面试中被问到:Netty中的零拷贝机制是怎么样的?
零拷贝(Zero-copy), CPU不需要为数据在内存之间的拷贝消耗资源。而它通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式。Zero Copy的模式中,避免了数据在用户空间和内存空间之间的拷贝,从而提高了系统的整体性能。
Netty 零复制场景
零拷贝是Netty的一个特性,主要发生在操作数据上,无须将数据buffer从一个内存区域拷贝到另个一内存区域,少一次拷贝,CPU效率就会提升。
Netty的零拷贝主要体现在以下5个方面中:
(1)Netty接收和发送ByteBuffer采用的都是堆外直接内存,使用堆外直接内存进行Socket的读/写,无须进行字节缓冲区的二次拷贝。如果使用传统的堆内存进行Socket的读/写,则JVM会将堆内存Buffer数据拷贝到堆外直接内存中,然后才写入Socket中。与堆外直接内存相比,使用传统的堆内存,在消息的发送过程中多了一次缓冲区的内存拷贝。
(2)在网络传输中,一条消息很可能会被分割成多个数据包进行发送,只有当收到一个完整的数据包后,才能完成解码工作。Netty通过组合内存的方式把这些内存数据包逻辑组合到一块,而不是对每个数据块进行一次拷贝,这类似于数据库中的视图。CompositeByteBuf是Netty在此零拷贝方案中的组合Buffer。
(3)Netty 使用 FileRegion 实现文件传输,FileRegion 底层封装了 FileChannel#transferTo() 方法,可以将文件缓冲区的数据直接传输到目标 Channel,避免内核缓冲区和用户态缓冲区之间的数据拷贝,这属于操作系统级别的零拷贝。
(4)通过 wrap 操作, 我们可以将 byte[] 数组、ByteBuf、ByteBuffer等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作。
(5)Netty 提供了 ByteBuf 的浅层复制操作( slice 、 duplicate ),可以将 ByteBuf 分解为多个共享同一个存储区域的 Byte Buf, 避免内存的拷贝。
ByteBuf 的浅层复制
浅层复制是一个非常重要的操作,可以很大程度第避免内存复制。ByteBuf的浅层复制分为两种:
- 切片(slice)浅层复制
- 整体(duplicate)浅层复制
切片(slice)浅层复制
ByteBuf的 slice 方法可以获取到一个 ByteBuf 的一个切片。一个 ByteBuf 可以进行多次的切片浅层复制;多次切片后的ByteBuf对象可以共享一个存储区域。
slice方法有两个重载版本:
public abstract class AbstractByteBuf extends ByteBuf {
/**
* 返回ByteBuf实例中可读部分的切片
* @return
*/
@Override
public ByteBuf slice() {
return slice(readerIndex, readableBytes());
}
/**
* 方法,可以通过灵活地设置不同起始位置和长度,来获取到
* ByteBuf 不同区域的切片。
* @param index 开始位置
* @param length 长度
* @return
*/
@Override
public ByteBuf slice(int index, int length) {
ensureAccessible();
return new UnpooledSlicedByteBuf(this, index, length);
}
}
调用slice() 方法后,返回的切片是一个新的 ByteBuf对象,切片后的新ByteBuf 有两个特点:
- 切片不可以写入,原因是maxCapacity 与WriterIndex 值相同;
- 切片和源ByteBuf的可读字节数相同,原因是:切片后的可读字节数为自己的属性 writerIndex = readerIndex ,也就是源 ByteBuf 的 readableBytes() =0 。
切片后的新ByteBuf 和源 ByteBuf 的关联性:
- 切片不会复制源 ByteBuf 的底层数据,底层数组和源 ByteBuf 的底层数组是同一个。
- 切片不会改变源 ByteBuf 的引用计数。
从根本上说,slice() 无参数方法所生成的切片就是源 ByteBuf 可读部分的浅层复制。
整体(duplicate)浅层复制
duplicate() 返回的是源 ByteBuf 的整个对象的一个浅层复制,包括如下内容:
- duplicate 的读写指针、最大容量值,与源 ByteBuf 的读写指针相同。
- duplicate() 不会改变源 B yteBuf 的引用计数。
- duplicate() 不会复制源 ByteBuf 的底层数据。
