教程--从零开始使用BiSeNet(语义分割)网络训练自己的数据集
引言
为了从图片分割出我们想要的特征,我们采用BiSeNet作为分割模型,并且在自己制作的数据集上进行训练测试。注:训练是在linux环境下的,Win下训练可能会有点问题。
一、下载BiSeNet网络的安装包
1、下载地址:GitHub - CoinCheung/BiSeNet: Add bisenetv2. My implementation of BiSeNet
2、下载解压到你的目录中,文件结构如下图所示:

二、制作相关数据集
1、我们采用labelme工具来进行数据标注,labelme使用方法这里就不具体叙述了。
2、经过步骤1,我们可以得到原图JPG文件以及对应的Json文件,如下图:
3、 将json文件转换为可视化的分割图片
我们这里借鉴了https://github.com/caozhiwei1994/labelme2dataset链接中的方法,将链接文件下载并解压到任意目录中,打开后有三个文件如下图:

进入到labelme2BisSeNet文件夹中,并且将步骤1得到的原图和JSON文件放入其中,如下图(PV是我数据集的名称,PV中就是JPG和JSON):

执行json_to_dataset.py文件代码,也就是下面的代码(注意修改自己的文件地址):
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
def main():
count = os.listdir("E:\File\Pycharm\BiSeNet-master\datasets\labelme2dataset-main\labelme2BiSeNet\PV") #数据集的地址
for i in range(0, len(count)):
path = os.path.join("./PV", count[i]) #注意好文件地址
if os.path.isfile(path) and path.endswith('json'):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(count[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(count[i]), out_dir)
out_dir = osp.join("output", out_dir)
if not osp.exists(out_dir):
#os.mkdir(out_dir)
os.makedirs(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
注意:执行这一步代码可能会出现错误:“labelme.utils”没有“draw_label”属性。
解决方法:主要是labelme版本的问题,降低版本即可:
pip install labelme==3.16.7
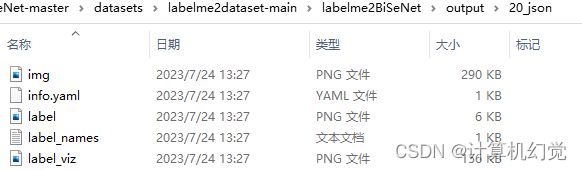
执行完之后,得到output文件夹,output文件夹下文件(可视化分割)如下图:

4、得到成对的JPG_PNG训练图片
首先,我们在labelme2BiSeNet目录下新建txt,里面包含了我们标记的所有类(我们这里是三类,包括背景),如下图:


接着,运行get_png.py文件,即下面的代码:
import os
from PIL import Image
import numpy as np
def main():
# 读取原文件夹
count = os.listdir("PV") #注意修改为自己的地址
for i in range(0, len(count)):
# 如果里的文件以jpg结尾
# 则寻找它对应的png
if count[i].endswith("jpg"):
path = os.path.join("PV", count[i]) #注意修改为自己的地址
img = Image.open(path)
if not os.path.exists('jpg_png/jpg'):
os.makedirs('jpg_png/jpg')
img.save(os.path.join("jpg_png/jpg", count[i]))
# 找到对应的png
path = "output/" + count[i].split(".")[0] + "_json/label.png"
img = Image.open(path)
# 找到全局的类
class_txt = open("class_name.txt", "r")
class_name = class_txt.read().splitlines()
# ["_background_","a","b"]
# 打开json文件里面存在的类,称其为局部类
with open("output/" + count[i].split(".")[0] + "_json/label_names.txt", "r") as f:
names = f.read().splitlines()
# ["_background_","b"]
new = Image.new("RGB", [np.shape(img)[1], np.shape(img)[0]])
# print('new:',new)
for name in names:
index_json = names.index(name)
index_all = class_name.index(name)
# 将局部类转换成为全局类
new = new + np.expand_dims(index_all * (np.array(img) == index_json), -1)
new = Image.fromarray(np.uint8(new))
print('new:',new)
if not os.path.exists('jpg_png/png'):
os.makedirs('jpg_png/png')
new.save(os.path.join("jpg_png/png", count[i].replace("jpg", "png")))
print(np.max(new), np.min(new))
if __name__ == '__main__':
main()
执行以上代码,会获得jpg_png文件,jpg文件存放了原图,png存放了与之对应的24位灰度图(肉眼看都是黑色的,因为类别都是按照像素值划分的,看上去都是黑的其实像素值都是0,1什么的):



