First Order Motion Model for Image Animation
仅 供 参 考
图像动画包括生成视频序列,以便根据驱动视频的运动使源图像中的对象动画。这篇论文的框架解决了这个问题,没有使用任何注释或关于动画特定对象的先验信息。一旦在一组描述同一类别对象的视频上进行训练,我们的方法就可以应用于该类中的任何对象。为了实现这一点,使用一个自监督的公式。为了支持复杂的运动,使用一种由一组学习过的关键点及其局部仿射变换组成的表示法。生成器网络对目标运动中产生的遮挡进行建模,并将从源图像中提取的外观与从驱动视频中提取的运动相结合。最终得到输出结果。
图像动画是指通过将从源图像中提取的外观与从驱动视频中提取的运动模式结合起来,自动合成视频的任务。
在文献中,大多数方法通过对对象表示,假设强先验并借助于计算机图形技术来解决这个问题。这些方法可以被称为特定对象的方法,因为它们假定了解要动画的特定对象的模型。
生成对抗网络(GANs)和变分自动编码器(VAEs)已被用于在视频中人类受试者之间转移面部表情[37]或运动模式[3]。然而,这些方法通常依靠预先训练好的模型来提取特定对象的表示,如关键点位置。不幸的是,这些预先训练过的模型是使用昂贵的ground-truth数据注释来构建的[2,27,31],通常不能用于任意对象类别。为了解决这个问题,最近Siarohin等人[28]推出了Monkey-Net,这是第一个面向对象的图像动画深度模型。Monkey-Net编码运动信息以一个自我监督的方式通过关键点学习。 在测试时,根据在驱动视频中估计的相应关键点轨迹对源图像进行动画处理。 Monkey-Net的主要弱点是,在假定为零阶模型的情况下,它很难对关键点邻域中的对象外观变换进行建模(如3.1节所示)。这导致在大物体姿态变化的情况下生成质量较差(见图4)。

为了解决这个问题,
-
- 我们提出使用一组自学习的关键点和局部仿射变换来建模复杂的运动。因此我们称我们的方法为一阶运动模型 [first-order motion model.]。
- 其次,我们介绍了一个遮挡感知生成器,它采用一个自动估计的遮挡掩模来指示目标部分,在源图像中不可见的,需要从上下文推断。这是特别需要的时候,驾驶视频包含大的运动模式和遮挡是典型的。
- 第三,我们扩展了关键点检测器训练中常用的等方差损失[18,44],以改进局部仿射变换的估计。
- 第四,我们的实验表明,我们的方法明显优于最先进的图像动画方法,可以处理高分辨率数据集,其他方法通常失败。
最后,我们发布了一个新的高分辨率数据集——Thai-Chi-HD,我们相信它可以成为评估图像动画和视频生成框架的参考基准。
Related work
视频生成。在深度视频生成方面的早期工作讨论了时空神经网络如何从噪声向量渲染视频帧[36,26]。最近,一些方法解决了条件视频生成的问题。例如,Wang et al.[38]结合递归神经网络和VAE来生成人脸视频。考虑到更广泛的应用,Tulyakov等人[34]引入了MoCoGAN,一种经过反训练的周期性建筑,用于从噪声、分类标签或静态图像合成视频。条件生成的另一个典型情况是未来帧预测问题,生成的视频以初始帧为条件[12,23,30,35,44]。注意,在这个任务中,可以通过简单地扭曲初始视频帧来获得现实的预测[1,12,35]。我们的方法与之前的工作密切相关,因为我们使用扭曲公式来生成视频序列。然而,在图像动画的情况下,应用的空间变形不是预测,而是由驱动视频给出。
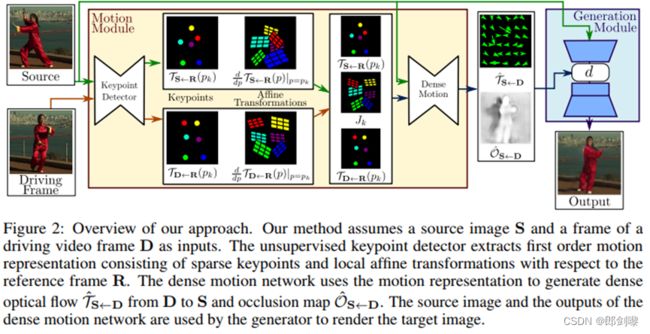
我们的方法概述。 我们的方法假设一个源图像 S 和一个帧驱动视频帧 D 作为输入。 无监督关键点检测器提取一阶运动
由稀疏关键点和局部仿射变换组成的表示参考帧R。
密集运动网络使用运动表示来生成密集的从 D 到 S 的光流 T^S D 和遮挡图 O^S D.
