void Sort::InsertSort( )
{
int i, j, temp;
for (i = 1; i < length; i++)
{
temp = data[i];
for (j = i - 1; j >= 0 && temp < data[j]; j--)
data[j + 1] = data[j];
data[j + 1] = temp;
}
}
分析时间性能:
当最好的情况,也就是要排序的表本身就是有序的,比如数据为:{2,3,4,5,6},那么我们比较次数,其实就是代码中寻找插入位置处,每个data[j]与data[j-1]的比较,共比较了 n − 1 ( ∑ i = 1 n − 1 1 ) n-1(\sum_{i=1}^{n-1}1) n−1(∑i=1n−11)次,由于每次都是data[j]>data[j-1],因此没有移动的记录,时间复杂度为O(n)。
当最坏的情况,即待排序表是逆序的情况,比如{6,5,4,3,2},此时需要比较 ∑ i = 1 n − 1 i = 1 + 2 + 3 + . . . + n − 1 = ( n + 2 ) ( n − 1 ) 2 \sum_{i=1}^{n-1}i=1+2+3+...+n-1=\frac{(n+2)(n-1)}{2} ∑i=1n−1i=1+2+3+...+n−1=2(n+2)(n−1)次,而记录的移动次数也达到最大值 ∑ i = 1 n − 1 ( i + 1 ) = ( n + 4 ) ( n − 1 ) 2 \sum_{i=1}^{n-1}(i+1)=\frac{(n+4)(n-1)}{2} ∑i=1n−1(i+1)=2(n+4)(n−1)次。
如果排序记录是随机的,那么根据概率相同的原则,平均比较和移动次数约为 n 2 4 \frac{n^2}{4} 4n2次。因此,我们得出直接插入排序法的时间复杂度为 O ( n 2 ) O(n^2) O(n2)。从这里也看出,同样的 O ( n 2 ) O(n^2) O(n2)时间复杂度,直接插入排序法比冒泡和简单选择排序的性能要好一些。
8.2.2 希尔排序
希尔排序(Shellsort)是对直接插入排序的一种改进,改进的着眼点是:
①若待排序记录基本有序,直接插入排序的效率很高;
②由于直接插入排序算法简单,则在待排序记录个数较少时效率也很高。
希尔排序的基本思想是:先将整个待排序记录序列分割成若干个子序列,在子序列内分别进行直接插入排序,待整个序列基本有序时,再对全体记录进行一次直接插入排序。
需解决的关键问题是:
①如何分割待排序记录,才能保证整个序列逐步向基本有序发展?
子序列的构成不能是简单地“逐段分割”,而是将相距某个增量的记录组成一个子序列,才能有效地保证在子序列内分别进行直接插入排序后得到的结果是基本有序而不是局部有序。接下来的问题是增量应如何取?到目前为止尚未有人求得一个最好的增量序列。希尔最早提出的方法是 d 1 = n / 2 , d i + 1 = d i / 2 d_1=n/2,d_{i+1}=d_i/2 d1=n/2,di+1=di/2,且增量序列互质,显然最后一个增量必须等手1。开始时增量的取值较大,每个子序列中的记录个数较少,这提供了记录跳跃移动的可能,排序效率较高;后来增量逐步缩小,每个子序列中的记录个数增加,但已基本有序,效率也较高。
②子序列内如何进行直接插入排序?
