Seata 分布式事务
Seata 分布式事务
一、概述
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务.在 Seata 开源之前,Seata 对应的内部版本在阿里经济体内部一直扮演着分布式一致性中间件的角色,帮助平稳的度过历年的双11,对各业务进行了有力的支撑。
经过多年沉淀与积累,商业化产品先后在阿里云、金融云进行售卖。2019.1 为了打造更加完善的技术生态,Seata 正式宣布对外开源,未来 Seata 将以社区共建的形式帮助其技术更加可靠与完备。
Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
二、Seata AT模式
Seata AT模式实际上是2PC协议的一种演变方式,也是通过两个阶段的提交或者回滚来保证多节点事务的一致性,它的工作模型如下图所示
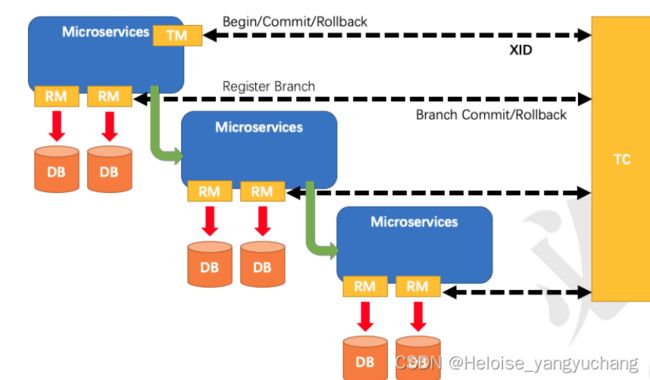
具体工作流程说明如下:
- 第一阶段, 应用系统会把一个业务数据的事务操作和回滚日志(redo log 表)记录在同一个本地事务中提交,在提交之前,会向TC(seata server)注册事务分支,并申请针对本次事务操作的表的全局锁。 接着提交本地事务,本地事务会提交业务数据的事务操作以及UNDO LOG,放在一个事务中提交。
- 第二个阶段,这个阶段会根据参与到同一个XID下所有事务分支在第一个阶段的执行结果来决定事务的提交或者回滚,这个回滚或者提交是TC来决定的,它会告诉当前XID下的所有事务分支,提交或者回滚。
- 如果是提交, 则把提交请求放入到一个异步任务队列,并且马上返回提交成功给到 TC,这样可以避免阻塞问题。而这个异步任务,只需要删除UNDO LOG就行,因为原本的事务已经提交了。
- 如果是回滚,则开启一个本地事务,执行以下操作
- 通过XID和Branch ID查找到响应的UNDO LOG记录
- 根据UNDO LOG中的before image和业务SQL的相关信息生成并执行回滚语句
- 提交本地事务,并把本地事务的执行结果上报给TC
总结核心步骤和SQL类似:
- 加锁
- 写事务日志
- 提交事务或回滚事务
2.1、Seata AT模式的事务隔离级别
数据库的事务特性,必须会涉及到的就是事务的隔离级别,不同的隔离级别,会产生一些并发性的问题,比如
- 脏读
- 不可重复读
- 幻读
读隔离
在数据库本地事务隔离级别读已提交(Read Committed) 或以上的基础上,Seata(AT模式)的默认全局隔离级别是读未提交(Read Uncommitted) 。其实从前面的流程中就可以很显而易见的分析出来,因为本地事务提交之后,这个数据就对外可见,并不用等到tc触发全局事务的提交。
如果在特定场景下,必须要求全局的读已提交,目前Seata的方式只能通过SELECT FORUPDATE语句来实现。SELECT FOR UPDATE 语句的执行会申请全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被block 住的,直到全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata目前的方案并没有对所有 SELECT语句都进行代理,仅针对FOR UPDATE 的 SELECT语句。
写隔离
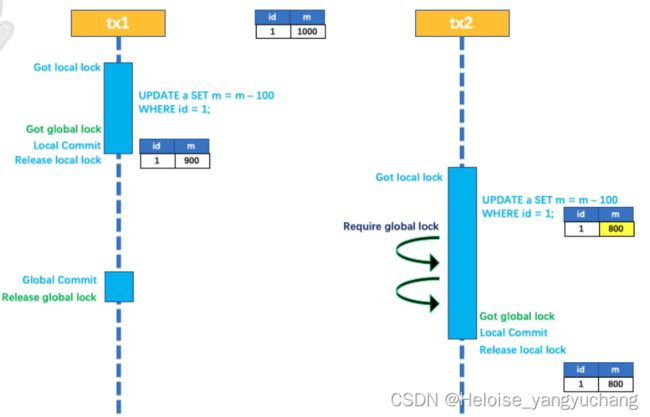
所谓的写隔离,就是多个事务对同一个表的同一条数据做修改的时候,需要保证对于这个数据更新操作的隔离性,在传统事务模型中,我们一般是采用锁的方式来实现。
那么在分布式事务中,如果存在多个全局事务对于同一个数据进行修改,为了保证写操作的隔离,也需要通过一种方式来实现隔离性,自然也是用到锁的方法,具体来说。
- 在第一阶段本地事务提交之前,需要确保先拿到全局锁,如果拿不到全局锁,则不能提交本地事务