源图像和生成器使用密集运动网络来渲染目标图像。
图像动画。传统的图像动画和视频重定向方法[6,33,13]是为特定领域设计的,如人脸[45,42],人体轮廓[8,37,27]或手势[31],并要求动画对象的强大先验。例如,在人脸动画中,Zollhofer等人[45]的方法以依赖人脸的3D morphable模型为代价,产生了逼真的结果。然而,在许多应用中,这样的模型是不可用的。图像动画也可以看作是一个从一个视觉领域到另一个视觉领域的转换问题。例如,Wang等人[37]使用Isola等人的图像到图像的翻译框架来传输人体运动。[16]。同样,Bansal等人[3]通过合并时空线索扩展了条件GANs,以改善两个给定域之间的视频平移。为了使一个人动起来,这种方法需要数小时的带有语义信息的视频,因此必须为每个人重新训练。与这些作品相比,我们既不依赖于标签,也不依赖于动画对象的先验信息,也不依赖于每个对象实例的特定训练程序。此外,我们的方法可以应用于同一类别中的任何对象。,人脸,人体,机器人手臂等)。
提出了几种不需要关于对象的先验的方法。X2Face[40]使用密集运动场,通过图像翘曲生成输出视频。与我们相似的是,它们使用一个参考姿态来获得对象的规范表示。在我们的公式中,我们不需要一个明确的参考姿态,导致显著简化优化和改善图像质量。Siarohin等人[28]介绍了Monkey-Net,这是一个自监督框架,通过使用稀疏的关键点轨迹来创建任意对象的动画。在这项工作中,我们也使用稀疏轨迹由自监督关键点。然而,我们通过局部仿射变换在每个预测关键点的邻域内建模物体的运动。此外,为了向生成网络表明扭曲源图像可以生成的图像区域和需要绘制的遮挡区域,我们对遮挡进行了显式建模。
3 Method
我们感兴趣的动画对象描述了源图像的基于相似的对象的运动以来驱动视频d直接监督不可用(对视频对象移动类似),我们遵循从Monkey-Net启发的self-supervised策略。为了进行训练,我们使用了大量的视频序列集合,其中包含了同一对象类别的对象。我们的模型被训练来重建训练视频结合一个单一的帧和一个学习的潜在的表示运动视频。通过观察从同一视频中提取的帧对,它学会了将运动编码为特定运动关键点位移和局部仿射变换的组合。在测试时,我们将模型应用于由源图像和驱动视频的每一帧组成的对,并执行源对象的图像动画。
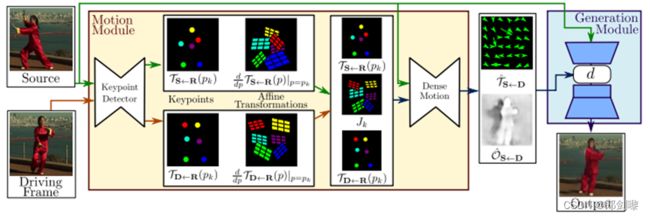 图2
图2
我们的方法的概述如图2所示。我们的框架由两个主要模块组成:运动估计模块和图像生成模块。
- 运动估计模块的目的是预测从驱动视频D的维数H×W的帧D∈R 3×H×W到源帧S∈R 3×H×W的密集运动场。密集的运动领域后用于对齐对象构成的特征图谱计算从S D运动领域建模函数TS←D: R^2→R^2映射每个像素位置与相应的位置TS←D通常被称为反向光流。由于使用双线性采样[17]可以以可微的方式有效地实现反向翘曲,因此我们采用了反向光流而不是前向光流。我们假设存在一个抽象参考系R,我们独立估计两个转换:从R到S (TS←R)和从R到D (TD←R)。注意,与X2Face[40]不同的是,参考框架是一个抽象概念,在后面的派生中会被抵消。因此,它从不被显式地计算,也不能被可视化。这种选择允许我们独立处理D和S,这是我们所希望的,因为在测试时,模型接收来自不同视频的源图像和驱动帧,它们在视觉上可能非常不同。动作估计器模块不直接预测TD←R和TS←R,而是分两步进行。