在每个子序列中,待插入记录和同一子序列中的前一个记录比较,在插入记录data[i]时,自data[i-d]起以幅度d往前跳跃式查找待插入位置,在查找过程中,记录后移也是跳跃d个位置,为了后移记录时避免覆盖待插入记录data[i],将data[i]用temp暂存,当搜索位置j<0或者temp≥data[j],表示插入位置已找到,退出循环。因为data[j]刚刚比较完毕,所以,j+d为正确的插入位置,将带插入记录插入。在整个序列中,记录data[0]~data[d-1]分别是d个子序列的第一个记录,所以从记录data[d]开始进行插入。
希尔排序的关键并不是随便分组后各自排序,而是将相隔某个“增量”的记录组成一个子序列,实现跳跃式的移动,使得排序的效率提高。
这里“增量”的选取就非常关键了,可究竟应该选取什么样的增量才是最好,目前还是一个数学难题,迄今为止还没有人找到一种最好的增量序列。不过大量的研究表明,当增量序列为 d l t a [ k ] = 2 t − k + 1 − 1 ( 0 ≤ k ≤ t ≤ ⌊ l o g 2 ( n + 1 ) ⌋ ) dlta[k]=2^{t-k+1}-1(0≤k≤t≤\left \lfloor log_2(n+1)\right \rfloor) dlta[k]=2t−k+1−1(0≤k≤t≤⌊log2(n+1)⌋)时,可以获得不错的效果,其时间复杂度为 O ( n 3 / 2 ) O(n^{3/2}) O(n3/2),要好于直接排序的 O ( n 2 ) O(n^{2}) O(n2)。需要注意的是,增量序列的最后一个增量值必须等于1才行。另外由于记录是跳跃式的移动,希尔排序并不是一种稳定的排序算法。
8.3 交换排序
8.3.1 起泡排序
起泡排序的基本思想是:两两比较相邻记录的关键码,如果反序则交换,直到没有反序的记录为止。
| 待排序记录序列 |
50 |
13 |
55 |
97 |
27 |
38 |
49 |
65 |
| 第一趟排序结果 |
13 |
50 |
55 |
27 |
38 |
49 |
65 |
97 |
| 第二趟排序结果 |
13 |
50 |
27 |
38 |
49 |
55 |
65 |
97 |
| 第三趟排序结果 |
13 |
27 |
38 |
49 |
50 |
55 |
65 |
97 |
| 第四趟排序结果 |
13 |
27 |
38 |
49 |
50 |
55 |
65 |
97 |
| 需解决的关键问题是: |
|
|
|
|
|
|
|
|
| ①在一趟起泡排序中,若有多个记录位于最终位置,应如何记载? |
|
|
|
|
|
|
|
|
| 如果在某趟起泡排序后有多个记录位于最终位置(例如在上表中第2趟排序结果)下一趟起泡排序中这些记录应该避免重复比较,为此,设变量exchange记载每次记录交换的位置,则一超排序后,exchange记载的一定是这趟排序最后一次交换记录的位置,从此位置之后的所有记录均已经有序。 |
|
|
|
|
|
|
|
|
| ②如何确定一趟起泡排序的范围,使得已经位于最终位置的记录不参与下一趟排序? |
|
|
|
|
|
|
|
|
| 设bound位置的记录是无序区的最后一个记录,则每趟起泡排序的范围是[0~bound]。在一趟排序后,exchange位置之后的记录一定是有序的,所以下一趟起泡排序中无序区的最后一个记录的位置是exchange,即 bound=exchange。 |
|
|
|
|
|
|
|
|
| ③如何判别起泡排序的结束? |
|
|
|
|
|
|
|
|
| 判别起泡排序的结束条件应是在一趟排序过程中没有进行交换记录的操作。为此,在每趟起泡排序开始之前,设exchange的初值为0,在一趟比较完毕,若exchange的值为0,或者该趟没有交换记录,或者只是交换了data[0]和data[1],因此,可以通过exchange的值是否为0来判别整个起泡排序是否结束。 |
|
|
|
|
|
|
|
|
| ④在进入循环之前,exchange的初值应如何设置呢? |
|
|
|
|
|
|
|
|
| 第一趟起泡排序的范围是[0~length-1],所以,exchange的初值应该为length-1。 |
|
|
|
|
|
|
|
|
| 下面给出起泡排序的成员函数定义。 |
|
|
|
|
|
|
|
|
void Sort::BubbleSort( )
{
int j, exchange, bound, temp;
exchange = length - 1;
while (exchange != 0)
{
bound = exchange; exchange = 0;
for (j = 0; j < bound; j++)
if (data[j] > data[j+1]) {
temp = data[j]; data[j] = data[j+1]; data[j+1] = temp;
exchange = j;
}
}
}
分析时间性能:
当最好的情况,也就是要排序的表本身就是有序的,那么我们比较次数,根据最后改进的代码,可以推断出就是length -1次的比较,没有数据交换,时间复杂度为O(n)。
当最坏的情况,即待排序表是逆序的情况,此时需要比较 ∑ i = 1 n − 1 ( n − i ) = n ( n − 1 ) 2 \sum_{i=1}^{n-1}(n-i)=\frac{n(n-1)}{2} ∑i=1n−1(n−i)=2n(n−1)次,并作等数量级的记录移动。因此,复总的时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
8.3.2 快速排序
希尔排序相当于直接插入排序的升级,它们同属于插入排序类,堆排序相当于简单选择排序的升级,它们同属于选择排序类。而快速排序其实就是我们前面认为最慢的冒泡排序的升级,它们都属于交换排序类。即它也是通过不断比较和移动交换来实现排序的,只不过它的实现,增大了记录的比较和移动的距离,将关键字较大的记录从前面直接移动到后面,关键字较小的记录从后面直接移动到前面,从而减少了总的比较次数和移动交换次数。
快速排序(Quick Sort)的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的。快速排序要做的,就是先选取当中的一个关键字,然后想尽办法将它放到一个位置,使得它左边的值都比它小,右边的值比它大,我们将这样的关键字称为枢轴(pivot)。
在快速排序中,需解决的关键问题是:
①如何选择轴值?
