深入浅出理解相机标定原理
重要说明:本文从网上资料整理而来,仅记录博主学习相关知识点的过程,侵删。
一、参考资料
微信公众号:计算机视觉life 专栏:#相机标定
Camera Calibration
Camera Calibration and 3D Reconstruction
张正友标定法-完整学习笔记-从原理到实战
相机标定的原理及四个坐标系之间的关系
二、相机标定相关介绍
1. 透视投影
用中心投影法,将物体投射到投射面上,从而获得一种较为接近视觉效果的单面投影图,也就是我们看到景物近大远小的一种成像方式。
2. 相机标定的概念
简单来说,摄像机标定(Camera calibration)就是从世界坐标系转换到像素坐标系的过程,该过程包括两个阶段:建立相机成像几何模型,并矫正透镜畸变。
建立相机成像几何模型:建立物体从三维世界映射到相机成像平面这一过程中的几何模型。最关键的部分是,得到相机的内参和外参。
矫正透镜畸变:由于透镜制造工艺,产生多种形式的畸变。为了去除畸变,计算并利用畸变系数来矫正像差,使成像后的图像与真实世界的景象保持一致。
3. 四大坐标系
世界坐标系(world coordinate system):用户定义的三维世界的坐标系,为了描述目标物在真实世界里的位置而被引入。单位为米,坐标系为 ( X w , Y w , Z w ) (X_w,Y_w,Z_w) (Xw,Yw,Zw)。
相机坐标系(camera coordinate system):在相机上建立的坐标系,为了从相机的角度描述物体位置而定义,作为沟通世界坐标系和图像/像素坐标系的中间一环。单位为米,一般取相机的光学轴为Z轴,坐标系为 ( X c , Y c , Z c ) (X_c, Y_c,Z_c) (Xc,Yc,Zc)。
图像物理坐标系(image coordinate system):为了描述成像过程中物体从相机坐标系到图像坐标系的投影透射关系而引入,方便进一步得到像素坐标系下的坐标。 单位为毫米,坐标原点为相机光轴与图像物理坐标系交点的位置,坐标系为 ( x , y ) (x,y) (x,y)。
图像像素坐标系(pixel coordinate system):为了描述物体成像后的像点在数字图像上(相片)的坐标而引入,是我们真正从相机内读取到的信息所在的坐标系。单位为像素,坐标原点在左上角,坐标系为 ( u , v ) (u,v) (u,v)。
四个坐标系之间的关系,如下图所示:

其中,相机坐标系的Z轴与光轴重合,且垂直于图像坐标系平面并通过图像坐标系的原点,相机坐标系与图像坐标系之间的距离为焦距f(也即图像坐标系原点与焦点重合)。像素坐标系平面u-v和图像坐标系平面x-y重合,但像素坐标系原点位于图中左上角(之所以这么定义,目的是从存储信息的首地址开始读写)。
4. 四大坐标系的转换
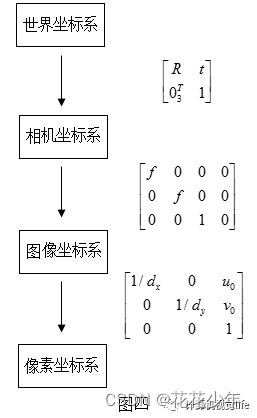
4.1 世界坐标系vs相机坐标系
世界坐标系转换到相机坐标系下,这两个坐标系之间的转换属于刚体运动,物体只改变两个坐标系中的空间位置(平移)和朝向(旋转),而不改变其形状。他们之间的转换关系可以用平移矩阵T和旋转矩阵R来完成,这两个矩阵反映了世界坐标系与相机坐标系之间的转换关系,合称为外参矩阵 L w L_w Lw。获得了外参矩阵,已知世界坐标系中的一点,通过转换关系就可以得到此点在相机坐标系中的位置。
变换矩阵由一个旋转矩阵和平移向量组合成的齐次坐标系来表示:
[ x C y C z C 1 ] = [ R t 0 3 T 1 ] [ x W y W z W 1 ] = [ r 1 r 2 r 3 t ] [ x W y W 0 1 ] = [ r 1 r 2 t ] [ x W y W 1 ] \left[\begin{array}{c}x_{C}\\y_{C}\\z_{C}\\1\end{array}\right]=\left[\begin{array}{cc}R&t\\0_{3}^{T}&1\end{array}\right]\left[\begin{array}{c}x_{W}\\y_{W}\\z_{W}\\1\end{array}\right]=\left[\begin{array}{cc}r_{1}&r_{2}&r_{3}&t\end{array}\right]\left[\begin{array}{c}x_{W}\\y_{W}\\0\\1\end{array}\right]=\left[\begin{array}{cc}r_{1}&r_{2}&t\end{array}\right]\left[\begin{array}{c}x_{W}\\y_{W}\\1\end{array}\right] xCyCzC1 =[R03Tt1] xWyWzW1 =[r1r2r3t] xWyW01 =[r1r2t] xWyW1
其中,R为旋转矩阵,t为平移向量。假定世界坐标系中,物点所在平面过世界坐标系原点,且与 Z w = 0 Z_w=0 Zw=0 轴垂直,即棋盘平面与 X w − Y w X_w - Y_w Xw−Yw 平面重合,目的在于方便后续计算。其中,变化矩阵为:
[ R t 0 3 T 1 ] \begin{bmatrix}R&t\\0_3^T&1\end{bmatrix} [R03Tt1]
下图表示用R、t将世界坐标系转换到相机坐标系的过程。

4.2 相机坐标系vs图像物理坐标系(无畸变)
相机坐标系转换到图像物理坐标系下,就是将三维的坐标系转换为二维的坐标系,也即投影透视过程。如下图所示,小孔成像过程:针孔面(相机坐标系)在图像平面(图像物理坐标系)和物点平面(棋盘平面)之间,所成图像为倒立实像。

但是,为了在数学上更方便描述,将相机坐标系和图像物理坐标系位置对调(没有实际的物理意义,只是方便计算),变成下图所示:

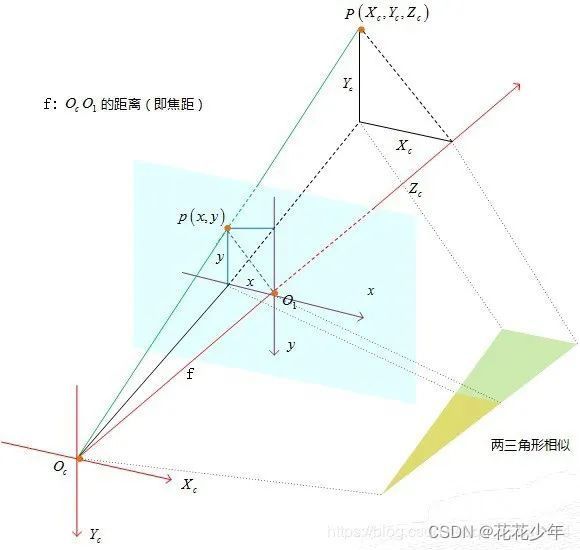
假设相机坐标系中有一点M,根据相似三角形原理,则在图像物理坐标系下(无畸变)的成像点P的坐标为:
x p = f x M z M , y p = f y M z M \mathrm{x}_{p}=f\frac{x_{M}}{z_{M}},y_{p}=f\frac{y_{M}}{z_{M}} xp=fzMxM,yp=fzMyM
将上式转化为齐次坐标表示形式为:
z M [ x p y p 1 ] = [ f 0 0 0 0 f 0 0 0 0 1 0 ] [ x M y M z M 1 ] = [ f 0 0 0 f 0 0 0 1 ] [ 1 0 0 0 0 1 0 0 0 0 1 0 ] [ x M y M z M 1 ] z_{M}\left[\begin{array}{c}{x_{p}}\\{y_{p}}\\{1}\\\end{array}\right]=\left[\begin{array}{ccc}{f}&{0}&{0}&{0}\\{0}&{f}&{0}&{0}\\{0}&{0}&{1}&{0}\\\end{array}\right]\left[\begin{array}{c}{x_{\mathrm{M}}}\\{y_{\mathrm{M}}}\\{z_{\mathrm{M}}}\\{1}\\\end{array}\right]=\left[\begin{array}{ccc}{f}&{0}&{0}\\{0}&{f}&{0}\\{0}&{0}&{1}\\\end{array}\right]\left[\begin{array}{ccc}{1}&{0}&{0}&{0}\\{0}&{1}&{0}&{0}\\{0}&{0}&{1}&{0}\\\end{array}\right]\left[\begin{array}{cc}{x_{\mathrm{M}}}\\{y_{\mathrm{M}}}\\{z_{\mathrm{M}}}\\{1}\\\end{array}\right] zM xpyp1 = f000f0001000 xMyMzM1 = f000f0001 100010001000 xMyMzM1
4.3 相机坐标系vs图像物理坐标系(有畸变)
请参考章节:相机畸变模型
4.4 图像物理坐标系vs图像像素坐标系
以一个形象的例子,说明图像物理坐标系与图像像素坐标系之间的区别。物理坐标系是一个连续的概念,它以毫米为单位,就好比某一观众在电影院里的具体坐标值为(3.4, 5.9);而像素坐标系是一个离散的概念,它是以像素为单位,之鞥你是整数值坐标,就好比某一观众在电影院里的位置是(第三排,第六列)。另外需要注意的是,这两个坐标系的原点位置不相同,物理坐标系的原点是相机光轴与图像物理坐标系的交点,通常称其为主点;而像素坐标系则以像素图像的左上角为原点。
由于定义的图像像素坐标系原点与图像物理坐标系原点不重合,假设图像物理坐标系原点在图像像素坐标系下的坐标为 ( u 0 , v 0 ) (u_0, v_0) (u0,v0),每个像素点在图像物理坐标系x轴、y轴方向的尺寸为: d x 、 d y d_x、d_y dx、dy,且像点在图像物理坐标系下的坐标为 ( x c , y c ) (x_c,y_c) (xc,yc),可得想点在图像坐标系下的坐标为:
u = x c d x + u 0 , v = y c d y + v 0 u=\frac{x_{c}}{d_{x}}+u_{0},\mathbf{v}=\frac{y_{c}}{d_{y}}+\mathbf{v}_{0} u=dxxc+u0,v=dyyc+v0
化为齐次坐标系的表现形式为:
[ u ν 1 ] = [ 1 / d x 0 u 0 0 1 / d y v 0 0 0 1 ] [ x c y c 1 ] \begin{bmatrix}u\\\nu\\1\end{bmatrix}=\begin{bmatrix}1/d_x&0&u_0\\0&1/d_y&v_0\\0&0&1\end{bmatrix}\begin{bmatrix}x_c\\y_c\\1\end{bmatrix} uν1 = 1/dx0001/dy0u0v01 xcyc1
5. 相机畸变模型
透镜的畸变主要分为:径向畸变和切向畸变,还有薄透镜畸变等,但都没有径向畸变和切向畸变影响显著,因此一般只考虑径向畸变k和切向畸变p。一共需要5个畸变参数(k1、k2、k3、p1和p2)来描述透镜畸变,其中径向畸变有3个参数 (k1、k2、k3),切向畸变有2个参数 (p1、p2)。
5.1 径向畸变
径向畸变是由于透镜形状的制造工艺导致的,越向透镜边缘移动,径向畸变越严重。下图所示是径向畸变的两种类型:桶型畸变(k<0)和枕型畸变(k>0)。
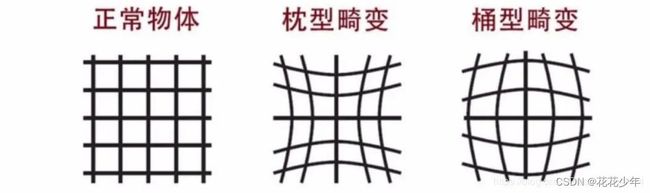
- 当k>0时,r越大(点离中心越远),畸变量越大,r越小,畸变量越小,呈枕型。
- 当k<0时,r越大(点离中心越远),畸变量越小,r越小,畸变量越大,呈桶型。
实际情况中,常用r=0处的泰勒级数展开的前几项来近似描述径向畸变。矫正径向畸变前后的坐标关系为:
{ x d i s t o r t e d = x p ( 1 + k 1 r 2 + k 2 r 4 + k 3 r 6 ) y d i s t o r t e d = y p ( 1 + k 1 r 2 + k 2 r 4 + k 3 r 6 ) \begin{cases}\mathbf{x}_{distorted}=x_p(1+k_1r^2+k_2r^4+k_3r^6)\\y_{distorted}=y_p(1+k_1r^2+k_2r^4+k_3r^6)\end{cases} {xdistorted=xp(1+k1r2+k2r4+k3r6)ydistorted=yp(1+k1r2+k2r4+k3r6)
由此可知,对于径向畸变,有3个径向畸变参数(k1、k2、K3)需要求解。
研究表明,径向畸变参数一般选择2或3个k值,可以获得较好结果。如果k取得再多,影响不会很大可以忽略,也有可能导致效果不好。
5.2 切向畸变
切向畸变是由于透镜和CMOS或者CCD的安装位置误差导致。由此,如果存在切向畸变,一个矩形被投影到成像平面时,很可能会变成一个梯形。切向畸变需要2个额外的畸变参数(p1和p2)来描述,矫正前后的坐标关系为:
{ x d i s t o r t e d = x p + [ 2 p 1 x p y p + p 2 ( r 2 + 2 x p 2 ) ] y d i s t o r t e d = y p + [ p 1 ( r 2 + 2 y p 2 ) + 2 p 2 x p y p ] \begin{cases}\mathbf{x}_{distorted}=x_{p}+[2p_{1}x_{p}y_{p}+p_{2}(r^{2}+2{x_{p}}^{2})]\\\mathbf{y}_{distorted}=y_{p}+[p_{1}(r^{2}+2{y_{p}}^{2})+2p_{2}x_{p}y_{p}]\end{cases} {xdistorted=xp+[2p1xpyp+p2(r2+2xp2)]ydistorted=yp+[p1(r2+2yp2)+2p2xpyp]
6. 相机标定参数
内参
-
焦距长度: f x 、 f y f_x、f_y fx、fy;
-
主点(光心)像素坐标: c x 、 c y c_x、c_y cx、cy;
-
畸变系数: k 1 , k 2 , k 3 , p 1 , p 2 k_{1},k_{2},k_{3},p_{1,}p_{2} k1,k2,k3,p1,p2;
c a m e r a matri x = [ f x 0 c x 0 f y c y 0 0 1 ] camera\textit{matri}x=\begin{bmatrix}f_x&0&c_x\\0&f_y&c_y\\0&0&1\end{bmatrix} cameramatrix= fx000fy0cxcy1
D i s t o r t i o n c o e f f i c i e n t s = ( k 1 k 2 p 1 p 2 k 3 ) Distortion \ coefficients = (k_1 \ k_2 \ p_1 \ p_2 \ k_3) Distortion coefficients=(k1 k2 p1 p2 k3)
外参
- 旋转矩阵R;
- 平移矩阵T。
7. 单应矩阵
张正友标定算法原理详解
7.1 引言
o’-uv是图像像素坐标系,o-XYZ是世界坐标系。假设图像中的一点坐标为(u,v),对应的三维点位置在(x,y,z),那么它们之间的转换关系是这样的:
[ u ν 1 ] = s [ f x γ u 0 0 f y ν 0 0 0 1 ] [ r 1 r 2 t ] [ x W y W 1 ] \begin{bmatrix}u\\\nu\\1\end{bmatrix}=s\begin{bmatrix}f_x&\gamma&u_0\\0&f_y&\nu_0\\0&0&1\end{bmatrix}\begin{bmatrix}r_1&r_2&t\end{bmatrix}\begin{bmatrix}x_W\\y_W\\1\end{bmatrix} uν1 =s fx00γfy0u0ν01 [r1r2t] xWyW1
其中,s是尺度因子,表示从相机光心出去的射线都会落在成像平面的同一个点。u、v表示图像像素坐标系中的坐标, f x 、 f y 、 u 0 、 v 0 、 γ f_x、f_y、u_0、v_0、\gamma fx、fy、u0、v0、γ 表示5个相机内参,R、t表示相机外参, X w 、 Y w 、 Z w X_w、Y_w、Z_w Xw、Yw、Zw 表示世界坐标系中的坐标,棋盘平面位于世界坐标系中 Z w = 0 Z_w=0 Zw=0 的平面。
7.2 单应性的概念
单应性(Homography)变换,描述物体在世界坐标系和图像像素坐标系之间的位置映射关系,这个变换矩阵称为单应性矩阵。在上述式子中,单应性矩阵定义为:
H = s [ f x γ u 0 0 f y ν 0 0 0 1 ] [ r 1 r 2 t ] = s M [ r 1 r 2 t ] H=s\begin{bmatrix}f_x&\gamma&u_0\\0&f_y&\nu_0\\0&0&1\end{bmatrix}\begin{bmatrix}r_1&r_2&t\end{bmatrix}=sM\begin{bmatrix}r_1&r_2&t\end{bmatrix} H=s fx00γfy0u0ν01 [r1r2t]=sM[r1r2t]
其中,M是相机内参矩阵:
M = [ f x γ u 0 0 f y ν 0 0 0 1 ] M=\left[\begin{array}{ccc}f_x&\gamma&u_0\\0&f_y&\nu_0\\0&0&1\end{array}\right] M= fx00γfy0u0ν01
单应性矩阵同时包含了相机内参和外参。
7.3 单应性的应用
7.3.1 图像矫正
用单应性矩阵进行图像矫正,最少需要四个对应点。

