data.
There is no simple relationship between logical addresses and physical address. Analogous (类似) to paging, a simple segmentation scheme would make use of a segment table for each process, and a list of free blocks of main memory. Each segment table entry would have to give the starting address in main memory of the corresponding segment. The entry should also provide the length of the segment to assure that invalid addresses are not used. When a process enters the Running state, the address of its segment table is loaded into a special register used by the memory management hardware.
To summerize, with simple segmentation, a process is divided into a number of segments that need not be of equal size. When a process is brought in, all of its segments are loaded into available regions of memory, and a segment table is set up.
Chapter 8 - Virtual Memory
Hardware and Control Structures
- All memory references within a process are logical addresses that are dynamically translated into physical addresses at run time.
- A process may be broken up into a number of pieces (pages or segments) and these pieces need not to be contiguously located in main memory during execution.
The OS begins by bringing in only one or a few pieces, to include the initial program piece and the initial data piece to which those instructions refer. The portion of a process that is actually in mian memory at any time is called the resident set of the process. As the process executes, things proceed smoothly as long as all memory references are to locations that are in the resident set. Using the segment or page table, the processor always is able to determine whether this is so.
When an address is needed that is not in main memory:
- An interrupt is generated, which is known as page fault interrupt.
- OS places the process in a blocking state.
- Pieces of process that contains the logical address is brought into main memory.
- OS place the affected process in the Ready state.
It may immediately occur to you to question the efficiency of this maneuver, in which a process may be executing and have to be interrupted for no other reason than that you have failed to load in all of the needed pieces of the process. There are 2 implications:
- More processes may be maintained in main memory.
- A process may be larger than all of main memory.
Real memory: Main memory which a process executes only in.
Virtual memory: A programmer or user perceives a potentially much larger memory that which is allcated on disk.
The type of memory that allows for very effective multiprogramming and relieves the user of memory size constraints is referred to as: Virtual memory.
Locality and Virtual Memory
Thrashing: The system spends most of its time swapping pieces rather than executing instructions.
For virtual memory to be practical and effective, two ingredients are needed. First, there must be hardware support for the paging and/or segmentation scheme to be employed. Second, the OS must include software for managing the movement of pages and/or segments between secondary memory and main memory.
Paging
In the discussion of simple paging, we indicated that each process has its own page table, and when all of its pages are loaded into main memory, the page table for a process is created and loaded into main memory.
Each page table entry (PTE) contains the frame number of the corresponding page in main memory.
A bit is needed in each PTE to indicate whether the corresponding page is present § in main memory or not.
The page table entry includes a modify (M) bit, indicating whether the contents of the corresponding page have been altered since the page was last loaded into main memory.

Page Table Structure
The basic mechanism for reading a word from memory involves the translation of a virtual, or logical, address, consisting of page number and offset, into a physical address, consisting of frame number and offset, using a page table.
When a particular process is running, a register holds the starting address of the page table for that process. The page number of a virtual address is used to index that table and look up the corresponding frame number. The is combined with the offset portion of the virtual address to produce the desired real address.
In most systems, there is one page table per process. But each process can occupy huge amounts of virtual memory.
Invented Page Table (倒排页表)
The page number portion of a virtual address is mapped into a hash value using a simple hashing function. The hash value is a pointer to the inverted page table, which contains the page table entries. There is one entry in the inverted page table for each real memory page frame, rather than one per virtual page. Thus, a fixed proportion of real memory is required for the tables regardless of the number of processes or virtual pages supported. Because more than one virtual address may map into the same hash table entry, a chaining technique is used for managing the overflow. The hashing technique results in chains that are typically short - between one and two entries. The page tables’s structure is called inverted because it indexes page table entries by frame number rather than by virtual page number.
Translation Lookaside Buffer
In principle, every virtual memory reference can cause two physical memory accesses: one to fetch the appropriate page table entry, and another to fetch the desired data.
Thus, a straightforward virtual memory scheme would have the effect of doubling the memory access time. To overcome this problem, most virtual memory schemes make use of a special high-speed cache for page table entries, usually called a translation lookaside buffer (TLB).
Page Size
There are several factors to consider.
-
One is internal fragmentation.
- The smaller the page size, the lesser is the amount of internal fragmentation.
- The smaller the page, the greater is the number of pages required per process.
- Larger page tables means large portion of page tables in virtual memory.
- Secondary memory is designed to efficiently transfer larg blocks of data so a large page size is better.
-
Another factor is that the physical characteristics of most secondary-memory devices, which are rotational, favor a larger size for more efficient blocktransfer of data.
Segmentation
Virtual Memory Implications
Segmentation allows the programmer to view memory as consisting of multiple address spaces or segments.

Advantages:
- It simplifies the handling of growing data structures.
- It allows programs to be altered and recompiled independently, without requiring the entire set of programs to be relinked and reloaded.