②在待排序序列中如何进行划分(通常叫作一次划分)?
③如何处理划分得到的两个待排序子序列?
④如何判别快速排序的结束?
问题①的解决:最简单的方法是选取第一个记录,但是,如果待排序记录是正序或者逆序,就会将除轴值以外的所有记录分到轴值的一边,这是快速排序的最坏情况。还可以在每次划外之前比较待排序序列的第一个记录、最后一个记录和中间记录,选取值居中的记录作为轴值并调换到第一个记录的位置。在下面的讨论中,选取第一个记录作为轴值。
问题②的解决:设待划分记录存储在data[first]~data[last]中,一次划分算法用伪代码描述如下:
算法:Partition(first,last)
输人:待划分的记录序列data[first]~data[last]
输出:轴值的位置
1.设置划分区间:i=first;j=last;
2.重复下述过程,直到i等于j
2.1右侧扫描,直到data[j]小于data[i];将data[j]与data[i]交换,i++;
2.2左侧扫描,直到data[i]大于data[j];将data[i]与data[j]交换,j--;
3.返回i的值;
例子:记录序列{23,13,35,6,19,50,28}
| 待划分记录序列 |
23 |
13 |
35 |
6 |
19 |
50 |
28 |
|
i |
|
|
|
|
|
j |
| 右侧扫描,直到data[j]<23 |
23 |
13 |
35 |
6 |
19 |
50 |
28 |
|
i |
|
|
|
j |
|
|
| data[j]与data[i]交换,i++ |
19 |
13 |
35 |
6 |
23 |
50 |
28 |
|
|
i |
|
|
j |
|
|
| 左侧扫描,直到data[i]>23 |
19 |
13 |
35 |
6 |
23 |
50 |
28 |
|
|
|
i |
|
j |
|
|
| data[j]与data[i]交换,j- - |
19 |
13 |
23 |
6 |
35 |
50 |
28 |
|
|
|
i |
j |
|
|
|
| 右侧扫描,直到data[j]<23,data[j]与data[i]交换,i++,i=j,结束划分 |
19 |
13 |
6 |
23 |
35 |
50 |
28 |
|
|
|
|
ij |
|
|
|
问题③和④的解决:对待排序序列进行一次划分之后,再分别对左右两个子序对进行快速排序,直到每个分区都只有一个记录为止。
快速排序复杂度分析
我们来分析一下快速排序法的性能。快速排序的时间性能取决于快速排序递归的深度,可以用递归树来描述递归算法的执行情况。如下图所示,它是{50,10,90,30,70,40,80,60,20}在快速排序过程中的递归过程。由于我们的第一个关键字是50,正好是待排序的序列的中间值,因此递归树是平衡的,此时性能也比较好。
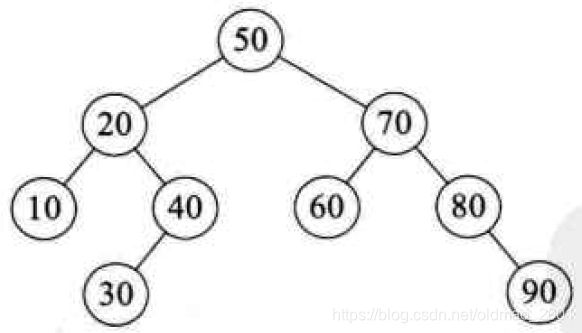
在最优情况下,Partition每次都划分得很均匀,如果排序n个关键字,其递归树的深度就为 ⌊ l o g 2 n ⌋ + 1 \left \lfloor log_2n\right \rfloor+1 ⌊log2n⌋+1,即仅需递归 l o g 2 n log_2n log2n次,需要时间为T(n)的话,第一次Partiation应该是需要对整个数组扫描一遍,做n次比较。
然后,获得的枢轴将数组一分为二,那么各自还需要T(n/2)的时间(注意是最好情况,所以平分两半)。于是不断地划分下去,我们就有了下面的不等式推断。
