synchronized的实现原理——对象头解密
前言
并发编程式Java基础,同时也是Java最难的一部分,因为与底层操作系统和硬件息息相关,并且程序难以调试。本系列就从synchronized原理开始,逐步深入,领会并发编程之美。
正文
基础稍微好点的同学应该都知道,Java中获取锁有两种方式,一种是使用synchronized关键字,另外一种就是使用Lock接口的实现类。前者就是Java原生的方式,但在优化以前(JDK1.6)性能都不如Lock,因为在优化之前一旦使用synchronized就会发生系统调用进入内核态,所以性能很差,也因此大神Doug Lea自己写了一套并发类,也就是JUC,并在JDK1.5版本引入进了Java类库。那么作为Java的亲儿子synchronized自然也不能示弱啊,所以sun公司对其做了大量的优化,引入了偏向锁、轻量级锁、重量锁、锁消除、锁粗化,才使得synchronized性能大大提升。
线程模型
Java的线程本质是什么?
首先我们需要了解线程的模型,实现线程有以下三种方式:
- 使用内核线程,即一对一模型
- 使用用户线程,即一对多模型(一个内核线程对应多个用户线程,如现在比较火的Golang)
- 混合实现,即多对多模型,这种比较复杂,不用太过深入。
而Java现在就是采用的一对一模型(JDK1.2以前是使用的用户线程实现),即当调用start方法时都是真实地创建一个内核线程(KLT),但程序一般不会直接使用内核线程,而是使用内核线程的一种高级接口——轻量级进程(LWP)。轻量级进程和内核线程也是一对一的关系,因此使用它可以保证每个线程都是一个独立的调度单元,即当前线程阻塞了也不会影响整个进程工作,但带来的问题就是在线程创建、销毁、同步、切换等场景都会涉及系统调用,性能比较低;另外每个轻量级进程都要占据一定的系统资源,因此,能够创建的线程数量是有限的。
锁优化
因为大部分情况下不会出现线程竞争,所以为了避免线程每次遇到synchronized都直接进入内核态,sun公司使用大量的优化手段:
- 偏向锁:当一个线程第一次获得锁后再次申请获取就可以直接拿到锁,相当于无锁,这种情况下效率最高。
- 轻量级锁:在没有多线程竞争,但有多个线程交替执行情况下,避免调用系统函数mutex(特指linux系统)产生的性能消耗。
- 重量级锁:发生了多线程竞争,就会调用mutex函数使得未获取到锁的线程进入睡眠状态。
- 锁消除:代码经过逃逸分析后,判断没有数据会逃逸出线程,就不会给这段这段代码加锁。
- 锁粗化:如果虚拟机检测到有一系列零碎的操作都对同一对象加锁,就会将整个同步操作扩大到这些操作的外部,这样就只需要加锁一次即可。
本篇主要讨论锁膨胀的过程对对象的影响,所以总结为一句话就是:当一个线程第一次获取锁后再去拿锁就是偏向锁,如果有别的线程和当前线程交替执行就膨胀为轻量级锁,如果发生竞争就会膨胀为重量级锁。这个就是synchronized锁膨胀的原理,但并不完全正确,其中还有很多细节,下面就一步步来说明。
对象的内存布局
理论
对象在内存中是如何分配的呢?学过JVM的人应该都知道,如下图:
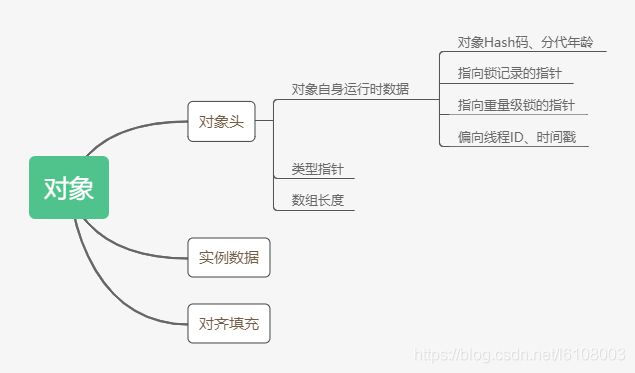
但上图只是说明了一个对象在内存中由哪几部分组成,但具体每一部分多大,整个对象又有多大呢?比如下面这个类的对象在内存中占用多少个字节:
public class A{}
32位和64位虚拟机表现不同,这里以主流的64位进行说明。一个对象在内存中存储必须是8字节的整数倍,其中对象头占了12字节,这里A对象没有实例数据,所以还需要4字节的对其填充,所以占用16字节(如果该对象中有一个boolean对象的成员变量,这个对象又占用多少字节呢)。另外对象头中也分为了两部分,一部分是指向方法区元数据的类型指针(klass point),固定占用4字节32位;另一部分则是则是用于存储对象hashcode、分代年龄、锁标识(偏向、轻量、重量)、线程id等信息的mark word,占用8字节64位。由于类型指针是固定的,下面主要讨论mark word部分的内存布局。
