美团后端开发工程师一面面经及详细答案
微信搜索公众号路人zhang,回复面试手册,领取更多高频面试题PDF版及更多面试资料。

面试手册在线版:面试手册在线版
文章目录
-
- 1.自我介绍
- 2.Spring AOP底层原理
- 3.HashMap的底层数据结构,如何进行扩容的?
- 4.ConcurrentHashMap如何实现线程安全?size()方法是加锁的吗?如何实现的?
- 5.线程池参数
- 6.线程池大小如何设置
- 7.IO密集=Ncpu*2是怎么计算出来
- 8.synchronized的锁优化
-
- 锁的升级
- 偏向锁
- 轻量级锁
- 自旋锁
- 9.常用垃圾回收器
- 10.G1有哪些特点
- 11.MySQL事务隔离级别
- 12.可重复读解决了哪些问题
- 13.脏读 不可重复读 幻读
- 14.聚集索引 非聚集索引
- 15.慢查询优化,会考虑哪些优化
- 16.缓存穿透 缓存击穿 缓存雪崩 以及解决办法
- 17.二叉搜索树中第K小的元素
- 18.反问
1.自我介绍
大家好,我是路人zhang,经常在CSDD分享一些面试相关的内容,收藏量已经高达几千,希望大家看的同时帮忙点个赞。
2.Spring AOP底层原理
作为Spring两大核心思想之一的AOP也是一个面试的高频问题
AOP:Aspect Oriented Programming(面向切面编程),和AOP比较像的一个词是OOP,OOP是面向对象编程,而AOP则是建立在OOP基础之上的一种设计思想。而SpringAOP则是实现AOP思想的主流框架
**应用场景:**SpringAOP主要用于处理各个模块的横切关注点,比如日志、权限控制等。
**SpringAOP的思想:**SpringAOP的底层实现原理主要就是代理模式,对原来目标对象创建代理对象,并且在不改变原来对象代码的情况下,通过代理对象,调用增强功能的方法,对原有的业务进行增强。
AOP的代理分为动态代理和静态代理,SpringAOP中是使用动态代理实现的AOP,AspectJ则是使用静态代理实现的AOP。
SpringAOP中的动态代理分为JDK动态代理和CGLIB动态代理。
-
JDK动态代理
**JDK动态代理原理:**基于Java的反射机制实现,必须有接口才能使用该方法生成代理对象。
JDK动态代理主要涉及到了两个类
java.lang.reflect.Proxy和java.lang.reflect.InvocationHandler。这两个类的主要方法如下:java.lang.reflect.Proxy:static InvocationHandler getInvocationHandler(Object proxy),该方法用于获取指定代理对象所关联的调用处理器static Class getProxyClass(ClassLoader loader, Class... interfaces),该方法主要用于返回指定接口的代理类static boolean isProxyClass(Class cl),该方法主要用于返回 cl 是否为一个代理类static Object newProxyInstance(ClassLoader loader, Class[] interfaces, InvocationHandler h)该方法主要用于构造实现指定接口的代理类的实例,所有的方法都会调用给定处理器对象的invoke()方法
java.lang.reflect.InvocationHandler:Object invoke(Object proxy, Method method, Object[] args)该方法主要定义了代理对象调用方法时所执行的代码。
篇幅有限,就不展开介绍了,大致流程如下:
- 实现
InvocationHandler接口创建方法调用器 - 通过为 Proxy 类指定
ClassLoader对象和一组interface创建动态代理 - 通过反射获取动态代理类的构造函数,参数类型就是调用处理器接口类型
- 通过构造函数创建动态代理类实例,构造时调用处理器对象作为参数传入
-
CGLib 动态代理原理:利用ASM开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
SpringAOP何时使用JDK动态代理,何时使用CGLiB动态代理?
- 当Bean实现接口时,使用JDK动态代理。
- 当Bean没有实现接口时,使用CGlib动态代理
3.HashMap的底层数据结构,如何进行扩容的?
