抛弃注意力,比EfficientNet快3.5倍,类Transformer新模型跨界视觉任务实现新SOTA

本文经机器之心(almosthuman2014)授权转载,禁止二次转载.
选自OpenReview
机器之心编译
机器之心编辑部
Transformer 用在图像识别上会存在计算效率过低的挑战,最近一篇向 ICLR 2021 大会提交的论文似乎很好地解决了这一问题,其研究的 PyTorch 代码也已在 GitHub 上开源。
在自然语言处理领域(NLP)成为重要力量的 Transformer 技术最近已经开始在计算机视觉领域展现自己的实力。不过到目前为止,由于 Transformer 注意力机制对内存的需求是输入图像的二次方,所以这一方向还存在一些挑战。
近日,LambdaNetworks 的出现提供了一种解决此问题的方法,人们可以无需建立昂贵的注意力图即可捕捉长距离交互。这一方法在 ImageNet 上达到了新的业界最佳水平(state-of-the-art)。

论文链接:https://openreview.net/pdf?id=xTJEN-ggl1b
GitHub链接:https://github.com/lucidrains/lambda-networks
对长程交互进行建模在机器学习中至关重要。注意力已成为捕获长程交互的一种常用范式。但是,自注意力二次方式的内存占用已经阻碍了其对长序列或多维输入(例如包含数万个像素的图像)的适用性。例如,将单个多头注意力层应用于一批 256 个64x64 (8 头)输入图像需要32GB的内存,这在实践中是不允许的。
该研究提出了一种名为「lambda」的层,这些层提供了一种捕获输入和一组结构化上下文元素之间长程交互的通用框架。
lambda 层将可用上下文转换为单个线性函数(lambdas)。这些函数直接单独应用于每个输入。研究者认为,lambda 层可以作为注意力机制的自然替代。注意力定义了输入元素和上下文元素之间的相似性核,而 lambda 层将上下文信息汇总为固定大小的线性函数,从而避免了对内存消耗大的注意力图的需求。这种对比如图1所示。
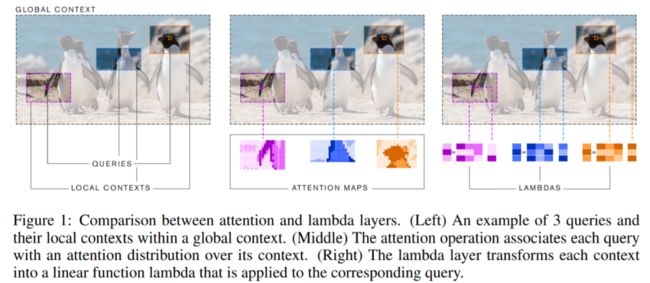
研究者证明了 lambda 层的通用性,展示了它们的实现可以被用来捕获全局、局部或掩模上下文中基于内容和位置的交互。利用lambda生成的神经网络 LambdaNetwork 计算效率很高,能够以很小的内存成本建模长程依赖,因而可用于高分辨率图像等大型结构化输入。
研究者在计算机视觉任务上评估了 LambdaNetwork,在这些任务上,自注意力显示出了希望,但遇到了内存成本高昂和无法实际实现的问题。在 ImageNet 分类、COCO 目标检测和实例分割三方面的对照实验表明,LambdaNetwork 显著优于基于卷积和注意力的同类方法,并且计算效率更高、运行速度更快。
最后,研究者提出了 LambdaResNets,它显著改善了图像分类模型的速度-准确性权衡。具体而言,LambdaResNets 在实现 SOTA ImageNet 准确性的同时,运行速度是 EfficientNets 的4.5 倍左右。
建模长程交互
在论文第二章开头,研究者定义了查询、上下文和交互等概念及各种用到的符号,此处不做赘述。
注意力交互。首先缩小查询深度,创建查询和上下文元素之间的相似性核(注意力图),也就是所谓的注意力操作。该机制可以被看作激发查询、键和数值术语的可微内存的寻址。由于上下文位置 |m| 的数量越来越大,并且输入和输出维数 |k| 和 |v| 保持不变,所以在层输出是较小维数 |v| << |m| 的一个向量时,我们可以假设计算注意力图是不划算的。
相反, 由于 y_n = F((q_n, n), C) = λ(C, n)(q_n) 拟合一些线性函数 λ(C, n),所以通过线性函数将每个查询映射到输出可能更有效率。在这种场景下,上下文聚合到一个固定大小的线性函数 λ_n = λ(C, n)。每个 λ_n作为独立于上下文(计算后)存在的小的线性函数,并在应用于关联查询q_n之后被丢弃。该机制令人联想到与lambda这个术语相关的函数式编程和 λ 演算。
lambda层
lambda层将输入 ![]() 和上下文
和上下文  作为输入,生成线性函数lambdas,然后将其应用于查询,从而得到输出
作为输入,生成线性函数lambdas,然后将其应用于查询,从而得到输出 ![]() 。
。
注意,在自注意力情况下可能有C=X。在不失一般性的前提下,研究者假设d_in=d_c=d_out=d。在论文的其他部分中,研究者将重点放在lambda层的特定实例上,并说明它可以在没有注意力图的情况下,处理密集的长程内容和基于位置的交互。
lambda层:将上下文转换成线性函数
研究者首先在(q_n,n)的上下文中描述lambda层。由于研究者希望生成一个线性函数  或将
或将  矩阵当作函数。
矩阵当作函数。
表1给出了lambda层的超参数、参数等量化数值。

