华为云hadoop伪分布式安装学习笔记(一)

所属专栏:【大数据学习笔记(华为云)】
作 者:我是夜阑的狗
个人简介:一个正在努力学技术的码仔,专注基础和实战分享 ,欢迎咨询!
欢迎大家:这里是CSDN,我总结知识的地方,喜欢的话请三连,有问题请私信
文章目录
- 前言
- 1. 购买云ECS主机
- 2. 开发环境
-
- step1 创建hadoop用户
- step2 更新apt
- step3 安装最新版本的Java
- step4 配置SSH无密码登陆节点
- 3. 安装Hadoop
-
- step1 下载
- step2 解压
- step3 配置Hadoop环境
- 4. Hadoop集群
-
- step1 $JAVA_HOME配置
- step2 core-site.xml配置
- step3 hdfs-site.xml配置
- step4 mapred-site.xml配置
- step5 yarn-site.xml配置
- step6 启动结点
- step7 结束结点
- 5.总结
前言
大家好,又见面了,我是夜阑的狗,本文是专栏【大数据学习笔记(华为云)】专栏的第1篇文章,主要讲解是华为云hadoop伪分布式的安装。
专栏地址:【大数据学习笔记(华为云)】, 此专栏是我是夜阑的狗对华为云hadoop的使用,希望能够加深自己的印象,以及帮助到其他的小伙伴。
如果文章有什么需要改进的地方还请大佬不吝赐教。
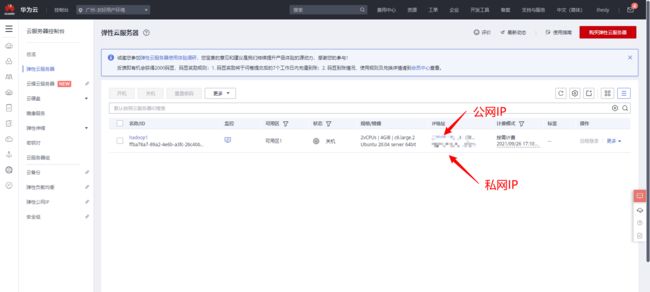
1. 购买云ECS主机
这里购买华为云ECS主机: 华为云购买链接.
2. 开发环境
-
step1 创建hadoop用户
购买好华为云服务器之后,这里用putty对云服务器进行连接
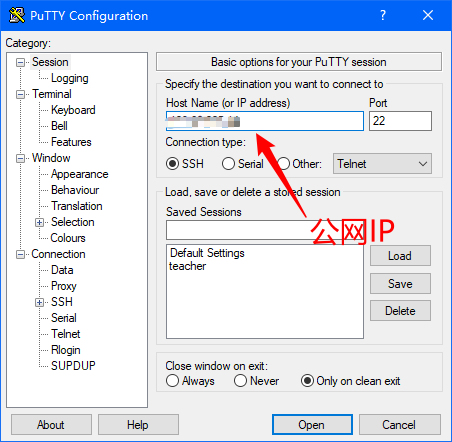
创建用户:
sudo useradd -m hadoop -s /bin/bash

设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop

hadoop 用户增加管理员权限,方便部署:
sudo adduser hadoop sudo

用hadoop用户登录
su - hadoop #切换当前用户为用户hadoop

-
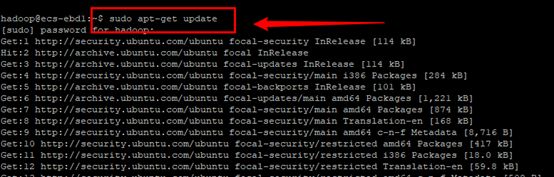
step2 更新apt
由于Ubuntu的一些特性,需要随时更新一下apt,不然有时候软件安装不了
sudo apt-get update
-
step3 安装最新版本的Java
更新软件列表
sudo apt-get update
安装 openjdk-8-jdk
sudo apt-get install openjdk-8-jdk

查看Java版本,如下:
java -version

安装好 OpenJDK 后,需要找到相应的安装路径
update-alternatives --config java

我们输出的路径为
/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
其中,绝对路径为
/usr/lib/jvm/java-8-openjdk-amd64
接着配置 JAVA_HOME 环境变量,为方便,我们在 ~/.bashrc 中进行设置
sudo vi /etc/profile 在文件最前面添加如下单独一行(注意 = 号前后不能有空格),将“JDK安装路径”改为绝对路径,并保存:

export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

让该环境变量生效
source /etc/profile

设置好后我们来检验一下是否设置正确:
echo $JAVA_HOME # 检验变量值
java -version
$JAVA_HOME/bin/java -version # 与直接执行 java -version 一样