非常高频的面试题
底层数据结构:
- JDK1.7的底层数据结构(数组+链表)
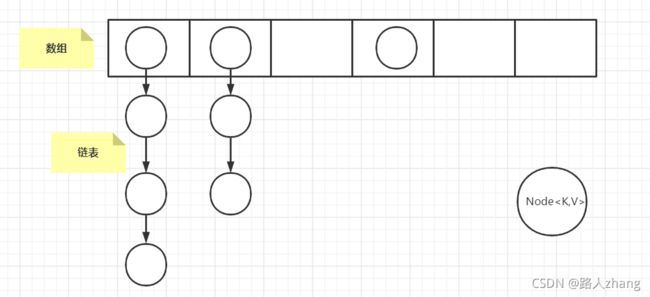
- JDK1.8的底层数据结构(数组+链表)

扩容机制:
-
初始值为16,负载因子为0.75,阈值为负载因子*容量
-
resize()方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize()方法进行扩容。 -
每次扩容,容量都是之前的两倍
-
扩容时有个判断
e.hash & oldCap是否为零,也就是相当于hash值对数组长度的取余操作,若等于0,则位置不变,若等于1,位置变为原位置加旧容量。源码如下:
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { //如果旧容量已经超过最大值,阈值为整数最大值 threshold = Integer.MAX_VALUE; return oldTab; }else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; //没有超过最大值就变为原来的2倍 } else if (oldThr > 0) newCap = oldThr; else { newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { Node<K,V> loHead = null, loTail = null;//loHead,loTail 代表扩容后在原位置 Node<K,V> hiHead = null, hiTail = null;//hiHead,hiTail 代表扩容后在原位置+旧容量 Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { //判断是否为零,为零赋值到loHead,不为零赋值到hiHead if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; //loHead放在原位置 } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; //hiHead放在原位置+旧容量 } } } } } return newTab; }其他HashMap高频面试题:Jav集合高频面试题
4.ConcurrentHashMap如何实现线程安全?size()方法是加锁的吗?如何实现的?
如何实现线程安全?
JDK1.7和JDK1.8在实现线程安全上略有不同
- JDK1.7采用了分段锁的机制,当一个线程占用锁时,会锁住一个Segment对象,不会影响其他Segment对象。
- JDK1.8则是采用了CAS和
synchronize的方式来保证线程安全。
size()方法是加锁的吗?如何实现的?
这个问题本质是ConcurrentHashMap是并发操作的,所在在计算size时,可能还会进行并发地插入数据,ConcurrentHashMap是如何解决这个问题的?
在JDK1.7会先统计两次,如果两次结果一致表示值就是当前ConcurrentHashMap的大小,如果两次不一样,则会对所有的segment都进行加锁,统计一个准确的值。代码如下:
/**
* Returns the number of key-value mappings in this map. If the
* map contains more than Integer.MAX_VALUE elements, returns
* Integer.MAX_VALUE.
*
* @return the number of key-value mappings in this map
*/
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments; //map数据从segments中拿取
int size;
boolean overflow; // 判断size是否过大会溢出
long sum; //
long last = 0L; //最近的一个sum值
int retries = -1; // 重试的次数
try {
for (;;) { //一直循环统计size直到segment结构没有发生变化
if (retries++ == RETRIES_BEFORE_LOCK) { //如果已经重试2次,到达第三次
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); //对segment加上锁
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock(); //对segment解锁
}
}
return overflow ? Integer.MAX_VALUE : size;
}
在JDK1.8中是这样实现的:
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n);
}
ConcurrentHashMap的容量大小可能会大于int的最大值,所以JDK建议使用mappingCount()方法,而不是size()方法:
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n;
}
不过这两个方法的关键点都是sumCount(),其代码如下:
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
从上面代码可以看出 sumCount()方法就是统计sum的过程,通过使用baseCount和遍历counterCells统计sum
其中counterCells的定义如下:
/**
* Table of counter cells. When non-null, size is a power of 2.
*/
private transient volatile CounterCell[] counterCells;
baseCount的定义如下:
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
private transient volatile long baseCount;
当容器大小改变时就会通过addCount()改变baseCount
/**
* Adds to count, and if table is too small and not already
* resizing, initiates transfer. If already resizing, helps
* perform transfer if work is available. Rechecks occupancy
* after a transfer to see if another resize is already needed
* because resizings are lagging additions.
