Transformer用于目标检测- End-to-End Object Detection with Transformers
目前为止看到的讲解transformer最清晰的文章
文章目录
- 传统方法存在的问题
- 该方法的创新点
- 网络结构与具体操作
- 实验结果分析
Facebook AI 的研究者推出了 Transformer 的视觉版本—Detection Transformer(以下简称 DETR),用于目标检测和全景分割。与之前的目标检测系统相比,DETR 的架构进行了根本上的改变。这是第一个将 Transformer 成功整合为检测 pipeline 中心构建块的目标检测框架。在性能上,DETR 可以媲美当前的 SOTA 方法,但架构得到了极大简化。
传统方法存在的问题
当前的目标检测方法(比如Faster RCNN、YOLO与CenterNet等)都不够直观,存在以下两点问题:
- 不直接预测目标框,而是使用替代的回归和分类去处理大量的propoasls、anchors或者window centers;
- 模型的效果会受到一系列问题的影响:后处理去消除大量重叠框、anchors的设计、怎么把目标框与anchor关联起来。
该方法的创新点
- 将目标检测任务转化为一个序列预测(set prediction)的任务,使用transformer编码-解码器结构和双边匹配的方法,由输入图像直接得到预测结果;
- 没有proposal(Faster R-CNN),没有anchor(YOLO),没有center(CenterNet),也没有繁琐的NMS,直接预测检测框和类别;
- 不需要任何定制层,可以在任何有CNN和transformer类的框架中使用。
思想
- 利用Transformer构建DETR Architecture,对每张图片预测固定数量的物体(set prediction);
- 训练时,需要将固定数量的预测物体与GT进行匹配。DETR的目标,就是找到set prediction结果与GT的匹配关系。
DETR的结构
DETR的结构很简单,包括三个部分:一个提取图像特征的CNN,一个编码-解码的transformer,一个用来预测最终目标的前向网络FFN。

下面是更细节的流程架构图:
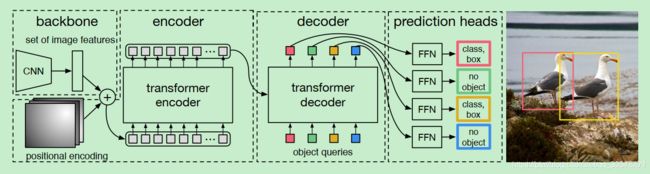
代码部分可参考阅读笔记2
输入
作者这里封装了一个类,感觉多此一举,假如我们输入的是如下两张图片,也就说batch为2:
img1 = torch.rand(3, 200, 200),
img2 = torch.rand(3, 200, 250)
x = nested_tensor_from_tensor_list([torch.rand(3, 200, 200), torch.rand(3, 200, 250)])
这里会转成nested_tensor, 这个nestd_tensor的类型简单说就是把{tensor, mask}打包在一起, tensor就是我们的图片的值,那么mask是什么呢? 当一个batch中的图片大小不一样的时候,我们要把它们处理的整齐,简单说就是把图片都padding成最大的尺寸,padding的方式就是补零,那么batch中的每一张图都有一个mask矩阵,所以mask大小为[2, 200,250], 在img有值的地方是1,补零的地方是0,tensor大小为[2,3,200,250]是经过padding后的。
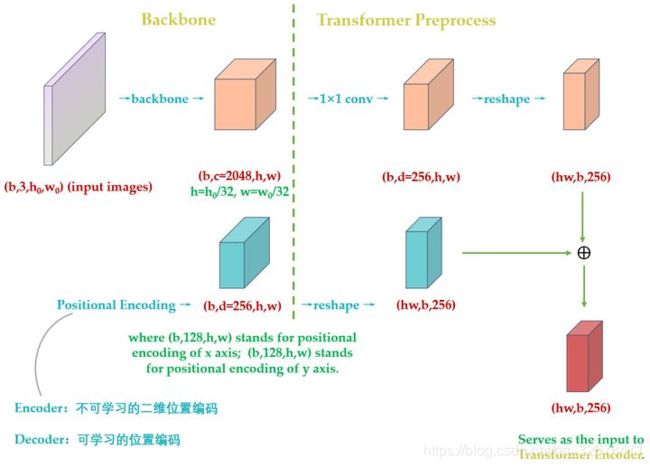
Backbone提取特征
此处可参考阅读笔记3
一般情况下输入是 R 3 ∗ H 0 ∗ W 0 R^{3*H_0*W_0} R3∗H0∗W0,卷积网络生成了更低分辨率的特征图, f = R C ∗ H ∗ W f=R^{C*H*W} f=RC∗H∗W,其中C=2048,H, W=H0/32, W0/32
BackboneBase
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_layers: bool):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
if return_interm_layers:
return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
else:
return_layers = {'layer4': "0"}
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.num_channels = num_channels
def forward(self, tensor_list: NestedTensor):
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
out[name] = NestedTensor(x, mask)
return out
BackBone
class Backbone(BackboneBase):
"""ResNet backbone with frozen BatchNorm."""