duplicate()和 slice() 方法都是浅层复制。不同的是, slice() 方法是切取一段的浅层复制, 而 duplicate( ) 是整体的浅层复制。
浅层复制方法不会实际去复制数据,也不会改变ByteBuf 的引用计数,这就会导致一个问题:在源 ByteBuf 调用 release() 之后,一旦引用计数为零,就变得不能访问了;在这种场景下,源 ByteBuf 的所有浅层复制实例也不能进行读写了;如果强行对浅层复制实例进行读写,则会报错。
因此,在调用浅层复制实例时,可以通过调用一次 retain() 方法来增加 一次 引用,表示它们对应的底层内存多了一次引用, 此后引用计数为 2 。在浅层复制实例用完后,需要调用一次 release() 方法,将引用计数减 1 ,这样就不影响 Netty 内部的 ByteBuf 的内存释放。
CompositeByteBuf
CompositeByteBuf的主要功能是组合多个ByteBuf,对外提供统一的readerIndex和writerIndex。由于它只是将多个ByteBuf的实例组装到一起形成了一个统一的视图,并没有对ByteBuf中的数据进行拷贝。
在 CompositeByteBuf 内部 , 合并的多个 ByteBuf 都是单独存在的。 CompositeByteBuf 里面有个 Component 数组,聚合的 ByteBuf 都放在 Component 数组里面,最小容量为16。
CompositeByteBuf的零复制主要应用与解码和编码。

将消息头和消息体两个ByteBuf组合到一块进行编码,在将ByteBuf写入缓冲区之前,需要对整个消息进行编码,如长度编码,此时需要把两个ByteBuf合并成一个,无须额外处理就可以知道其整体长度。因此使用CompositeByteBuf是非常适合的。
在解码时,由于Socket通信传输数据会产生粘包和半包问题,因此需要一个读半包字节容器,这个容器采用CompositeByteBuf比较合适,将每次从Socket中读到的数据直接放入此容器中,少了一次数据的拷贝。
如果不使用CompositeByteBuf,原始的将header 和body 合并成为一个ByteBuf的代码,代码如下:
//消息头
ByteBuf headerBuf = Unpooled.copiedBuffer("java RPC 框架:",utf8);
//消息体
ByteBuf bodyBuf = Unpooled.copiedBuffer("高性能netty",utf8);
long length = headerBuf.readableBytes() + bodyBuf.readableBytes();
ByteBuf allBuf = Unpooled.buffer(length);
//拷贝 header 数据
allBuf.writeBytes(headerBuf );
//拷贝 body 数据
allBuf.writeBytes(body);
使用CompositeByteBuf 合并多个 ByteBuf ,代码如下:
//消息头
ByteBuf headerBuf = Unpooled.copiedBuffer("java RPC 框架:",utf8);
//消息体
ByteBuf bodyBuf = Unpooled.copiedBuffer("高性能netty",utf8);
cbuf.addComponents(headerBuf,bodyBuf);
sendMsg(cbuf);
不使用CompositeByteBuf的情况下,将header 和 body 都拷贝到了新的 allBuf 中,增加了两次额外的数据拷贝操作 。使用 CompositeByteBuf 合并 ByteBuf ,减少两次额外的数据拷贝操作。
CompositeByteBuf内部定义了一个Component类型的集合。实际上,Component是ByteBuf的包装实现类,它聚合了ByteBuf对象并维护了ByteBuf对象在集合中的位置偏移量信息等。
private Component[] components; // resized when needed
添加ByteBuf 的方法addComponent()方法源码如下:
/**
* 添加bytebuf
*/
public CompositeByteBuf addComponent(boolean increaseWriterIndex, int cIndex, ByteBuf buffer) {
checkNotNull(buffer, "buffer");
//把buffer加入Component数组中
//并对数组中的元素进行相应的挪动
addComponent0(increaseWriterIndex, cIndex, buffer);
//是否需要合并成一个ByteBuf
consolidateIfNeeded();
return this;
}
/**
* Precondition is that {@code buffer != null}.