T ( n ) ≤ 2 T ( n / 2 ) + n , T ( 1 ) = 0 T(n)≤2T(n/2)+n,T(1)=0 T(n)≤2T(n/2)+n,T(1)=0
T ( n ) ≤ 2 ( 2 T ( n / 4 ) + n / 2 ) + n = 4 T ( n / 4 ) + 2 n T(n)≤2(2T(n/4)+n/2)+n=4T(n/4)+2n T(n)≤2(2T(n/4)+n/2)+n=4T(n/4)+2n
T ( n ) ≤ 4 ( 2 T ( n / 8 ) + n / 4 ) + 2 n = 8 T ( n / 8 ) + 3 n T(n)≤4(2T(n/8)+n/4)+2n=8T(n/8)+3n T(n)≤4(2T(n/8)+n/4)+2n=8T(n/8)+3n
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ \cdot\cdot\cdot\cdot\cdot\cdot\cdot ⋅⋅⋅⋅⋅⋅⋅
T ( n ) ≤ n T ( 1 ) + ( l o g 2 n ) × n = O ( n l o g n ) T(n)≤nT(1)+(log_2n)×n=O(nlogn) T(n)≤nT(1)+(log2n)×n=O(nlogn)
也就是说,在最优的情况下,快速排序算法的时间复杂度为O(nlogn)。
在最坏的情况下,待排序的序列为正序或者逆序,每次划分只得到一个比上一次划分少一个记录的子序列,注意另一个为空。如果递归树画出来,它就是一棵斜树。此时需要执行n-1次递归调用,且第i次划分需要经过n-i次关键字的比较才能找到第i个记录,也就是枢轴的位置,因此比较次数为 ∑ i = 1 n − 1 ( n − i ) = n − 1 + n − 2 + … + 1 = n ( n − 1 ) 2 \sum_{i=1}^{n-1}(n-i)=n-1+n-2+…+1=\frac{n(n-1)}{2} ∑i=1n−1(n−i)=n−1+n−2+…+1=2n(n−1),最终其时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
平均的情况,设枢轴的关键字应该在第k的位置(1≤k≤n),那么:
T ( n ) = 1 n ∑ k = 1 n ( T ( k − 1 ) + T ( n − k ) ) + n = 2 n ∑ k = 1 n T ( k ) + n T(n)=\frac{1}{n}\sum_{k=1}^n(T(k-1)+T(n-k))+n=\frac{2}{n}\sum_{k=1}^nT(k)+n T(n)=n1k=1∑n(T(k−1)+T(n−k))+n=n2k=1∑nT(k)+n
由数学归纳法可证明,其数量级为O(nlogn)。
就空间复杂度来说,主要是递归造成的栈空间的使用,最好情况,递归树的深度为 l o g 2 n log_2n log2n,其空间复杂度也就为O(logn),最坏情况,需要进行n-1递归调用,其空间复杂度为O(n),平均情况,空间复杂度也为O(logn)。
可惜的是,由于关键字的比较和交换是跳跃进行的,因此,快速排序是一种不稳定的排序方法。
8.4 选择排序
8.4.1 简单选择排序
简单选择排序是选择排序中最简单的排序方法,其基本思想是:第i趟排序通过n-i次关键码的比较,在n-i+1(1≤i≤n-1)个记录中选取关键码最小的记录,并和第i个记录交换作为有序序列的第i个记录。
在简单选择排序中,需解决的关键问题是:
①如何在待排序序列中选出最小的记录?