def __init__(self, name: str,
train_backbone: bool,
return_interm_layers: bool,
dilation: bool):
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation=[False, False, dilation],
pretrained=is_main_process(), norm_layer=FrozenBatchNorm2d)
num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
super().__init__(backbone, train_backbone, num_channels, return_interm_layers)
Backbone其实是resnet的改编版:
- 一个是用了FrozenBatchNorm2d,冻结了部分参数,实际上这不是DETR的首创,作者的同事(也是facebook)开源的maskrcnn-benchmark中就用到过这个FrozenBatchNorm2d;
- 把resnet作为backbone套到了另一个子网络里,这个子网络主要是把送进去tensor list送进resnet网络,然后逐个提取出来其中的节点(也就是里面的Tensor),把每个节点的“mask”提出来做一次采样,然后再打包进自定义的“NestedTensor”中,按照“名称”:Tensor的方式存入输出的out。(这个NestedTensor一个Tensor里打包存了两个变量:x和mask)。
是把tensor, 也就是图片输入到特征提取器中,这里作者使用的是残差网络,我做实验的时候用多个resnet-50, 所以tensor经过resnet-50后的结果就是[2,2048,7,8]。另外,还有个mask, mask采用的方式F.interpolate,最后得到的结果是[2,7,8]。
获取position_embedding
这里作者使用的三角函数的方式获取position_embedding,position_embediing的输入是上面的NestedTensor={tensor,mask}, 输出最终pos的size为[1,2,256,7,8]。
def forward(self, tensor_list: NestedTensor):
#tensor_list的类型是NestedTensor,内部自动附加了mask,用于表示动态shape,是pytorch中tensor新特性
x = tensor_list.tensors
mask = tensor_list.mask
assert mask is not None
not_mask = ~mask
#因为图像是2d的,所以位置编码也分为x,y方向
# 1 1 1 1 .. 2 2 2 2... 3 3 3...
y_embed = not_mask.cumsum(1, dtype=torch.float32)
# 1 2 3 4 ... 1 2 3 4...
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
#num_pos_feats = 128
## 0~127 self.num_pos_feats=128,因为前面输入向量是256,编码是一半sin,一半cos
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
## 输出shape=b,h,w,128
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
# 每个特征图的xy位置都编码成256的向量,其中前128是y方向编码,而128是x方向编码
return pos
## b,n=256,h,w
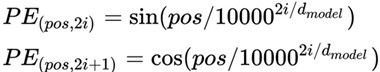
transformer 编码器
可参考阅读笔记4和阅读笔记2。
经过上面一系列操作以后,目前我们拥有src=[ 2, 2048,7,8],mask=[2,7,8], pos=[1,2,256,7,8]。
hs = transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
input_proj:一个卷积层,卷积核为1*1,说白了就是将压缩通道的作用,将2048压缩到256,所以传入transformer的维度是压缩后的[2,256,7,8]。
self.query_embed.weight:现在还用不到,在decoder的时候用到。
下面是transformer,结合网络结构图看代码。

class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
# encode
# 单层
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
# 由6个单层组成整个encoder
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
#decode
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
模型结构如下:
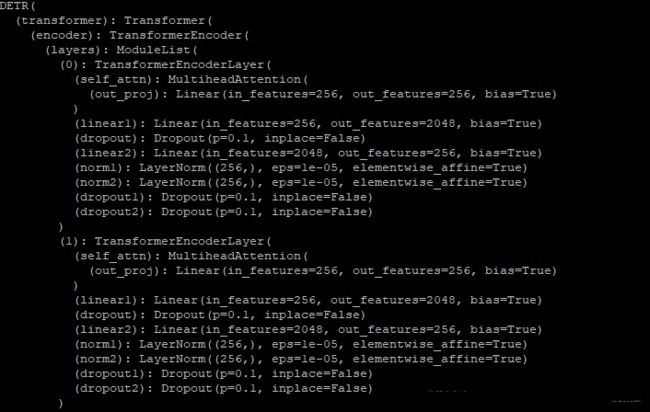