我们可以看到在mark word中存储了很多信息,这么多信息64位肯定是不够存储的,那怎么办呢?虚拟机将mark word设计成为了一个非固定的动态数据结构,意思是它会根据当前的对象状态存储不同的信息,达到空间复用的目的,下图就是一个对象的mark word在不同的状态下存储的信息:
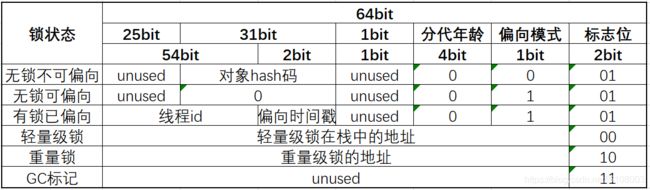
从上图我们可以发现无锁、偏向锁、轻量锁、重量锁分别的状态是:01、01、00、10,偏向锁同时还需要额外的以为表示是否可偏向。因为当一个对象持有偏向锁时,需要在对象头中存储线程id和偏向时间戳,占用56bit,而对象的hashcode需要占用31bit,空间就不够了,所以一旦对象调用了未重写的hashcode方法就无法获取偏向锁。
另外我们可以看到当锁膨胀为轻量锁或重量锁时,对象头中62bit都用来存储锁记录(Lock record)的地址了,那他们的分代年龄、hashcode这些信息去哪了呢?其实就存在于锁记录空间中,而锁记录是存在于当前线程的栈帧中的。虚拟机会使用CAS操作尝试把mark word指向当前的Lock record,如果修改成功,则当前线程获取到该锁,并标记为00轻量锁,如果修改失败,虚拟机会检查对象的mark word是否指向当前线程的栈帧,如果是,则直接获取锁执行即可,否则则说明有其它线程和当前线程在竞争锁资源,直接膨胀为重量级锁,等待的线程则进入阻塞状态。
证明
偏向锁
上面说的都是理论,怎么证明呢?先引入下面这个依赖:
org.openjdk.jol
jol-core
0.10
然后针对之前创建的A类,执行下面的方法:
public class TestJol {
static A l = new A();
public static void main(String[] args) throws InterruptedException {
log.debug("线程还未启动----无锁");
log.debug(ClassLayout.parseInstance(l).toPrintable());
}
}
控制台就会打印如下信息:

我们主要看到二进制部分内容前两行内容(第三行是类型指针),按照之前所说,当前这个对象应该是无锁可偏向状态,那么前25个bit应该是未被使用的,后三个bit应该是101,中间部分也应该都是0,但是图中显示的和我们理论不符啊。别急,这其实是由于我们现在的家用电脑基本上采用的都是小端存储导致的,那什么又是小端存储呢?小端存储就是高地址存高字节,低地址存低字节。
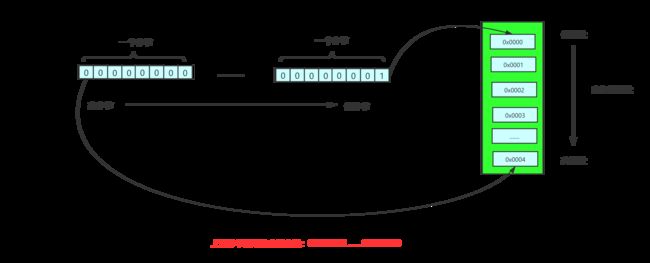
所以小端地址输出的格式是反着的从右到左(反之大端存储输出格式就是符合我们人类阅读习惯的格式),这里只是帮助理解,不深入探究大小端存储问题。
因此之前输出的信息是符合我们上面所说的理论的,接着我们在输出对象头之前获取下hashcode,看看会发生什么,main方法中增加下面这行代码。
System.out.println(Integer.toHexString(l.hashCode()));

可以看到对象头中存储的hashcode和我们输出的hashcode是一致的,同时状态变为了无锁不可偏向(001)。
再来看看加锁之后会有什么变化:
public static void testLock() {
//偏向锁 首选判断是否可偏向 判断是否偏向了 拿到当前的id 通过cas 设置到对象头
