【Linux】进程优先级|进程并发概念|在vim中批量化注释
文章目录
- 前言
- tips——如何在vim中批量化注释
- 进程更深度理解
- 一、什么是进程优先级
- 二、 为什么要有优先级
- 三、Linux怎么设置优先级
-
- 查看进程优先级的命令
- PRI and NI
- 用top命令更改已存在进程的nice:
- 如何根据优先级开展调度呢?
- 五、其他概念
-
- 并发(重点)
- 总结
前言
这篇文章继续上篇内容讲解进程的优先级。
tips——如何在vim中批量化注释
首先进入命令行模式
- 1.输入ctrl + v
- 2.然后选择H,J,K,L键进行左下上右移动(注意不能按上下左右的箭头)
- 3.选中注释区域后,按shift + I键进入插入模式
- 4.再输入两个反斜杠即可。
进程更深度理解
前面说过,进程 = 描述该进程的PCB结构体对象 + 数据和代码。
而一个PCB结构体对象(task_struct)其实就是进程所有属性的集合。
那么在进程的调度队列数据结构中,如何获取到进程的所有属性呢?
一般一个进程的task_struct结构体对象的大致结构如下:
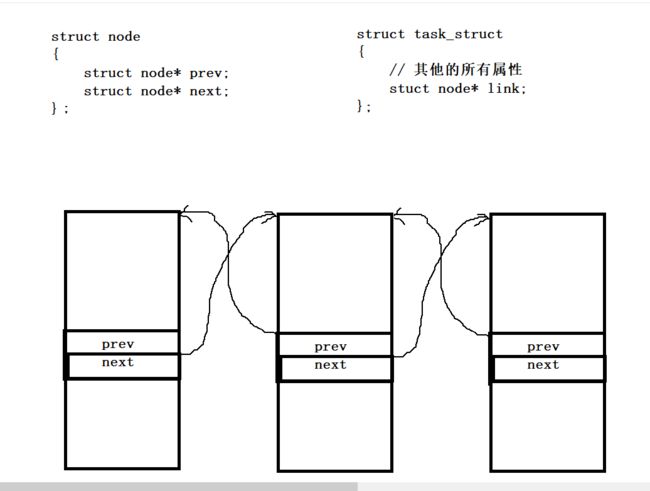
如何获取到_start的起始地址呢? 如何获取到其他的所有属性呢?
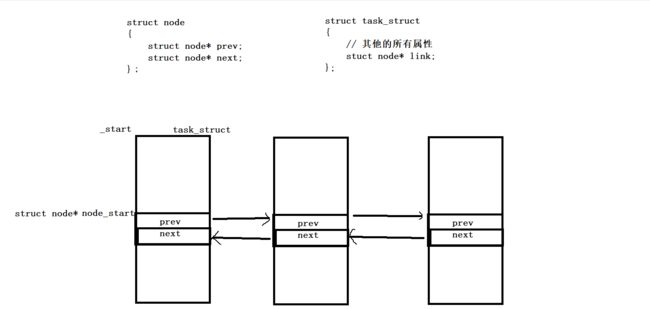
我们应该这样:
(task_struct * )(node_start - ( & ( (task_struct *)0->link ) ) )->other
应该这样解释:将0强转成task_struct*指针,即默认0地址处有一个task_struct结构体对象,通过该对象访问到link属性成员,然后再取它的地址,即link成员相对于该结构体起始位置的偏移量。
node_start是link这个位置的起始地址,相减后获得该结构体最起始地址处的地址,将该地址强转成结构体对象,即可访问所有其他属性成员。
所以,通过上面的方法能访问到进程调度队列中的每个数据结构的task_struct的其他所有属性后,在队列排队的每一个task_struct结构体对象就可以是不同类型的对象。
比如下图:
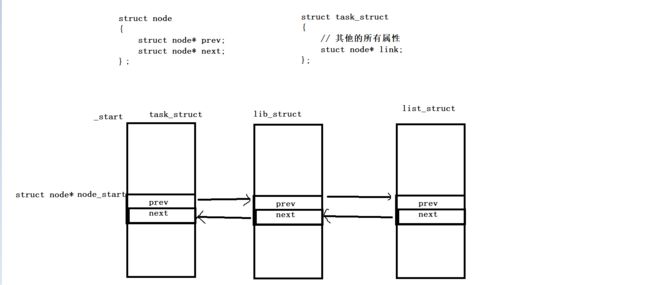
从此以后在调度队列中排队的PCB结构体就能做到不同类型的对象,因为只要知道该对象的类型就能访问所有其他属性,由此更加灵活实现,就允许更多进程可以被同一个调度队列调度!