- It lends itself to sharing data among processes.
- It lends itself to protection.
Orgazization
Because only some of the segments of a process may be in main memory, a bit is needed in each segment table entry to indicate whether the corresponding segment is present in main memory or not. If the bit indicates that the segment is in memory, then the entry also includes the starting address and length of that segment.
Another control bit in the segmentation table entry is a modify bit, indicating whether the contents of the corresponding segment have been altered since the segment was last loaded into main memory. If there has been no change, then it is not necessary to write the segment out when it comes time to replace the segment in the frame that it currently occupies.
The basic mechanism for reading a word from memory involves the translation of a virtual, or logical, address, consisting of segment number and offset, into a physical address, using a segment table. Because the segment table is of variable length, depending on the size of the process, we cannot expect to hold it in registers. Instead, it must be in main memory to be accessed.
Combined Paging and Segmentation
Paging, which is transparent to the programmer, eliminates external fragmentation and thus provides efficient use of main memory. In addition, because the pieces that are moved in and out of main memory are of fixed, equal size, it is possible to develop sophisticated memory management algorithms that exploit the behavior of programs.
Segmentation, which is visible to the programmer, has the strengths listed earlier, including the ability to handle growing data structures, modularity, and support for sharing and protection.
In a combined paging/segmentation system, a user’s address space is broken up into a number of segments, at the discretion of the programmer. Each segment is, in turn, broken up into a number of fixed-size pages, which are equal in length to a main memory frame.
In a combined paging/segmentation system, a user’s address space is broken up into a number of: Variable-sized Segments, which are in turn broken down into fixed-size pages.

Protection and Sharing
Because each segment table entry includes a length as well as a base address, a program cannot inadvertently access a main memory location beyond the limits of a segment. To achieve sharing, it is possible for a segment to be referenced in the segment tables of more than one process.
More sophisticated mechanisms can also be provided. A common scheme is to use a ring-protection structure.
OS Software
The design of the memory management portion of an OS depends on three fundamental areas of choice:
- Whether or not to use virtual memory techniques
- The use of paging or segmentation or both
- The algorithms employed for various aspects of memory management
Fetch Policy
With demand paging (请求分页), a page is brought into main memory only when a reference is made to a location on that page.
With prepaging (预先分页), pages other than the one demanded by a page fault are brought in. Prepaging exploits the characteristics of most secondary memory devices, such as disks, which have seek times and rotational latency.
The prepaging policy could be employed either when a process first starts up, in which case the programmer would somehow have to designate desired pages, or every time a page fault occurs.
Placement Policy
The placement policy determines where in real memory a process piece is to reside.
- Important in a segmentation system and nonuniform memory access (NUMA, 非一致存储器访问) system. (放置策略对分段系统和 NUMA 系统影响大)
- Paging or combined paging with segmentation hardware performs address translation and placement is usually irrelevant. (放置策略对分页和段页式系统影响不大)
Replacement Policy
Page removed should be the page least likely to be referenced in the near future.
Frame Locking
One restriction on replacement policy needs to be mentioned before looking at various algorithms: Some of the frames in main memory may be locked. When a frame is locked, the page currently stored in that frame may not be replaced.
It associates a lock bit with each frame.
Basic Algorithm
Replacement algorithms that have been discussed in the literature include:
- Optimal (OPT, 最佳)
- Least recently used (LRU)
- First-in-first-out (FIFO)
- Clock
The optimal policy selects for replacement that page for which the time to the next reference is the longest.
The LRU policy replaces the page in memory that has not been referenced for the longest time. Each page could be tagged with the time of last reference. This would require a great deal of overhead.
The FIFO policy treats the page frames allocated to a process as a circular buffer, and pages are removed in round-robin style.
Clock policy:
- When a page is first loaded into a frame in memory, the use bit for that frame is set to 1.
- Whenever the page is subsequently referenced (after the reference that generated the page fault), its use bit is set to 1.
- For the page replacement algorithm, the set of frames that are candidates for replacement is considered to be a circular buffer, with which a pointer is associated.
- When a page is replaced, the pointer is set to indicate the next frame in the buffer after the one just updated.
- When it comes time to replace a page, the OS scans the buffer to find a frame with a use bit set to 0. Each time it encounters a frame with a use bit of 1, it resets that bit to 0 and continues on.
The page replacement algorithm cycles through all of the pages in the buffer, looking for one that has not been modified since being brought in has the advantage that, because it is unmodified, it does not need to be written back out to secondary memory.
Page Buffering
An interesting strategy that can improve paging performance and allow the use of a simpler page replacement policy is page buffering.
The VAX VMS approach is representative. The page replacement algorithm is simple FIFO. To improve performance, a replaced page is not lost but rather is assigned to one of two lists: the free page list if the page has not beean modified, or the modified page list if it has. Note the page is not physically moved about in main memory; instead, the entry in the page table for this page is removed and placed in either the free or modified page list.
