三、机器学习基础知识:Python常用机器学习库(Pandas)
文章目录
- 1、Pandas
- 2、Series数据结构
-
- 2.1 Series的创建
- 2.2 Series的索引与访问
- 2.3 Series的常见操作
- 3、DataFrame对象
-
- 3.1 DataFrame的创建与索引
- 3.2 DataFrame的访问
- 3.3 DataFrame的常见操作
- 4、数据对齐
- 5、缺失数据处理
- 6、Pandas存取文件
1、Pandas
Pandas 库是以Numpy库为基础构建的,通常用来处理表格型(关系型)的数据集或与时间序列相关的数据集。
Pandas的优点总结如下:
- Pandas提供了快速高效的DataFrame对象,可用于集成索引的数据集操作。
- Pandas提供了对各种格式数据的读取和写入工具。
- 提供智能的数据对齐功能和缺失数据处理方式,可以方便地将混乱的数据处理成有序的形式。
- 可以很灵活地进行数据集的维度变换和旋转。
- 基于DataFrame对象的标签,可以对数据集进行灵活的切片、花式索引,或将大数据集分拆为多个小子集。
- 当需要修改数据尺度时,允许对数据对象中的数据列进行添加和删除操作。
- 提供了强大的分组引擎,可以对分组数据集进行拆分、应用、组合等操作,也可以方便地对数据集进行汇总统计和转换。
- 提供了对多个数据集进行高效合并和连接的方法。
- 分层轴索引提供了在低维数据结构中处理高维数据的直观方式。
- 提供了方便的时间序列操作功能。
- Pandas经过了高度的性能优化,执行效率高。
- 应用领域广泛。
一般使用如下方式引入Pandas库:
import pandas as pd
Pandas有两种主要的数据结构:
- Series:一维数组,与Numpy中一维的ndarray相似,数据结构接近Python中的List列表,数据元素可以是不同的数据类型。
- DataFrame:二维数据结构,可以近似将其看成由多个Series组成。
2、Series数据结构
Series是一种类似于一维数组的对象,它由一组数据以及与其对应的标签(索引)组成,数据可以是任何Numpy数据类型。
2.1 Series的创建
创建Series对象的语法格式如下:
pandas.Series(data,index)
data表示数据值,index为对应的索引,可以自定义索引,若未自定义,则自动创建0~N-1的整数型索引(N为数据长度)
Series的创建:
import pandas as pd
s1 = pd.Series([1,2,3,4,5]) #使用默认整数索引创建Series
ls = ['a','b','c','d','e']
s2 = pd.Series([1,2,3,4,5],index=ls) #使用自定义索引创建Series
print(s1)
print(s2)

2.2 Series的索引与访问
若创建Series的过程中自定义了索引,那么访问数据时可以通过自定义索引或整数索引进行访问。若采用整数索引对Series进行切片访问,则切片片区不包含最右侧索引;若采用自定义索引切片,则包含最右侧索引。
Series的索引访问:
ls = ['a','b','c','d','e']
s2 = pd.Series([1,2,3,4,5],index=ls) #使用自定义索引创建Series
print(s2[0:2]) #使用整数索引切片访问Series
print(s2['a':'c']) #使用自定义索引切片访问Series

2.3 Series的常见操作
创建Series后,可以对其进行常见数组操作,包括标量乘法、数据过滤、应用数学函数等。
import numpy as np
ls = ['a','b','c','d','e']
s2 = pd.Series([1,2,3,4,5],index=ls) #使用自定义索引创建Series
print(s2)
print(s2**2) #使用标量乘法计算平方
print(s2[s2>3]) #筛选大于3的元素
print(np.sqrt(s2)) #应用数学函数开方

而针对Series内的元素,可以对其进行数据值的新增、修改和删除。
ls = ['a','b','c','d','e']
s2 = pd.Series([1,2,3,4,5],index=ls) #使用自定义索引创建Series
print("原始Series为:\n",s2)
s2['f']=8
print("添加元素后的Series为:\n",s2)
s2['a']=9
print("修改元素后的Series为:\n",s2)
s2 = s2.drop('c')
print("删除元素后的Series为:\n",s2)

此外还可以通过字典来创建Series对象,因为字典中的数据都是以键值对的形式存储,所以将其转换为Series时会使用其中的键部分作为索引,值部分作为数据值。与字典不同的是,字典中的条目是无序的,而Series中的数据是有序的。
dic = {'a':6,'b':7,'c':8,'d':9,'f':10}
s = pd.Series(dic)
print(s)