- 拿到全局锁的尝试会被限制在一定范围内,超出范围会被放弃并回滚本地事务并释放本地锁
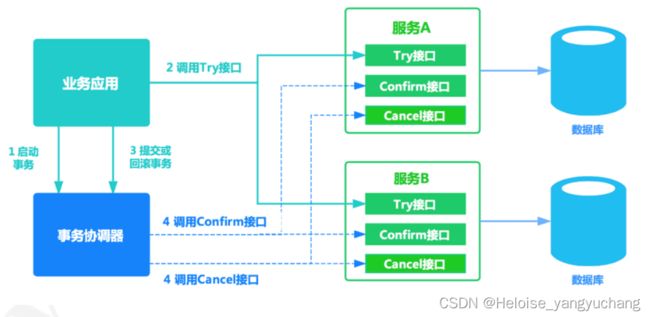
三、Seata TCC模式
TCC将整个业务逻辑的每个分支分成了Try、Confirm/Cancel三个操作,try部分完成业务的准备工作,confirm部分完成业务的提交、cancel部分完成事务的回滚。
TCC事务解决方案本质上是一种补偿的思路,它把事务运行过程分成Try、Confirm/cancel两个阶段,每个阶段由业务代码控制,这样事务的锁力度可以完全自由控制。需要注意的是,TCC事务和2pc的思想类似,但并不是2pc的实现,TCC不再是两阶段提交,而只是它对事务的提交/回滚是通过执行一段confirm/cancel业务逻辑来实现,并且也并没有全局事务来把控整个事务逻辑。
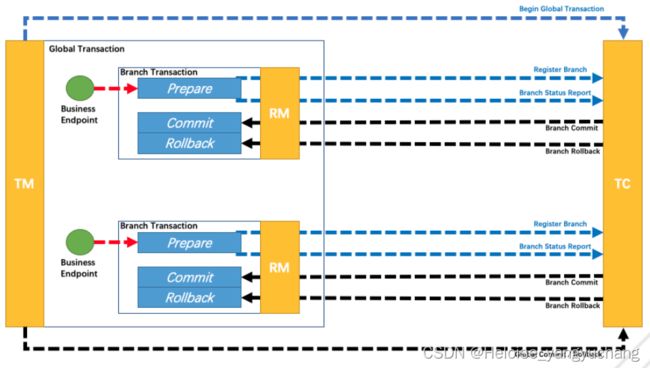
3.1、Seata TCC模式
- 一阶段 prepare 行为
- 二阶段 commit 或 rollback 行为
3.2、AT 模式 和 TCC 模式 总结
AT 模式基于 支持本地 ACID 事务 的 关系型数据库:
- 一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
- 二阶段 commit 行为:马上成功结束,自动异步批量清理回滚日志。
- 二阶段 rollback 行为:通过回滚日志表记录,自动生成补偿操作,完成数据回滚。
TCC 模式,不依赖于底层数据资源的事务支持:
- 一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
- 二阶段 commit 行为:调用 自定义 的 commit 逻辑。
- 二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中,对业务代码的侵入比较严重。
四、Seata Saga模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。这个其实就是一个最终一致性的实现
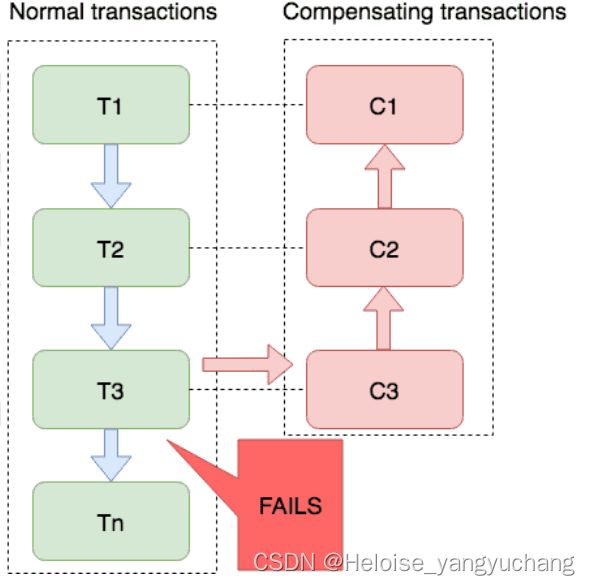
4.1、Saga事务的恢复策略
Saga 的执行顺序有两种,如上图:
- 事务正常执行完成:T1, T2, T3, …, Tn,例如:扣减库存(T1),创建订单(T2),支付(T3),依次有序 完成整个事务。
- 事务回滚:T1, T2, …, Tj, Cj,…, C2, C1,其中 0 < j
向前恢复
所谓向前恢复,就是指一些必须要成功的场景,如果某个子事务出现异常,不能回滚,而是不断触发重试来确保事务的成功。
向后恢复
所谓向后恢复,就是指事务的回滚。也就是要往后逐项会撤销之前所有成功的子事务。注意如果向后反向还是失败的话,这个就需要人工干预,因为没有向后反向的反向。
适用场景
业务流程长、业务流程多,参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口,优势如下
- 一阶段提交本地事务,无锁,高性能
- 事件驱动架构,参与者可异步执行,高吞吐
- 补偿服务易于实现
缺点就是不保证事务隔离性
五、Seata XA模式
实际上前面的三种事务方式,AT、TCC、Saga都是属于补偿性事务,补偿性事务有一个特点就是无法做到真正的全局一致性,也就是无法保证从事务框架之外的全局视角的数据一致性,所以Seata引入了XA模式的支持。
XA模式,之前也讲过,它是X/Open组织定义的分布式事务处理标准(DTP,DistributedTransaction Processing)XA 规范描述了全局的事务管理器与局部的资源管理器之间的接口。XA规范的目的是允许的多个资源(如数据库,应用服务器,消息队列等)在同一事务中访问,这样可以使 ACID 属性跨越应用程序而保持有效。