Resident Set Management
Resident Set Management
How much main memory to allocate to a particular process. Serveral factors come into play:
- The smaller the amount of memory allocated to a process, the more processes that can reside in main memory at any one time. This increases the probability that the OS will find at least one ready process at any given time, and hence reduces the time lost due to swapping.
- If a relatively small number of pages of a process are in main memory, then, despite the principle of locality, the rate of page faults will be rather high.
- Beyond a certain size, additional allocation of main memory to a particular process will have no noticeable effect on the page fault rate for that process because of the principle of locality.
A fixed-allocation policy gives a process a fixed number of frames in main memory within which to execute.
A variable-allocation policy allows the number of page frames allocated to a process to be varied over the lifetime of the process.
Replacement Scope
A local replacement policy chooses only among the resident pages of the process that generated the page fault in selecting a page to replace.
A global replacement policy considers all unlocked pages in main memory as candidates for replacement, regardless of which process owns a particular page.
Fixed Allocation, Global Scope
For this case, we have a process that is running in main memory with a fixed number of frames. When a page fault occurs, the OS must choose which page is to be replaced from among the currently resident pages for this process.
With a fixed-allocation policy, it is necessary to decide ahead of time the amount of allocation to give to a process. This could be decided on the basis of the type of application and the amount requested by the program.
Variable Allocation, Global Scope
The combination is perhaps the easiest to implement and has been adopted in a number of OSs.
At any given time, there are a number of processes in main memory, each with a certain number of frames allocated to it.
The difficulty with this approach is in the replacement choice.
One way to counter the potential performance problems of a variable-allocation, global-scope policy is to use page buffering.
Variable Allocation, Local Scope
- When a new process is loaded into main memory, allocate to it a certain number of page frames as its resident set, based on application type, program request, or other criteria. Use either prepaging or demand paging to fill up the allocation.
- When a page fault occurs, select the page to replace from among the resident set of the process that suffers the fault.
- From time to time, reevaluate the allocation provided to the process, and increase or decrease it to improve overall performance.
With this strategy, the decision to increase or decrease a resident set size is a deliberate one, and is based on an assessment of the likely future demands of active processes.
It’s more complex than a simple global replacement policy. However, it may yield better performance.
The key elements of the variable-allocation, local-scope strategy are the criteria used to determine resident set size and the timing of changes. The working set strategy would be difficult to implement but is useful to examine it as a baseline for comparison.
An algorithm that follows this strategy is the page fault frequency (PFF) algorithm.
A major flaw in the PFF approach is that it does not perform well during the transient periods when there is a shift to a new locality.
An approach that attempts to deal with the phenomenon of interlocality transition, with a similar relatively low overhead to that of PFF, is the variable-interval sampled working set (VSWS).
The VSWS policy evaluates the working set of a process at sampling instances based on elapsed virtual time.
Cleaning Policy
Cleaning policy is concerning with determining when a modified page should be written out to secondary memory.
2 choices:
- With demand cleaning, a page is written out to secondary memory only when it has beem selected for replacement.
- A precleaning policy writes modified pages before their page frames are needed so pages can be written out in batches.
Drawbacks:
- Precleaning: The transfer capacity of secondary memory is limited, and should not be wasted with unnecessary cleaning operations.
- Demand cleaning: A process that suffers a page fault may have to wait for 2 page transfers before it can be unblocked. This may decrease processor utilization.
A better approach incorporates page buffering: Clean only pages that are replaceable, but decouple the cleaning and replacement operations.
Load Control
If too few processes are resident at any one time, then there will be many occasions when all processes are blocked, and much time will be spent in swapping. On the other hand, if too many processes are resident, then, on average, the size of the resident set of each process will be inadequate and frequent faulting will occur. The result is thrashing (抖动).
Multiprogramming Level
- L = S L=S L=S criterion
- 50 50 50% criterion
Process Suspension
If the deree of multiprogramming is to be reduced, one or more of the currently resident processes must be suspended (swapped out). The followings are 6 possibilities:
- Lowest-priority process: This implements a scheduling policy decision, and is unrelated to performance issues.
- Faulting process: The reasoning is there is a greater probability that the faulting task does not have its working set resident, and performance would suffer least by suspending it. In addition, this choice has an immediate payoff because it blocks a process that is about to be blocked anyway, and it eliminates the overhead of a page replacement and I/O operation.
- Last process activated: This is the process least likely to have its working set resident.
- Process with the smallest resident set: This will require the least future effort to reload. However, it penalizes programs with strong locality.
- Largest process: This obtains the most free frames in an overcommited memory, making additional deactivations unlikely soon.
- Process with the largest remaining execution window: In most process scheduling schemes, a process may only run for a certain quantum of time before being interrupted and placed at the end of the Ready queue. This approximates a shortest-processing-time-first scheduling discipline.
