RDD常用算子总结
一、转换算子(Transformation)
返回一个新的RDD;
惰性,遇到动作算子才会触发执行;
不存储实际数据,只存储转换规则,遇到动作算子根据规则对数据进行处理。
1、单值类型
针对value进行处理的相关算子。
(1)map算子:一对一的转换操作
根据用户传入的自定义转换规则(函数),将数据一对一的转换成为一个新的RDD。
map算子是作用在每个分区、每个元素上,对每个元素执行自定义的函数。
演示:对列表中的每一个元素进行+1操作

(2)groupBy算子:用于执行分组操作
根据传入的函数对数据进行分组操作,每一组都是一个迭代器(列表)
演示:将数据分为奇数和偶数
转换前:

转换后:
![]()
其中,mapValues(list) 是对kv类型进行处理,主要对value进行数据转换,参数写入一个列表对象,将其转换为List列表。
(3)filter算子:数据过滤
根据传入的自定义函数对数据进行过滤操作,自定义函数用于定义过滤规则。
自定义函数返回false表示过滤掉,返回true表示保留此数据。
演示:过滤掉奇数,保留偶数。

(4)flatMap算子:将map结果扁平化
先对数据根据传入的函数进行map操作,然后对map的结果进行扁平化。
演示:将每个名字抽取出来,放到一个列表中。

2、双值类型
(1)union:计算两个RDD的并集
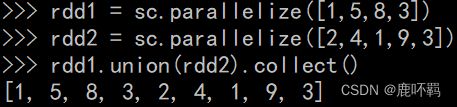
(2)intersection:计算两个RDD的交集
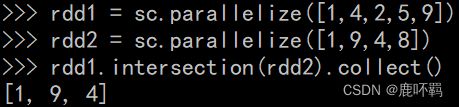
3、KV类型的相关算子
(1)groupByKey:
根据key进行分组,将value合并为一个迭代器(列表)
演示:对同一组的人进行聚合操作。
![]()
(2)reduceByKey:
根据key进行分组,将value合并为一个迭代器(列表),然后根据传入的自定义函数,对每组中value数据进行聚合处理。
演示:统计每个组的人数。

(3)sortByKey:
根据key进行排序操作。默认升序,若想倒序排列,设置参数ascending = False(可直接写False,省略 ascending =)。
演示:根据key值对数据进行排序。

(4)countByValue:
对value进行count的数量统计。
演示:统计各数字个数。

二、动作算子(Action)
不会返回RDD,要不没有返回值,要不返回其他;
所有动作算子都是立即执行,在代码中每一个action都会触发一个JOB的任务。
1、collect:
将各个分区的处理完成的数据收集回来,统一放在一个列表中。
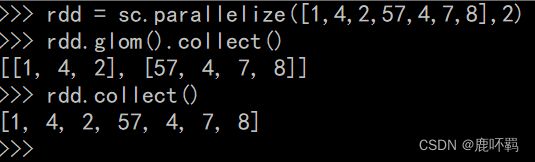
2、reduce:
对数据进行聚合操作,根据传入的fn完成聚合统计。
演示:对数据进行求和。

3、first:
获取第一个数据。

4、take:
获取前N个数据,类似SQL中的limit。

5、top:
先对数据进行降序排列,然后获取前N个元素,支持自定义排序规则。
对于单值类型的数据,直接降序排序;对于KV型,默认按照K进行倒序排序,也可以自定义排序方案。
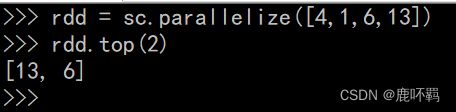
6、count:
获取一共返回多少个元素。