XA和补偿性不一样的点在于,XA协议要求事务资源(RM)本身提供对于XA协议的实现,这样可以使得事务资源(RM)感知并参与分布式事务的处理过程,所以事务资源(RM)可以保障从任意视角对数据的访问有效隔离并满足全局数据一致性。
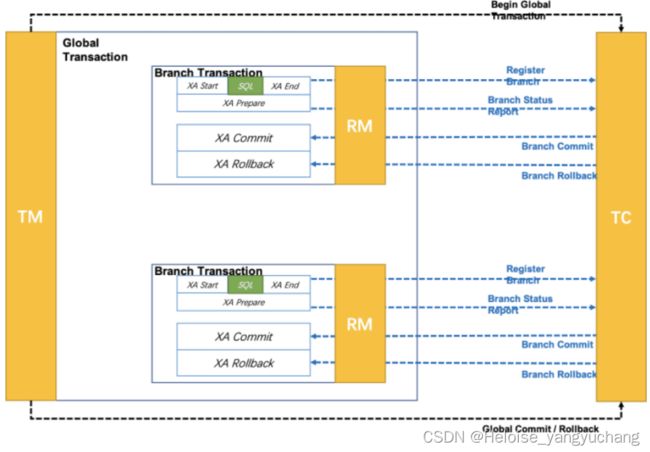
- 执行阶段
- 先向TC(Seata server)注册全局事务,注册之后会分配一个xid,XA start的时候需要Xid参 数,这个参数可以和Seata全局事务的XID和BranchId关联,以便由TC来驱动XA分支的提交和回滚
- 向TC注册分支事务,目前Seata的BranchId是在分支注册的过程中由TC统一生成的,所以XA模式分支注册的时机需要在XA start之前。
- 通过XA Start开启XID事务,{XA START xid}
- 执行事务SQL,预提交xid事务,也就是先执行事务操作,但是这个事务并没有提交,只是像本地事务一样写入事务日志。再调用XA END xid结束xid事务
- XA Prepare XID 表示准备就绪,等待提交。然后向TC上报事务分支的执行结果
- 完成阶段
TC根据第一阶段所有事务分支的执行结果来决定事务的提交或者回滚,XA commit / XA rollback
5.1 XA的优点
XA和补偿性事务不同,XA协议要求事务资源本身提供对XA协议规范和协议的支持。
因为事务资源感知并参与分布式事务处理过程,所以事务资源(如数据库)可以保障从任意视角对数据的访问有效隔离,满足全局数据一致性。而这些数据的隔离性,就会依赖于数据库本身的隔离级别,如果是在读已提交之上,则不会出现脏读的情况。
- 业务无侵入:和 AT 一样,XA 模式将是业务无侵入的,不给应用设计和开发带来额外负担。
- 数据库的支持广泛:XA 协议被主流关系型数据库广泛支持,不需要额外的适配即可使用
- 传统基于 XA 应用的迁移:传统的,基于 XA 协议的应用,迁移到 Seata 平台,使用 XA 模式将更平滑。
六、Seata事务的使用
6.1、Seata server安装
sh seata-server.sh -p 8091 -h 127.0.0.1 -m file
使用时只要在对应的位置加上**@GlobalTranscation**
6.2、存储模式
事务日志的存储方式可以支持file、 db、 redis,默认情况下采用的是file,file存储是单机模式,全局事务会话信息会持久化到${SEATA_HOME}\bin\sessionStore\root.data中。db和redis可以支持HA,file不行,但是性能比较好。
6.3、服务端配置
Seata-Server包含两个核心配置文件,registry.conf和file.conf
- registry.conf表示配置Seata服务注册的地址,它目前支持所有主流的注册中心。默认是file,表示不依赖于注册中心以及配置中心。
- file.conf存储的是Seata服务端的配置信息,完整的配置包含transport、Server、Metrics,分别表示线程配置,服务端配置,监控等。
registry.conf:
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "file"
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP"
namespace = ""
cluster = "default"
username = ""
password = ""
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = ""
password = ""
}
}
file.conf:
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true # client和server心跳检测开关
