nodejs写接口测试浏览器请求304缓存
1 概念和作用
顾名思义 是浏览器将数据暂时缓存在某一位置的方式;
作用:优化浏览器端用户体验的性能;缓存策略是在服务器端设置
通过浏览器缓存策略可以把从服务器请求的数据缓存在浏览器端;再次请求相同数据,不用发送http请求去服务器端获取数据,第一节省带宽,第二能提高用户体验。
对概念的消化必须建立在实际应用之上;杜绝似懂非懂。所以先用nodejs写几个接口进行测试,一睹为快,更有利于理解概念;
2 一睹为快:nodejs写restful缓存接口演示
2.1 新建一个api_cache.js
,然后在它的同目录执行 node api_cache.js即可(需要安装nodejs环境)
不需要安装别的包,全部使用nodejs内置包实现api 接口;下面代码,我们定义三个请求,一个返回js文件,一个返回图片,一个返回json数据。
// 协商缓存
const http = require('http')
const fs = require('fs')
var path = require('path');
let img = fs.readFileSync('./1.png');
http.createServer(function (request, response) {
// image
if (request.url === '/img/1') {
response.writeHead(200, {
'Content-Type': 'image/png',
});
response.end(img);
}
// script.js
if (request.url === '/script.js') {
response.writeHead(200, {
'Content-Type': 'text/javascript'
})
response.end("");
}
// 普通get请求
if (request.url === '/china') {
var file = path.join(__dirname, 'china.geojson');
fs.readFile(file, 'utf-8', function (err, data) {
response.writeHead(200,{
'Content-Type': 'application/json'
})
response.end(data);
})
}
}).listen(3000)
console.log("接口服务成功启动在3000接口");
启动接口如下:

2.2 新建一个test.html,调用我们的接口
1.png.script.js和china.json,这三个文件可以自己新建,geojson数据可以在geojson.io上获取;
2.3 启动网页查看请求
vscode有个扩展 open with in live server,可以用方式的端口启动,安装后,右键html文件即可。



可以看到会出现跨域错误,浏览器因为同源策略会跨域,需要我们在nodejs脚本加上跨域请求头,允许跨域即可;因为服务器不存在跨域,所以只要服务器端开启跨域,ip不同还是可以访问的。但是不同服务器必须满足同源策略。
在json接口的请求头部分,加上跨域请求参数如下
response.writeHead(200,{
'Content-Type': 'application/json',
'Access-Control-Allow-Origin':'*',
'Access-Control-Allow-Methods':'PUT,POST,GET,DELETE,OPTIONS',
})然后重启接口,刷新页面,请求全部成功

题外话:我们工作中可以不做后端,但不能不懂。因为从工作以后发现,前后端分离合作的沟通问题以及解决问题的效率 远没有自己做全栈快;因为出了问题需要联调,但是不能过多干涉后端,更不知道他是不是犯了低级的错误,所以如果一个前端能够深刻理解后端很多逻辑,那么定位到问题也可以跟后端协商解决。
3 认识缓存策略概念
首先我们看下未加任何缓存策略的请求network,如下