根据代码和模型结构可以看到,encoder部分就是6个TransformerEncodeLayer组成,而每一个编码层又由1个self_attention, 2个ffn,2个norm,每个编码器都需要加入pos位置编码,第一个编码器输入来自图像特征,后面的编码器输入来自前一个编码器输出。
在进行encoder之前先还有个处理:
bs, c, h, w = src.shape# 这个和我们上面说的一样[2,256,7,8]
src = src.flatten(2).permute(2, 0, 1) # src转为[56,2,256]
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)# pos_embed 转为[56,2,256]
mask = mask.flatten(1) #mask 转为[2,56]
encoder的输入为:src是将空间的维度即高和宽进行压缩变成(HW,B,256)维的feature map, mask, pos_embed是位置编码,与原版Transformer不同的是,原版只考虑了x方向的位置编码,DETR考虑了xy方向的位置编码,因为图像特征是2D特征。pos_embed的输出张量是(B,d,H,W),d=256,其中d代表位置编码的长度,H,W代表张量的位置。意思是说,这个特征图上的任意一个点(H1,W1)有个位置编码,这个编码的长度是256,其中,前128维代表H1的位置编码,后128维代表W1的位置编码。
接下来捋一捋第一个单层encoder的过程:
q = k = self.with_pos_embed(src, pos)# pos + src
src2 = self.self_attn(q, k, value=src, key_padding_mask=mask)[0]
#做self_attention,这个不懂的需要补一下transfomer的知识,此处位置编码只与q、k相加,没有与v相加。
src = src + self.dropout1(src2)# 类似于残差网络的加法
src = self.norm1(src)# norm,这个不是batchnorm,很简单不在详述
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))#两个ffn
src = src + self.dropout2(src2)# 同上残差加法
src = self.norm2(src)# norm
return src
根据模型的代码可以看到单层的输出依然为src[56, 2, 256],第二个单层的输入依然是:src, mask, pos_embed。循环往复6次结束encoder,得到输出memory, memory的size依然为[56, 2, 256]。下图是feature map与位置编码相加图:
另一点不同的是,原版Transformer 只在Encoder之前使用了Positional Encoding,而且是在输入上进行Positional Encoding,再把输入经过transformation matrix变为Query,Key和Value这几个张量。但是DETR在Encoder的每一个Multi-head Self-attention之前都使用了Positional Encoding,且只对Query和Key使用了Positional Encoding,即:只把维度为(HW,B,256)维的位置编码与维度为(HW,B,256)维的Query和Key相加,而不与Value相加。
为了更加清晰地看transformer的结构,采用以下图片显示:

transformer 解码器
DETR的Transformer Decoder是一次性处理全部的object queries,即一次性输出全部的predictions;而不像原始的Transformer是auto-regressive的,从左到右一个词一个词地输出。这个过程我们表达为:decodes the N objects in parallel at each decoder layer。
DETR的Decoder主要有两个输入:
- Transformer Encoder输出的Embedding与 position encoding 之和
- Object queries
Embedding就是上面提到的Encoder的输出(HW,b, 256)的编码矩阵。Object queries是一个维度为
(100, b, 256)维的张量,数值类型是nn.Embedding,说明这个张量是可以学习的,即:我们的Object queries是可学习的。Object queries矩阵内部通过学习建模了100个物体之间的全局关系,例如房间里面的桌子旁边(A类)一般是放椅子(B类),而不会是放一头大象(C类),那么在推理时候就可以利用该全局注意力更好的进行解码预测输出。
Decoder的输入一开始也初始化成维度为(100,b, 256)维的全部元素都为0的张量,和Object queries加在一起之后充当第1个multi-head self-attention的Query和Key。第一个multi-head self-attention的Value为Decoder的输入,也就是全0的张量。
到了每个Decoder的第2个multi-head self-attention,它的Key和Value来自Encoder的输出张量,维度为 (hw,b,256),其中Key值还进行位置编码。Query值一部分来自第1个Add and Norm的输出,维度为(100,b,256)的张量,另一部分来自Object queries,充当可学习的位置编码。所以,第2个multi-head self-attention的Key和Value的维度为 (hw,b,256),而Query的维度为(100, b, 256)。