3、DataFrame对象
DataFrame是一个表格型的数据结构,由行和列组成,DataFrame的列是有序的,列与列之间的数据类型可以互不相同。DataFrame的每一行存在一个行索引(index),每一列存在一个列索引(columns)。
3.1 DataFrame的创建与索引
创建dataFrame对象的方法有很多,最常见的就是通过一个字典进行转换,使用的是DataFrame()函数。
dic = {'a':[1,2,3,4,5],'b':[6,7,8,9,10]}
df = pd.DataFrame(dic)
print(df)

在上述转换过程中,字典的键变成DataFrame的列索引,自动生成整数行索引。
此外还可以使用DataFrame()函数将二维数组转换成DataFrame。
l1 = [[1,2,3],[4,5,6],[7,8,9]]
df1 = pd.DataFrame(l1)
print(df1)

在上述过程中,由于没有自定义索引,因为行索引和列索引均自动生成整数索引。
对于dataFrame对象,还可以使用一些属性查看它的基本信息。
| 属性 | 信息 |
|---|---|
| df.shape | 查看DataFrame的形状 |
| df.index | 查看DataFrame的行索引 |
| df.columns | 查看DataFrame的列索引 |
| df.values | 以ndarray对象类型返回DataFrame的所有数据 |
| df.info | 查看DataFrame的摘要信息 |
dic = {'a':[1,2,3,4,5],'b':[6,7,8,9,10]}
df = pd.DataFrame(dic)
print(df)
print(df.shape) #查看DataFrame的形状
print(df.index) #查看DataFrame的行索引
print(df.columns) #查看DataFrame的列索引
print(df.values) #以ndarray对象类型返回DataFrame的所有数据
print(df.info) #查看DataFrame的摘要信息

DataFrame对象的索引是不支持修改的,但是允许用户使用set_index()将某列设置为新索引,也可以使用reindex()方法改变数据行的顺序,生成一个匹配新索引的新对象。
dic = {'a':['class1','class2','class3','class4','class5'],'b':[6,7,8,9,10]}
df = pd.DataFrame(dic)
print(df)
df = df.set_index(['a']) #以a列作为新索引创建一个新对象
print(df)
df = df.reindex(['class2','class3','class5','class1','class4']) #根据给定索引改变数据行顺序,创建一个新对象
print(df)

3.2 DataFrame的访问
如果想对DataFrame对象进行切片来获取部分数据,根据想要获取区域的不同,常用的数据选择方式为:选择行、选择列、选择区域、选择单个数据以及条件筛选。
选择行:
import pandas as pd
dic = {'class':['class1','class2','class3','class4','class5'],'num':[1,2,3,4,5]}
df = pd.DataFrame(dic,index=['a','b','c','d','e'])
print(df)
print('获取第一行数据\n',df[0:1])
print('获取第1、2行数据\n',df[1:3])
print('获取行标签为a、b、c的数据\n',df['a':'c'])
print('获取前三行数据\n',df.head(3))
print('获取最后一行数据\n',df.tail(1))

选择列:
print('获取列标签为class的数据\n',df['class'])

选择区域数据时可用到的方法有loc和iloc,其中loc基于行列索引标签进行选择,iloc基于行列位置关系进行切片。
| 使用方式 | 功能 |
|---|---|
| loc[i] | 选取行索引为i的行 |
| loc[i1:i2] | 选取行索引从i1到i2的行,包括i2 |
| loc[i1:i2, c1:c2] | 选取行索引从i1到i2,列索引从c1到c2的矩形区域 |
| iloc[r] | 选取位置为第r行的数据,r为大于等于0的整数 |
| iloc[r1:r2] | 选取位置为第r1到r2行的数据,不包括r2行 |
| iloc[r1:r2, v1:v2] | 选取位置为第r1到r2行,第v1列到v2列的矩形区域,不包括v2列 |
选择区域:
print('选取行索引为a的行:\n',df.loc['a'])
print('选取行索引从a到c的行:\n',df.loc['a':'c'])
print('选取行索引从a到c,列索引从class到num的矩形区域:\n',df.loc['a':'c','class':'num'])
print('选取位置为第1行的数据:\n',df.iloc[1])
print('选取位置为第1行到第3行的数据,不包括第2行:\n',df.iloc[1:3])
print('选取位置为第1行到第3行,第0列到第1列的区域,不包括第2行、第1列:\n',df.iloc[1:3,0:1])