5、然而BiSeNet需要的是8位的灰度图,上面是24位的,需要我们继续转化,执行get_dataset.py文件,即以下代码:
import cv2
import os
from PIL import Image
#if picture is jpg,you can use jpg2png
jpg_read = "jpg_png/jpg/"
if not os.path.exists('dataset/gt_png'):
os.makedirs('dataset/gt_png')
png_write = "dataset/gt_png/"
jpg_names = os.listdir(jpg_read)
for j in jpg_names:
img = Image.open(jpg_read + j)
j = j.split(".")
if j[-1] == "jpg":
j[-1] = "png"
j = str.join(".", j)
# r,g,b,a=img.split()
# img=Image.merge("RGB",(r,g,b))
to_save_path = png_write + j
img.save(to_save_path)
else:
continue
#24bit to 8bit
bit24_dir = 'jpg_png/png' #上一步保存.png图像文件夹
if not os.path.exists('dataset/label_png'):
os.makedirs('dataset/label_png')
bit8_dir = 'dataset/label_png'
png_names = os.listdir(bit24_dir)
for i in png_names:
img = cv2.imread(bit24_dir+'/'+i)
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
cv2.imencode('.png', gray)[1].tofile(bit8_dir+'/'+i)
执行完之后,得到dataset文件,里面存放了成对的训练图片,如下图:


由于BiSeNet网络需要保证所有图片大小保持一致,这样测试不会出错,如果你的训练图片大小都一致就可以不用看下面代码,下面代码是resize和crop(也就是分别执行resize.py和crop.py文件):
# resize.py
import cv2
import os
import shutil
def main(path):
for root, dirs, files in os.walk(path):
for file in files:
if file.endswith('.png'):
image_name = os.path.join(root, file)
image = cv2.imread(image_name, -1)
crop_image = cv2.resize(image,(1080,704))
os.remove(image_name)
cv2.imwrite(image_name, crop_image)
image_path = './dataset/gt_png'
label_path = './dataset/label_png'
if __name__ == '__main__':
main(image_path)
main(label_path)
# crop.py
# 将1280×720裁剪1080×704
import cv2
import os
import shutil
def main(path):
for root, dirs, files in os.walk(path):
for file in files:
if file.endswith('.png'):
image_name = os.path.join(root, file)
image = cv2.imread(image_name, -1)
crop_image = image[:700,:1080]
os.remove(image_name)
cv2.imwrite(image_name, crop_image)
image_path = './dataset/gt_png'
label_path = './dataset/label_png'
if __name__ == '__main__':
main(image_path)
main(label_path)
6、获得txt文件
完成上述步骤之后,执行train_val.py以及train_val_txt.py文件,即以下代码,将数据集划分成训练集和验证集,并且得到txt文件:
# train_val.py
'''
将数据分为train val
'''
import os
import random
import shutil
total_list = []
train_list = []
val_list = []
image_path = 'dataset/gt_png'
label_path = 'dataset/label_png'
# 清空
for dir in ['train', 'val']:
image_dir = os.path.join(image_path, dir)
label_dir = os.path.join(label_path, dir)
if os.path.exists(image_dir):
shutil.rmtree(image_dir)
os.makedirs(image_dir)
if os.path.exists(label_dir):
shutil.rmtree(label_dir)
os.makedirs(label_dir)
for root, dirs, files in os.walk(image_path):
for file in files:
if file.endswith('png'):
total_list.append(file)
total_size = len(total_list)
train_size = int(total_size * 0.8)
val_size = total_size-train_size
train_list = random.sample(total_list, train_size)
remain_list = list(set(total_list) - set(train_list))
val_list = random.sample(remain_list, val_size)
for file in total_list:
image_path_0 = os.path.join(image_path, file)
label_file = file.split('.')[0] + '.png'
label_path_0 = os.path.join(label_path, label_file)
if file in train_list:
image_path_1 = os.path.join(image_path, 'train', file)
shutil.move(image_path_0, image_path_1)
label_path_1 = os.path.join(label_path, 'train', label_file)
shutil.move(label_path_0, label_path_1)
elif file in val_list:
image_path_1 = os.path.join(image_path, 'val', file)
shutil.move(image_path_0, image_path_1)
label_path_1 = os.path.join(label_path, 'val', label_file)
shutil.move(label_path_0, label_path_1)
print(len(total_list))
print(len(train_list))
print(len(val_list))import os
def write_txt(type,txt):
gt = os.listdir("dataset/gt_png/"+type)
label = os.listdir("dataset/label_png/"+type)
with open(txt, "w") as f:
for i in gt:
j = i.replace("gt_png","label_png")
# 判断jpg是否存在对应的png
if j in label:
f.write("gt_png/"+ type + '/' + i + ","+"label_png/"+type + '/'+ j + "\n")
write_txt("train","train.txt")
write_txt("val","val.txt")
得到我们需要的文件,即dataset、train.txt以及val.txt,至此数据集的准备工作已经全部完成。