*/
private int addComponent0(boolean increaseWriterIndex, int cIndex, ByteBuf buffer) {
assert buffer != null;
boolean wasAdded = false;
try {
//检查下标是否正常
checkComponentIndex(cIndex);
// No need to consolidate - just add a component to the list.
//构建包装component
Component c = newComponent(ensureAccessible(buffer), 0);
int readableBytes = c.length();
// Check if we would overflow.
// See https://github.com/netty/netty/issues/10194
if (capacity() + readableBytes < 0) {
throw new IllegalArgumentException("Can't increase by " + readableBytes);
}
//把component追加到数组中,并移动其后面的元素
addComp(cIndex, c);
wasAdded = true;
if (readableBytes > 0 && cIndex < componentCount - 1) {
//当插入的位置不在数组末尾时,不仅需要设置插入元素的位置信息,还需要更新其后面元素的位置信息
updateComponentOffsets(cIndex);
} else if (cIndex > 0) {
//当插入的位置在数组末尾时,只需设置插入元素的位置信息即可
c.reposition(components[cIndex - 1].endOffset);
}
//是否修改写索引
if (increaseWriterIndex) {
writerIndex += readableBytes;
}
return cIndex;
} finally {
//当出现异常增加失败时,释放buffer
if (!wasAdded) {
buffer.release();
}
}
}
@SuppressWarnings("deprecation")
private Component newComponent(final ByteBuf buf, final int offset) {
//获取buf读索引及buf的长度
final int srcIndex = buf.readerIndex();
final int len = buf.readableBytes();
// unpeel any intermediate outer layers (UnreleasableByteBuf, LeakAwareByteBufs, SwappedByteBuf)
ByteBuf unwrapped = buf;
int unwrappedIndex = srcIndex;
while (unwrapped instanceof WrappedByteBuf || unwrapped instanceof SwappedByteBuf) {
unwrapped = unwrapped.unwrap();
}
/**
* 若是派生 ByteBuf,则需要通过unwrap 得到原始 ByteBuf
* 原始 buf 的读索引=派生 buf 读索引+偏移量 adjustment
* 由于是非可重复利用内存,所以其读索引应为 0
*/
// unwrap if already sliced
if (unwrapped instanceof AbstractUnpooledSlicedByteBuf) {
unwrappedIndex += ((AbstractUnpooledSlicedByteBuf) unwrapped).idx(0);
unwrapped = unwrapped.unwrap();
} else if (unwrapped instanceof PooledSlicedByteBuf) {
unwrappedIndex += ((PooledSlicedByteBuf) unwrapped).adjustment;
unwrapped = unwrapped.unwrap();
} else if (unwrapped instanceof DuplicatedByteBuf || unwrapped instanceof PooledDuplicatedByteBuf) {
unwrapped = unwrapped.unwrap();
}
// We don't need to slice later to expose the internal component if the readable range
// is already the entire buffer
final ByteBuf slice = buf.capacity() == len ? buf : null;
//包装成Component对象返回,并设置为大端模式
return new Component(buf.order(ByteOrder.BIG_ENDIAN), srcIndex,
unwrapped.order(ByteOrder.BIG_ENDIAN), unwrappedIndex, offset, len, slice);
}
处理数据的读/写源码如下:
//读数据
@Override
public CompositeByteBuf getBytes(int index, byte[] dst, int dstIndex, int length) {
checkDstIndex(index, length, dstIndex, dst.length);
if (length == 0) {
return this;
}
//根据 readerIndex 获取 components 数组的下标
int i = toComponentIndex0(index);
/**
* 由于 ByteBuf 是逻辑组合
* 在读的过程中,一个 buf 可能不够
* 需要从多个 buf 中读取数据,因此需要 while 循环,直到写满
*/
while (length > 0) {
Component c = components[i];
//在每次读数据时,只能读取当前 buf 的可读字节与 length 两者中的最小值
int localLength = Math.min(length, c.endOffset - index);
//从 buf 中读取 localLength 字节到 dst中
c.buf.getBytes(c.idx(index), dst, dstIndex, localLength);
//其读索引值需要增加 localLength
index += localLength;
//目标 buf 的写索引也需进行相应的增加
dstIndex += localLength;
//对需要写的字节数进行相应的调整
length -= localLength;
//components 数组的下标也要向上移一位
i ++;
}
return this;
}
//通过偏移量获取对应的下标
private int toComponentIndex0(int offset) {
int size = componentCount;
//偏移量为0,快速获取第一个元素
if (offset == 0) { // fast-path zero offset
for (int i = 0; i < size; i++) {
if (components[i].endOffset > 0) {
return i;
}
}
}
//当小于或等于两个元素时,没必要使用二分查找算法,注销快速判断并获取即可
if (size <= 2) { // fast-path for 1 and 2 component count
return size == 1 || offset < components[0].endOffset ? 0 : 1;
}
/**
* 当component数组中的元素个数多于两个时,使用二分查找算法
* 其分割规则主要根据偏移量来判断
* (1)当偏移量大于或等于元素的endOffset时,low = mid+1
* (2)当偏移量小于遍历元素的offset时 ,high = mid-1
* (3)当偏移量等于遍历元素的offset时,只需要返回其下标即可.
*/
for (int low = 0, high = size; low <= high;) {
int mid = low + high >>> 1;
Component c = components[mid];
if (offset >= c.endOffset) {
low = mid + 1;
} else if (offset < c.offset) {
high = mid - 1;
} else {
return mid;
}
}
throw new Error("should not reach here");
}
// 写数据,从src缓冲区读取数据并写入compositeByteBuf中
@Override
public CompositeByteBuf setBytes(int index, byte[] src, int srcIndex, int length) {
checkSrcIndex(index, length, srcIndex, src.length);
if (length == 0) {
return this;
}
//根据writerIndex获取components数组的下标
int i = toComponentIndex0(index);
/**
* 循环写入,逻辑与循环读数据逻辑类似
* 只是index从readerIndex 换成writerIndex
*/
while (length > 0) {
Component c = components[i];
int localLength = Math.min(length, c.endOffset - index);
c.buf.setBytes(c.idx(index), src, srcIndex, localLength);
index += localLength;
srcIndex += localLength;
length -= localLength;
i ++;
}
return this;
}
虽然Component是ByteBuf的包装对象,但它并没有像其他派生对象一样调用retain()方法。ByteBuf的引用计数器并没有任何的改变。
Unpooled 提供wrap包装方法实现零复制
wrap 操作和 slice操作刚好相反, , slice 操作可以将一个 ByteBuf 切片为多个共享一个存储区域的 ByteBuf 对象,而Unpooled.wrappedBuffer 可以将多个 ByteBuf 合并为一个.