选择单个数据的方法有at和iat,其中at基于索引进行选择,iat基于位置信息进行选择。
| 使用方式 | 功能 |
|---|---|
| at[i,c] | 选择行索引为i,列索引为c的单个数据 |
| iat[r,v] | 选择第r行、第v列的单个数据,r和v从0开始 |
选择单个数据:
print('选择行索引为a,列索引为num的单个数据:\n',df.at['a','num'])
print('选择第1行第1列的单个数据:\n',df.iat[1,1])

条件筛选:
import numpy as np
data=pd.DataFrame(np.arange(16).reshape(4,4),
index=['BJ','SH','GZ','SZ'],
columns=['q','r','s','t'])
print(data)
print(data[data['r']>6]) #筛选出列索引为r的取值中大于6的行

3.3 DataFrame的常见操作
可以通过赋值语句来修改DataFrame中的数据,修改过程中需指定修改的行、列索引。此外在使用赋值语句赋值时,若该列索引名不存在,即为添加新列。
dic = {'class':['class1','class2','class3','class4','class5'],'num':[1,2,3,4,5]}
df = pd.DataFrame(dic,index=['a','b','c','d','e'])
print('当前DataFrame结构为:\n',df)
df['num']['a']=7
print('修改后的DataFrame结构为:\n',df)
df['age']=[1,4,7,9,0]
print('修改后的DataFrame结构为:\n',df)

有时候需要把几个DataFrame对象合并为一个DataFrame对象,此时可以使用append()方法和merge()方法。
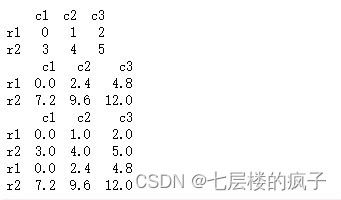
append()方法是将其他数据对象沿行索引方向(列对齐)追加到当前对象的末尾,并返回一个新对象。
df1 = pd.DataFrame(np.arange(6).reshape(2,3),index=['r1','r2'],columns=['c1','c2','c3'])
df2 = pd.DataFrame(np.linspace(0,12,6).reshape(2,3),index=['r1','r2'],columns=['c1','c2','c3'])
print(df1)
print(df2)
print(df1.append(df2))
merge()方法主要对多个DataFrame对象依据某些列的值进行匹配合并。
df1 = pd.DataFrame(np.arange(6).reshape(2,3),index=['r1','r2'],columns=['c1','c2','c3'])
df3 = pd.DataFrame(np.arange(6).reshape(2,3),index=['r1','r2'],columns=['c1','c4','c5'])
df4 = pd.merge(df1,df3,on='c1')
print(df1)
print(df3)
print(df4)

Pandas的Series对象和DataFrame对象都继承了Numpy的统计函数,拥有常用的数学与统计方法,可以对一列或多列数据进行统计分析,常见的统计分析函数如下:
| 函数 | 功能 |
|---|---|
| count() | 统计元素个数,不包含Nan值 |
| describe() | 按照列进行统计分析,获取数量、均值、最大值等相关信息 |
| min(),max() | 获取最大值、最小值 |
| argmin(),argmax() | 获取列最大值、最小值的索引位置信息 |
| idxmin(),idxmax() | 获取列最大值、最小值的索引值 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| var() | 计算方差 |
| std() | 计算标准差 |
| cumsum() | 计算累计和 |
df = df.drop(['class'],axis=1)
print('DataFrame结构为:\n',df)
print('每列的元素数量为:\n',df.count())
print('每列的统计分析值为:\n',df.describe())
print('每列的元素之和为:\n',df.sum())
print('每列的标准差为:\n',df.std())

drop()方法可以按照行列删除数据,其语法格式如下:
df.drop(索引值或索引列表,axis= , inplace = )
其中axis默认为0,表示删除行,取值为1时表示删除列;inplace表示操作是否对元数据生效,默认为false,产生新数据。
print('DataFrame结构为:\n',df)
df1 = df.drop('num',axis = 1) #删除列索引为num的列
print(df1)
df.drop('a',inplace = True) #对原数据进行删除操作,删除行索引为a的行
print(df)