1. 生成上下文lambda函数
lambda层首先通过线性投影上下文来计算键和值,通过softmax运算对键进行归一化,从而得到归一化键![]() 。
。
这种实现能可以看作是函数消息传递的一种形式,每个上下文元素都贡献一个内容函数 和一个位置函数
和一个位置函数  。λ_n 是通过将上下文贡献求和得到的,如下所示:
。λ_n 是通过将上下文贡献求和得到的,如下所示:

其中还定义了内容lambda λ^c和位置lambda λ^p_n。内容lambda λ^c对于上下文元素的排列组合是固定不变的,在所有的查询位置n上共享,并且对如何转换仅基于上下文内容的查询内容q_n进行编码。相比之下,位置lambda λ^p_n对如何根据内容c_m和位置(n, m)转换查询内容q_n,从而可以对诸如图像之类的结构化输入进行建模。
2. 将lambda应用于查询
将输入x_n转换为查询 ![]() ,然后获得lambda层的输出为
,然后获得lambda层的输出为
![]()
3. lambda解释
 矩阵的列可以看作是|k|x|v|维的上下文特征的固定大小集合。这些上下文特征是根据上下文的内容和结构汇总得出的。利用lambda线性函数动态分配这些上下文特征,以产生输出
矩阵的列可以看作是|k|x|v|维的上下文特征的固定大小集合。这些上下文特征是根据上下文的内容和结构汇总得出的。利用lambda线性函数动态分配这些上下文特征,以产生输出  。
。
此过程可以捕获密集内容和基于位置的长程交互,同时不产生注意力图。
4. 归一化
可修改方程式1和2以涵盖非线性或归一化运算。该研究的实验表明,在计算查询和值之后应用批归一化是很有用的。
带有结构化上下文的 lambda 层
这一部分介绍了如何使 lambda 层适应结构化的上下文,如相关上下文和局部上下文。
1. 平移等变性
在很多学习情景中,平移等变性是一种很强的归纳偏置。基于内容的交互是置换等变的,因此它已经具备平移等变性。对于任意的平移 t,研究者通过确保位置嵌入满足 ![]() 。在位置交互中得到平移不变性。在实践中,研究者定义了相对位置嵌入
。在位置交互中得到平移不变性。在实践中,研究者定义了相对位置嵌入 ![]() 的一个张量。其中,r 表示所有 (n, m) 对的可能相对位置,并将其重新索引到
的一个张量。其中,r 表示所有 (n, m) 对的可能相对位置,并将其重新索引到 ![]() ,从而使得
,从而使得 ![]() 。
。
2. Lambda 卷积
尽管长程交互有一定的优点,但在很多任务中,局部性依然是一种强大的归纳偏置。从计算的角度来看,使用全局上下文可能会增加噪声,增加算力消耗。因此,将位置交互的范围限制到查询位置 n 周围的一个局部邻域,就像局部自注意和卷积中那样,可能是一种有用的做法。这可以通过对所需范围之外的上下文位置 m 的位置嵌入进行归零来实现。但是,对于较大的 |m| 值,这种策略依然代价高昂,因为计算仍在进行。
在这种上下文被安排在多维网格上的情况下,可以使用一个将 V 中的第 v 维视为一个额外空间维度的常规卷积来从局部上下文中生成位置 lambda。例如,假设我们想在一维序列上生成局部范围大小为 |r| 的位置 lambdas。相对位置嵌入张量 ![]() 可以变为
可以变为 ![]() ,然后被用作一个二维卷积的卷积核,计算所需的位置 lambda
,然后被用作一个二维卷积的卷积核,计算所需的位置 lambda
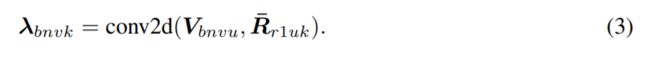
研究者将这个运算称为 lambda 卷积。由于现在的计算被限制在局部范围内,lambda 卷积可以得到与输入长度相关的线性时间和内存复杂度。lambda 卷积很容易用于 dilation 和 striding 等其他功能,并且在专用硬件加速器上享有高度优化的实现。这与局部自注意力的实现形成鲜明对比,后者需要物化重叠查询和内存块的特征块,从而增加了内存消耗和延迟(见下表4)。