由此还能引出另一个重大意义:
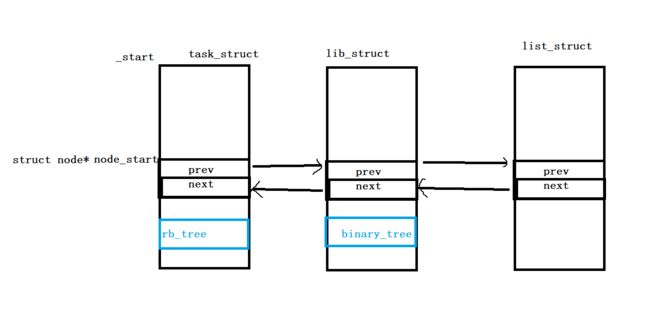
一个task_struct结构体对象不仅仅可以属于双向链表这个数据结构,还能属于其他数据结构比如二叉树,红黑树等等。
因为通过上面的方法可以访问任意属性成员,就能存储其他数据结构的地址,就能访问到其他数据结构了!
总结:一个task_struct 结构体对象既可以属于双向链表,也可以属于其他数据结构。
一、什么是进程优先级
优先级就是对于资源的访问,谁先谁后的问题!
二、 为什么要有优先级
我们知道,一台电脑的CPU一般只有一个,两个或以上是造价是非常昂贵的。
可是电脑上的进程却有很多个, 只有一个CPU,但是有多个进程,这就意味着进程之间
必然存在竞争CPU资源的关系!
也必然存在进程之间谁先执行,谁后执行的问题!
既然有了竞争关系,就必然要保证良性竞争。
此时就有了优先级的概念,其实就是确定一种谁先谁后访问CPU资源的关系。
所以进程之间就必须排队,排队就必须保证进程优先级。
最典型的例子就是学校的食堂排队打饭。
学校饭堂窗口就那么多个,但是学生有那么多,学生之间有男生有女生,有大个的有小个的,假如大家不按要求排队打饭,可能就是大个的男生能先挤上去,小个子的女生会打不到饭,或者如果存在不合理的排队问题时,导致大个子能吃到饭,小个子吃不到饭,那就会导致大个子的越吃越多,小个子的越吃越少,小个子就会越来越小,就会导致进程过长时间得不到CPU资源,就会引发进程的饥饿问题。
综上,必须存在进程优先级的概念,并且要保证良性的优先级!
三、Linux怎么设置优先级
查看进程优先级的命令
使用
ps -l
命令可以查看进程的优先级:

其中,PRI就是优先级(priority)
NI是nice值。
还有其他的进程信息如下:
UID : 代表执行者的身份
PID : 代表这个进程的代号
PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
PRI :代表这个进程可被执行的优先级,其值越小越早被执行
NI :代表这个进程的nice值
实际在OS识别进程时,并不是按照进程的名字进行识别,而是按照进程的PID编号进行识别的。
PRI and NI
进程确认优先级规则如下:
PRI的值越小,该进程越早被执行。
PRI和NI的关系如下:
PRI(new) = PRI(old) + NI
所以NI可以取负数,NI越小,PRI就越小,该进程就越早被执行。
一般情况下,NI的取值范围是:-20~19,共四十个级别
按照这样的情况,我们可以更改进程优先级的!
但是,对操作系统来说,调度器才是最公平的优先级队列调度者,它才能保证最公平的进程调度。
所以,操作系统不希望我们过多地参与进程优先级的修改。
所以这就是为什么NI值有一个范围是[-20,19]的原因!
由于进程的初始PRI是80,Ni值取值范围是-20~19,所以PRI的取值范围就是[60,99]!