Chapter 9 - Uniprocessor Scheduling
The decision as to which job to admit to the system next can be based on which of the following criteria: Priority, Simple FIFO, I/O requirements.
Types of Processor scheduling
The aim of processor scheduling is to assign processes to be executed by the processor or processors over time, in a way that meets system objectives, such as response time (响应事件), throughput (吞吐率), and processor efficiency (处理器效率).
In many system, this scheduling activity is broken down into three separate functions: long-, medium-, and short-term scheduling.
| Scheduling | Description |
|---|---|
| Long-term scheduling | The decision to add to the pool of processes to be executed. |
| Medium-term scheduling | The decision to add to the number of processes that are partiallyor fully in main memory. |
| Short-term scheduling | The decision as to which available process will be executed by the processor |
| I/O scheduling | The decision as to which process’s pending I/O request shall be handled by an available I/O device. |

- Long-term scheduling is performed when a new process is created. This is a decision whether to add a new process to the set of processes that are currently active.
- Medium-term scheduling is a part of the swapping function. This is a decision whether to add a process to those that are at least partially in main memory and therefore available for execution.
- Short-term scheduling is the actual decision of which ready process to execute next.
Long-term Scheduling
The long-term scheduler determines which programs are admitted to the system for processing. (确定哪些程序被允许进入系统被执行)
Thus, it controls the degree of multiprogramming (控制并发度).
More processes, smaller percentage of time each process is executed. (进程越多,执行每个进程的时间百分比越小)
Medium-term Scheduling
Medium-term scheduling is part of the swapping function.
The swapping-in decision is based on the need to manage the degree of multiprogramming.(换入决定取决于管理系统并发度需求)
Short-term Scheduling
The short-term scheduler, also known as the dispatcher, executes most frequently and makes the fine-grained decision of which process to execute next.
The short-term scheduler is invoked whenever an event occurs that may lead to the blocking of the current in favor of another. Examples of such events include:
- Clock interrupts
- I/O interrupts
- OS calls
- Signals (e.g. semaphores)
Scheduling Algorithms
Short-term Scheduling Criteria
The main objective of short-term scheduling is to allocate processor time in such a way as to optimize one or more aspects of system behavior.
The commonly used criteria can be categorized along two dimensions: user-oriented and system-oriented criteria.
- User-oriented
- The behavior of the system as perceived by the individual user or process
- System-oriented
- Effective and efficient utilization of the processor
Another dimension along which criteria can be classified is those that are performance related, and those that are not directly performance related.
Response time in an interactive system is an example of: User-oriented criteria for short-term scheduling policies.
Scheduling Criteria:
- User Oriented, Performance Related
- Turnaround time (周转时间): Between the submission of a process and its completion. Includes actual execution time plus time spent waiting for resources.
- Response time (响应时间): From the submission of a request until the response begins to be received.
- Deadlines (最后期限)
- User Oriented, Other
- Predictability (可预测性): A given job should run in about the same amount of time and about the same cost regardless of the load on the system.
- System Oriented, Performance Related
- Throughput (吞吐量): The scheduling policy should attempt to maximize the number of processes completed per unit of time.
- Processor utilization (处理器利用率)
- System Oriented, Other
- Fairness (公平性)
- Enforcing priorities (强制优先级)
- Balancing resources (平衡资源)
The Use of Priorities
In many systems, each process is assigned a priority, and the scheduler will always choose a process of higher priority over one of lower priority.
- One problem: Lower-priority processes may suffer starvation.
- Solution: Allow a process to change its priority based on its age or execution history.
Alternative Scheduling Policies
Terms:
- Response time (响应时间)
- Turnaround time (周转时间)
- Normalized turnaround time (归一化周转时间,周转时间 ÷ 服务时间)
- Throughput (吞吐率)
- Predictability (可预测性)
- Selection function: Determines which process, among ready processes, is selected next for execution. (选择函数,确定在就绪进程中选择哪一个进程在下一次执行)
- Decision mode (决策模式,选择函数被执行瞬间的处理方法)
- Preemptive (抢占,当前正在执行的进程可能被操作系统中断,并转移到就绪态)
- Nonpreemptive (非抢占,一旦处于运行态就不断执行知道终止或者被阻塞)




First-Come-First-Served
As each process becomes ready, it joins the ready queue.
- FCFS performs much better for long processes than short ones.
- FCFS tends to favor processor-bound processes over I/O-bound processes.
Round-Robin
A clock interrupt is generated at periodic intervals. When the interrupt occurs, the currently running process is placed in the ready queue, and the next ready job is selected on a FCFS basis. This technique is also known as time slicing, because each process is give a slice of time before being preempted.
Round robin is particularly effective in a general-purpose time-sharing system or transaction processing system.