# the client batch send request enable
enableClientBatchSendRequest = false
#thread factory for netty
threadFactory { # 线程配置
bossThreadPrefix = "NettyBoss"
workerThreadPrefix = "NettyServerNIOWorker"
serverExecutorThreadPrefix = "NettyServerBizHandler"
shareBossWorker = false
clientSelectorThreadPrefix = "NettyClientSelector"
clientSelectorThreadSize = 1
clientWorkerThreadPrefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
bossThreadSize = 1
#auto default pin or 8
workerThreadSize = "default"
}
shutdown {
# when destroy server, wait seconds
wait = 3
}
serialization = "seata" #序列化方式
compressor = "none" # 数据压缩方式, none ,gzip, 默认none
}
## server configuration, only used in server side
server {
recovery {
#schedule committing retry period in milliseconds
committingRetryPeriod = 1000 # 两阶段提交未完成状态全局事务重试提交线程间隔时间
#schedule asyn committing retry period in milliseconds
asynCommittingRetryPeriod = 1000 # 两阶段异步提交状态重试提交线程间隔时间
#schedule rollbacking retry period in milliseconds
rollbackingRetryPeriod = 1000 # 两阶段回滚状态 重试回滚线程 间隔时间
#schedule timeout retry period in milliseconds
timeoutRetryPeriod = 1000 # 超时状态监测重试线程间隔时间
}
undo {
logSaveDays = 7 # undo保留天数
#schedule delete expired undo_log in milliseconds
logDeletePeriod = 86400000 # 清理线程间隔时间(毫秒)
}
#check auth
enableCheckAuth = true
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days,
default permanent
maxCommitRetryTimeout = "-1"
maxRollbackRetryTimeout = "-1"
rollbackRetryTimeoutUnlockEnable = false
}
## metrics configuration, only used in server side
metrics { # 指标数据,
enabled = false
registryType = "compact"
# multi exporters use comma divided
exporterList = "prometheus"
exporterPrometheusPort = 9898
}