设置一个整型变量index,用于记载一趟比较过程中最小记录的位置。将index初始化为当前无序区的第一个位置,然后用data[index]与无序区中其他记录进行比较,如果有比data[index]小的记录,就将index修改为这个新的最小记录的位置,一趟比较结束后,index中保留的就是本趟排序最小记录的位置。
②如何确定待排序序列中最小的记录在有序序列中的位置?
第i趟简单选择排序的待排序区间是data[i]~data[length-1],则data[i]是无序区第一个记录,所以,将记录data[index]与data[i]进行交换。
简单选择排序复杂度分析
从简单选择排序的过程来看,它最大的特点就是交换移动数据次数相当少,这样也就节约了相应的时间。分析它的时间复杂度发现,无论最好最差的情况,其比较次数都是一样的多,第i趟排序需要进行n-i次关键字的比较,此时需要比较 ∑ i = 1 n − 1 ( n − i ) = n − 1 + n − 2 + . . . + 1 = n ( n − 1 ) 2 \sum_{i=1}^{n-1}(n-i)=n-1+n-2+...+1=\frac{n(n-1)}{2} ∑i=1n−1(n−i)=n−1+n−2+...+1=2n(n−1)次。而对于交换次数而言,当最好的时候,交换为0次,最差的时候,也就初始降序时,交换次数为n-1次,基于最终的排序时间是比较与交换的次数总和,因此,总的时间复杂度依然为 O ( n 2 ) O(n^2) O(n2)。
应该说,尽管与冒泡排序同为 O ( n 2 ) O(n^2) O(n2),但简单选择排序的性能上还是要略优于冒泡排序。
8.4.2 堆排序
堆排序改进的着眼点是:如何减少记录的比较次数。
简单选择排序在一趟排序中仅选出最小记录,可惜的是,这样的操作并没有把每一趟的比较结果保存下来,在后一趟的比较中,有许多比较在前一趟已经做过了,但由于前一趟排序时未保存这些比较结果,所以后一趟排序时又重复执行了这些比较操作,因而记录的比较次数较多。如果可以做到每次在选择到最小记录的同时,并根据比较结果对其他记录做出相应的调整,那样排序的总体效率就会非常高了。
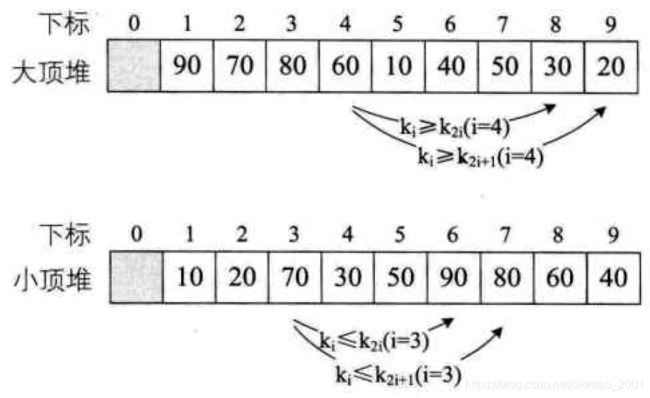
1.堆定义
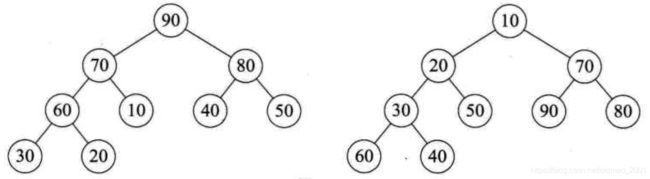
堆是具有下列性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆(例如下图左图所示);或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆(例如下图右图所示)。
如果按照层序遍历的方式给结点从1开始编号,则结点之间满足如下关系:
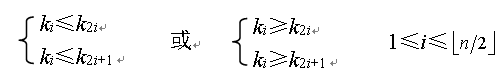
这里为什么i要小于等于ln/2]呢?二叉树的性质5-5-1就是说一棵完全二叉树,如果i=1,则结点i是二叉树的根,无双亲;如果i>1,则其双亲是结点 ⌊ i / 2 ⌋ \left \lfloor i/2\right \rfloor ⌊i/2⌋。那么对于有n个结点的二叉树而言,它的i值自然就是小于等于 ⌊ n / 2 ⌋ \left \lfloor n/2\right \rfloor ⌊n/2⌋了。性质5的第二、三条,也是在说明下标i与2i和2i+1的双亲子女关系。如果完全忘记的同学不妨去复习一下。
如果将上面的大顶堆和小顶堆用层序遍历存入数组,则一定满足上面的关系表达,如下图所示。
2.堆排序
堆排序是基于堆(假设用大根堆)的特性进行排序的方法,其基本思想是:首先将待排序序列调整成一个堆,此时,选出了堆中所有记录的最大者即堆顶记录,然后将堆顶记录移走,并将剩余记录再调整成堆,这样又找出了次大记录,以此类推,直到堆中只有一个记录。
在堆排序中,需解决的关键问题是:
①如何将待排序序列调整成一个堆(即初始建堆)?