从一个进程切换到另一个进程是需要一定时间进行管理事务处理的——保存和装入寄存器值及内存映像、更新各种表格和列表、清除和重新调入内存高速缓存 等。假如进程切换(process switch),有时称为上下文切换(context switch),需要1ms,包括切换内存映像、清除和重新调入高速缓存等。再假设时间片设为4ms。有了这些参数,则CPU在做完4ms有用的工作之 后,CPU将花费(即浪费)1ms来进行进程切换。因此,CPU时间的20%浪费在管理开销上。很清楚,这一管理时间太多了。
Shortest Process Next
This is a nonpreemptive inherent in which the process with the shortest expected processing time is selected next.
Thus, a short process will jump to the head of the queue past longer jobs.
One difficulty with the SPN policy is the need to know (or at least estimate) the required processing time of each process.
一种办法是根据进程过去的行为进行推测,并执行估计运行时间最短的那一个。假设某个终端上每条命令的估计运行时间为T0 。现在假设测量到其下一次运行时间为T1 。可以用这两个值的加权和来改进估计时间,即aT0 +(1-a)T1 。通过选择a的值,可以决定是尽快忘掉老的运行时间,还是在一段长时间内始终记住它 们。
有时把这种通过当前测量值和先前估计值进行加权平均而得到下一个估计值的技术称作老化(aging)。它适用于许多预测值必须基于先前值的情况。老化算法在a=1/2时特别容易实现,只需将新值加到当前估计值上,然后除以2(即右移一位)。
A risk with SPN is the possibility of starvation for longer processes, as long as there is a steady supply of shorter processes. On the other hand, although SPN reduces the bias in favor of longer jobs, it still is not desirable for a time-sharing or transaction-processing environment because of the lack of preemption.
Shorest Remaining Time
The shortest remaining time (SRT) policy is a preemptive version of SPN.
In this case, the scheduler always chooses the process that has the shortest expected remaining processing time.
调度程序总是选择剩余运行时间最短的那个进程运行。当一个新的作业到达时,其整个时间同当前进程的剩余时间做比较。如果新的进程比当前运行进程需要更少的时间,当前进程就被挂起,而运行新的进程。
Highest Response Ratio Next
R = w + s s R=\frac{w+s}{s} R=sw+s
- R = response ratio
- w = time spent waiting for the processor
- s = expected service time
Feedback
Scheduling is done on a preemptive (at time quantum) basis, and a dynamic priority mechanism is used.

Performance Comparison
Fair-Share Scheduling
Scheduling is done on the basis of
- under-lying priority of the process
- recent processor usage of the process
- recent processor usage of the group
The higher the numerical value of the priority the lower the priority.
The strategy that schedules processes based on their group affiliation is generally referred to as: Fair share scheduling.
Chapter 11 - I/O Management & Disk Scheduling
I/O Devices
Roughly grouped into three categories:
- Human readable (人可读) :
- Used to communicate with the user
- Printers
- Video display terminals
- Input terminals
- Keyboard
- Mouse
- Machine readable (机器可读)
- Used to communicate with electronic equipment
- Disk and tape drives
- Sensors (传感器)
- Controllers (控制器)
- Communication (通信)
- Used to communicate with remote devices
- Digital line drivers
- Modems
- Network device
Difference in I/O Devices:
- Data rate: May be differences of several orders of magnitude between the data transfer rates.
- Application: The use to which a device is put has an influence on the software and policies in the OS and supporting utilities.
- Complexity of control
- Unit of transfer: Data may be transferred as a stream of bytes or characters (e.g., terminal I/O) or in larger blocks (e.g., disk I/O).
- Data representation
- Error conditions
An example of the key differences that can exist across (and even in) classes of I/O devices is: Error conditions, Data rate, Data representation.
Organization of the I/O Function
-
Programmed I/O
Process is busy-waiting for the operation to complete.
-
Interrpt-driven I/O
I/O command is issued.
Processor continues executing instructions.
I/O module sends an interrupt when done.
-
Direct memory access (DMA)
DMA module controls exchange of data between main memory and the I/O device.
Processor interrupted only after entire block has been transferred.
The I/O technique where the processor busy waits for an I/O operation to complete is called: Programmed I/O.
Evolution of the I/O Function
-
Processor directly controls a peripheral device
Processor has to handle details of external devices.
-
Controller or I/O module is added
Processor uses programmed I/O without interrupts.
Processor does not need to handle details of external devices.
-
Controller or I/O module with interrupts
Processor does not spend time waiting for an I/O operation to be performed.
-
DMA
Blocks of data are moved into memory without involving the processor.
Processor involved at beginning and end only.
-
I/O module (I/O channel) is enhanced to a separate processor
The CPU directs the I/O processor to execute an I/O program in main memory.
The I/O processor fetches and executes these instructions without processor intervention.
-
I/O processor
I/O module has its own memory.
DMA
- Processor delegates (委派) I/O operation to the DMA module.
- DMA module transfers data directly to or from memory.
- When complete DMA module sends an interrupt signal to the processor.