synchronized (l) {//t1 locked t2 ctlock
log.debug("name:" + Thread.currentThread().getName());
//有锁 是一把偏向锁
log.debug(ClassLayout.parseInstance(l).toPrintable());
}
}
去掉hashcode方法的调用并调用这个方法,另外还需要关闭偏向延迟-XX:BiasedLockingStartupDelay=0,否则也会直接膨胀为轻量锁。输出结果如下:
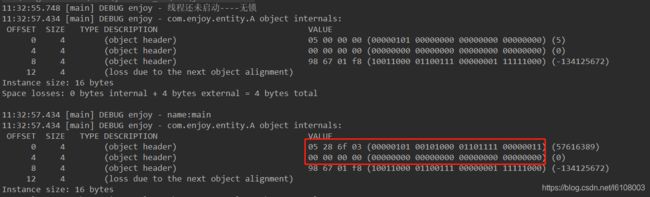
可以看到在获取偏向锁后将线程id存入到了对象头中。
轻量锁
接下来我们看看膨胀为轻量锁的过程,导致膨胀轻量锁的原因主要有以下几点:
- 调用了未重写的hashcode方法
- 开启了偏向延迟(因为我们是短时间执行程序,默认延迟时间是4s中)
- 多线程交替执行
前两点读者可自行打印输出看看,这里主要来看最后一点,使用如下程序(记得关闭偏向延迟):
@Slf4j
public class TestJol {
static A l = new A();
static Thread t1;
static Thread t2;
public static void main(String[] args) throws InterruptedException {
t1 = new Thread() {
@SneakyThrows
@Override
public void run() {
testLock();
Thread.sleep(1000);
testLock();
}
};
t2 = new Thread() {
@SneakyThrows
@Override
public void run() {
Thread.sleep(3000);
testLock();
}
};
t1.setName("t1");
t1.start();
t2.setName("t2");
t2.start();
}
public static void testLock() {
synchronized (l) {
log.debug("name:" + Thread.currentThread().getName());
log.debug(ClassLayout.parseInstance(l).toPrintable());
}
}
}
这里创建了两个线程t1、t2,t1先调用一次testLock方法,然后使用sleep睡眠让出cpu,这时候让t2拿到cpu和锁调用一次,确保t2执行完成后t1再调用一次(注意不要两个线程产生竞争),形成交替执行testLock方法,最终打印如下:
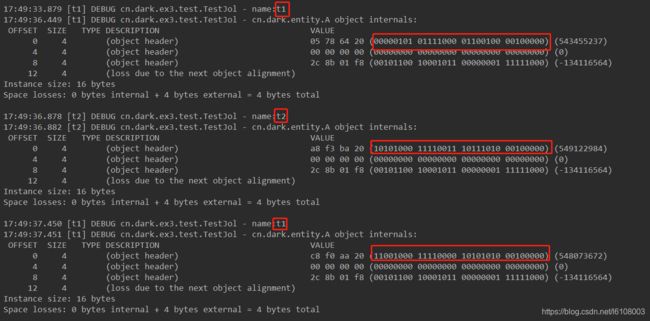
注意t1首先获取到的偏向锁,之后t2打印可以看到升级为轻量级锁,接着t1醒来打印也是获取的轻量级锁(如果发生竞争就会膨胀为重量级锁10),对象头中存储的是Lock Record的地址,和我们猜测相符合。
重量锁
最后去掉上面代码中的两个sleep并删掉t1中的一个调用,这样两个线程就会发生竞争膨胀为重量锁:

可以看到和我们的理论也是相符合的。
总结
本篇是并发系列的第一篇,也是synchronized原理的第一篇,主要分析了锁对象在内存中的布局情况以及锁膨胀的过程,并通过代码验证了所学理论,但synchronized的实现原理是非常复杂的,尤其是优化过后。更深入的内容将在后面的文章中逐步展开,另外读者们可以思考一个问题,synchronized有没有使用自旋锁来优化?
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=37nlwj3o8puso