*
* @param x the count to add
* @param check if <0, don't check resize, if <= 1 only check if uncontended
*/
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { //cas操作使得 baseCount加1
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended); //高并发导致CAS失败时执行
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
从上述代码可以看出,首先会CAS地更新baseCount的值,如果存在并发,CAS失败的线程则会进行方法中,后面会执行到fullAddCount()方法,该方法就是在初始化counterCells, 这也解释了为什么在 sumCount()中通过baseCount和遍历counterCells统计sum,所以在JDK1,8中size()是不加锁的
5.线程池参数
线程池的常用创建方式主要有两种,通过Executors工厂方法创建和**通过new ThreadPoolExecutor**方法创建。
ThreadPoolExecutor构造函数的重要参数分析:
三个比较重要的参数:
corePoolSize:核心线程数,定义了最小可以同时运行的线程数量。maximumPoolSize:线程中允许存在的最大工作线程数量workQueue:存放任务的阻塞队列。新来的任务会先判断当前运行的线程数是否到达核心线程数,如果到达的话,任务就会先放到阻塞队列。
其他参数:
keepAliveTime:当线程池中的数量大于核心线程数时,如果没有新的任务提交,核心线程外的线程不会立即销毁,而是会等到时间超过keepAliveTime时才会被销毁。unit:keepAliveTime参数的时间单位。threadFactory:为线程池提供创建新线程的线程工厂。handler:线程池任务队列超过maxinumPoolSize之后的拒绝策略
6.线程池大小如何设置
-
CPU 密集型应用,线程池大小设置为 N + 1(N表示CPU数量)
-
IO 密集型应用,线程池大小设置为 2N
7.IO密集=Ncpu*2是怎么计算出来
无论是CPU密集型应用的N+1还是IO密集型应用的2N都是一个经验值,在《Java并发编程实战》中,给出一种计算线程池大小的方法,在一个基准负载下,使用 几种不同大小的线程池运行你的应用程序,并观察CPU利用率的水平。 给定下列定义:
Ncpu 表示CPU的数量 ,Ucpu 表示目标CPU的使用率,其中0 <= Ucpu <= 1,W/C =表示等待时间与计算时间的比率,为保持处理器达到期望的使用率,最优的池的大小等于:Nthreads = Ncpu x Ucpu x (1 + W/C)
对于IO密集型应用,等待时间一般都会比计算时间长,如果假设等待时间等于计算时间,那么Nthreads = Ncpu x Ucpu x 2,当CPU使用率达到100%,Nthreads = Ncpu x2
8.synchronized的锁优化
锁的升级
在JDK1.6中,为了减少获得锁和释放锁带来的性能消耗,引入了偏向锁和轻量级锁,锁的状态变成了四种,如下图所示。锁的状态会随着竞争激烈逐渐升级,但通常情况下,锁的状态只能升级不能降级。这种只能升级不能降级的策略是为了提高获得锁和释放锁的效率。

偏向锁
常见面试题:偏向锁的原理(或偏向锁的获取流程)、偏向锁的好处是什么(获取偏向锁的目的是什么)
引入偏向锁的目的:减少只有一个线程执行同步代码块时的性能消耗,即在没有其他线程竞争的情况下,一个线程获得了锁。
偏向锁的获取流程:
- 检查对象头中Mark Word是否为可偏向状态,如果不是则直接升级为轻量级锁。
- 如果是,判断Mark Work中的线程ID是否指向当前线程,如果是,则执行同步代码块。
- 如果不是,则进行CAS操作竞争锁,如果竞争到锁,则将Mark Work中的线程ID设为当前线程ID,执行同步代码块。
- 如果竞争失败,升级为轻量级锁。
偏向锁的获取流程如下图:

偏向锁的撤销:
只有等到竞争,持有偏向锁的线程才会撤销偏向锁。偏向锁撤销后会恢复到无锁或者轻量级锁的状态。
- 偏向锁的撤销需要到达全局安全点,全局安全点表示一种状态,该状态下所有线程都处于暂停状态。
- 判断锁对象是否处于无锁状态,即获得偏向锁的线程如果已经退出了临界区,表示同步代码已经执行完了。重新竞争锁的线程会进行CAS操作替代原来线程的ThreadID。
- 如果获得偏向锁的线程还处于临界区之内,表示同步代码还未执行完,将获得偏向锁的线程升级为轻量级锁。
一句话简单总结偏向锁原理:使用CAS操作将当前线程的ID记录到对象的Mark Word中。
轻量级锁
引入轻量级锁的目的:在多线程交替执行同步代码块时(未发生竞争),避免使用互斥量(重量锁)带来的性能消耗。但多个线程同时进入临界区(发生竞争)则会使得轻量级锁膨胀为重量级锁。
轻量级锁的获取流程:
- 首先判断当前对象是否处于一个无锁的状态,如果是,Java虚拟机将在当前线程的栈帧建立一个锁记录(Lock Record),用于存储对象目前的Mark Word的拷贝,如图所示。

-
将对象的Mark Word复制到栈帧中的Lock Record中,并将Lock Record中的owner指向当前对象,并使用CAS操作将对象的Mark Word更新为指向Lock Record的指针,如图所示。

-
如果第二步执行成功,表示该线程获得了这个对象的锁,将对象Mark Word中锁的标志位设置为“00”,执行同步代码块。
-
如果第二步未执行成功,需要先判断当前对象的Mark Word是否指向当前线程的栈帧,如果是,表示当前线程已经持有了当前对象的锁,这是一次重入,直接执行同步代码块。如果不是表示多个线程存在竞争,该线程通过自旋尝试获得锁,即重复步骤2,自旋超过一定次数,轻量级锁升级为重量级锁。
轻量级锁的解锁:
轻量级的解锁同样是通过CAS操作进行的,线程会通过CAS操作将Lock Record中的Mark Word(官方称为Displaced Mark Word)替换回来。如果成功表示没有竞争发生,成功释放锁,恢复到无锁的状态;如果失败,表示当前锁存在竞争,升级为重量级锁。
一句话总结轻量级锁的原理:将对象的Mark Word复制到当前线程的Lock Record中,并将对象的Mark Word更新为指向Lock Record的指针。
自旋锁
Java锁的几种状态并不包括自旋锁,当轻量级锁的竞争就是采用的自旋锁机制。
什么是自旋锁:当线程A已经获得锁时,线程B再来竞争锁,线程B不会直接被阻塞,而是在原地循环 等待,当线程A释放锁后,线程B可以马上获得锁。
引入自旋锁的原因:因为阻塞和唤起线程都会引起操作系统用户态和核心态的转变,对系统性能影响较大,而自旋等待可以避免线程切换的开销。
自旋锁的缺点:自旋等待虽然可以避免线程切花的开销,但它也会占用处理器的时间。如果持有锁的线程在较短的时间内释放了锁,自旋锁的效果就比较好,如果持有锁的线程很长时间都不释放锁,自旋的线程就会白白浪费资源,所以一般线程自旋的次数必须有一个限制,该次数可以通过参数-XX:PreBlockSpin调整,一般默认为10。
自适应自旋锁:JDK1.6引入了自适应自旋锁,自适应自旋锁的自旋次数不在固定,而是由上一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。如果对于某个锁对象,刚刚有线程自旋等待成功获取到锁,那么虚拟机将认为这次自旋等待的成功率也很高,会允许线程自旋等待的时间更长一些。如果对于某个锁对象,线程自旋等待很少成功获取到锁,那么虚拟机将会减少线程自旋等待的时间。
更多synchronized面试题可以看这篇文章:
9.常用垃圾回收器
用于回收新生代的收集器有Serial、PraNew、Parallel Scavenge
用于回收老年代的收集器包括Serial Old、Parallel Old、CMS
用于回收整个Java堆的收集器:G1
10.G1有哪些特点
G1收集器是JDK1.7提供的一个新收集器,G1收集器基于“标记-整理”算法实现,不会产生内存碎片。G1收集器不同于之前的收集器的一个重要特点是:G1回收的范围是整个Java堆。
11.MySQL事务隔离级别
- 未提交读:一个事务在提交前,它的修改对其他事务也是可见的。