- 在第一步中,我们从稀疏轨迹集近似两个转换,通过使用自监督方式学习的关键点获得。通过编解码器网络分别预测D和S中关键点的位置。关键点表示是实现紧凑运动表示的瓶颈。如Siarohin等人[28]所示,这种稀疏运动表示非常适合于动画,因为在测试时,可以使用驱动频中的关键点轨迹移动源图像的关键点。我们使用局部仿射变换在每个关键点的邻域建模运动。与只使用关键点位移相比,局部仿射变换允许我们建模一个更大的变换家族。我们用泰勒展开通过一组关键点位置和仿射变换来表示TD←R。为此,关键点检测器网络输出关键点位置以及每个仿射变换的参数。
- 在第二步中,密集的运动网络结合了本地近似获得由此产生的密集运动领域TˆS←D。此外,除了密集的运动领域,这个网络输出一个遮罩贴图OˆS←D, D表明图像部分可以重建源图像的扭曲和哪些部分应该根据上下文填补。
- 最后,生成模块呈现源对象移动的图像,如驱动视频中提供的那样。在这里,我们使用一个生成网络(generator network)G根据TˆS←D扭曲源图像和填补图像部分被遮挡在源图像。在下面的部分中,我们将详细介绍这些步骤和培训过程。
3.1 Local Affine Transformations for Approximate Motion Description 局部仿射变换近似运动描述
运动估计模块估计从驱动帧D到源帧s的反向光流TS←D。如上所述,我们通过其一阶泰勒展开在关键点位置的邻域来近似TS←D。在本节的其余部分中,我们将描述此选择背后的动机,并详细介绍提出的TS←D近似。
我们假设存在一个抽象的参考系R,因此,估算TS←D包含在估算TS←R和TR←D中。此外,给定一个坐标系X,我们估计每个变换TX←R在已学习关键点附近。正式地,给定一个变换TX←R,我们考虑它在K个关键点p1,…pK,这里是p1…pK表示的参考系R中的关键点的坐标 .请注意,为了简单起见在参考点位置都是用p点表示,位置在X,S或D构成空间是用z表示。我们得到:
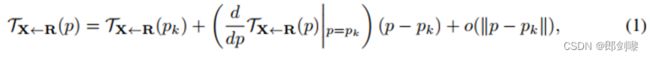 在这个公式中,运动函数 TX<-R 由它在每个关键点 pk 中的值表示,并且
在这个公式中,运动函数 TX<-R 由它在每个关键点 pk 中的值表示,并且
在每个 pk 位置计算其雅可比行列式:
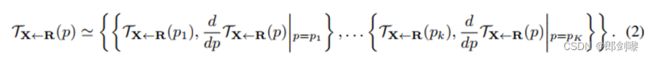
此外,为了估计 ![]() ,我们假设 TX <-R 在每个关键点的邻域。我们需要估计 D 中关键点 zk 附近的 TS<-D,因为zk 是对应于R 中关键点位置 pk 的像素位置。为此,我们首先估计驱动坐标系 D中点 zk 附近的变换 TR<-D。然后我们估计参考 R 中 pk 附近的变换 TS<-R。最后得到 TS<-D 如下:
,我们假设 TX <-R 在每个关键点的邻域。我们需要估计 D 中关键点 zk 附近的 TS<-D,因为zk 是对应于R 中关键点位置 pk 的像素位置。为此,我们首先估计驱动坐标系 D中点 zk 附近的变换 TR<-D。然后我们估计参考 R 中 pk 附近的变换 TS<-R。最后得到 TS<-D 如下:
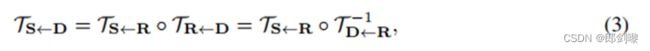