利用多查询 lambda 降低复杂度
对于多个 |b| 元素,每个都包含 |n| 输入。应用 lambda 层所需算数运算和内存占用的数量分别为 Θ(bnmkv) 和 Θ(bnkv + knm)。由于E_nm 参数捕获了基于位置的交互 ,因此相对于输入长度,研究者拥有的内存占用仍是二次的。但是,这个二次项并不随批大小扩展,这与生成每个示例(per-example)注意力图谱的注意力操作一样。在实践中,超参数 |k| 设为很小的值,如 |k| =16,并且在注意力失效的情况下可以处理大批量的大型输入。
多查询 lambdas 可以降低复杂度。lambdas 将注意力图 q_n ∈ R^k映射到输出 y_n ∈ R^d。如公式2所示,这意味着 |v|=d。所以,|v| 的较小值成为了特征向量 y_n上的瓶颈,但考虑到 Θ(bnmkv) 和 Θ(bnkv + knm) 的时间和空间复杂度,更大的输入维数 |v| 将导致非常高昂的计算成本。
所以,研究者提出将 lambda 层的时间和空间复杂度从输出维数 d 中解耦。他们并没有强制地令 |v|=d,而是创建了 |h| 查询 {q^h _n},将相同的 lambda 函数 λ_n 应用到每个查询 q^h_n,并将输出串连接成 y_n=concat(λ_nq^1_n , · · · ,λ_nq^|h|_n )。
由于每个 lambda 都应用于 |h| 查询,所以研究者将这一操作当做多查询 lambda 层。这也可以理解为将 lambda 约束到具有 |h| 等重复块的更小块矩阵。现在d=|hv|,并且时间和空间复杂度变成了 Θ(bnmkd/h) 和 Θ(bnkd/h + knm)。此外,研究者注意到,这类似于多头或多查询注意力机制,但motivation不同。在注意力操作中使用多个查询增强了表示能力和复杂度。而在本研究中,使用多查询 lambdas 降低了复杂度和表示能力。
下表2比较了多查询 lambda 层和多头注意力操作的时间和空间复杂度:

批量多查询 lambda 层可以使用 einsum 实现高效执行,具体如下

局部位置的 lambdas 可以通过 lambdas 卷积来获得,具体如上文公式3所示。
实验
LambdaNetworks 优于基于卷积和注意力的同类方法
在下表 3 中,研究者进行了控制实验,以比较 LambdaNetworks 与 a)基线 ResNet50、b)通道注意力和 c)以往使用自注意力来补充或替换 ResNet50 中的 3x3 卷积的研究方法。结果显示,在参数成本仅为其他方法一小部分的情况下,lambda 层显著优于这些方法,并且相较于 Squeeze-and-Excitation(通道注意力)实现了 +0.8% 的提升。

在上表 4 中,研究者对比了 lambda 层和自注意力机制,并给出了它们的吞吐量、内存复杂度和 ImageNet 图像识别准确性比较,这一结果展示了注意力机制的不足。相比之下,lambda 层可以捕获高分辨率图像上的全局交互,并可以比局部自注意力机制获得多 1.0% 的提升,同时运行速度几乎是后者的 3 倍。
此外,位置嵌入也可以在 lambda 层之间共享,以最小的降级花费进一步降低了内存使用的需求。最后,lambda 卷积具有线性内存复杂度,这在图像检测和分割任务中遇到非常大的图片时非常有用。
LambdaResNets 明显改善了 ImageNet 分类任务的速度-准确性权衡
下图 2 展示了 LambdaResNets与使用或不使用 channel attention 机制的ResNet 及最流行的 EfficientNets 相比的效果。LambdaResNets 在所有深度和图像尺度上均优于基准水平,最大的 LambdaResNet 实现了 SOTA 水平准确度 84.8。更值得注意的是,LambdaResNets 在准确性一定的情况下比 EfficientNets 要快大概 3.5 倍,速度-准确性曲线提升明显。

计算效率
在下表5和表6中,研究者发现构造 LambdaResNets 来提升大型 EfficientNets 的参数和 flops 效率也是有可能的。


这样的结果表明,lambda层可能非常适合在资源有限的场景中使用,例如嵌入式视觉应用。
目标检测与实例分割
最后,研究人员评估了 LambdaResNets 使用 Mask-RCNN 架构在 COCO 数据集上进行目标检测和实力分割任务的效果。使用 lambda 层会在所有 IoU 阈值和所有对象比例(尤其是难以定位的小对象)上产生一致的增益,这表明 lambda 层容易在需要定位信息的更复杂的视觉任务中实现不错的效果。
END

备注:CV

计算机视觉交流群
扫码备注拉你入群。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 