- 提交读:一个事务提交之后,它的修改才能被其他事务看到。
- 可重复读:在同一个事务中多次读取到的数据是一致的。
- 串行化:需要加锁实现,会强制事务串行执行。
12.可重复读解决了哪些问题
数据库的隔离级别分别可以解决数据库的脏读、不可重复读、幻读等问题。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读 | 允许 | 允许 | 允许 |
| 提交读 | 不允许 | 允许 | 允许 |
| 可重复读 | 不允许 | 不允许 | 允许 |
| 串行化 | 不允许 | 不允许 | 不允许 |
MySQL的默认隔离级别是可重复读。
13.脏读 不可重复读 幻读
当多个事务并发执行时,可能会出现以下问题:
- 脏读:事务A更新了数据,但还没有提交,这时事务B读取到事务A更新后的数据,然后事务A回滚了,事务B读取到的数据就成为脏数据了。
- 不可重复读:事务A对数据进行多次读取,事务B在事务A多次读取的过程中执行了更新操作并提交了,导致事务A多次读取到的数据并不一致。
- 幻读:事务A在读取数据后,事务B向事务A读取的数据中插入了几条数据,事务A再次读取数据时发现多了几条数据,和之前读取的数据不一致。
- 丢失修改:事务A和事务B都对同一个数据进行修改,事务A先修改,事务B随后修改,事务B的修改覆盖了事务A的修改。
不可重复度和幻读看起来比较像,它们主要的区别是:在不可重复读中,发现数据不一致主要是数据被更新了。在幻读中,发现数据不一致主要是数据增多或者减少了。
14.聚集索引 非聚集索引
聚簇索引和非聚簇索引最主要的区别是数据和索引是否分开存储。
- 聚簇索引:将数据和索引放到一起存储,索引结构的叶子节点保留了数据行。
- 非聚簇索引:将数据进和索引分开存储,索引叶子节点存储的是指向数据行的地址。
在InnoDB存储引擎中,默认的索引为B+树索引,利用主键创建的索引为主索引,也是聚簇索引,在主索引之上创建的索引为辅助索引,也是非聚簇索引。为什么说辅助索引是在主索引之上创建的呢,因为辅助索引中的叶子节点存储的是主键。
在MyISAM存储引擎中,默认的索引也是B+树索引,但主索引和辅助索引都是非聚簇索引,也就是说索引结构的叶子节点存储的都是一个指向数据行的地址。并且使用辅助索引检索无需访问主键的索引。
可以从非常经典的两张图看看它们的区别(图片来源于网络):


15.慢查询优化,会考虑哪些优化
慢查询一般用于记录执行时间超过某个临界值的SQL语句的日志。
相关参数:
- slow_query_log:是否开启慢日志查询,1表示开启,0表示关闭。
- slow_query_log_file:MySQL数据库慢查询日志存储路径。
- long_query_time:慢查询阈值,当SQL语句查询时间大于阈值,会被记录在日志上。
- log_queries_not_using_indexes:未使用索引的查询会被记录到慢查询日志中。
- log_output:日志存储方式。“FILE”表示将日志存入文件。“TABLE”表示将日志存入数据库。
如何对慢查询进行优化?
- 分析语句的执行计划,查看SQL语句的索引是否命中
- 优化数据库的结构,将字段很多的表分解成多个表,或者考虑建立中间表。
- 优化LIMIT分页。
16.缓存穿透 缓存击穿 缓存雪崩 以及解决办法
-
缓存穿透:指缓存和数据库中都没有的数据,所有请求都打在数据库上,造成数据库短时间承受大量请求而挂掉
解决方法:
- 增加接口校验,过滤一些不合法请求,比如大量订单号为-1的数据
- 从缓存和数据库都不能获取到的数据,可以先对空的结果进行缓存,比如key-null,缓存有效期要设置的短一些
- 采用布隆过滤器,过滤掉一定不存在的数据
-
缓存击穿:指缓存中没有但数据库中有的数据,一般是在高并发的情况下,某些热门key突然过期,导致所有请求直接打到数据库上
解决方法::
- 设置热点数据永不过期
- 加互斥锁
-
缓存雪崩:大量缓存在一段时间内集中过期,导致查询的数据都打在数据库上,和缓存击穿的区别是缓存过期的数量
解决方法:
- 将缓存的过期时间设置随机,避免大量缓存同时过期
- 服务降级或熔断
17.二叉搜索树中第K小的元素
这是一个力扣中等题题目,第230题,二叉搜索树的中序遍历即为有序数组,取到第K小的元素即可