7.3.2 视角变换
单应性矩阵可以方便的将普通视图转换成鸟瞰图,如下图所示,左边是普通视图,右边是鸟瞰图:

7.3.3 图像拼接
既然单应性矩阵可以进行视角转换,那么把不同角度拍摄的图像都转换到同一视角下,就可以实现图像拼接了。如下图所示,通过单应性矩阵H可以将image1和image2都变换到同一个平面。


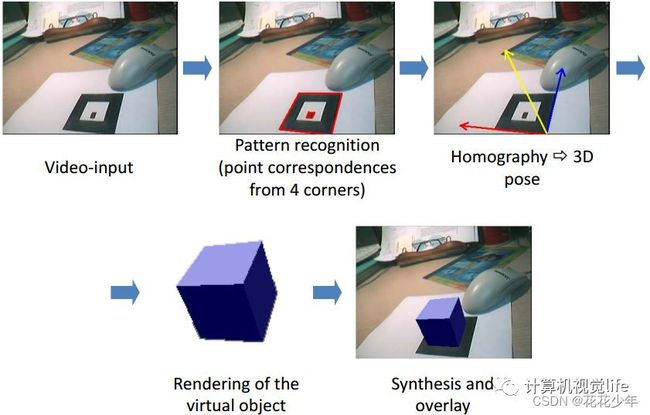
7.3.4 增强现实AR
平面二维标图案(marker)经常用来做AR展示,根据marker不同视角下的图像,可以方便的得到虚拟物体的位置姿态并进行现实,如下图所示:
7.4 单应性矩阵的原理
假设两张图像中的对应点的齐次坐标为 ( x ′ , y ′ , 1 ) (x^{\prime},y^{\prime},1) (x′,y′,1),单应性矩阵H定义为:
H = [ h 11 h 12 h 13 h 21 h 22 h 23 h 31 h 32 h 33 ] H=\left[\begin{array}{ccc}h_{_{11}}&h_{_{12}}&h_{_{13}}\\h_{_{21}}&h_{_{22}}&h_{_{23}}\\h_{_{31}}&h_{_{32}}&h_{_{33}}\end{array}\right] H= h11h21h31h12h22h32h13h23h33
则有:
[ x ′ y ′ 1 ] ∼ [ h 11 h 12 h 13 h 21 h 22 h 23 h 31 h 32 h 33 ] [ x y 1 ] \left[\begin{array}{c}x'\\y'\\1\end{array}\right]\sim\left[\begin{array}{ccc}h_{11}&h_{12}&h_{13}\\h_{21}&h_{22}&h_{23}\\h_{31}&h_{32}&h_{33}\end{array}\right] \begin{bmatrix}x\\y\\1\\\end{bmatrix} x′y′1 ∼ h11h21h31h12h22h32h13h23h33 xy1
矩阵展开后有3个等式,将第三个等式带入前两个等式中,可得:
x ′ = h 11 x + h 12 y + h 13 h 31 x + h 32 y + h 33 x'=\frac{h_{11}x+h_{12}y+h_{13}}{h_{31}x+h_{32}y+h_{33}} x′=h31x+h32y+h33h11x+h12y+h13
y ′ = h 21 x + h 22 y + h 23 h 31 x + h 32 y + h 33 y'=\frac{h_{21}x+h_{22}y+h_{23}}{h_{31}x+h_{32}y+h_{33}} y′=h31x+h32y+h33h21x+h22y+h23
也就是一个点对,对应两个等式。
将H添加约束条件,使得H矩阵模变为1,即 ∣ ∣ H ∣ ∣ = 1 ||{H}||=1 ∣∣H∣∣=1,如下:
x ′ = h 11 x + h 12 y + h 13 h 31 x + h 32 y + h 33 ( 1 ) x'=\frac{h_{11}x+h_{12}y+h_{13}}{h_{31}x+h_{32}y+h_{33}} \quad (1) x′=h31x+h32y+h33h11x+h12y+h13(1)
y ′ = h 21 x + h 22 y + h 23 h 31 x + h 32 y + h 33 ( 2 ) y'=\frac{h_{21}x+h_{22}y+h_{23}}{h_{31}x+h_{32}y+h_{33}} \quad (2) y′=h31x+h32y+h33h21x+h22y+h23(2)
h 11 2 + h 12 2 + h 13 2 + h 21 2 + h 22 2 + h 23 2 + h 31 2 + h 32 2 + h 33 2 = 1 h_{11}^2+h_{12}^2+h_{13}^2+h_{21}^2+h_{22}^2+h_{23}^2+h_{31}^2+h_{32}^2+h_{33}^2=1 h112+h122+h132+h212+h222+h232+h312+h322+h332=1
对上式(1)、(2)乘以分母展开,得:
( h 31 x + h 32 y + h 33 ) x ′ = h 11 x + h 12 y + h 13 \left(h_{31}x+h_{32}y+h_{33}\right)x^{\prime}=h_{11}x+h_{12}y+h_{13} (h31x+h32y+h33)x′=h11x+h12y+h13
( h 31 x + h 32 y + h 33 ) y ′ = h 21 x + h 22 y + h 23 \left(h_{31}x+h_{32}y+h_{33}\right)y^{\prime}=h_{21}x+h_{22}y+h_{23} (h31x+h32y+h33)y′=h21x+h22y+h23
整理,得到:
h 11 x + h 12 y + h 13 − h 31 x x ′ − h 32 y x ′ − h 33 x ′ = 0 h_{11}x+h_{12}y+h_{13}-h_{31}xx^{\prime}-h_{32}yx^{\prime}-h_{33}x^{\prime}=0 h11x+h12y+h13−h31xx′−h32yx′−h33x′=0
h 21 x + h 22 y + h 23 − h 31 x y ′ − h 32 y y ′ − h 33 y ′ = 0 h_{21}x+h_{22}y+h_{23}-h_{31}xy'-h_{32}yy'-h_{33}y'=0 h21x+h22y+h23−h31xy′−h32yy′−h33y′=0
假设我们得到两幅图片中对应的N个点对(特征点匹配对),可以得到如下线性方程组:

写成矩阵形式:
2 N x 9 9 x 1 2 N x 1 A h = 0 \begin{array}{cccc}\mathbf{2Nx9}&\mathbf{9x1}&&\mathbf{2Nx1}\\\mathbf{A}&\mathbf{h}&=&\mathbf{0}\end{array} 2Nx9A9x1h=2Nx10
在真实的应用场景中,计算的点对中都会包含噪声。比如,点的位置偏差几个像素,甚至出现特征点对误匹配的现象,如果只是用4个点对来计算单应性矩阵,会出现很大的误差。因此,为了使得计算更精确,一般都会使用远大于4个点对来计算单应性矩阵。另外,上述的线性方程组采用直接线性解法,通常很难得到最优解,所以实际使用中一般会使用其他优化方法,如奇异值分解、Levenberg-Marquarat(LM)算法等进行求解。
7.5 单应性矩阵的计算流程
根据打印的棋盘标定图和拍摄的照片来计算单应性矩阵H。其大致流程如下:
-
打印一张棋盘格标定图纸,将其贴在平面物体的表面;
-
拍摄一组不同方向棋盘格的图片,可以通过移动相机来实现,也可以移动标定图片来实现;
-
对于每张拍摄的棋盘图片,检测图片中所有的棋盘格的角点。
-
因为棋盘标定图纸中所有角点的世界坐标是已知的,这些角点对应的图像像素坐标也是已知的。如果有N>=4个配对点对,就可以根据LM等优化方法得到其单应性矩阵H,匹配点对越多,计算结果越鲁棒。计算单应性矩阵一般不需要自己写函数实现,在OpenCV中有现成的函数可以调用,对应的C++函数是:
Mat findHomography(InputArray srcPoints, InputArray dstPoints, int method=0, double ransacReprojThreshold=3, OutputArray mask=noArray() )从函数来看,只要输入匹配点对,指定具体计算方法,即可得到单应性矩阵。
三、张正友相机标定法
1. 引言
张正友博士在1999年发表在国际顶级会议ICCV的论文《Flexible Camera Calibration By Viewing a Plane From Unknown Orientations》,提出一种利用平面棋盘格进行相机标定的实用方法。该方法介于摄影标定法和自标定法之间,既客服了摄影标定法需要的高精度三维标定物的缺点,又解决了自标定法鲁棒性差的难题。标定过程仅需要一个打印出来的棋盘格,并从不同方向拍摄几组图像即可,任何人都可以自己制作标图案。不仅实用灵活方便,而且精度很高,鲁棒性好。因此,很快被全世界广泛采用,极大的促进了三维计算机视觉从实验室走向真实世界的进程。
张正友标定法,使用二维方格组成的标定板进行标定,采集标定板不同位姿图片,提取图片中角点像素坐标,通过单应矩阵计算出相机的内外参数初始值,利用非线性最小二乘法估计畸变系数,最后使用极大似然估计法优化参数。该方法操作简单,精度高,满足大部分的场合。
2. 张正友简介
张正友博士,是世界著名的计算机视觉和多媒体技术的专家,ACM Fellow,IEEE Fellow。现任微软研究院视觉计算组高级研究员。他在立体视觉、三维重建、运动分析、图像配准、摄像机标定等方面都有开创性的贡献。
3. 棋盘格标定板
3.1 棋盘格标定板简介
棋盘格标定板是一块由黑白方块间隔组成的标定板,用来作为相机标定的标定物(从真实世界映射到数字图像内的对象)。之所以使用棋盘作为标定物,是因为相对于复杂的三维物体,平面棋盘模式更容易处理。与此同时,二维物体相对于三维物体会缺少一部分信息,通过多次改变棋盘的方位来捕捉图像,以获得更丰富的坐标信息。如下图所示,是相机在不同方向下拍摄的同一个棋盘格标定板的图像。

3.2 获取棋盘格标定板
calib.io
3.2.1 方格标定板
下载:方格标定板
标定板的尺寸:w=9,h=6。

3.2.2 圆形标定板
下载:圆形标定板
标定板的尺寸:w=11,h=4。

标定板的尺寸:w=17,h=6。

3.2.3 ChAruco标定板
- 7X5 ChAruco board;
- square size: 30 mm ;
- marker size: 15 mm;
- aruco dict: DICT_5X5_100;
- page width: 210 mm, page height: 297 mm。

3.2.4 生成棋盘格标定板
Create calibration pattern
用python生成自定义的标定板,下载python脚本文件:gen_pattern.py
3.3 角点
角点就是黑白棋盘格交叉点,如下图所示,中间品红的圆圈内就是一个角点。
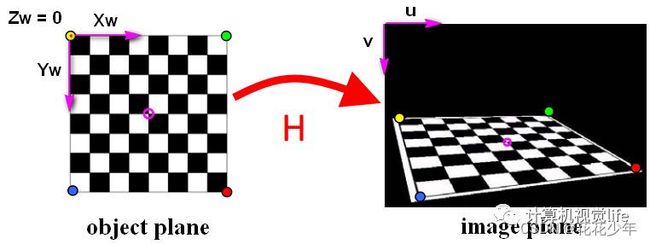
如下图所示,X方向有8个角点,Y方向有3个角点。

