【LittleXi】【MIT6.S081-2022Fall】Lab: syscall
【LittleXi】【MIT6.S081-2022Fall】Lab: syscall
文章目录
- lab2
-
- 实验1:Process counting
-
- 实验思路
- 实验过程
- 实验2:Free Memory Cou
-
- 实验思路
- 实验过程
- 实验3:System call tracin
-
- 实验思路
- 实验过程
- 实验4:流程概述
-
- 1.请概述用户从发出系统调用指令到得到返回结果的执行的流程。
- 2.搜索资料,概述malloc的底层实现原理
- 实验过程中遇到的问题及解决方案
-
- 遇到的问题:
- 解决方案:
- 实验总结
lab2
实验1:Process counting
实验思路
1、实验要求我们增加一个新的系统调用procnum,统计系统总进程数。
2、那么我们只需要按照实验准备的工作的五个步骤去添加(最开始并没有注意到每个地方添加的意义是什么,所以直接原封不动添加了SYS_new_syscal,然后感觉不太对劲)
3、添加实验准备后,然后就可以直接开始计数了,计数步骤很简单,(最开始误以为进程挂载在CPU上,导致出错)直接遍历proc数组就行了,注意数组的长度为NPROC ,然后简单计数一下就行了
实验过程
1、在proc.c中添加计数代码,用num计数,然后将函数声明放进defs.h文件中,保证其它文件能够调用到该函数
uint64 proccnt()
{
uint64 num = 0;
for(int i=0;i<NPROC;i++)
{
acquire(&proc[i].lock);
num+=proc[i].state != UNUSED;
release(&proc[i].lock);
}
return num;
}
2、在sysproc.c文件中添加一个系统级可调用的函数,直接返回proccnt的值
uint64 sys_procnum (void)
{
return proccnt();
}
3、修改procnum.c文件中的num的值的获取方式,使得num的值为procnum()的返回的值
int num = -1;
if ((num = procnum()) < 0)
{
fprintf(2, "procnum failed!\n");
exit(1);
}
printf("Number of process: %d\n", num);
exit(0);
4、系统调用流程,先进入procnum.c文件中,然后遇到procnum函数,从user.h中去查找这个函数,接着进入syscall中去查找sys_procnum函数,进入sysproc.c中调用对应函数,然后继续调用proc.c 中的函数
5、实验运行结果

实验2:Free Memory Cou
实验思路
1、实验2和实验1高度相似,除了计数不一样之外,其它地方和实验一几乎一样
2、单独说一下计数,这个实验的计数是在kalloc.c文件中完成的,因为空闲页的管理是用指针的方式实现的 ,所以计数的方法可以先用一个指针指向空闲内存链表的表头,然后对指针进行移动,同时记录一下有多少个页被访问过了,当移到到链表的表尾的时候就停止移动,返回num*pageSize就是空闲的内存
实验过程
1、实验准备和实验一类似,不再赘述
2、计数的代码实现和实验思路第二点一样,就是利用指针的移动来进行计数
uint64 freecnt()
{
uint64 num = 0;
struct run* ptr = kmem.freelist;
struct spinlock* lock = &kmem.lock;
acquire(lock);
while(ptr) {
num++;
ptr = ptr->next;
}
release(lock);
return num*PGSIZE;
}
3、系统调用流程,和实验一几乎一样,不同的区别在于实验一计数是进入proc.c中,而这里是进入kalloc.c 文件
4、实验结果截图:

实验3:System call tracin
实验思路
1、本实验的前期准备和实验一和实验二一样,一共要修改makefile、user.h、usys.pl等8个文件
2、本实验的整体思路就是将读取参数中的mask保存在proc进程中,然后在进行系统级调用的时候根据掩码进行打印程序运行的pid、系统调用名称和返回值就行。
实验过程
1、修改makefile、user.h、usys.pl等8个文件和实验1、2类似,不再赘述
2、修改proc.h文件中的结构体proc,在该结构体中添加一个mask变量以保存mask参数
struct proc
{
struct spinlock lock;
//此处省略若干代码....
char name[16]; // Process name (debugging)
int mask; // Add mask val
};
3、对于具有fork代码的实现,我们需要修改一下proc.c文件中的fork()函数,在子进程中我们需要copy一下父进程的mask和state
int fork(void)
{
int i, pid;
//此处省略若干代码....
//copy mask
np->mask = p -> mask;
pid = np->pid;
np->state = p->state;
//此处省略若干代码....