在再次计算方程式的一阶泰勒展开之后。我们得到:
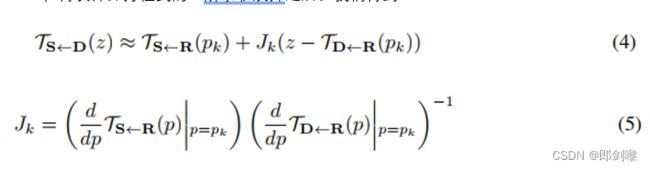 在实践中,公式中的 TS<-R(pk) 和 TD<-R(pk)。 (4) 由关键点预测器预测。 更多的
在实践中,公式中的 TS<-R(pk) 和 TD<-R(pk)。 (4) 由关键点预测器预测。 更多的
准确地说,我们采用标准的 U-Net 架构来估计 K 个热图,每个热图一个关键。 解码器的最后一层使用 softmax 激活来预测热图,被解释为关键点检测置信度图。 估计每个预期的关键点位置
使用 [29, 25] 中的平均操作。 注意如果我们设置 Jk = 1(1 是 2 × 2 单位矩阵),我们
得到 Monkey-Net 的运动模型。 因此 Monkey-Net 使用零阶近似TS D(z) - z。
对于帧 S 和 D,关键点预测器网络还输出四个附加通道每个关键点。 从这些通道中,我们得到矩阵 和
和![]() 在等式。 (5) 通过使用相应的关键点置信图作为权重计算空间加权平均值。
在等式。 (5) 通过使用相应的关键点置信图作为权重计算空间加权平均值。
3.2 Occlusion-aware Image Generation 遮挡感知图像生成
Sec.3提到过,源图像不是pixel-to-pixel与图像生成Dˆ。为了处理这种错位,我们使用了类似于[29,28,15]的特征扭曲策略。更准确地说,经过两个下采样卷积块,我们获得一个特性映射![]() 的维度。然后根据TˆS←D扭曲ξ。在 S 中存在遮挡的情况下,光流可能不足以生成 D^ 。实际上,S中被遮挡的部分是无法通过图像扭曲恢复的,因此应该进行补绘。因此,我们引入一个掩码映射(occlusion map)。以屏蔽应修复的特征图区域。因此,遮挡掩模减少了与遮挡部分相对应的特征的影响。转换后的feature map为:
的维度。然后根据TˆS←D扭曲ξ。在 S 中存在遮挡的情况下,光流可能不足以生成 D^ 。实际上,S中被遮挡的部分是无法通过图像扭曲恢复的,因此应该进行补绘。因此,我们引入一个掩码映射(occlusion map)。以屏蔽应修复的特征图区域。因此,遮挡掩模减少了与遮挡部分相对应的特征的影响。转换后的feature map为:

其中 fw(·;·) 表示反向翘曲操作,表示 Hadamard 乘积。 我们估计来自我们稀疏关键点表示的遮挡掩码,通过将通道添加到最后一层密集运动网络。 最后,将变换后的特征图 ξ0 馈送到后续网络生成模块的层(参见 Sup. Mat.)来渲染所寻找的图像。
3.3 Training Losses
我们以端到端的方式训练我们的系统,结合了一些损失。首先,我们使用基于Johnson等人[19]的感知损失的重建损失,使用预训练的vgg -19网络作为我们的主要驱动损失。损失是基于Wang等人[37]的实施。与输入驱动框架和相应的重构帧Dˆ,重建损失是写成: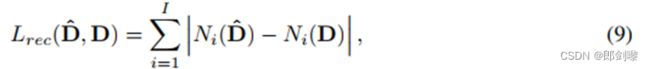
实施(等方差)Equivariance约束。关键点预测器在训练期间不需要任何关键点注释。这可能会导致不稳定的性能。等方差约束是驱动无监督关键点发现的最重要因素之一[18,43]。它迫使模型对已知的几何变换预测一致的关键点。我们使用薄板样条插值(Thin Plate Spline