用top命令更改已存在进程的nice:
当运行起来一个进程的时候,可以看到myproc这个进程的默认PRI是80。

输入top,进入监控进程。
然后输入r,就会弹出一个PID to renice的提醒。

里面显示默认的pid是1,这里我们要修改的进程的pid是16439,输入16439后进行回车。

上面就提示我们需要将nice值改成多少。
当我输入-30后,就弹出一个:
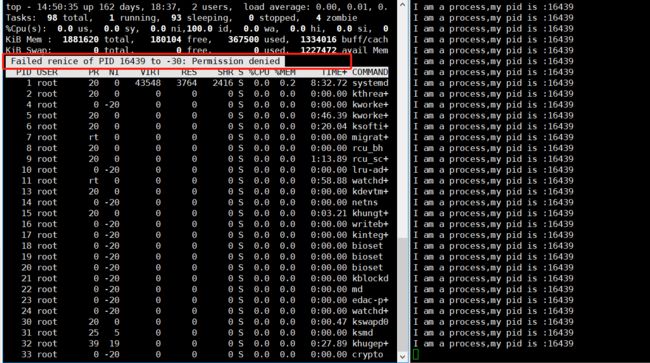
Permission deny,就是权限不允许的意思。
这意味着普通用户是无法更改nice值的。
下面切换到root用户,
当我再次输入15时,它成功了,我们验证一下:

此时我再将nice值设置成-20试试。

这里有一个问题,NI值是没错,可是上一次的PRI值不是95吗,设置更改了NI值为-20后应该是75,为什么这里变成60了呢?
原因很简单,
PRI(new) = PRI(old) + NI
这条公式中PRI(old)每次更改nice值的时候都是默认从80开始的。
如何根据优先级开展调度呢?
我们知道一个CPU维护一个运行队列(runqueue)。
该运行队列的结构体大致如下:
struct runqueue
{
task struct* running[140];
task struct* waiting[140];
};
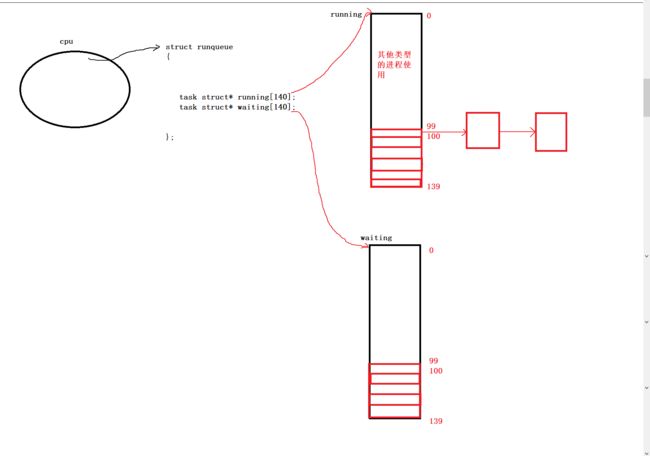
在运行队列中有两个哈希表指针,来映射进程的位置。
一般来说,0~99号位置我们是不能用的,这些位置都是给操作系统的其他进程进行调度的。
从100~139号位置开始,一共40个位置,对应这进程的PRI有40个优先级,是我们可以使用的。
调度原理:
当有一个进程进来时,根据进程的PRI来对哈希表中不同节点的位置进行映射,再讲该进程链接到该位置之后即可。
如果有新的进程进来,且该进程的优先级与上一个进程的优先级相同的话,就会链接到上一个进程之后。
如果新的进程的优先级与其他进进程的优先级不同,最终也会映射到相应位置,然后链接起来。
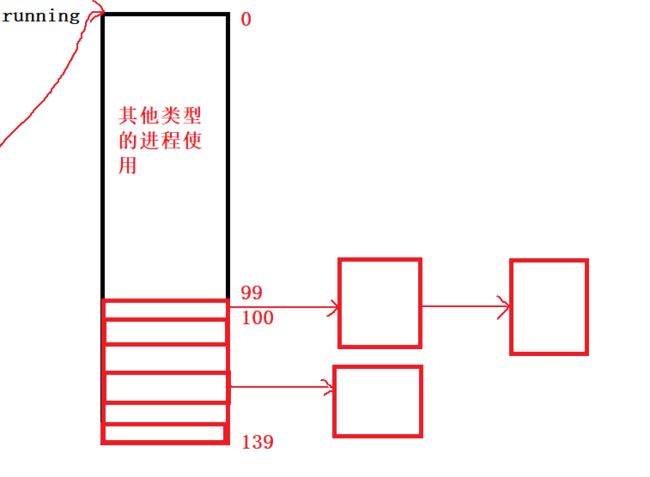
当进程数量达到一定值时,操作系统就会对该调度该哈希表,进行遍历,从上往下,从左到右一个个运行上面的进程。
这样就实现了进程优先级调度队列!