每个Decoder的输出维度为(1, b, 100, 256),送入后面的前馈网络,具体的变量维度的变化见下图:

self.query_embed = nn.Embedding(num_queries, hidden_dim)
注意变量的命名:
object queries(query_pos)
Encoder的位置编码(pos)
Encoder的输出(memory)
到这里你会发现:self.query_embed即query_pos,也就是Object queries,它充当的其实是位置编码的作用,这里使用了nn.Embedding,这是一个矩阵类,里面初始化了一个随机矩阵,矩阵的长是字典的大小,宽是用来表示字典中每个元素的属性向量,向量的维度根据你想要表示的元素的复杂度而定。类实例化之后可以根据字典中元素的下标来查找元素对应的向量。输入下标0,输出就是embeds矩阵中第0行。只不过它是可以学习的位置编码,所以,我们对Encoder和Decoder的每个self-attention的Query和Key的位置编码做个归纳,Value没有位置编码。
代码如下:
tgt = torch.zeros_like(query_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
输入部分:
- memory:这个就是encoder的输出,size为[56,2,256]
- mask:还是上面的mask
- pos_embed:Encoder的位置编码的输出
- query_embed:Object Queries
- tgt: 每一层的decoder的输入,第一层的话等于0
query_embed其实是一个varible,size=[100,2,256],由训练得到,结束后就固定下来了,其中100表示要预测100个目标框。到目前为止我们获得了decoder的所有输入,和encoder一样我们先来看看单层的decoder的运行流程:
#query,key的输入是object queries(query_pos) + Decoder的输入(tgt),shape都是(100,b,256)
#value的输入是Decoder的输入(tgt),shape = (100,b,256)
q = k = self.with_pos_embed(tgt, query_pos)# tgt + query_pos, 第一层的tgt(Decoder的输入)为0
tgt2 = self.self_attn(q, k, value=tgt, key_padding_mask=mask)[0]# 同上
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
#query的输入是上一个attention的输出(tgt) + object queries(query_pos)
#key的输入是Encoder的位置编码(pos) + Encoder的输出(memory)
#value的输入是Encoder的输出(memory)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory,
key_padding_mask=mask)[0]#交叉attention
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
这里的难点可能是交叉attention,也叫encoder_decoder_attention, 这里利用的是encoder的输出来参与计算,经过上面六次的处理,最后得到的结果为[100,2,256], 返回的时候做一个转换,最终的结果transpose(1, 2)->[100,256,2]。DETR Decoder的结构也与Transformer类似,每个Decoder有两个输入:一个是Object Query(或者是上一个Decoder的输出),另一个是Encoder的结果,区别在于这里是并行解码N个object。与原始的transformer不同的地方在于decoder每一层都输出结果,计算loss。另外一个与Transformer不同的地方是,DETR的Decoder和encoder一样也加入了可学习的positional embedding,其功能类似于anchor。最后一个Decoder后面接了两个FFN(F由三层的感知器计算,使用relu,隐层的size为d,线性的映射层。使用softmax输出类别概率),分别预测检测框及其类别。
Object queries可参考阅读笔记5。
损失函数
此处可参考 阅读笔记1
使用附加的loss对模型的训练有帮助,我们在每一个decoder层后面加上FFNs和匈牙利loss。所有FNNs共享权重。我们使用共享的layer-norm 去归一化不同decoder层的输出(N=100个预测目标的class和Bounding Box)。当然这个100肯定是大于图中的目标总数的。如果不够100,则采用背景填充,计算loss时候回归分支分支仅仅计算有物体位置,背景集合忽略。所以,DETR输出张量的维度为输出的张量的维度是 (b,100,class+1)和(b,100,4)。对应COCO数据集来说,class+1=92,4指的是每个预测目标归一化的(cx,cy,w,h)。归一化就是除以图片宽高进行归一化。
怎么将预测值与真值一一对应?