),因为它们以前在无监督关键点检测中使用[18,43],并且类似于自然图像变形。由于我们的运动估计器不仅可以预测关键点,而且可以预测雅可比矩阵,因此我们扩展了众所周知的等方差损失,增加了对雅可比矩阵的约束。
我们假设图像X经历了已知的空间变形TX←Y。在这种情况下,TX←Y可以是仿射变换或薄板样条插值。在此变形之后,我们得到了一个新的图像y。现在通过对这两幅图像应用我们的扩展运动估计器,我们得到了一组TX←R和TY←R的局部逼近。标准等方差约束为:

在计算两边的一阶泰勒展开后,我们得到以下约束
(参见 Sup. Mat. 中的推导细节):

注意,约束Eq.(11)与关键点的标准等方差约束严格相同[18,43]。在训练过程中,我们在Eq.(11)的两边使用一个简单的L1损失来约束每个关键点的定位。但是,用L1来实现Eq.(12)中的第二个约束会使雅可比矩阵的大小为零,会导致数值问题。为此目的,我们使用公式13重新表述这一约束:
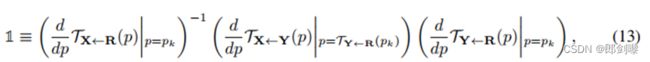
3.4 Testing Stage: Relative Motion Transfer 测试阶段:相对运动转移
在这个阶段,我们的目标是动画的对象在源帧S1使用驱动视频D1,…DT。我们将D1和Dt之间的相对运动转移到S1,而不是将TS1←Dt (pk)中编码的运动转移到S中。换句话说,我们对每个关键点pk的邻域应用变换TDt←D1 (p):
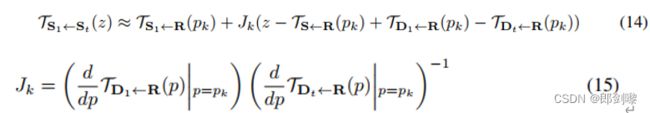
直观上,我们根据driving video中每个关键点pk的局部变形,对S1中每个关键点pk的邻域进行变换。实际上,在绝对坐标上传输相对运动只允许传输相关的运动模式,同时保留全局物体的几何形状。相反,在传输绝对坐标时,如在X2Face[40]中,生成的帧继承驱动视频的对象比例。需要注意的是,传递相对运动的一个限制是,我们需要假设S1和D1中的物体具有相似的姿态(见[28])。在没有初始粗对准的情况下,Eq.(14)可能导致对象在物理上无法得到绝对的关键点位置。
4 Experiments
数据集。我们在包含不同对象的四个不同数据集上训练和测试我们的方法。在我们所有的实验中,我们的模型能够呈现比[28]分辨率高得多的视频。
VoxCeleb数据集
BAIR机器人推送数据集
The UvA-Nemo 数据集
taichi -HD数据集我们从YouTube上收集了280个太极视频。我们使用252个视频进行培训,28个视频进行测试。每个视频被分割成简短的片段,正如在VoxCeleb数据集预处理中描述的那样。我们只保留高质量的视频,并将所有剪辑调整为256×256像素(而不是[34]中的64×64像素)。最后,我们分别得到3049和285个视频块进行训练和测试,视频长度在128到1024帧之间。这个数据集被称为taichi - HD数据集。数据集将向公众开放。
评估方案。评价图像动画的质量并不明显,因为地面真实动画是不可用的。我们遵循猴网[28]的评估协议。首先,我们对视频重建的“代理”任务进行了定量评估。这个任务包括从外观和运动解耦的再现中重构输入视频。在我们的例子中,我们结合每一帧的稀疏运动表示和第一帧视频来重建输入视频。其次,我们根据用户研究评估我们的图像动画模型。在所有的实验中,我们使用K=10作为[28]。其他实现细节见 Sup. Mat.