The bus configuration for DMA that provides no path other than the system bus between the DMA module(s) and I/O devices is: Single bus, detached DMA.
OS Design Issues
Design Objectives
Efficiency and generality are most important objectives in designing the I/O facility. (效率与通用性)
- Efficiency:
- Most I/O devices extremely slow compared to main memory, I/O cannot keep up with processor speed.
- Multiprogramming allows some processes to be waiting on I/O operations while another process is executing.
- Swapping is used to bring in additional ready processes to keep the processor busy, but this in itself is an I/O operation.
- Generality
- Desirable to handle all I/O devices in a uniform manner (统一模式).
- Hide most of the details of device I/O in lower-level routines so that processes and upper levels see devices in general terms such as read, write, open, close, lock, unlock. (将设备 I/O 的大部分细节隐藏在较低级别的例程中)
The primary objective in designing the I/O facility of a computer system that deals with the desire to handle all I/O devices in a uniform manner is referred to as: Generality.
I/O Buffering
Reasons for buffering:
- Processes must wait for I/O to complete before proceeding.
- Certain pages must remain in main memory during I/O.
Define of I/O buffering: Performs input transfers in advance of requests being made, and performs output transfers some time after the request is made. (预输入,缓输出)
Two types of I/O devices:
- Block-oriented
- Fixed size
- Transfers are made one block at a time.
- e.g., Disk, USB keys.
- Stream-oriented
- Transfers data in and out as a stream of bytes.
- e.g., terminals, printers, communications ports, mouse, and other pointing devices, and most other devices that are not secondary storage are stream-oriented.
An example of a block-oriented I/O device is: CD-ROM.
Single Buffer (单缓冲)
OS assigns one buffer in the system space for an I/O request.
Block-oriented single buffering
- Input transfers are made to the system buffer.
- Block is moved to user space when needed.
- Another block is requested immediately.
Advantages of block-oriented single buffer:
- User process can process one block of data while next block is read in.
- Swapping can occur since input is taking place in system memory, not user memory.
Disadvantages of block-oriented single buffer:
- OS keeps track of assignment of system buffers to user processes.
- The swapping logic is affected.
Stream-oriented single buffer
-
Line-at-a-time fashion (一次一行)
Input from or output to a terminal is one line at a time with carriage return signaling the end of the line.
-
Byte-at-a-time fashion (一次一字节)
Input and Output follow the producer/consumer model.
Double Buffer
Use two system buffers instead of one.
A process can transfer data to or from one buffer while the OS empties or fills the other buffer.
Circular Buffer
More than two buffers are used.
Each individual buffer is one unit in a circular buffer.
Used when I/O operation must keep up with process.
Disk Scheduling
Disk Performance Parameters
To read or write, the disk head must be positioned at the desired track (磁道) and at the beginning of the desired sector (扇区).
-
Access time
The time it takes to get in position to read or write.
Sum of seek time ( T s T_s Ts) and rotational delay ( 1 2 r \frac{1}{2r} 2r1).
-
Transfer time (传输时间, b r N \frac{b}{rN} rNb)
Data transfer occurs as the sector moves under the head.
The total average access time can be expressed as: T a = T s + 1 2 r + b r N T_a=T_s+{\frac{1}{2r}+{\frac{b}{rN}}} Ta=Ts+2r1+rNb
Disk Scheduling Policies
Seek time and rotational delay are the reasons for differences in performance.
Random scheduling:
- For a single disk there will be a number of I/O requests.
- If requests are selected randomly, we will poor performance.
- Used to evaluate other techniques.
The following disk scheduling policy is useful as a benchmark against which to evaluate other disk scheduling policies because it provides a worst-case scenario: Random scheduling.
FIFO
Process request sequentially.
Fair to all processes.
Approaches random scheduling in performance if there are many processes.
Priority
- Goal is not to optimize disk use but to meet other objectives
- Short batch jobs may have higher priority
- Provide good interactive response time
LIFO
Good for transaction processing systems.
Possibility of starvation since a job may never regain the head of the line unless the queue in front of it empties.
Shortest Service Time First (SSTF)
Select the disk I/O request that requires the least movement of the disk arm from its current position.
Always choose the minimum Seek time.
SCAN
Arm moves in one direction only, satisfying all outstanding requests until it reaches the last track in that direction.
The service direction is then reversed and the scan proceeds in the opposite direction, again picking up all requests in order.
C-SCAN (circular SCAN)
Restricts scanning to one direction only.
When the last track has been visited in one direction, the arm is returned to the opposite end of the disk and the scan begins again.
N-step-SCAN
N-step-SCAN segments the disk request queue into subqueues of length N.
Subqueues are processed one at a time, using SCAN.
New requests added to other queue when queue is processed
To solve: If one or a few processes have high access rates to one track, they can monopolize the entire device by repeated requests to that track.