然后在三个请求的头部分别加入缓存配置参数 'Cache-Control': 'max-age=200'.如下
response.writeHead(200, {
'Content-Type': 'image/png',
'Cache-Control': 'max-age=200' // 浏览器缓存时间,单位是秒
});
response.writeHead(200, {
'Content-Type': 'text/javascript',
'Cache-Control': 'max-age=200'
})
response.writeHead(200,{
'Content-Type': 'application/json',
'Access-Control-Allow-Origin':'*',
'Access-Control-Allow-Methods':'PUT,POST,GET,DELETE,OPTIONS',
'Cache-Control': 'max-age=200' // 浏览器缓存时间,单位是秒
})再次看请求如下:
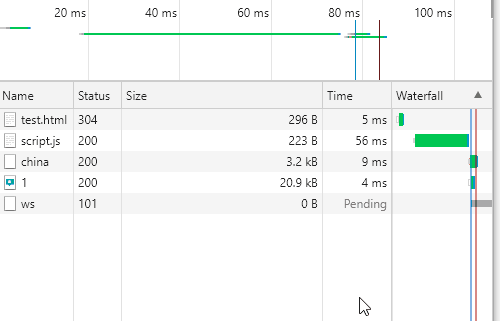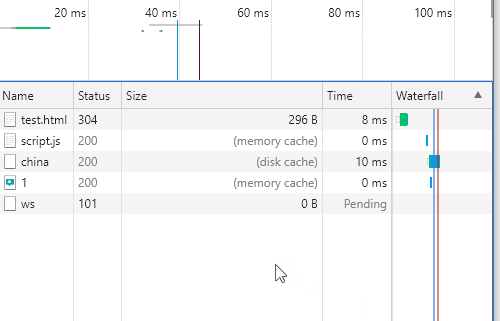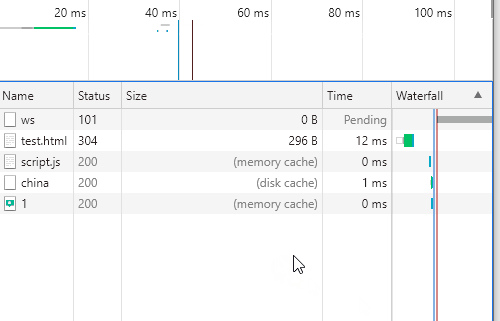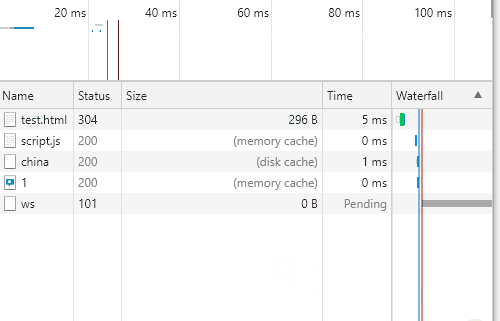
在size一列中,出现了memory cache和disk cache;这里就是我们提到的缓存,说明后面的资源请求都会从缓存中读取,不再请求服务器;
3.1 强缓存
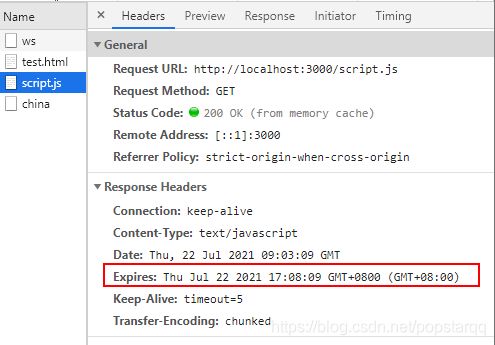
强缓存:不向服务器发送请求,直接从缓存中读取资源,强缓存可以通过设置两种 HTTP 响应Header 实现:Expires 和 Cache-Control,后者是前者的进化版本。
Expires:是HTTP1.0提出的一个表示资源过期时间的header,它描述的是一个绝对时间;但是如果修改了本地时间,就会造成缓存失效。
Cache-Control:Cache-Control 出现于 HTTP/1.1,常见字段是max-age,单位是秒,优先级高于Expires,表示的是相对时间。
例如Cache-Control:max-age=3600 代表资源的有效期是 3600 秒。表示资源第一次请求后的3600秒之内都会从缓存读取资源,之后需要再次从服务器请求一次。
Cache-Control 其他值:
no-cache 不直接使用缓存,也就是跳过强缓存。
no-store 禁止浏览器缓存数据,每次请求资源都会向服务器要完整的资源。
public 可以被所有用户缓存,包括终端用户和 CDN 等中间件代理服务器。
private 只允许终端用户的浏览器缓存,不允许其他中间代理服务器缓存。分别看一下两者的响应头结果
// script.js
if (request.url === '/script.js') {
response.writeHead(200, {
'Content-Type': 'text/javascript',
'Expires': new Date(Date.now() + 300000)
})
response.end("");
}
// 普通get请求
if (request.url === '/china') {
var file = path.join(__dirname, 'china.geojson');
fs.readFile(file, 'utf-8', function (err, data) {
response.writeHead(200,{
'Content-Type': 'application/json',
'Access-Control-Allow-Origin':'*',
'Access-Control-Allow-Methods':'PUT,POST,GET,DELETE,OPTIONS',
'Cache-Control': 'max-age=200' // 浏览器缓存时间,单位是秒
})
response.end(data);
})

如果让浏览器禁用缓存,勾选如下禁用缓存选项;

