机器学习实战---PM2.5预测
文章目录
- 一. 预处理
- 二、模型训练
- 三、测试
- 四、模型预测
- 五、保存预测结果
- 感受
- 项目数据集
数据集介绍
- 使用丰原站的观测记录,分成 train set 跟 test set,train set 是丰原站每个月的前 20 天所有资料。test set 则是从丰原站剩下的资料中取样出来。
- train.csv: 每个月前 20 天的完整资料。
- test.csv : 从剩下的资料当中取样出连续的 10 小时为一笔,前九小时的所有观测数据当作 feature,第十小时的 PM2.5 当作 answer。一共取出 240 笔不重複的 test data,请根据 feature 预测这 240 笔的 PM2.5。
- Data 含有 18 项观测数据 AMB_TEMP, CH4, CO, NHMC, NO, NO2, NOx, O3, PM10, PM2.5, RAINFALL, RH, SO2, THC, WD_HR, WIND_DIREC, WIND_SPEED, WS_HR。
一. 预处理
import os
import pandas as pd
import numpy as np
data=pd.read_csv("./train.csv", encoding="big5")
# 1.观察数据
data.head(20)
data.info()
data.describe()

# 2.特征抽取
# rainfall补零,截取第四列一直到结束
data=data.iloc[:,3:]
data[data=='NR']=0
numpy_data=data.to_numpy()
data.head(18)
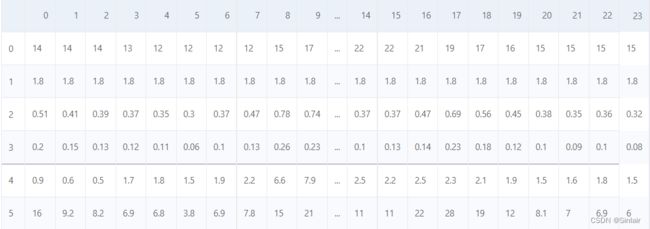
# 整理成每月的数据
# RangeIndex: 4320 entries, 0 to 4319 24列(小时),18个特征
# 4320 18= 12月 18 480每月小时数...os
month_data={}
for month in range(12):
# 每月数据量
sample=np.empty([18,480])
# 每天数据量
for day in range(20):
# 每天24小时,对应这个18个*24小时个数据
sample[:, day*24:(day+1)*24]=numpy_data[18*(20*month +day): 18*(20*month +day+1),:]
month_data[month]=sample
# 3.数据分析
# 数据
x=np.empty([12*471,18*9],dtype=float)
# pm2.5
y=np.empty([12*471,1],dtype=float)
for month in range(12):
for day in range(20):
for hour in range(24):
# 如果是最后一天,最后一个包结束,则返回
if day==19 and hour>14:
continue
# 每个小时的18项数据
x[month*471+day*24+hour,:]=month_data[month][:,day*24+hour:day*24+hour+9].reshape(1,-1)
# pm值
y[month*471+day*24+hour,0]=month_data[month][9,day*24+hour+9]
print(x)
print(y)

# 4.归一
mean_x = np.mean(x, axis = 0) #18 * 9
std_x = np.std(x, axis = 0) #18 * 9
for i in range(len(x)): #12 * 471
for j in range(len(x[0])): #18 * 9
if std_x[j] != 0:
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
x

二、模型训练
使用线性回归模型
# 1为常数项
dim = 18 * 9 + 1
# 床架矩阵
w = np.zeros([dim, 1]) #利用zeros初始化w np.zeros矩阵 dim行一列
# np.concatenate数组的拼接
x = np.concatenate((np.ones([471 * 12, 1]), x), axis = 1).astype(float)
learning_rate = 100 #调整学习率
iter_time = 10000 #跳转学习次数
adagrad = np.zeros([dim, 1])
# 防止被除数为0
eps = 0.0000000001
for t in range(iter_time):
# 计算平方差 np.sqrt(
# np.sum(np.power(np.dot(x, w) - y, 2))/471/12) 这是线性回归的公式
loss = np.sqrt(np.sum(np.power(np.dot(x, w) - y, 2))/471/12) #rmse
# 每100次输出一次
if(t%100==0):
print(str(t) + ":" + str(loss))
# 计算梯度
gradient = 2 * np.dot(x.transpose(), np.dot(x, w) - y) #dim*1
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps)
np.save('weight.npy', w)
w

三、测试
准备测试集
test_data=pd.read_csv("./hw1_data/test.csv",header=None, encoding="big5")
test_data.head()

test_data=test_data.iloc[:,2:]
# 雨置0
test_data[test_data == 'NR'] = 0
test_data=test_data.to_numpy()
# 240个记录,18*9
test_x=np.empty([240,18*9], dtype=float)
for i in range(240):
test_x[i, :] = test_data[18 * i: 18* (i + 1), :].reshape(1, -1)
# 归一化
for i in range(len(test_x)):
for j in range(len(test_x[0])):
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)
test_x
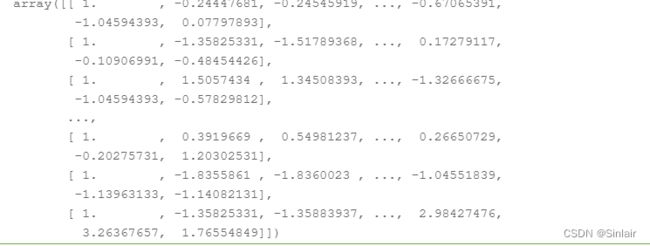
四、模型预测
w=np.load("weight.npy")
# np.dot 向量矩阵的乘法
ans_y=np.dot(test_x,w)
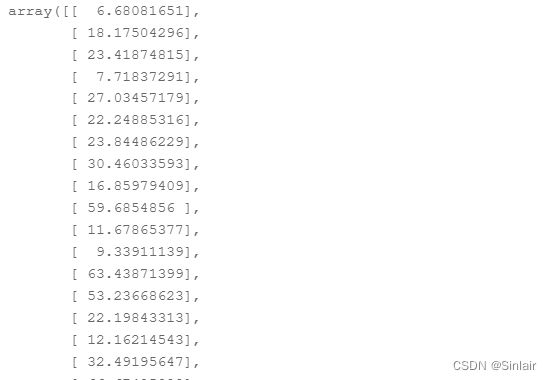
五、保存预测结果
import csv
with open("submit.csv", mode="w",newline='') as submit_file:
csv_writer=csv.writer(submit_file)
header=['id','value']
csv_writer.writerow(header)
for i in range(240):
row=["id_" +str (i), ans_y[i][0]]
csv_writer.writerow(row)
print(row)

感受
项目总体来说,没有很难,整个项目的逻辑很清晰。但是numpy的一些常用的api还需要加强学习。
项目数据集
链接:https://pan.baidu.com/s/1c2GnEJO_29hKOxHf-t9Rqg
提取码:1234
–来自百度网盘超级会员V3的分享