return pid;
}
4、在sysproc.c文件中实现trace函数,在函数的实现过程中可以调用argint方法,获取系统调用的参数,然后将参数保存在之前加入到的结构体proc中
uint64 sys_trace(int n)
{
argint(0, &n);
if ( n < 0)
return -1;
myproc()->mask = n;
return 0;
}
5、在syscall.c文件中,添加系统调用的识别名,并在syscall函数中添加需要输出的信息,如果当前进程的掩码和系统调用的函数是一样的,那么就输出该系统调用的pid、系统调用名称和返回值,代码实现如下
char* syscalls_name[23] = {
"",
"fork",
"exit",
"wait",
"pipe",
"read",
"kill",
"exec",
"fstat",
"chdir",
"dup",
"getpid",
"sbrk",
"sleep",
"uptime",
"open",
"write",
"mknod",
"unlink",
"link",
"mkdir",
"close",
"trace",
};
void syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if (num > 0 && num < NELEM(syscalls) && syscalls[num])
{
p->trapframe->a0 = syscalls[num]();
if(p->mask&(1<<num))
printf("%d: syscall %s -> %d\n",p->pid,syscalls_name[num],p->trapframe->a0);
}
else
{
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
6、实验结果截图
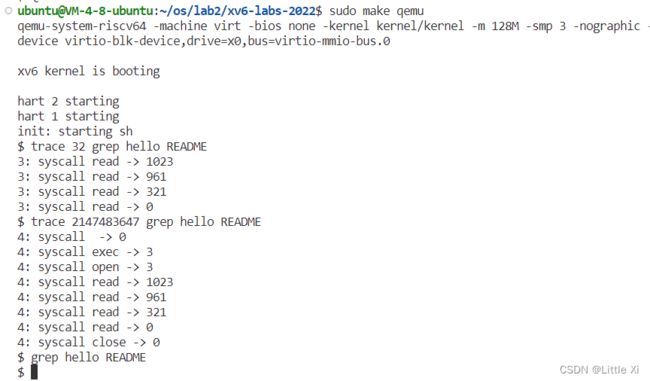
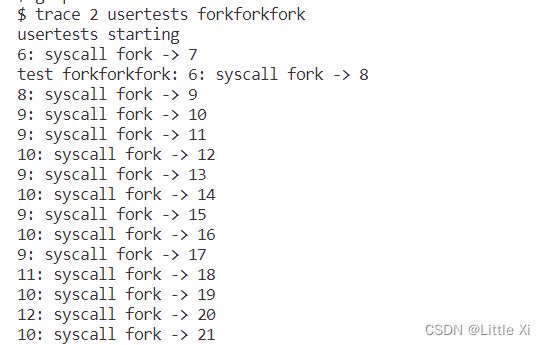
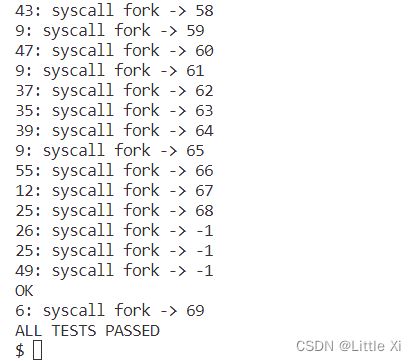
实验4:流程概述
1.请概述用户从发出系统调用指令到得到返回结果的执行的流程。
答:
- 用户程序发出系统调用指令: 用户程序需要与操作系统内核进行交互以执行特权操作。用户程序通过调用包装好的系统调用函数(例如
procnum()、freemem()、trace()等)来发出系统调用请求。 - 陷入内核态: 当用户程序发出系统调用请求时,处理器从用户态切换到内核态。通常是通过硬件中断或异常来实现的,将程序控制权传递给内核。
- 系统调用处理:一旦操作系统内核获得控制权,它会根据系统调用号和参数来确定要执行的操作。内核会检查参数的有效性,然后执行请求的操作。
- 执行系统调用: 内核执行系统调用的实际操作,例如进程计数、空闲内存计数、跟踪调用trace等。
- 返回结果给用户程序: 一旦系统调用完成,内核将结果返回给用户程序,例如procnum.c文件中的procnum()函数。如果系统调用成功,返回值将是非负整数,表示操作成功的结果。如果发生错误,返回值将是一个负整数,表示错误码。
- 恢复用户态: 用户程序再次获得控制权,并继续执行。它可以检查系统调用的返回值以确定操作是否成功,并采取适当的措施来处理结果或错误。
总之,用户从发出系统调用指令到获得返回结果的执行流程涉及从用户态到内核态的切换、系统调用处理和结果返回。这个过程允许用户程序执行需要操作系统内核权限的任务,并获得对系统资源的访问和控制。
2.搜索资料,概述malloc的底层实现原理
答:malloc 是C语言标准库中用于动态分配内存的函数,它的底层实现原理通常涉及内存管理和操作系统的系统调用。下面是 malloc 的基本底层实现原理:
- 内存池管理:
malloc会维护一个内存池(memory pool),通常是一块连续的虚拟内存空间。这个内存池被分割成小块,每块用于存储用户请求的内存。内存块可以分为不同的大小类别,以便满足不同大小的内存需求。 - 分配内存: 当用户调用
malloc函数请求内存时,底层实现会搜索内存池,查找一个足够大的、未被分配的内存块。这个内存块会被标记为已分配,并返回给用户程序。 - 内部碎片: 内存分配可能会导致内部碎片,也就是已分配内存块比用户请求的内存稍大。这是因为内存管理需要在内存块之间维护元数据(例如大小、分配状态),从而浪费一些内存空间。
- 释放内存: 当用户调用
free函数释放已分配的内存时,底层实现将相应的内存块标记为未分配,以便后续malloc调用可以再次使用它。 - 碎片整理: 随着时间的推移,内存池可能会出现碎片,其中已分配和未分配的内存块交织在一起。一些
malloc实现会定期执行碎片整理操作,将未分配的内存块合并在一起,以便更好地满足大内存块的请求。 - 底层系统调用: 在底层,
malloc的实现通常需要与操作系统内核进行交互,以获取物理内存或虚拟内存的分配和释放权限。这可能涉及到系统调用,如brk或mmap,这些系统调用用于动态分配和释放内存页。
具体的 malloc 实现在不同的编译器和操作系统上可能有所不同。常见的 malloc 实现包括 glibc 中的 malloc、Windows 中的 HeapAlloc 等。这些实现可能采用不同的算法和数据结构来管理内存池,以提高性能和减少碎片。
实验过程中遇到的问题及解决方案
遇到的问题:
在procnum.c文件中直接调用函数procnum(&num)会报错,并且不是因为函数没有定义为procnum(int* num)造成的
解决方案:
将procnum(&num)函数重构为num = procnum()可以解决
实验总结
简单总结一下:实验本身不难,感觉90%的难度都在理解代码,以及各个文件之间的依赖关系和每个函数之间的依赖关系
。