3.4 内角点
角点是指黑白色相接的方块定点部分;内角点是不与标定板边缘接触的内部角点。
patternSize:(w,h),棋盘上每一排和每一列的内角数。w=棋盘板一行上黑白块的数量-1,h=棋盘板一列上黑白块的数量-1,例如:9x4的棋盘板,则(w,h)=(8,3)
3.5 棋盘格标定板坐标系
棋盘格标定板坐标系,默认采用平面标定模式,即Z轴都为零。
定义棋盘格标定板位于世界坐标系 Z w = 0 Z_w=0 Zw=0 的平面上,世界坐标系的原点位于棋盘格标定板的固定一角,比如下图中的黄色点。图像像素坐标系的原点位于图像左上角。
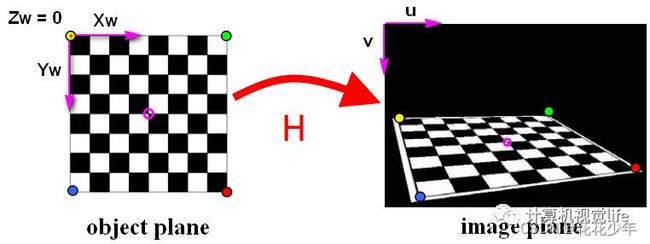
写坐标时,要保证Z轴为0,按照先X变化,后Y变化,从小到大的顺序写。如果棋盘标定板的网格尺寸为5cm,世界坐标系下的坐标可以写为:(0,0,0),(5,0,0), (10,0,0)…(0,5,0), (5,5,0), (10,5,0),…
4. 张正友标定法计算流程
采用棋盘格标定板进行标定,需要找到棋盘格内角点,根据棋盘格内角点在图像像素坐标系下的坐标和各点对应的世界坐标系下的坐标,拍摄多个位置的棋盘格,多点求解相机内外参。
使用OpenCV进行张正友标定法,计算流程如下:
- 准备标定图片,理论上至少4张,一般在多个角度采集20张左右;
- 提取标定板的角点,并计算出标定板上角点的坐标,一般将标定板当作 X-Y 平面,Z为0;
- 相机标定,通过张正友标定法计算出内参外参以及畸变参数;
- 对标定结果进行评价,一般通过重投影误差进行评价;
- 查看标定效果,利用标定结果对棋盘图进行矫正。
5. 核心函数
cornerSubPix()
OpenCV中feature2D学习——亚像素级角点检测(cornerSubPix)
OpenCV3 亚像素角点检测:cornerSubPix()
功能:亚像素级别的角点检测,将内角点位置精确到亚像素级精度。
void cornerSubPix(InputArray image,
InputOutputArray corners,
Size winSize,
Size zeroZone,
TermCriteria criteria);
参数解释
-
image表示输入原始的棋盘标定板图像(图像矩阵),是输入参数。图像矩阵必须是8-bit灰度图或者彩色图像,在图像传入函数之前,一般经过灰度处理,还有滤波操作; -
corners表示内角点坐标,既是输入参数,也是输出参数。把findChessboardCorners()输出的内角点作为该函数的输入corners,经过亚像素级别的内角点检测之后输出corners; -
winSize表示搜索窗口边长的一半。例如,如果winSize=Size(5, 5),则一个大小为 ( 5 ∗ 2 + 1 ) ∗ ( 5 ∗ 2 + 1 ) = 11 ∗ 11 (5*2+1)*(5 *2+1)=11*11 (5∗2+1)∗(5∗2+1)=11∗11 的搜索窗口将被使用; -
zeroZone表示搜索区域中间的dead region边长的一半,有时用于避免自相关矩阵的奇异性。如果值设为(-1,-1)则表示没有这个区域; -
criteria表示角点亚像素级精准化迭代过程的终止条件。可选的值有:cv::TermCriteria::MAX_ITER表示迭代次数达到最大次数时停止;cv::TermCriteria::EPS表示角点位置变化已经达到最小值时停止迭代。
二者均使用
cv::TermCriteria()构造函数进行指定,且可以组合使用。//指定亚像素计算迭代条件 cv::TermCriteria criteria = cv::TermCriteria( cv::TermCriteria::MAX_ITER + cv::TermCriteria::EPS, // 终止条件 40, // 最大次数 0.01); // 最小值
findChessboardCorners()
findChessboardCorners()角点检测详解
功能:角点检测,获取棋盘格标定板内角点位置。
返回值:所有角点被检测出且以一定顺序排列,返回非0数,否则返回0。
// 函数原型
findChessboardCorners(InputArray image,
Size patternSize,
OutputArray corners,
int flags);
参数解释
-
image表示输入原始的棋盘标定板图像(图像矩阵),是输入参数。图像矩阵必须是8-bit灰度图或者彩色图像,在图像传入函数之前,一般经过灰度处理,还有滤波操作; -
patternSize表示内角点的size,是输入参数。数据类型:
Size patternSize(w,h),w、h分别表示棋盘上每一排和每一列的内角数。w=棋盘格标定板一行上黑白块的总数-1,h=棋盘格标定板一列上黑白块的总数-1。
例如:10x6的棋盘格标定板,则(w,h)=(9,5)。
注意:根据内角点的尺寸,确定标定板的方向。具体来说,w和h不相同,该函数可辨别标定板的方向;如果w和h相同,该函数每次画出的角点起始位置会发生变化,不利于标定。
-
corners表示检测到的内角点的输出数组,输出参数。数据类型:
vector。 -
flags标志位,是输入参数,有默认值。CV_CALIB_CB_ADAPTIVE_THRESH:函数默认方式,使用自适应阈值法对图像进行二值化,而不是使用一个固定的阈值;CV_CALIB_CB_NORMALIZE_IMAGE:在利用固定阈值或自适应阈值法二值化图像之前,调用EqualizeHist()函数进行图像归一化处理,利用直方图均衡化图像;CV_CALIB_CB_FILTER_QUADS:二值化完成后,函数开始定位图像中的四边形(这里不应该称之为正方形,因为存在畸变)。使用额外的标准(如轮廓面积,周长,正方形形状)来过滤掉在轮廓检索阶段提取的假四边形,从而使得角点检测更准确更严格;CALIB_CB_FAST_CHECK:快速检测选项,对图像进行一个快速检查机制以查找棋盘板的角点。对于检测角点极可能不成功检测的情况,这个标志位可以使函数效率提升。
注意:标志位可组合使用。
CALIB_CB_FAST_CHECK一般用于快速检测,很有可能检测不成功,特别是棋盘光线不均匀时。总体来说,CV_CALIB_CB_ADAPTIVE_THRESH是最可能检测到棋盘格的方式。组合使用推荐CV_CALIB_CB_ADAPTIVE_THRESH|CV_CALIB_CB_NORMALIZE_IMAGE,如果默认方式或这个组合方式检测不到角点,基本就需要重新采图了。
该函数的功能是判断图像内是否包含完整的棋盘格,如果能完全检测出来,就把角点位置顺序(从左到右,从上到下)记录下来,并返回非0数,否则返回0。这里对 patternSize 参数要求非常严格,函数必须检测出相同的size才会返回非0,否则返回0。
该函数检测的角点坐标是不准确的,获得角点精确坐标,可使用 cornerSubPix() 函数,进行角点亚像素提取,使用方法可参考博客:角点检测及优化函数使用
drawChessboardCorners()
功能:把检测到的角点在原图中画出来。
calibrateCamera()
OpenCV函数用法之calibrateCamera
功能:相机标定。
double calibrateCamera(InputArrayOfArrays objectPoints,
InputArrayOfArrays imagePoints,
Size imageSize,
InputOutputArray cameraMatrix,
InputOutputArray distCoeffs,
OutputArrayOfArrays rvecs,
OutputArrayOfArrays tvecs,