FSCAN
FSCAN is a policy that uses two subqueues.
One queue is empty for new requests.
The disk scheduling algorithm that implements two subqueues in a measure to avoid the problem of “arm stickiness” is the: FSCAN.
RAID
-
Redundant Array of Independent Disks. (独立冗余磁盘阵列)
-
Set of physical disk drives viewed by the operating system as a single logical drive. (逻辑磁盘)
-
Data are distributed across the physical drives of an array. (数据分布)
-
Redundant disk capacity is used to store parity information. (冗余)
RAIDs:
- RAID 0 (nonredundant)
- RAID 1 (mirrored)
- RAID 2 (redundancy through Hamming code)
- RAID 3 (bit-interleaved parity)
- RAID 4 (block-interleaved parity)
- RAID 5 (block-interleaved distributed parity)
- RAID 6 (block-interleaved dual distributed parity)
Disk Cache
Buffer in main memory for disk sectors.
Contains a copy of some of the sectors on the disk.
Two design issues:
- Method to transfer the block of data from the disk cache to memory assigned to the user process.
- The replacement strategy when the disk cache is full for store new data.
Design Considerations
LRU
- The block that has been in the cache the longest with no reference to it is replaced.
- The cache consists of a stack of blocks.
- Most recently referenced block is on the top of the stack.
- When a block is referenced or brought into the cache, it is placed on the top of the stack.
LFU
- The block that has experienced the fewest references is replaced.
- A counter is associated with each block.
- Counter is incremented each time block accessed.
- Block with smallest count is selected for replacement.
- Some blocks may be referenced many times in a short period of time and the reference count is misleading.
The disk cache replacement strategy that replaces the block that has experienced the fewest references is called: Least Frequently Used (LFU).
Chapter 12 - File Management
Overview
File and File Systems
File Management
- File management system consists of system utility programs that run as privileged applications (特权程序)
- Provides a means of data I/O(文件作为数据输入输出的手段)
- Input to applications is by means of a file
- Output is saved in a file for long-term storage
File System Properties
- Long-term existence (长期存在)
- Sharable between processes (进程共享)
- Structure (结构化存储)
- Have specific structure according to application
File Operations
- Create(定义一个新文件,分配文件结构)
- Delete(删除文件结构,释放相关资源)
- Open(通过“打开”操作,进程可以对文件操作)
- Close(关闭操作,不在对文件进行操作)
- Read(读)
- Write(写)
File Structure
A field is the basic element of data.
A record is a collection of related fields that can be treated as a unit by some application.
A file is a collection of similar records.
A database is a collection of related data.
File Management Systems
File System Architecture
- At the lowest level, device drivers communicate directly with peripheral devices (外部设备) or their controllers or channels.
- The next level is referred to as the basic file system, or the physical I/O level. This is the primary interface with the environment outside of the computer system.
- The basic I/O supervisor is responsible for all file I/O initiation and termination.
- Logical I/O enables users and applications to access records.
- The level of the file system closest to the user is the access method.
The level of the file system architecture that enables users and applications to access file records is called the: Logical I/O level.
File Management Functions
- Identify and locate a selected file.
- On a shared system describe user access control.
- Blocking for access to files
- Manage free blocks
- Allocate free blocks to files.
- Reclaim (回收) free blocks.
File Organization and Access
Criteria for File Organization:
- Short access time
- Ease if update
- Economy of storage
- Simple maintenance
- Reliability
The Pile
Data are collected in the order in which they arrive.
The purpose of the pile is simply to accumulate the mass of data and save it.
Each record consists of one burst of data.
No structure.
Record access is by exhaustive search. (彻底的搜索)
The Sequential File
All records are of the same length, consisting of the same number of fixed-length fields in a particular order.
One particular field, usually the first field in each record, is referred to as the key field.
New records are placed in a log file or transaction file.
Batch update is performed to merge the log file with the master file.
Sequential files are typically used in batch applications and are generally optimum for such applications if they involve the processing of all the records.
The Indexed Sequential File
Sequential file + index + overflow file
Index provides a lookup capability to quickly reach the vicinity of the desired revord.
- Index contains a key field and a pointer to the main file.
- Indexed is searched to find highest key value that is equal to or precedes the desired key value.
The Indexed File
Use multiple indexes for defferent key fields.
- May contain an exhaustive index (完全索引) that contains one entry for every record in the main file.
- May contain a partial index (部分索引) that contains entries to records where the field of interest exists.
Index files itself are sequential file.
The Direct or Hashed File
Directly access a block at a known address.
Key field required for each record.
Hash based on the key field.
Direct files are often used where very rapid access is required, where fixed-length records are used, and where records are always accessed one at a time.
File Directories
Contents
Contains information about files:
- Attributes
- Location
- Ownership (所有者)
Directory itself is a file owned by the OS.
Provides mapping between file names and the files themselves.