相比Faster R-CNN等做法,DETR最大特点是将目标检测问题转化为无序集合预测问题(set prediction)。论文中特意指出Faster R-CNN这种设置一大堆anchor,然后基于anchor进行分类和回归其实属于代理做法即不是最直接做法,目标检测任务就是输出无序集合,而Faster R-CNN等算法通过各种操作,并结合复杂后处理最终才得到无序集合属于绕路了,而DETR就比较纯粹了。现在核心问题来了:输出的(b,100)个检测结果是无序的,如何和 GT Bounding Box计算loss?这就需要用到经典的双边匹配算法了,也就是常说的匈牙利算法,该算法广泛应用于最优分配问题。
假设set prediction有N个预测结果,而GT的数量一般都是小于N,那么,先要对GT执行PAD操作(用no object来进行填充),然后通过匈牙利算法找到预测的N个结果与M个GT的两两匹配结果,距离越近表示越可能是最优匹配关系,也就是两者最密切,广义距离的计算考虑了分类分支和回归分支。此处的匹配与之前Faster RCNN/Yolo的匹配其实都是差不多的,不同之处在于,DETR中GT与预测结果是一一匹配的。以下是DETR的匹配公式:

对于非空的匹配, Lmatch同时考虑了类别预测损失即真实框之间的相似度预测,形式如下:
![]()
考虑到尺度的问题,将L1损失和iou损失线性组合,在batch内部我们用目标的数量对loss做了归一化。bbox损失定义为:
![]()
其中,Liou是generalized IoU loss。在匹配损失中我们直接使用概率而非对数值是为了让类别预测项与box损失一个量级,我们发现这种效果更好。代码部分如下:
# pred_logits:[b,100,92]
# pred_boxes:[b,100,4]
# targets是个长度为b的list,其中的每个元素是个字典,共包含:labels-长度为(m,)的Tensor,元素是标签;boxes-长度为(m,4)的Tensor,元素是Bounding Box。
# detr分类输出,num_queries=100,shape是(b,100,92)
bs, num_queries = outputs["pred_logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes] = [100b, 92]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4] = [100b, 4]
# 准备分类target shape=(m,)里面存储的是类别索引,m包括了整个batch内部的所有gt bbox
# Also concat the target labels and boxes
tgt_ids = torch.cat([v["labels"] for v in targets])# (m,)[3,6,7,9,5,9,3]
# 准备bbox target shape=(m,4),已经归一化了
tgt_bbox = torch.cat([v["boxes"] for v in targets])# (m,4)
#(100b,92)->(100b, m),对于每个预测结果,把目前gt里面有的所有类别值提取出来,其余值不需要参与匹配
#对应上述公式,类似于nll loss,但是更加简单
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be ommitted.
#行:取每一行;列:只取tgt_ids对应的m列
cost_class = -out_prob[:, tgt_ids]# (100b, m)
# Compute the L1 cost between boxes, 计算out_bbox和tgt_bbox两两之间的l1距离 (100b, m)
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)# (100b, m)
# Compute the giou cost betwen boxes, 额外多计算一个giou loss (100b, m)
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
#得到最终的广义距离(100b, m),距离越小越可能是最优匹配
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
#(100b, m)--> (b, 100, m)
C = C.view(bs, num_queries, -1).cpu()
#计算每个batch内部有多少物体,后续计算时候按照单张图片进行匹配,没必要batch级别匹配,徒增计算
sizes = [len(v["boxes"]) for v in targets]
#匈牙利最优匹配,返回匹配索引
#enumerate(C.split(sizes, -1))]:(b,100,image1,image2,image3,...)
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
实验部分

由上图可知,DETR框架虽然简洁,但效果与经典方法faster rcnn不相上下,其中DETR对于大目标的检测效果有所提升,但在小目标的检测中表现较差。该文提出的方法十分新颖,使用类似机器翻译的序列预测思想,打破了目标检测的传统思想,减少检测器对先验性息和后处理的依赖,使目标检测框架更加简洁的同时获得了与faster rcnn相媲美的效果。训练了500个epoch,比Faster RCNN慢了10-20倍,需要大显存才能提升性能。每块V100(32G显存)只能放下四张图片的batch,64个batch是用了16块V100实现的。