int flags=0);
参数解释
-
objectPoints表示世界坐标系下的点,即3D points。数据类型为:
std::vector,第一层vector表示每一个视角(每一张图),第二层vector表示每一个点。 -
imagePoints表示其对应图像像素坐标系下的点,即2D points。这个值可以通过findChessboardCorners()函数从图像中获得。数据类型为:
std::vector,第一层vector表示每一个视角,第二层vector表示每一个内角点。 -
imageSize表示图像的大小,在计算相机的内参和畸变矩阵需要用到; -
cameraMatrix表示相机内参矩阵,该矩阵大小为 3x3。该矩阵由相机标定输出的结果。数据类型为:
cv::Mat cameraMatrix; -
distCoeffs表示畸变矩阵,具体尺寸取决于参数flags。该矩阵由相机标定输出的结果。数据类型:
cv::Mat distCoeffs; -
rvecs表示旋转向量。每个vector会得到一个 rvecs,每个 vec 为 3x1,可以用Rodrigues()函数转换为3x3的旋转矩阵。数据类型:
vector; -
tvecs表示平移向量,和rvecs一样,每个 vec 为3x1。数据类型:
vector;参数 rvecs 和 tvecs 是相机外参,对于每一个视图,都可以将其世界坐标系转成相机坐标系。
-
flags表示标定时所采用的参数,包括决定是否使用初始值、畸变矩阵的参数个数等。有如下参数:CV_CALIB_USE_INTRINSIC_GUESS:使用该参数时,在cameraMatrix矩阵中应该有fx,fy,cx,cy的估计值。否则的话,将初始化图像的中心点(cx,cy),并使用最小二乘估算出fx,fy;CV_CALIB_FIX_PRINCIPAL_POINT:在进行优化时会固定光轴点。当CV_CALIB_USE_INTRINSIC_GUESS参数被设置,光轴点将保持在中心或者某个输入的值;CV_CALIB_FIX_ASPECT_RATIO:固定fx/fy的比值,只将fy作为可变量,进行优化计算。当CV_CALIB_USE_INTRINSIC_GUESS没有被设置,fx和fy将会被忽略。只有fx/fy的比值在计算中会被用到;CV_CALIB_ZERO_TANGENT_DIST:设定切向畸变参数(p1,p2)为零;- CV_CALIB_FIX_K1,…,CV_CALIB_FIX_K6:对应的径向畸变在优化中保持不变;
CV_CALIB_RATIONAL_MODEL:计算k4,k5,k6三个畸变参数。如果没有设置,则只计算其它5个畸变参数。
6. 示例代码
用OpenCV实现张正友标定流程。
6.1 C++实现
张正友视觉标定算法学习笔记
示例一
对多张视图进行标定。
#include
#include
#include
std::vector get_all_image_file(std::string image_folder_path){
boost::filesystem::path dirpath = image_folder_path;
boost::filesystem::directory_iterator end;
std::vector files;
for (boost::filesystem::directory_iterator iter(dirpath); iter != end; iter++)
{
boost::filesystem::path p = *iter;
files.push_back(dirpath.string()+ "/"+ p.leaf().string());
}
std::sort(files.begin(),files.end());
return files;
}
std::vector get_all_iamge(std::string image_folder_path)
{
std::vector images;
std::vector image_files_path = get_all_image_file(image_folder_path);
for(int i=0; i< image_files_path.size() ;i++){
cv::Mat image;
image = cv::imread(image_files_path[i]);
images.push_back(image);
}
return images;
}
int find_chessboard(cv::Mat image, std::vector &image_points, cv::Size board_size)
{
if (0 == findChessboardCorners(image, board_size, image_points))
{
std::cout<<"can not find chessboard corners!\n";
return 0;
}
else
{
cv::Mat view_gray;
cv::cvtColor(image,view_gray,cv::COLOR_RGB2GRAY);
//对粗提取的角点进行亚像素精确化
cv::find4QuadCornerSubpix(view_gray,image_points,cv::Size(11,11));
//int nChessBoardFlags = cv::CALIB_CB_EXHAUSTIVE | cv::CALIB_CB_ACCURACY;
//bool bFindResult = findChessboardCornersSB(view_gray,board_size,image_points,nChessBoardFlags );
//Opencv4 识别棋盘格方法,比opencv3有较大提升
}
return 1;
}
int init_chessboard_3dpoints(cv::Size board_size, std::vector &points, float point_size)
{
cv::Size2f square_size = cv::Size2f(point_size,point_size);
for (int i=0;i images){
cv::Size image_size;
cv::Size board_size(11,4);
std::vector images_tvecs_mat;
std::vector images_rvecs_mat;
image_size.width = images[0].cols;
image_size.height = images[0].rows;
std::vector > images_points;
// 识别所有图片的棋盘格
for(int i=0;i image_points;
if(find_chessboard(images[i],image_points,board_size)>0){
images_points.push_back(image_points);
}
}
std::vector image_points_in3d;
// 计算棋盘格角点在棋盘格坐标系中的位置
init_chessboard_3dpoints(board_size,image_points_in3d,0.045); // 0.045为棋盘格一个格子的大小
std::vector > images_points_in3d;
// 生成所有识别出的标定板对应在各自棋盘格坐标系中的位置
for(int i=0;i images = get_all_iamge(image_file_path);
calib_monocular(images);
return 0;
}

