深入解析docker内核网桥
今天做虚拟桌面,朋友问我,为什么vnc 连接另一个docker 容器一直超时,原因是在docker 启动的时候没有组网,那么接下来我就要解析下docker的内核网络。
我们思考几个问题,带你了解linux 中docker 网络实现的基本原理。
文章分析的基石来源于 Docker 的moby源码:
https://github.com/moby/moby一、docker 网络组成
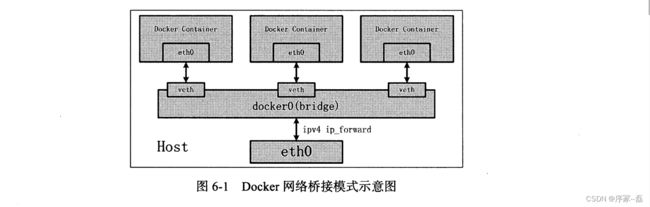 docker 默认有主机模式和网桥模式,这里只说网桥模式,我们说一下docker内核的网桥代码
docker 默认有主机模式和网桥模式,这里只说网桥模式,我们说一下docker内核的网桥代码
先简单说一下容器,容器底层调用的是linux 的 clone,我们使用clone的时候有一些独特的标志位
CLONE_NEWNES,
CLONE_NEWUTS,
CLONE_NEWIPC,
CLONE_NEWPID,
CLONE_NEWNET
使用linux内核的这些标志位,我们都可以创建出不同NS的进程,其中我们需要注意的是CLONE_NEWNET
二、Docker 桥接模式分析
Docker Bridge 实现方式如下:
1)我们实现要考虑不同的两个进程 netns 是不一样的,那么这两个不同的netns之间如何通信?
我们可以使用linux 的 veth 接口 ,申请两个veth 设备假设是veth0 和 veth1。而veth pair 设备确保无论哪一个收到报文都会发送给另一端
2)我们把veth0 附加到 docker daemon 创建的docker0 网桥上。保证宿主机有能力把报文发送到veth0
3) 然后我们把 veth1 添加到容器所属的命名空间下,veth1 在Docker 容器里看来就是eth0。一方面保证网络报文发往veth0,可以被veth1收到,实现宿主机到docker 容器之间连通性。
1)问题反思?
docker 网桥是如何实现的?
docker 又是怎么通过建立linux 设备veth的?
docker 创建这些基础网络组件的过程中,到底是用了linux 内核的哪些特性?
2)docker 网桥是如何实现的?
go 部分
我们翻阅Docker 源码,发现这么一段
位于源码的
daemon/daemon_unix.go
// --ip processing
if cfg.DefaultIP != nil {
netOption[bridge.DefaultBindingIP] = cfg.DefaultIP.String()
}
_, err = controller.NewNetwork("bridge", "bridge", "",
libnetwork.NetworkOptionEnableIPv6(cfg.EnableIPv6),
libnetwork.NetworkOptionDriverOpts(netOption),
libnetwork.NetworkOptionIpam("default", "", v4Conf, v6Conf, nil),
libnetwork.NetworkOptionDeferIPv6Alloc(deferIPv6Alloc))libnetwork/controller.go
func (c *Controller) addNetwork(n *Network) error {
d, err := n.driver(true)
if err != nil {
return err
}
// Create the network
if err := d.CreateNetwork(n.id, n.generic, n, n.getIPData(4), n.getIPData(6)); err != nil {
return err
}
n.startResolver()
return nil
}最后我们发现网桥的实现最后到了CreateNetwork中,我们在追踪进入CreateNetwork中
libnetwork/drivers/bridge/bridge_linux.go
CreateNetwork 的实现我们发现具体关键代码位于
// If the bridge interface doesn't exist, we need to start the setup steps
// by creating a new device and assigning it an IPv4 address.
bridgeAlreadyExists := bridgeIface.exists()
if !bridgeAlreadyExists {
bridgeSetup.queueStep(setupDevice)
bridgeSetup.queueStep(setupDefaultSysctl)
}
再继续看 setupDevice,一切水落石处,Docker 网桥创建的关键在于 setupDevice
func setupDevice(config *networkConfiguration, i *bridgeInterface) error {
// We only attempt to create the bridge when the requested device name is
// the default one. The default bridge name can be overridden with the
// DOCKER_TEST_CREATE_DEFAULT_BRIDGE env var. It should be used only for
// test purpose.
var defaultBridgeName string
if defaultBridgeName = os.Getenv("DOCKER_TEST_CREATE_DEFAULT_BRIDGE"); defaultBridgeName == "" {
defaultBridgeName = DefaultBridgeName
}
if config.BridgeName != defaultBridgeName && config.DefaultBridge {
return NonDefaultBridgeExistError(config.BridgeName)
}
// Set the bridgeInterface netlink.Bridge.
i.Link = &netlink.Bridge{
LinkAttrs: netlink.LinkAttrs{
Name: config.BridgeName,
},
}
// Set the bridge's MAC address. Requires kernel version 3.3 or up.
hwAddr := netutils.GenerateRandomMAC()
i.Link.Attrs().HardwareAddr = hwAddr
log.G(context.TODO()).Debugf("Setting bridge mac address to %s", hwAddr)
if err := i.nlh.LinkAdd(i.Link); err != nil {
log.G(context.TODO()).WithError(err).Errorf("Failed to create bridge %s via netlink", config.BridgeName)
return err
}
return nil
}linux 接口部分:
既然我们找到了库的实现,那么我们继续思考netlink库为什么能调在linux 系统里创建网桥,它到底是使用了kernel 开发的哪些能力?