- Basic Information
- File name
- File Type
- File Organization
- Address Information
- Volume (卷,指出存储文件的设备)
- Starting Address
- Size Used
- Size Allocated
- Access Control Information
- Owner
- Access Information
- Permitted Actions
- Usage Information
- Date Created
- Identity of Creator
- Date Last Read Access
- Identity of Last Reader
- Date Last Modified
- Identity of Last Modified
- Date of Last Backup
- Current Usage
Structure
Simple Structure for a Directory
Represented by a simple sequential file with the name of the file serving as the key. (用顺序文件代表目录,该目录下的文件名做该顺序文件的关键字)
Forces user to be careful not to use the same name for two different files. (文件不能重名)
Two-level Scheme for a Directory
- A master directory
- Master directory contains entry for each user: Provides address and access control information.
- One directory for each user
- Each user directory is a simple list of files for that user.
However, it still provides users with no help in structuring collections of files.
Hierarchical, or Tree-Structure Directory
Files can be located by following a path from the root, or master, directory down various branches.
Naming
Files can be located (文件定位) by following a path from the root, or master, directory down various branches(文件可以通过从根目录或主目录到各个分支的路径来定位)
Can have several files with the same file name (文件同名) as long as they have unique path names (文件名可以重复,只要唯一的路径名)
Current directory is the working directory.
Files are referenced relative to the working directory.
In a tree-structured directory, the series of directory names that culminates in a file name is referred to as the: Pathname.
File Sharing
In multiuser system, allow files to be shared among users.
Two issues:
- Access rights (存取权限)
- Management of simultaneous access (同时存取控制)
Access Rights
- None (无)
- User may not know of the existence of the file.
- User is not allowed to read the user directory that includes the file.
- Knowledge (知道)
- User can only determine that the file exists and who its owner is.
- Execution (执行)
- The user can load and execute a program but cannot copy it.
- Reading (读)
- The user
- Appending (追加)
- Updating (更新)
- Changing protection (更改保护)
- Deletion (删除)
These rights can be considered to constitute (构成) a hierarchy, with each right implying those that precede it. (这些权限构成了一个层次,每项权限都隐含着它前面的那些权限)
Owners
- Has all rights previously listed.
- May grant rights to others using the following
Simultaneous Access
User may lock entire file when it is to be updated. (文件锁定)
User may lock the individual records during the update. (记录锁定)
Mutual exclusion and deadlock are issues for shared access. (互斥和死锁的问题)
Record Blocking (记录组块)
- Fixed blocking
- Variable-length spanned blocking
- Variable-length unspanned blocking
Fixed blocking is the common mode for sequential files with fixed-length records.
Variable-length spanned blocking is efficient of storage and does not limit the size of records. However, this technique is difficult to implement. Records that span two blocks require two I/O operations, and files are difficult to update, regardless of the organization.
Variable-length unspanned blocking results in wasted space and limits record size to the size of a block.
Secondary Storage Management
File Allocation
File allocation table (FAT) is used to track portions allocated to files.(FAT用于跟踪分配给文件的分区)
Preallocation vs Dynamic Allocation
- Preallocation
- Need the maximum size for the file at the time of creation.
- Difficult to reliably estimate the maximum potential size of the file.
- Dynamic allocation
- Allocates space to a file in portions as needed.
File Allocation Methods
Contiguous Allocation
Single set of blocks is allocated to a file at the time of creation.
Only a single entry in the file allocation table. (Starting block and length of the file)
External fragmentation will occur. (Need to perform compaction,需要压缩算法)
Chained Allcation
Allocation on basis of individual block. (基于单个块进行分配)
Each block contains a pointer to the next block in the chain. (每个块有一个指针指向下一个块)
Only single entry in the file allocation table. (文件分配表中只有一项)
No external fragmentation.
Best for sequential files.
No accommodation of the principle of locality (局部性原理不再适用),so consolidation (迁移、集结) is need to move blocks adjacent each other.
Indexed Allocation
File allocation table contains a separate one-level index for each file (每个文件在文件分配表中有一个一级索引)
The file allocation table contains block number for the index (文件分配表指向该文件在磁盘上的索引块)
The index has one entry for each portion allocated to the file (分配给文件的每个分区都在索引中都有一个表项)
Indexed allocation supports both sequential and direct access to the file and thus is the most popular form of file allocation.(索引分配支持对文件的顺序和直接访问,因此是最流行的文件分配形式)
Free Space Management
-
Bit Tables
Use a vector containing one bit for each block on the disk.
Each entry of a 0 corresponds to a free block, and each one corresponds to a block in use.
-
Chained Free Portions
- The free portions may be chained together by using a pointer and length value in each free portion(空闲区链接在一起)
-
Indexing
-
Free Block List
Reliability
Use a lock to prevent interfere among processes and make sure of consistent of space allocation(使用锁来防止进程之间的干扰,并确保空间分配的一致性)