初始建堆的过程就是反复调用堆调整的过程。因为序列对应完全二叉树的顺序存储,所有叶子结点都已经是堆,只需从最后一个分支结点到根结点,执行堆调整。
②如何处理堆顶记录?
初始建堆后,将待排序序列分成无序区和有序区两部分,其中,无序区对应一个大根堆,且包括全部待排序记录,有序区为空。将堆顶与堆中最后一个记录交换,则堆中减少了一个记录,有序区增加了一个记录。一般情况下,第i趟(1≤i≤length-1)堆排序对应的堆中最后一个记录是data[length-i],将data[0]与data[length-i]相交换。
③如何调整剩余记录,成为一个新的堆(即重建堆)?
第i趟(1≤i≤length-1)排序后,无序区有length-i个记录,在无序区对应的完全二叉树中,只需调整根结点即可重新建堆。
3.堆排序复杂度分析
堆排序的运行时间主要是消耗在初始构建堆和在重建堆时的反复筛选上。
在构建堆的过程中,因为我们是完全二叉树从最下层最右边的非终端结点开始构建,将它与其孩子进行比较和若有必要的互换,对于每个非终端结点来说,其实最多进行两次比较和互换操作,因此整个构建堆的时间复杂度为O(n)。
在正式排序时,第i次取堆顶记录重建堆需要用O(logi)的时间(完全二叉树的某个结点到根结点的距离为 ⌊ l o g 2 i ⌋ + 1 \left \lfloor log_2i\right \rfloor+1 ⌊log2i⌋+1),并且需要取n-1次堆顶记录,因此,重建堆的时间复杂度为O(nlogn)。
所以总体来说,堆排序的时间复杂度为O(nlogn)。由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn)。这在性能上显然要远远好过于冒泡、简单选择、直接插入的 O ( n 2 ) O(n^2) O(n2)的时间复杂度了。
空间复杂度上,它只有一个用来交换的暂存单元,也非常的不错。不过由于记录的比较与交换是跳跃式进行,因此堆排序也是一种不稳定的排序方法。
另外,由于初始构建堆所需的比较次数较多,因此,它并不适合待排序序列个数较少的情况。
8.5 归并排序
归并一词的中文含义就是合并、并入的意思,而在数据结构中的定义是将两个或两个以上的有序表组合成一个新的有序表。
归并排序(Merging Sort)就是利用归并的思想实现的排序方法。它的原理是假设初始序列含有n个记录,则可以看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到 ⌈ n / 2 ⌉ \left \lceil n/2\right \rceil ⌈n/2⌉个长度为2或1的有序子序列;再两两归并,……,如此重复,直至得到一个长度为n的有序序列为止,这种排序方法称为2路归并排序。
二路归并排序的递归算法
首先将待排序的记录序列分为两个相等的子序列,分别将这两个子序列进行排序,然后调用一次归并算法Merge,将这两个有序子序列合并成一个含有全部记录的有序序列。下图给出了一个用递归方法进行归并排序的例子:

void Sort::Merge(int first1, int last1, int last2)
{
int *temp = new int[length];
int i = first1, j = last1 + 1, k = first1;
while (i <= last1 && j <= last2)
{
if (data[i] <= data[j])
temp[k++] = data[i++];
else
temp[k++] = data[j++];
}
while (i <= last1)
temp[k++] = data[i++];
while (j <= last2)
temp[k++] = data[j++];
for (i = first1; i <= last2; i++)
data[i] = temp[i];
delete[ ] temp;
}
void Sort::MergeSort1(int first, int last)
{
if (first == last)
return;
else {
int mid = (first + last)/2;
MergeSort1(first, mid);
MergeSort1(mid+1, last);
Merge(first, mid, last);
}
}
二路归并排序非递归算法
需要解决的关键问题:
(1)如何构造初始有序序列?