7、takeSample:对数据进行抽样
takeSample(是否允许重复抽取,抽样数量[,种子值])
一旦设置种子值,会导致相同种子值的每次采样结果也相同。

8、foreach(fn):
对数据遍历,参数fn表示每次遍历执行的操作,没有返回值。

三、RDD重要算子
1、分区函数
对RDD中每一个分区进行处理操作。减少自定义函数出发的次数,如果自定义函数中有资源相关的操作(如IO),触发次数减少,则会减少资源调度,提高效率。
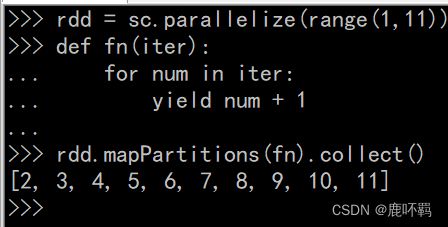
(1)mapPartitions:
相对于普通函数:map算子,根据用户传入的自定义转换规则(函数),将数据一对一的转换成为一个新的RDD。
(2)foreachPartition:
相对于普通算子:foreach函数,对数据进行遍历。

2、重分区函数:
对RDD中分区数量进行增大或减少。
①增大分区数量情况:
一个分区通过一个线程来处理,当分区中数量较大时,即每个线程中所需处理的数据量较大。此时可以增大分区数量,从而减少每个线程处理的数据量,提高并行度,提高效率。
②减少分区数量的情况:
每个分区数据量较小时,分区数多造成资源损耗,此时可以减少分区数量,从而减少资源浪费。
当需要将数据写出到文件系统时,分区越多输出的文件数量越多,减少分区数量,从而减少输出文件数量,避免小文件过多。
(1)repartition:
增加或减少分区的数量,此算子会产生shuffle(清理)。

(2)coalesce:
减少分区数量,不会产生shuffle。
coalesce(N,ifShuffle=False) 参数二表示是否有shuffle,默认为false,表示没有,此时只能减少分区。如果要增大分区,需要设置为True。
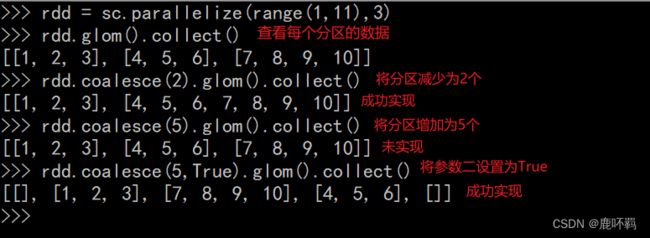
注:reparation是coalesce当参数为为True时的一种简写。
3、KV类型的调整分区的函数
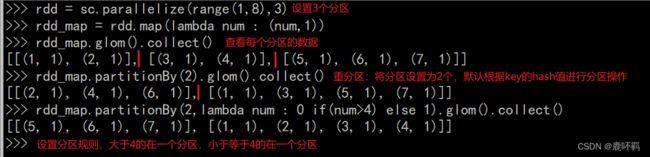
partitionBy:
partitionBy(N,[fn]) 参数二设置分区规则。
四、聚合函数
1、单值聚合算子
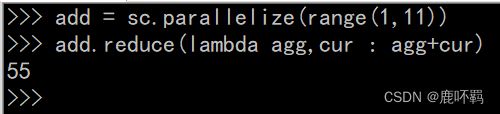
(1)reduce(fn)
根据传入的自定义函数,对整个数据集进行聚合统计。默认agg初始值为 0。
(2)fold(default,fn)
根据传入的自定义函数,对整个数据集进行聚合统计,可以设置agg的初始值。

问:为什么是105?
答:
(3)aggregate(default,fn1,fn2)
参数一:agg初始值 参数二:对每个分区执行的函数 参数三:对各个分区结果执行的函数

执行逻辑和fold类似。
注:当参数二和参数三处理的逻辑一样时,可以写为fold聚合,当初始值为0时,可以简写为reduce。
五、关联函数
针对类型:KV。
1、join():内连接
两个RDD的K值一样的数据会连接在一起。

2、leftOuterJoin():左关联
以左表数据为准,左表有数据,右表无数据的补None。

3、rightOuterJoin():右关联

4、fullOuterJoin:全外连接