示例二
对单张视图进行标定。
int cols = 10;
int rows = 7;
float distance = 30; //间距30mm
cv::Size patternSize(cols,rows);
std::vector corners;
std::vector> cornersVect;
std::vector worldPoints;
std::vector> worldPointsVect;
for (int i=0;i rvecs,tvecs,rvecs2,tvecs2;
if (find)
{
cornersVect.push_back(corners);
worldPointsVect.push_back(worldPoints);
cv::calibrateCamera(worldPointsVect,
cornersVect,image.size(),
cameraMatirx,
distCoeffs,
rvecs,tvecs);
}
6.2 Python实现
[学习笔记]python-Opencv cv2.findChessboardCorners() 的基本使用
示例一
对单张视图进行标定。
import numpy as np
import cv2
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
fname='calibration_test.png'
image=cv2.imread(fname)
# plt.imshow(image)
# plt.show()
gray=cv2.cvtColor(image,cv2.COLOR_RGB2GRAY)
plt.imshow(gray,cmap='gray')
plt.show()
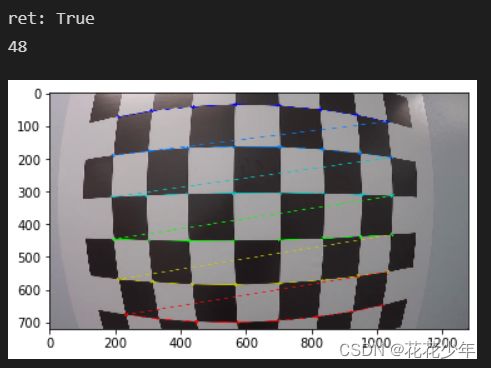
# Find the chessboard corners
nx=8
ny=6
ret, corners = cv2.findChessboardCorners(gray, (nx, ny), None)
print('ret:',ret)
# print(len(corners))
# If found, draw corners
if ret == True:
# Draw and display the corners
cv2.drawChessboardCorners(image, (nx, ny), corners, ret)
plt.imshow(image)
如下图所示,9x7的棋盘格标定板,一行棋盘格为9,一列棋盘格为7,则内角点 patternSize(w,h) 中的w=8,h=6。