Unpooled提供了一系列的 wrap 包装方法,方便快速包装出 CompositeByteBuf 实例或者 ByteBuf 实例,而不用进行内存的拷贝。
Unpooled 包装 CompositeByteBuf 的操作,使用起来更加方便。其代码如下:
//消息头
ByteBuf headerBuf = Unpooled.copiedBuffer("java RPC 框架:",utf8);
//消息体
ByteBuf bodyBuf = Unpooled.copiedBuffer("高性能netty",utf8);
ByteBuf allByte = Unpooled.wrappedBuffer(headerBuf,bodyBuf);
Unpooled类提供了很多重载的 wrappedBuffer 方法,将多个 ByteBuf 包装为 CompositeByteBuf 实例,从而实现零拷贝,这些重载方法大致如下:
public static ByteBuf wrappedBuffer(ByteBuf buffer)
public static ByteBuf wrappedBuffer(ByteBuf... buffers)
public static ByteBuf wrappedBuffer(ByteBuffer buffer)
public static ByteBuf wrappedBuffer(ByteBuffer... buffers)
如果不是使用Unpooled.wrappedBuffer(…) 包装方法,那么传统的做法是将此 byte 数组的内容拷贝到 ByteBuf 中,这种方式有额外的内存申请和拷贝操作的 , 既浪费了内存空间,而且需要耗费内存复制的时间。其代码如下:
byte[] bytes = {1,2,3,5};
ByteBuf byteBuf = Unpooled.buffer();
byteBuf.writeBytes(bytes);
通过Unpooled 将 byte 数组包装成 ByteBuf 。其代码如下:
byte[] bytes = {1,2,3,5};
ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);
通过Unpooled.wrappedBuffer 方法将 bytes 包装为一个 UnpooledHeapByteBuf 对象, 而在包装的过程中 , 不会有拷贝操作的,所得到的 ByteBuf 对象是和 bytes 数组共用了同一个存储 间,对 bytes 的修改也就是对 ByteBuf 对象的修改 。此操作既复用了空间,节省了时间。
通过 FileRegion 实现零拷贝
Netty 传输文件的时候没有使用 ByteBuf 进行向 Channel 中写入数据,而使用的 FileRegion。
首先,我们来看个示例,使用netty发送文件的核心代码:
public void runClient() {
//创建reactor 线程组
EventLoopGroup workerLoopGroup = new NioEventLoopGroup();
try {
//1 设置reactor 线程组
b.group(workerLoopGroup);
//2 设置nio类型的channel
b.channel(NioSocketChannel.class);
//3 设置监听端口
b.remoteAddress(serverIp, serverPort);
//4 设置通道的参数
b.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
//5 装配子通道流水线
b.handler(new ChannelInitializer<io.netty.channel.socket.SocketChannel>() {
//有连接到达时会创建一个channel
protected void initChannel(io.netty.channel.socket.SocketChannel ch) throws Exception {
// pipeline管理子通道channel中的Handler
// 向子channel流水线添加一个handler处理器
ch.pipeline().addLast(new FileSendHandler());
}
});
ChannelFuture f = b.connect();
f.addListener((ChannelFuture futureListener) ->
{
if (futureListener.isSuccess()) {
Logger.info("客户端连接成功!");
} else {
Logger.info("客户端连接失败!");
}
});
// 阻塞,直到连接完成
f.sync();
Channel channel = f.channel();
// String srcPath = NioDemoConfig.SOCKET_SEND_BIG_FILE;
String srcPath = NioDemoConfig.SOCKET_SEND_FILE;
channel.writeAndFlush(srcPath);
// 7 等待通道关闭的异步任务结束
// 服务监听通道会一直等待通道关闭的异步任务结束
ChannelFuture closeFuture = channel.closeFuture();
closeFuture.sync();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 优雅关闭EventLoopGroup,
// 释放掉所有资源包括创建的线程
workerLoopGroup.shutdownGracefully();
}
}
public class FileSendHandler extends ChannelOutboundHandlerAdapter {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
....
//发送文件名称长度
ByteBuf outBuf = ctx.alloc().buffer();
outBuf.writeInt(fileNameBytes.length);
outBuf.writeBytes(fileNameBytes);
outBuf.writeInt((int) length);
ctx.writeAndFlush(outBuf);
Logger.info("文件长度:" + length);
ChannelFuture future = null;
//发送文件内容
if (ctx.pipeline().get(SslHandler.class) == null) {
//创建一个fileRegion对象
DefaultFileRegion fileRegion = new DefaultFileRegion(raf.getChannel(), 0, length);
// 传输文件使用了 DefaultFileRegion 进行写入到 NioSocketChannel 中 ==》核心代码
future = ctx.write(fileRegion);
} else {
// SSL enabled - cannot use zero-copy file transfer.