假如在操作系统调度上面的running的进程时,又有一些新的进程进来,怎么让这些进程能够进去排队呢?
Linux是这样处理的:
给running哈希表再设置一个镜像表(waiting)!
在操作系统调度running内的进程时,当有其他进程过来,这些进程就会被连接到waiting哈希表中,然后再设置两个哈希表指针,当上一个running哈希表内的进程完成调度时,只需要交换这两个指针,就可以继续调度其他的进程了。
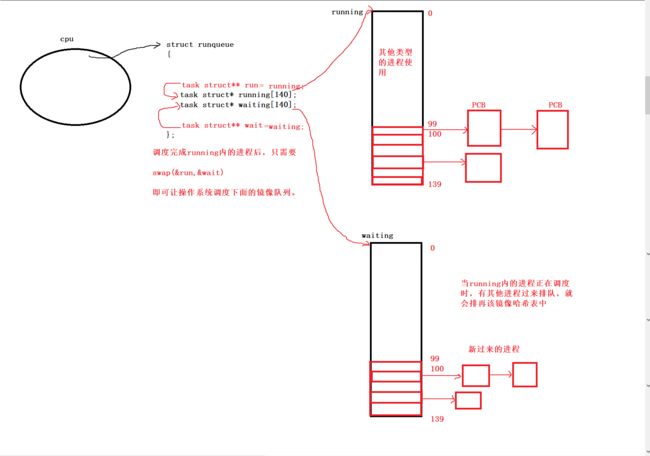
但是这里仍然存在一个可以改进效率的问题。
操作系统在调度running哈希表中的进程时,需要从上往下一个个地判断每一个桶是否为空,才能找到第一个调度的进程。
这是一个近似O(n)的搜索算法。
为了提高效率,引入了位图的操作:
位图是能快速判断某一个值在不在位图里面,如果在设置为1,如果不在设置为0。因为一个比特位只能是0或1。
此时我们让位图的对应比特位映射哈希表的对应下标,当查找哈希表某一个下标x中有没有进程在排队时,可以这样检测:
char bitmap[5];
int i = x % sizeof(char);
int j = x / sizeof(char);
return bitmap[i] & (1<<j);
上面方法是检测某一个下标是否为1,如果为1,代表该位置有进程在排队,如果为0,代表没有进程在排队。
由此还能引出另一个检测方法:
一次检测8个比特位。
只需要让char类型的元素按位与8个比特位均为1的十进制数,如果结果为0,则说明8个比特位全为0。
综上,使用位图检测哈希表中是否有进程在排队时,能将O(n)的算法直接提高到接近O(1)的算法。
我们把这种算法称为O(1)的调度算法。
所以操作系统中进程的调度队列框架大致如下:
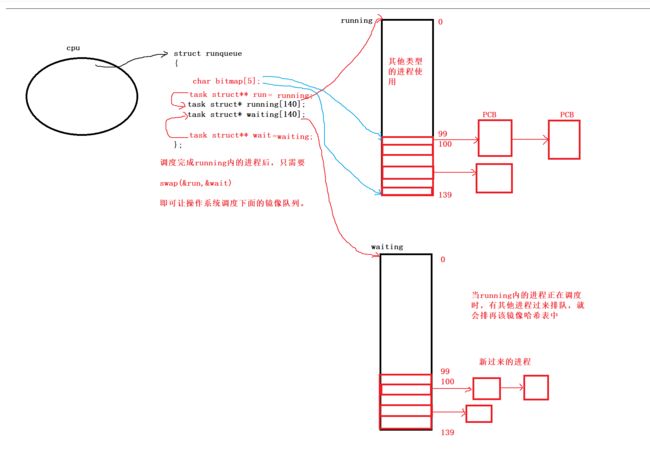
这样就能完整搭建一个进程调度的框架出来了!