3.2 协商缓存
协商缓存相比于强缓存又显得温柔一些;强缓存直接缓存在客户端,如果服务器的资源数据发生改变,客户端是感觉不到的;除非客户端强制清除缓存,重新从服务器请求接口;协商缓存是当服务器端资源发生变化后,就不从缓存中获取数据,从服务器获取数据了;
实现原理很简单;就是在服务器端设置缓存策略头;
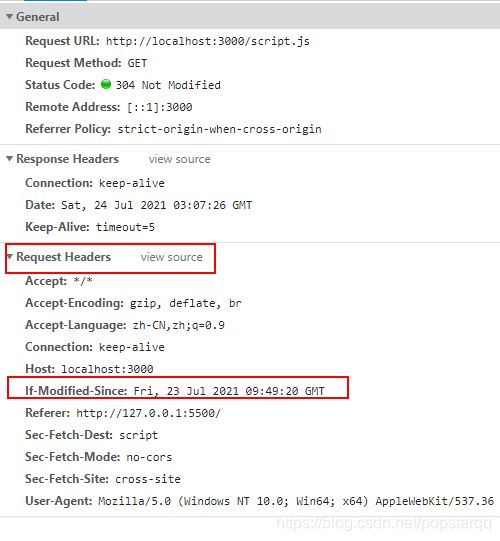
(1) Last-Modified与If-Modified-Since
这个机制是,服务器在响应头中加上Last-Modified, 一般是一个资源的最后修改时间, 浏览器首次请求时获得这个时间, 下一次请求时将这个时间放在请求头的If-Modified-Since, 服务器收到这个If-Modified-Since时间n后查询资源的最后修改时间m与之对比, 若m>n, 说明资源更新过;给出200响应, 更新Last-Modified为新的值, body中为这个资源, 浏览器收到后使用新的资源; 否则如果资源没有更新给出304响应, body无数据, 浏览器使用上一次缓存的资源.
将图片资源和js设置为协商缓存 代码如下:
// image
if (request.url === '/img/1') {
let stats = fs.statSync('./1.png');
let mtimeMs = stats.mtimeMs;
let If_Modified_Since = null;
if(request.headers['if-modified-since'])
If_Modified_Since=request.headers['if-modified-since'];
let oldTime = 0;
if(If_Modified_Since) {
const If_Modified_Since_Date = new Date(If_Modified_Since);
oldTime = If_Modified_Since_Date.getTime();
}
mtimeMs = Math.floor(mtimeMs / 1000) * 1000; // 这种方式的精度是秒, 所以毫秒的部分忽略掉
if(oldTime < mtimeMs) {
response.writeHead(200, {
'Cache-Control': 'no-cache',
'Last-Modified': new Date(mtimeMs).toGMTString()
});
response.end(fs.readFileSync('./1.png'));
}else {
response.writeHead(304);
response.end();
}
}
// script.js
if (request.url === '/script.js') {
let stats = fs.statSync('./script.js');
let mtimeMs = stats.mtimeMs;
let If_Modified_Since = null;
if(request.headers['if-modified-since']) If_Modified_Since=request.headers['if-modified-since'];
let oldTime = 0;
if(If_Modified_Since) {
const If_Modified_Since_Date = new Date(If_Modified_Since);
oldTime = If_Modified_Since_Date.getTime();
}
mtimeMs = Math.floor(mtimeMs / 1000) * 1000;
console.log('mtimeMs', mtimeMs);
console.log('oldTime', oldTime);
if(oldTime < mtimeMs) {
response.writeHead(200, {
'Access-Control-Allow-Origin':'*',
'Access-Control-Allow-Methods':'PUT,POST,GET,DELETE,OPTIONS',
'Cache-Control': 'no-cache',
'Last-Modified': new Date(mtimeMs).toGMTString()
});
response.end(fs.readFileSync('./script.js',"utf-8"));
}else {
console.log("304")
response.writeHead(304);
response.end();
}
}看一下效果:可以看到script.js和1.png第一次状态码是200 从服务器获取资源,以后是304 从缓存中拿数据;
看一下响应头和请求头参数变化
第一次

304请求
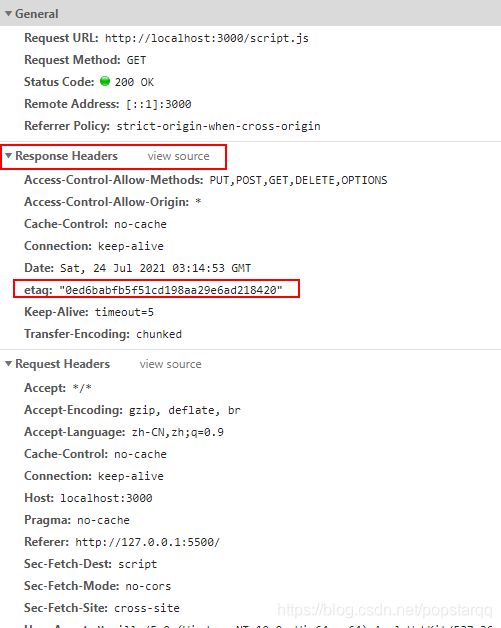
(2)Etag与If-None-Match
Last-Modified模式存两个问题,
一是它是秒级别的比对, 如果资源请求时间是毫秒级,那么这个比对就没有意义;
二是资源的最新修改时间变了,但内容没有变, 会重新从服务器请求资源,失去了缓存的意义;
所以基于此在HTTP1.1引入了Etag模式:Etag一般是基于资源内容生成的标识. 由于Etag是基于内容生成的, 当且仅当内容变化才会给出完整响应, 无浪费和错误的问题;所以比对资源标识比最后修改时间更准确。
代码和效果如下:
// image
if (request.url === '/img/1') {
let fileBuffer = fs.readFileSync("./1.png");
let ifNoneMatch=null;
if(request.headers['if-none-match'])
ifNoneMatch=request.headers['if-none-match'];
const hash = crypto.createHash('md5')
hash.update(fileBuffer)
const etag = `"${hash.digest('hex')}"`
if (ifNoneMatch === etag) {
response.writeHead(304);
response.end();
} else {
response.writeHead(200, {
'Cache-Control': 'no-cache',
'etag':etag
});
response.end(fs.readFileSync('./1.png'));
}