指标。为了评估视频重构,我们采用Monkey-Net[28]中提出的度量:
- L1。我们报告了生成的视频和地面真实视频之间的平均L1距离。
- 平均关键点距离(AKD)。对于Tai-Chi-HD、VoxCeleb和Nemo数据集,我们使用第三方预训练的关键点检测器来评估输入视频的运动是否被保留。对于VoxCeleb和Nemo数据集,我们使用Bulat等人的面部地标检测器。[5]。对于taichi - hd数据集,我们采用了Cao等人[7]的人体姿态估计器。对于每一帧,这些关键点都是独立计算的。AKD是通过计算ground truth检测关键点与生成视频之间的平均距离得到的。
- 缺少关键点率(MKR)。在Tai-Chi-HD的情况下,人体姿态估计器为每个关键点返回一个额外的二进制标签,以指示是否成功地检测到关键点。因此,我们还报告MKR定义为在ground truth框架中检测到但在生成的框架中未检测到的关键点的百分比。这个度量评估每个生成帧的外观质量。
- 平均欧氏距离(AED)。考虑到外部训练的图像表示,我们报告了ground truth和生成的帧表示之间的平均欧氏距离,类似于Esser等人[11]。我们使用了在猴网[28]中使用的特征嵌入。
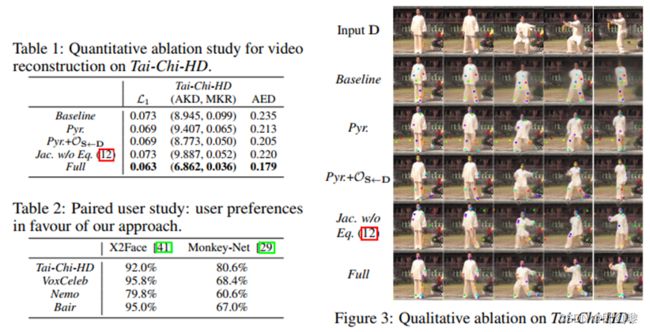
消融实验(Ablatoin Study)。我们比较模型的以下变体。
基线(Baseline):不使用遮挡模板训练的最简单模型, Eq.(4)中雅可比矩阵(Jk =1),并且仅在最高分辨率下使用Lrec进行监督;
Pyr:金字塔损失添加到Baseline;
Pyr +OS←D:对于Pyr,我们将生成器网络替换为遮挡感知网络;。
![]() Eq.(12)我们的局部仿射变换模型,但对雅可比矩阵没有等方差约束完整:包括3.1节中描述的局部仿射变换的
Eq.(12)我们的局部仿射变换模型,但对雅可比矩阵没有等方差约束完整:包括3.1节中描述的局部仿射变换的
完整(FULL):完整模型,包括局部仿射变换。
在图3中,我们报告了定性消融。首先,根据除AKD之外的所有指标,金字塔损失导致更好的结果。其次,在模型中添加OS←D可以持续地改进关于Pyr的所有度量。这说明了明确建模遮挡的好处。我们发现,如果雅可比矩阵上没有等方差约束,Jk将变得不稳定,从而导致较差的运动估计。
最后,我们的完整模型进一步改进了所有的度量。特别地,我们注意到,相对于基线模型,完整模型的MKR要小2.75倍。这表明,我们丰富的运动表示有助于生成更真实的图像。我们在表1中对基线和完整模型进行了定性评价,验证了这些结果。在这些实验中,输入视频的每一帧D都从第一帧(第一列)和估计的关键点轨迹重建。我们注意到基线模型没有在武器区域定位任何关键点。因此,当与初始位姿的位姿差增大时,模型无法重构视频(第3、4、5列),而全模型学习检测每只手臂上的一个关键点,从而在复杂运动的情况下更准确地重构输入视频。