假设待排序序列中含有n个记录,则将整个序列看成是长度为1的n个有序序列
(2)如何将两个相邻的有序序列归并成一个有序序列(一次归并)?
设两个相邻的有序序列为r[s]~r[m]和r[m+1] ~r[t],将两个有序序列归并成一个有序序列r1[s] ~r1[t]
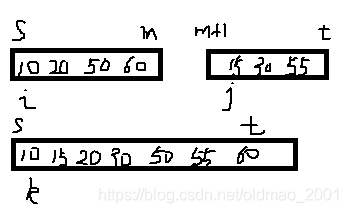
设置三个参数i,j,k分别指向两个待归并的有序序列和最终有序序列的当前记录,然后比较i和j所指记录的关键码,取较小者作为归并结果存入k所指位置,直至两个有序序列之一 所有记录都取完,再将另外一个有序序列的剩余记录送到归并后的有序序列中。
(3)如何才能完成一趟归并?
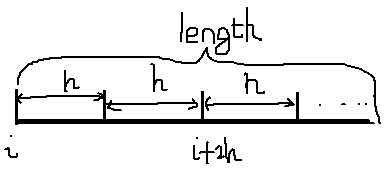
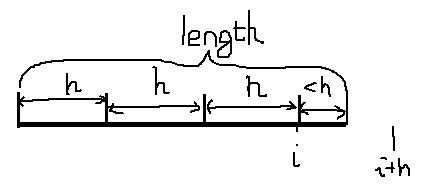
在一趟归并中,除最后一个有序序列外,其他有序序列中记录的个数(或称为序列的长度)相同,用h表示。现在的任务是把若干个相邻的长度为h的有序序列和最后一个长度有可能小于h的有序序列进行两两合并,将结果放到temp[length]中,为此,设参数i指向待归并的第一条记录,初始时,i=0,合并的步长为2h,在归并过程中,有以下三种情况:
若i+2h≤length,表示待合并的两个相邻有序子序列长度均为h,如下图所示,执行一次合并,完成后i加2h,准备进行下一次合并:
若i+h<length,则表示仍有两个相邻有序子序列,一个长度为h,一个长度小于h,则执行这两个有序序列的合并,完成后退出一趟归并。
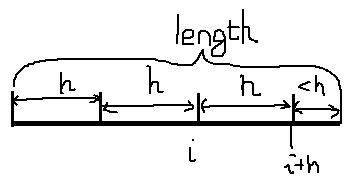
若i+h≥length,则表明只剩下一个有序序列,不用合并(为什么?)。
(4)如何控制二路归并的结束?