future = ctx.write(new ChunkedFile(raf));
}
future.addListener(f -> {
if (f.isSuccess()) {
Logger.info("发送完成");
ctx.channel().close();
}
});
}
}
DefaultFileRegion 类是接口类FileRegion的默认实现,在DefaultFileRegion方法中定义了几个比较重要的属性:
// 传输的文件
private final File f;
// 文件的其实坐标
private final long position;
// 传输的字节数
private final long count;
// 已经写入的字节数
private long transferred;
// 传输文件对应的 FileChannel
private FileChannel file;
DefaultFileRegion 中有一个方法是transferTo(),其源码如下:
@Override
public long transferTo(WritableByteChannel target, long position) throws IOException {
long count = this.count - position;
if (count < 0 || position < 0) {
throw new IllegalArgumentException(
"position out of range: " + position +
" (expected: 0 - " + (this.count - 1) + ')');
}
if (count == 0) {
return 0L;
}
if (refCnt() == 0) {
throw new IllegalReferenceCountException(0);
}
// Call open to make sure fc is initialized. This is a no-oop if we called it before.
open();
//核心代码==》调用了Nio 的FileChannel.transferTo()方法发送文件
long written = file.transferTo(this.position + position, count, target);
if (written > 0) {
transferred += written;
} else if (written == 0) {
validate(this, position);
}
return written;
}
文件通过 FileChannel.transferTo 方法直接发送到 WritableByteChannel 中。,通过断点可知:
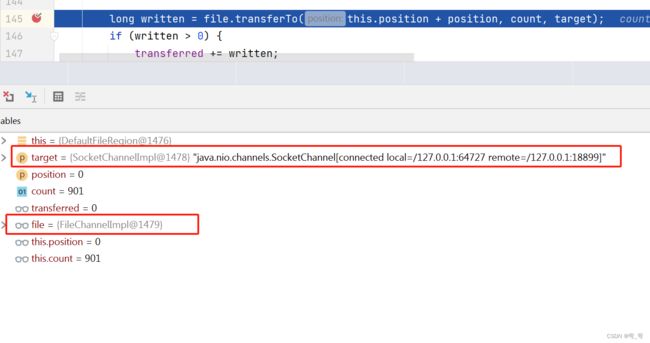
target 是Java Nio的channels的socket, file是Nio的FileChannelImpl。
那FileRegion是在AbstractNioByteChannel.doWriteInternal()方法中写入的,其源码如下:
private int doWriteInternal(ChannelOutboundBuffer in, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
if (!buf.isReadable()) {
//若可读字节数为0,则从缓存区中移除
in.remove();
return 0;
}
//实际发送字节数据
final int localFlushedAmount = doWriteBytes(buf);
if (localFlushedAmount > 0) {
//更新字节数据的发送进程
in.progress(localFlushedAmount);
if (!buf.isReadable()) {
//若可读字节数为o,则从缓存区中移除
in.remove();
}
return 1;
}
} else if (msg instanceof FileRegion) {
//如果是文件FileRegion消息
FileRegion region = (FileRegion) msg;
if (region.transferred() >= region.count()) {
in.remove();
return 0;
}
//实际写操作
long localFlushedAmount = doWriteFileRegion(region);
if (localFlushedAmount > 0) {
//更新数据的发送进度
in.progress(localFlushedAmount);
if (region.transferred() >= region.count()) {
//若region已经全部发送成功,则从缓存中移除
in.remove();
}
return 1;
}
} else {
// Should not reach here.
//不支持发送其他类型的数据
throw new Error();
}
//当实际发送字节数为0时 ,返回Integer.MAX_VALUE
return WRITE_STATUS_SNDBUF_FULL;
}
从 ChannelOutboundBuffer 中获取 FileRegion 类型的节点。然后调用 NioSocketChannel.doWriteFileRegion() 方法进行写入;其源码如下:
@Override
protected long doWriteFileRegion(FileRegion region) throws Exception {
final long position = region.transferred();
return region.transferTo(javaChannel(), position);
}
总结:
通过 Nio 的 FileChannel 可以使用 map 文件映射的方式,直接发送到 SocketChannel中,这样可以减少两次 IO 的复制。
第一次 IO:读取文件的时间从系统内存中拷贝到 jvm 内存中。
第二次 IO:从 jvm 内存中写入 Socket 时,再 Copy 到系统内存中。