与现有水平的比较(Comparison with State of the Art.)。我们现在比较我们的方法与先进的视频重建任务在[28]。就我们所知,X2Face[40]和Monkey-Net[28]是之前唯一的无模型图像动画方法。定量结果在Tab中报告。3.我们观察到,我们的方法始终如一地改善了四个不同数据集的每一个指标。即使在VoxCeleb和Nemo这两个人脸数据集上,我们的方法也明显优于最初为人脸生成而提出的X2Face。与X2Face相比,我们的方法的更好性能尤其令人印象深刻。X2Face利用了更大的运动嵌入(128个浮点数),而我们的方法(60=K*(2+4)浮点数)。与使用类似维数(50=K*(2+3))的运动表示的猴网相比,我们的方法在包含高度非刚性对象(如人体)的Tai-Chi-HD数据集上的优势是显而易见的。
 我们现在报告一个图像动画的定性比较。生成的序列如图4所示。结果与表3的定量评价很一致。实际上,在这两个例子中,X2Face和Monkey-Net都无法在驱动视频中正确传输身体概念,而是将源图像中的人体扭曲成一个blob。相反,我们的方法能够产生明显更好的视频,其中身体的每个部分都是独立的动画。这种定性评价说明了我们丰富的运动描述的潜力。我们通过用户研究来完成我们的评估。我们要求用户选择最真实的图像动画。每个问题由源图像,驱动视频,以及相应的结果,我们的方法和竞争方法。我们要求每个问题由10个AMT工人回答。这个评估在50个不同的输入对上重复。结果如表2所示。我们观察到我们的方法明显优于竞争对手的方法。有趣的是,与目前最先进的最大差异是在Tai-Chi-HD上获得的:由于其丰富的运动,在我们的评估中最具挑战性的数据集。
我们现在报告一个图像动画的定性比较。生成的序列如图4所示。结果与表3的定量评价很一致。实际上,在这两个例子中,X2Face和Monkey-Net都无法在驱动视频中正确传输身体概念,而是将源图像中的人体扭曲成一个blob。相反,我们的方法能够产生明显更好的视频,其中身体的每个部分都是独立的动画。这种定性评价说明了我们丰富的运动描述的潜力。我们通过用户研究来完成我们的评估。我们要求用户选择最真实的图像动画。每个问题由源图像,驱动视频,以及相应的结果,我们的方法和竞争方法。我们要求每个问题由10个AMT工人回答。这个评估在50个不同的输入对上重复。结果如表2所示。我们观察到我们的方法明显优于竞争对手的方法。有趣的是,与目前最先进的最大差异是在Tai-Chi-HD上获得的:由于其丰富的运动,在我们的评估中最具挑战性的数据集。
5 Conclusions
本文提出了一种基于关键点和局部仿射变换的图像动画方法。我们的新的数学公式描述了两个帧之间的运动场,并通过推导一阶泰勒展开近似来有效地计算。这样,运动被描述为一组关键点位移和局部仿射变换。生成网络将源图像的外观和驱动视频的运动表示结合起来。此外,我们建议显式地建立遮挡模型,以便向生成器网络指示哪些图像部分需要修复。我们对所提出的方法进行了定量和定性的评估,并表明我们的方法在所有基准测试中都明显优于现有的技术水平。