分析go netlink 库我发现了一个函数叫linkModify,他的一段代码实现如下:
_, err := req.Execute(unix.NETLINK_ROUTE, 0)
if err != nil {
return err
}底层使用的是
func getNetlinkSocket(protocol int) (*NetlinkSocket, error) {
fd, err := unix.Socket(unix.AF_NETLINK, unix.SOCK_RAW|unix.SOCK_CLOEXEC, protocol)
if err != nil {
return nil, err
}
s := &NetlinkSocket{
fd: int32(fd),
}
s.lsa.Family = unix.AF_NETLINK
if err := unix.Bind(fd, &s.lsa); err != nil {
unix.Close(fd)
return nil, err
}
return s, nil
}
也就是说Docker 的网络库最终使用的是
netlink socket API:
socket()函数
socket域(地址族)是AF_NETLINK
socket类型是SOCK_RAW或SOCK_DGRAM,因为netlink是一种面向数据的服务
netlink协议类型定义在netlink.h(以下以NETLINK_ROUTE为例),也可以自定义
AF_NETLINK 无疑是linux 中内核态和用户态通信的重要手段,他和ioctl的最大区别是,AF_NETLINK是一种协议族,提供了一种标准化的机制,用于用户态程序与内核之间进行网络相关的通信。它定义了不同的协议类型,如NETLINK_ROUTE、NETLINK_SELINUX等,以支持特定的网络操作和功能。使用AF_NETLINK,用户态程序可以发送特定类型的消息给内核,以请求或传递网络相关的信息。
docker 是使用AF_NETLINK 做的,而我们使用brctl 却是使用的ioctl
docker veth 设备是如何实现的
case *Veth:
data := linkInfo.AddRtAttr(nl.IFLA_INFO_DATA, nil)
peer := data.AddRtAttr(nl.VETH_INFO_PEER, nil)
nl.NewIfInfomsgChild(peer, unix.AF_UNSPEC)
peer.AddRtAttr(unix.IFLA_IFNAME, nl.ZeroTerminated(link.PeerName))
if base.TxQLen >= 0 {
peer.AddRtAttr(unix.IFLA_TXQLEN, nl.Uint32Attr(uint32(base.TxQLen)))
}
if base.NumTxQueues > 0 {
peer.AddRtAttr(unix.IFLA_NUM_TX_QUEUES, nl.Uint32Attr(uint32(base.NumTxQueues)))
}
if base.NumRxQueues > 0 {
peer.AddRtAttr(unix.IFLA_NUM_RX_QUEUES, nl.Uint32Attr(uint32(base.NumRxQueues)))
}
if base.MTU > 0 {
peer.AddRtAttr(unix.IFLA_MTU, nl.Uint32Attr(uint32(base.MTU)))
}
if link.PeerHardwareAddr != nil {
peer.AddRtAttr(unix.IFLA_ADDRESS, []byte(link.PeerHardwareAddr))
}
if link.PeerNamespace != nil {
switch ns := link.PeerNamespace.(type) {
case NsPid:
val := nl.Uint32Attr(uint32(ns))
peer.AddRtAttr(unix.IFLA_NET_NS_PID, val)
case NsFd:
val := nl.Uint32Attr(uint32(ns))
peer.AddRtAttr(unix.IFLA_NET_NS_FD, val)
}
}我们发现还是AF_NETLINK 实现的
三、快速组网组成一个测试网络
创建网桥
ip link add br0 type bridge启动网桥
ip link set br0 up创建网络命名空间ns1 和ns2
~# ip netns add ns1
~# ip netns add ns2创建 veth 对
~# ip link add veth0 type veth peer br-veth0
~# ip link add veth1 type veth peer br-veth1查看创建的 veth 对,通过查看此时 veth对 在 root名称空间下
ip address show将创建的 veth对 的一端插入到指定的名称空间
~# ip link set veth0 netns ns1
~# ip link set veth1 netns ns2通过进入不同的名称空间查看网卡的一端
~# ip netns exec ns1 ip a
~# ip netns exec ns2 ip a将创建的 veth对 的另一端插入到 br0 的桥接网卡
~# ip link set br-veth0 master br0
~# ip link set br-veth1 master br0启动网卡 veth0 veth1 br-veth0 br-veth1,并配置 ip 地址
// 开启网桥部分
~# ip link set br-veth0 up
~# ip link set br-veth1 up
// 开启ns里的veth
~# ip netns exec ns1 ip link set veth0 up
~# ip netns exec ns2 ip link set veth1 up
// 设置容器内的veth 设备ip
~# ip netns exec ns1 ifconfig veth0 192.168.100.10/24
~# ip netns exec ns2 ifconfig veth1 192.168.100.20/24四、总结
Docker 创建网桥和Veth设备都是通过AF_NETLINK 套接字实现的,我需要去读 <精通linux内核网络>这本书去调研一下