三、训练BiSeNet网络
1、将dataset文件中的gt_png、label_png文件夹以及train.txt和val.txt放入到BiSeNet-master/datasets/cityscapes目录下,如下图(其他两个文件后面自动生成的,这里先不管):

2、修改部分代码
这一步需要根据你自己的情况来修改代码,基本要改的就是类别数,原作者的类别数是19,可以自己全局搜索19,将所有19都改成你的类别数量(这里的类别数量包含了背景)
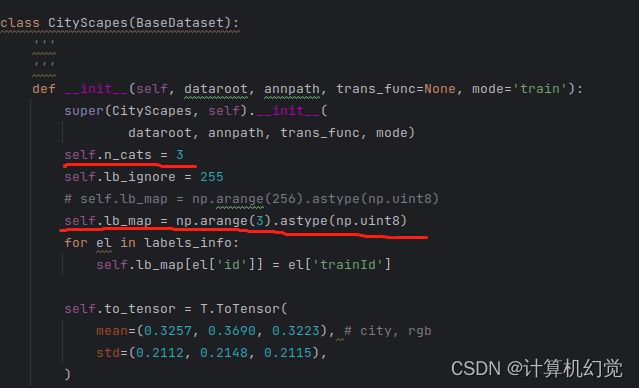
除此之外,有一个比较重要的修改就是cityscapes_cv2.py文件,需要修改两个部分,如下图:

第一行默认不要动(背景类),第二行第三行改成你自己的类(因为博主除了背景只有两类),并且将‘ignoreInEval’改为False,color随意设置,trainId和name也需要修改。(这一步不改好后面训练可能会出现loss为Nan)
接着修改下面的代码(就在文件下面),n_cats=你的类别数(包含背景),arange(类别数)
四、开始训练
博主采用的单卡训练,LInux环境:
export CUDA_VISIBLE_DEVICES=0
torchrun --nproc_per_node=1 tools/train_amp.py --config ./configs/bisenetv2_city.py
训练参数在configs/目录下的文件进行调整:


详细的训练和测试命令可以参考该代码的作者github,也就是GitHub - CoinCheung/BiSeNet: Add bisenetv2. My implementation of BiSeNet
参考文章:BiSeNet训练labelme标注的语义分割数据集_setuptools==50.3.1.post20201107_无为旅人的博客-CSDN博客
如果遇到问题,欢迎在评论区留言,博主都会一一解答。