示例二
对单张视图进行标定。
import numpy as np
import cv2 as cv
import glob
# termination criteria
#
criteria = (cv.TERM_CRITERIA_MAX_ITER + cv.TERM_CRITERIA_EPS, 30, 0.001)
# prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
"""
objp =
[[0 0 0],
[0 0 0],
...,
[0 0 0]], (42, 3)
"""
objp = np.zeros((6*7,3), np.float32)
"""
np.mgrid[0:7,0:6] = array([
[[0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 2],
[3, 3, 3, 3, 3, 3],
[4, 4, 4, 4, 4, 4],
[5, 5, 5, 5, 5, 5],
[6, 6, 6, 6, 6, 6]],
[[0, 1, 2, 3, 4, 5],
[0, 1, 2, 3, 4, 5],
[0, 1, 2, 3, 4, 5],
[0, 1, 2, 3, 4, 5],
[0, 1, 2, 3, 4, 5],
[0, 1, 2, 3, 4, 5],
[0, 1, 2, 3, 4, 5]]]), (2, 7, 6)
objp = array([
[0 0 0],
[1 0 0],
[2 0 0],
...,
[6 5 0]], (42, 3)
"""
objp[:,:2] = np.mgrid[0:7,0:6].T.reshape(-1,2)
# Arrays to store object points and image points from all the images.
objpoints = [] # 3d point in real world space
imgpoints = [] # 2d points in image plane.
images = glob.glob('*.jpg')
for fname in images:
img = cv.imread(fname)
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Find the chess board corners
ret, corners = cv.findChessboardCorners(gray, (7,6), None)
# If found, add object points, image points (after refining them)
if ret == True:
objpoints.append(objp)
corners2 = cv.cornerSubPix(gray,corners, (11,11), (-1,-1), criteria)
imgpoints.append(corners2)
# Draw and display the corners
cv.drawChessboardCorners(img, (7,6), corners2, ret)
cv.imshow('img', img)
cv.waitKey(500)
cv.destroyAllWindows()
# Calibration
"""
camera matrix: mtx
distortion coefficients: dist
rotation vectors: rvecs
translation vectors: tvecs
"""
ret, mtx, dist, rvecs, tvecs = cv.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
if ret == True:
# Re-projection Error
mean_error = 0
for i in range(len(objpoints)):
imgpoints2, _ = cv.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv.norm(imgpoints[i], imgpoints2, cv.NORM_L2)/len(imgpoints2)
mean_error += error
print( "total error: {}".format(mean_error/len(objpoints)) )
如下图所示,8x7的棋盘格标定板,一行棋盘格为9,一列棋盘格为7,则内角点 patternSize(w,h) 中的w=7,h=6。


四、相关经验
opencv标定实现总结(圆点,棋盘格和非对称圆点)
Kalibr标定工具
github官方仓库:kalibr
kalibr是一个标定工具箱,适用于以下场景:
- Multi-Camera Calibration;
- Visual-Inertial Calibration(CAM-IMU);
- Multi-Inertial Calibration(IMU-IMU);
- Rolling Shutter Camera Calibration。