-
step4 配置SSH无密码登陆节点
现在检查您是否可以在没有密码的情况下通过 ssh 连接到本地主机:
$ ssh localhost
如果没有密码就无法 ssh 到 localhost,请执行以下命令:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
3. 安装Hadoop
-
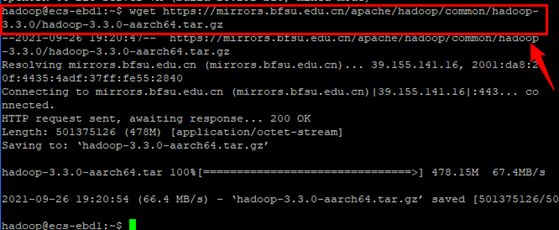
step1 下载
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0-aarch64.tar.gz
-
step2 解压
sudo tar -zxvf hadoop-3.3.0-aarch64.tar.gz -C /usr/local/
cd /usr/local
sudo mv hadoop-3.3.0 hadoop #重命名为hadoop
sudo chown -R hadoop ./hadoop #修改文件权限


-
step3 配置Hadoop环境
给hadoop配置环境变量,将下面代码添加到.bashrc文件:

export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
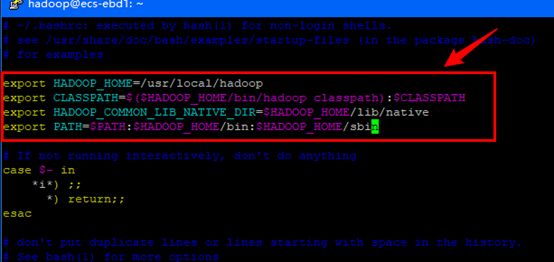
同样,执行source ~/.bashrc使设置生效,并查看hadoop是否安装成功
source ~/.bashrc

4. Hadoop集群
-
step1 $JAVA_HOME配置
hadoop-env.sh和yarn-env.sh两个文件
-
step2 core-site.xml配置
etc/hadoop/core-site.xml:

fs.defaultFS
hdfs://localhost:9000

-
step3 hdfs-site.xml配置
etc/hadoop/hdfs-site.xml:

注意:这里xxx可以填写localhost
dfs.namenode.secondary.http-address
xxx:9001
dfs.replication
2
dfs.webhdfs.enabled
true

-
step4 mapred-site.xml配置
etc/hadoop/mapred-site.xml:

注意:这里xxx可以填写localhost
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
xxx:10020
mapreduce.jobhistory.webapp.address
xxx:19888

-
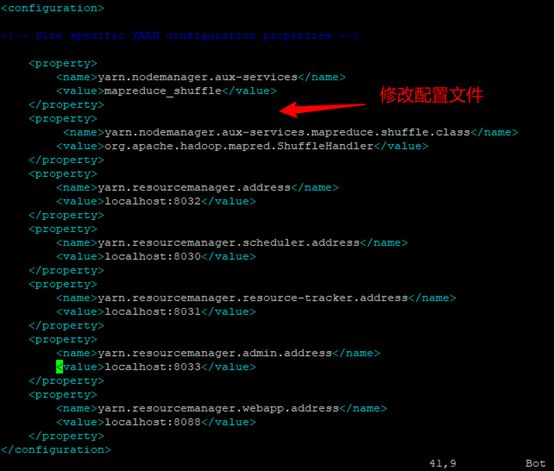
step5 yarn-site.xml配置
etc/hadoop/yarn-site.xml:
注意:这里xxx可以填写localhost
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
xxx:8032
yarn.resourcemanager.scheduler.address
xxx:8030
yarn.resourcemanager.resource-tracker.address
xxx:8031
yarn.resourcemanager.admin.address
xxx:8033
yarn.resourcemanager.webapp.address
xxx:8088
-
step6 启动结点
start-all.sh
浏览Web界面 - http://localhost:9870/
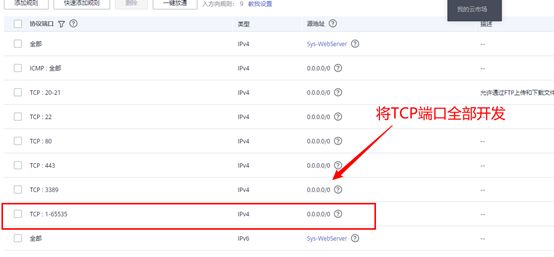
遇到问题:结点挂载上去了,但是web页面访问不了
解决方法:本人使用的华为云,需要在华为云控制台修改一下安全组,把hadoop要用TCP协议的端口添加进去,这里我把全部端口进行设置开放。
访问结果:

-
step7 结束结点
sbin/stop-all.sh
5.总结
感谢观看,如果有帮助到你,请给文章点个赞和收藏,让更多的人看到。
也欢迎你,关注我。
原创不易,还希望各位大佬支持一下,你们的点赞、收藏和留言对我真的很重要!!! 最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
更多专栏订阅:
- 【LeetCode题解(持续更新中)】
- 【Java Web项目构建过程】
- 【数字图像处理】
- ⚽ 【JavaScript随手笔记】
- 【大数据学习笔记(华为云)】
- 【程序错误解决方法(建议收藏)】
- 【软件安装教程】
订阅更多,你们将会看到更多的优质内容!!