五、其他概念
并发(重点)
并发是多个进程在一个CPU下采用进程切换的方式,在一段时间内,让多个进程都得以推进,称之为并发。
前面已经了解到,CPU在调度运行队列时,会去哈希表中查找进程进行调度,因为这些进程是链接在哈希表中的。
CPU在对进程调度时,有两个概念:
进程切换
时间片
以这两个概念为核心的调度算法叫做:基于进程切换和时间片轮转的调度算法。
时间片指的是,任何进程,即使该进程是一个死循环,一旦将它放在CPU上运行,它只能运行指定的时间,一旦时间到了,就会立刻被操作系统扒下来,如果该进程还想运行,那就让该进程的PCB去waiting哈希表中链接起来再次排队。
一旦一个进程运行完,或者时间片到了,操作系统就会立刻将其他进程放上CPU上运行。
这个过程是非常非常快的,快到可以以光速来形容。
这就是为什么我们肉眼看到的是多个进程同时进行的原因。
这里有一个问题:为什么一个函数的返回值能正确地返回到一个变量中或者返回到上层栈桢中?
因为在CPU中存在这大量的寄存器,这些寄存器也有不同的类型。
比如:
通用寄存器:eax,ebx,ecx,edx
栈桢:ebp,esp,eip
状态寄存器:status
函数的返回值会转化成汇编指令
return a -->> mov eax a
意味着会把a这个变量的值临时保存在寄存器中,然后再给上级栈桢中的其他变量。
正因如此,寄存器中还能保存与进程相关的上下文数据!
如果一个进程的时间片到了可该进程的代码还未被执行完,CPU的寄存器就会保存该进程的下一条指令的地址,每次执行完代码都会将该寄存器的值更新,永远保持着该寄存器(eip)存储的都是下一条指令的地址。
所以寄存器在CPU中扮演着能够帮助进程执行,提高调度效率的角色。
进程的高频数据都会被放入到CPU寄存器中,并且大量的寄存器在物理上都安装得离CPU很近,离CPU越近,访问和读取效率越高。
那么,进程切换具体是如何执行的呢?
一个进程在被切换的时候,要将自己的上下文数据保存好并带走,未来该进程再次被CPU调度运行时,CPU才能根据上下文数据从上次调度的地方再次进行调度。
所以,进程被切换时要做两件事:
- 1.保存上下文
- 2.恢复上下文
在被切换走时,可以设置一个结构体,结构体中保存寄存器的数据,这些数据都是进程相关的信息,在进程被切换时将该结构体交给进程的PCB保存即可。
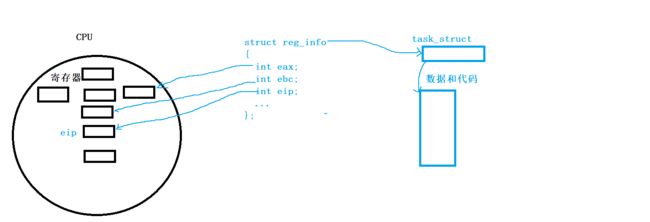
总结
本文章的整条关系链就出来了,先是引入了进程优先级的概念,根据优先级可以知道进程之间存在竞争关系,为了合理地竞争以及合理地分配CPU资源,必须有一个调度队列,该调度队列由调度器控制,能最大程度上尽可能公平地保证每一个进程都能获取到CPU资源,由此引出我们还可以手动修改进程的优先级,PRI,NI值等。
知道了整个进程队列的调度原理后,又继续深入剖析进程的调度队列是如何实现的,由此引入各种数据结构,哈希表,位图,等等。
介绍完进程优先级以及调度队列后,引入了并发的概念,简单说就是一个CPU通过进程切换和时间片的操作,能将大量进程放到CPU上来回切换地运行,从而达到将整个的进程推进的效果。
后面又继续深剖进程的并发,进程切换是如何实现的。