开始时,有序子序列长度为1,结束时,有序子序列长度为length,可以用有序子序列长度来控制排序过程的结束。
算法分析
一趟归并将r[1]~ r[n]中相邻的长度为h的有序序列进行两两归并,结果保存到r1[1]~ r1[n]中,这需要将待排序序列中所有记录扫描一遍,因此耗时O(n)。整个归并排序需要进行 ⌈ l o g 2 n ⌉ \left \lceil log_2n\right \rceil ⌈log2n⌉趟,因此,总的时间代价是 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n),最好最坏平均的时间性能都一样。
二路归并排序在归并过程中需要与原始记录序列相同数量的存储空间,以便存放归并结果,因此空间复杂度为O(n)。
二路归并排序是一种稳定的排序方法。
8.6 各种排序方法的比较
排序方法的选用应该根据具体情况而定,一般应该从以下几个方面综合考虑:
⑴ 时间复杂性;
⑵ 空间复杂性;
⑶ 稳定性;
⑷ 算法简单性;
⑸ 待排序记录个数n的大小;
⑹ 记录本身信息量的大小;
⑺ 关键码的分布情况。
1. 时间复杂性
前面所述各种内排序的时间和空间性能的比较结果如下表所示。
| 排序方法 |
平均情况 |
最好情况 |
最坏情况 |
辅助空间 |
| 直接插入排序 |
O ( n 2 ) O(n^2) O(n2) |
O ( n ) O(n) O(n) |
O ( n 2 ) O(n^2) O(n2) |
O ( 1 ) O(1) O(1) |
| 希尔排序 |
O ( n l o g 2 n ) ∼ O ( n 2 ) O(nlog_2n)\sim O(n^2) O(nlog2n)∼O(n2) |
O ( n 1.3 ) O(n^{1.3}) O(n1.3) |
O ( n 2 ) O(n^2) O(n2) |
O ( 1 ) O(1) O(1) |
| 起泡排序 |
O ( n 2 ) O(n^2) O(n2) |
O ( n ) O(n) O(n) |
O ( n 2 ) O(n^2) O(n2) |
O ( 1 ) O(1) O(1) |
| 快速排序 |
O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) |
O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) |
O ( n 2 ) O(n^2) O(n2) |
O ( n l o g 2 n ) ∼ O ( n ) O(nlog_2n)\sim O(n) O(nlog2n)∼O(n) |
| 简单选择排序 |
O ( n 2 ) O(n^2) O(n2) |
O ( n 2 ) O(n^2) O(n2) |
O ( n 2 ) O(n^2) O(n2) |
O ( 1 ) O(1) O(1) |
| 堆排序 |
O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) |
O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) |
O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) |
O ( 1 ) O(1) O(1) |
| 归并排序 |
O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) |
O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) |
O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) |
O ( n ) O(n) O(n) |
2. 空间复杂性
从空间复杂性看,所有排序方法分为三类:
·归并排序单独属于一类,其空间复杂性为 O ( n ) O(n) O(n);
·快速排序单独属于一类,其空间复杂性为 O ( n l o g 2 n ) ∼ O ( n ) O(nlog_2n)\sim O(n) O(nlog2n)∼O(n);
·其它排序方法归为一类,其空间复杂性为 O ( 1 ) O(1) O(1)。
3. 稳定性
所有排序方法可分为两类,一类是稳定的,包括直接插入排序、起泡排序、简单选择排序和归并排序;
另一类是不稳定的,包括希尔排序、快速排序和堆排序。
4. 算法简单性
从算法简单性看,一类是简单算法,包括直接插入排序、简单选择排序和起泡排序;
另一类是改进算法,包括希尔排序、堆排序、快速排序和归并排序,这些算法都很复杂。
5. 待排序的记录个数n的大小
从待排序的记录个数n的大小看,n越小,采用简单排序方法越合适。
6. 记录本身信息量的大小
记录本身信息量越大,移动记录所花费的时间就越多,所以对记录的移动次数较多的算法不利。三种简单排序算法中记录的移动次数的比较下表所示:
| 排序方法 |
最好情况 |
最坏情况 |
平均情况 |
| 直接插入排序 |
O ( n ) O(n) O(n) |
O ( n 2 ) O(n^2) O(n2) |
O ( n 2 ) O(n^2) O(n2) |
| 起泡排序 |
0 |
O ( n 2 ) O(n^2) O(n2) |
O ( n 2 ) O(n^2) O(n2) |
| 简单选择排序 |
0 |
O ( n ) O(n) O(n) |
O ( n ) O(n) O(n) |
7. 关键码的分布情况
当待排序记录序列为正序时,直接插入排序和起泡排序能达到 O ( n ) O(n) O(n)的时间复杂度;
对于快速排序而言,这是最坏的情况,此时的时间性能蜕化为 O ( n 2 ) O(n^2) O(n2);
简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键码的分布而改变。