4、数据对齐
Series和DataFrame还有一个重要的功能就是在进行算术运算时实现数据的自动对齐,对齐不同索引的数据,简单的解释就是数据依照索引进行匹配后再进行算术运算,如果索引不同,则获得这两个索引的并集。
Series的数据对齐:
dic1 = {'a':6,'b':7,'c':8,'d':9,'f':10}
dic2 = {'a':1,'b':1,'d':1}
s1 = pd.Series(dic1)
s2 = pd.Series(dic2)
print(s1+s2)

DataFrame的数据对齐:
dic1 = {'class':[1,2,3,4,5],'num':[1,2,3,4,5]}
df1 = pd.DataFrame(dic1,index=['a','b','c','d','e'])
print('第一个DataFrame结构为:\n',df1)
dic2 = {'class':[2,3,5]}
df2 = pd.DataFrame(dic2,index=['b','c','e'])
print('第二个DataFrame结构为:\n',df2)
df3 = df1+df2
print(df3)

5、缺失数据处理
在使用Series或DataFrame结构进行数据的存储时,最常见的就是在存储过程中出现数据缺失的情况,即出现空值。在pandas中针对这一现象可以依次采用判断空值、过滤缺失数据以及填充缺失数据来进行处理。
当不确定数据中是否存在空值时,可以使用notnull()方法进行判断,Series或DataFrame中对应位置不存在空值则返回True,否则返回False。
notnull()方法的使用:
df3.notnull()

但确定存在空值时,可以采用过滤缺失数据或填充的方式进行处理。
过滤缺失数据主要可以使用dropna()方法,该方法中主要包含两个参数,分别是axis和how。
axis可以取值为0或1,默认取值为0。当取值为0时表示对存在缺失值的行进行处理;当取值为1表示对存在缺失值的列进行处理。
how可以取值为any或all,默认取值为any。当取值为any时表示只要该行或该列存在空值,则删除该行或该列;当取值为all时表示只有当该行或该列全部为空值时才会删除。
dropna()方法的使用:
df4 = df3.dropna()
df5 = df3.dropna(how = 'all')
print('原始DataFrame结构为:\n',df3)
print('删除包含空值的行之后DataFrame结构为:\n',df4)
print('删除全部为空值的行之后DataFrame结构为:\n',df5)

填充数据主要可以使用filllna()方法,该方法默认填充后返回新的数据对象,常见参数如下:
| 参数 | 功能 |
|---|---|
| value | 用于填充缺失部分的数据 |
| method | 插值方法,默认是ffill,用上一个非缺失值填充,bfill表示用下一个非缺失值填充 |
| axis | 填充的轴向 |
| inplace | 是否修改原对象,默认为False |
| limit | 可以填充的数量 |
filllna()方法的使用:
print('原始DataFrame结构为:\n',df3)
df6 = df3.fillna(1)
print('将空值替换为1之后DataFrame结构为:\n',df6)
df7 = df3.fillna(method='bfill',limit=1)
print('用下一个缺失值填充且仅填充一个空值之后DataFrame结构为:\n',df7)

6、Pandas存取文件
Pandas提供了专门的文件输入输出函数,主要分为读取函数和写入函数两种。
| 读取函数 | 写入函数 | 功能 |
|---|---|---|
| read_csv() | to_csv() | 对CSV文件进行读写操作,默认以逗号分隔 |
| read_excel() | to_excel() | 对Excel文件进行读写 |
| read_sql() | to_sql() | 读写数据库表内容 |
| read_json() | to_json() | 读写JSON格式文件和字符串 |
| read_html() | to_html() | 读写HTML字符串、文件以及URL等 |
在上述函数中,最常用的是read_csv()和to_csv(),这两种主要可以对CSV和TXT文件进行读写操作。
to_csv()主要用于将数据写入CSV文件。其语法格式如下:
pd.to_csv(filename, sep='', columns=None, header=None)
其中filename为写入的文件名;sep为输出文件的字段分隔符,默认点;columns为写入的字段;header为列名的别名。
read_csv()主要读取CSV文件中的数据,其语法格式如下:
pd.read_csv(filename, sep='', columns=None, header=None, names='')
names表示设置的列名。
使用to_csv()与read_csv()读写文件:
df1 = pd.DataFrame(np.arange(6).reshape(2,3),index=['r1','r2'],columns=['c1','c2','c3'])
print(df1)
df1.to_csv('1.csv')
df2 = pd.read_csv('1.csv',header = None,names=['a','b','c'])
print(df2)
